VLA综述:Vision-Language-Action Models: Concepts, Progress, Applications and Challenges(前2章)
视觉-语言-动作(Vision-Language-Action, VLA)模型标志着人工智能领域的一项变革性进展,旨在将感知、自然语言理解与具身行动统一于单一的计算框架之中。本综述系统性地梳理了VLA模型近年来的研究进展,并围绕五大主题支柱对该快速演进领域的研究图景进行了全面整合。首先,我们确立了VLA系统的概念基础,追溯其从早期跨模态学习架构逐步演进为通用型智能体的发展脉络——此类智能体紧密融合
全文翻译精炼From https://arxiv.org/abs/2505.04769
Abstract
视觉-语言-动作(Vision-Language-Action, VLA)模型标志着人工智能领域的一项变革性进展,旨在将感知、自然语言理解与具身行动统一于单一的计算框架之中。本综述系统性地梳理了VLA模型近年来的研究进展,并围绕五大主题支柱对该快速演进领域的研究图景进行了全面整合。
首先,我们确立了VLA系统的概念基础,追溯其从早期跨模态学习架构逐步演进为通用型智能体的发展脉络——此类智能体紧密融合了视觉-语言模型(Vision-Language Models, VLMs)、动作规划器与分层控制器。本文采用严谨的文献综述方法,系统分析了过去三年内发表的80余项VLA模型研究。
关键进展涵盖架构创新、参数高效训练策略以及实时推理加速等多个维度。我们深入探讨了VLA模型在人形机器人、自动驾驶、医疗与工业机器人、精准农业及增强现实导航等多样化应用场景中的实践成果。同时,本文亦剖析了当前面临的核心挑战,包括实时控制、多模态动作表征、系统可扩展性、对未见任务的泛化能力以及伦理部署风险等问题。
基于对前沿技术的综合研判,我们提出了若干针对性解决方案,如具身智能体的自适应机制、跨具身泛化能力提升以及统一的神经符号规划框架。在前瞻性讨论中,我们勾勒出一条未来技术路线图:VLA模型、VLM与具身智能体将深度融合,共同驱动具备社会对齐性、适应性与通用能力的具身智能系统的发展。
本综述旨在为推动面向真实世界的智能机器人技术与通用人工智能(AGI)研究提供基础性参考。
Introduction
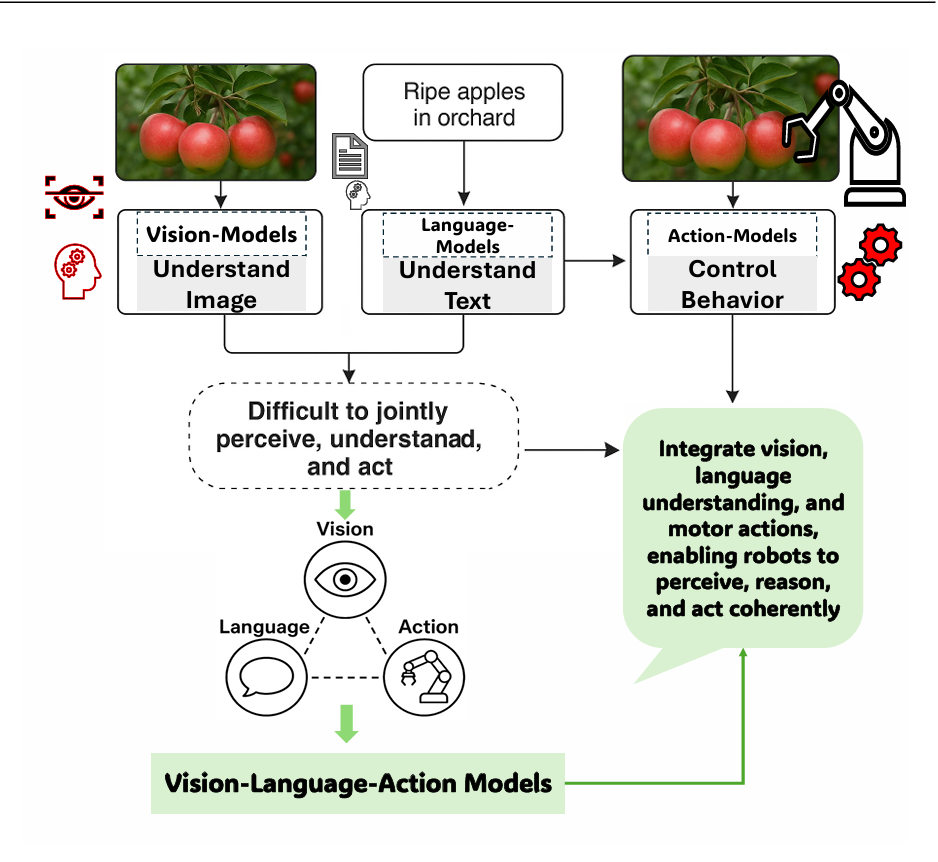
在视觉-语言-动作(Vision-Language-Action, VLA)模型出现之前,机器人学与人工智能的进展主要集中在相互割裂的领域:用于图像识别的视觉系统 [44, 69]、用于文本理解与生成的语言系统 [164, 137],以及用于运动控制的动作系统 [49]。尽管这些系统在各自任务上表现优异,但在协同工作或应对新异、不可预测情境方面存在显著局限 [46, 21],难以真正理解复杂环境或灵活响应现实挑战。
如图1所示,传统的计算机视觉模型(主要基于卷积神经网络,CNNs)通常针对狭窄任务(如目标检测或分类)进行定制,依赖大量标注数据,**且在环境或目标发生微小变化时即需繁琐的重新训练 [156, 62]。**此类模型虽能“看见”(例如识别果园中的苹果),却缺乏语言理解能力,亦无法将视觉信息转化为有目的的动作。大型语言模型(LLMs)虽在文本理解与生成方面带来革命性突破 [23],但其局限于符号空间,无法感知或推理物理世界(图1中“Ripe apples in orchard”即体现此局限)。与此同时,基于手工策略或强化学习的机器人动作系统虽能执行特定操作(如抓取物体),却依赖大量工程设计,泛化能力极弱,难以超越预设脚本 [119]。
尽管视觉-语言模型(VLMs)通过融合视觉与语言实现了强大的多模态理解能力 [149, 25, 148],但仍存在明显的“动作鸿沟”——即无法基于多模态输入生成或执行连贯动作 [121, 107]。如图1进一步所示,多数AI系统最多仅整合两种模态(视觉-语言、视觉-动作或语言-动作),难以实现三者的端到端统一。因此,机器人虽可分别完成“识别苹果”、“理解‘摘苹果’指令”或“执行抓取动作”,却无法将这些能力协调为流畅、自适应的行为。这种碎片化流水线架构导致系统泛化能力脆弱、工程成本高昂,暴露出具身智能的核心瓶颈:缺乏能同步感知、理解与行动的统一系统,使得真正的自主智能行为遥不可及。
正是在这一背景下,VLA模型应运而生。**约在2021–2022年间,以Google DeepMind的Robotic Transformer 2(RT-2)[224]为代表的研究率先提出了一种变革性架构,将感知、推理与控制统一于单一框架之中。**作为对图1所示局限的直接回应,VLA模型融合视觉输入、语言理解与动作输出,使具身智能体能够动态感知环境、解析复杂指令并执行恰当行为。早期VLA方法通过在视觉-语言模型中引入“动作令牌”(action tokens)——即机器人控制命令的数值或符号表示——实现了三模态对齐,从而可从配对的视觉、语言与轨迹数据中联合学习 [121]。该方法显著提升了机器人对未见物体的泛化能力、对新语言指令的理解能力,以及在非结构化环境中进行多步推理的能力 [83]。
VLA模型标志着迈向统一多模态智能的关键一步,突破了长期将视觉、语言与动作视为孤立模块的范式 [121]。借助融合视觉、语言与行为信息的互联网规模数据集,VLA不仅使机器人能识别和描述环境,更能进行上下文推理并在复杂动态场景中执行合适动作 [196]。图1所示的演进路径——从孤立模态系统到集成VLA范式——体现了向真正自适应、可泛化具身智能体的根本性转变。
鉴于其深远影响,亟需一项系统性综述以厘清VLA的核心概念、技术脉络与未来方向。此类综述具有五重必要性:
(1)明确VLA区别于前代模型的基础原理与架构特征;
(2)梳理领域内关键技术进展与里程碑成果,呈现发展轨迹;
(3)系统归纳VLA在家庭服务、工业自动化、辅助技术等真实场景中的应用潜力;
(4)批判性分析当前在数据效率、安全性、泛化能力及伦理风险等方面的挑战;
(5)整合洞见以引导社区聚焦新兴研究方向与工程实践,促进协同创新。
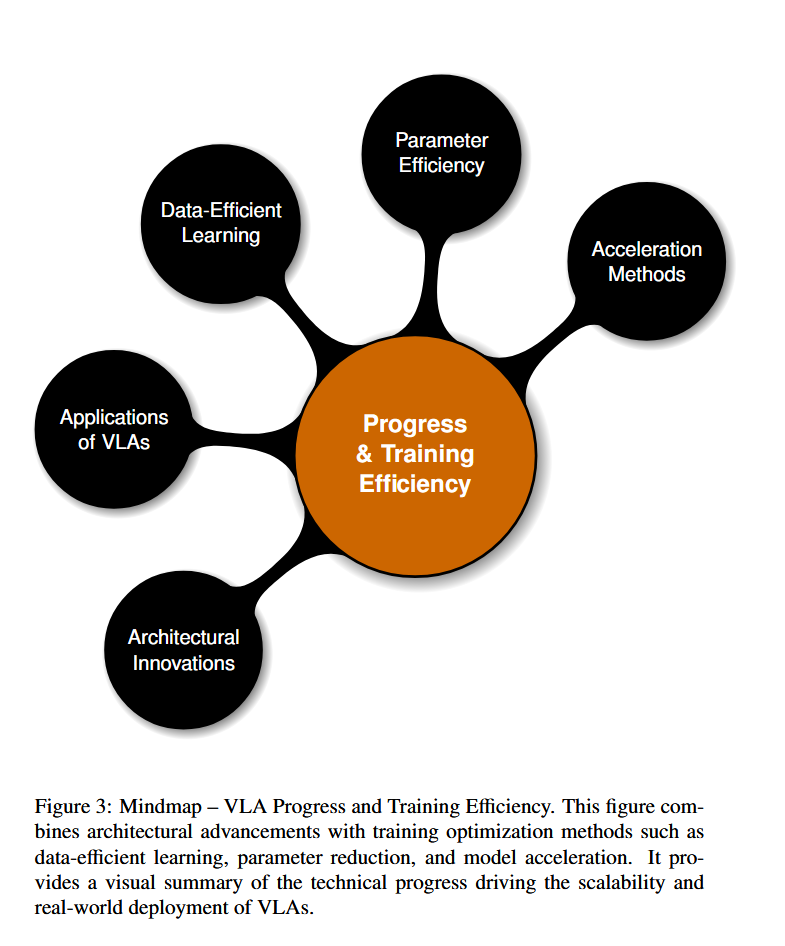
本文系统分析VLA模型的概念基础、发展进展与技术挑战,旨在凝练当前认知、识别局限并提出未来路径。综述首先深入探讨VLA的核心概念(见图2),包括定义、演化历程、多模态融合机制、基于语言的动作令牌化与编码策略等,为理解其跨模态运作机制奠定理论基础。继而,我们整合近期在模型架构、训练效率与推理加速方面的突破(见图3),涵盖支持更强泛化能力的架构创新、数据高效学习框架、参数高效建模方法及模型压缩技术——这些进展对VLA在现实场景中的规模化部署至关重要。最后,我们全面剖析当前VLA系统面临的瓶颈(见图4),包括推理延迟、安全风险、计算开销、泛化局限与伦理问题,并探讨潜在解决方案。
图2–图4共同构建了本文的可视化分析框架:分别对应概念基础、技术进展与开放挑战。通过系统整合理论、方法与应用,本综述旨在推动VLA系统向更鲁棒、高效与伦理可信的方向演进,为具身人工智能与通用智能体的发展提供坚实支撑。
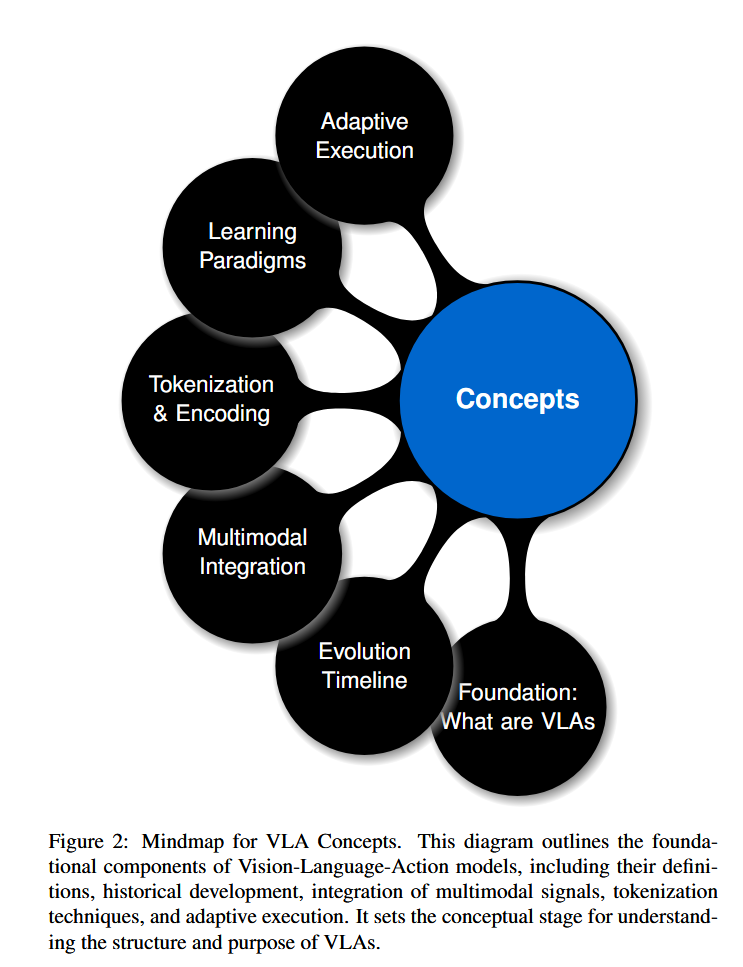

Concepts of Vision-Language-Action Models
视觉-语言-动作(Vision-Language-Action, VLA)模型是一类新型智能系统,能够在动态环境中联合处理视觉输入、理解自然语言并生成可执行动作。从技术架构上看,VLA融合了视觉编码器(如CNN、ViT)、语言模型(如LLM、Transformer)以及策略模块或规划器,实现任务条件下的闭环控制。
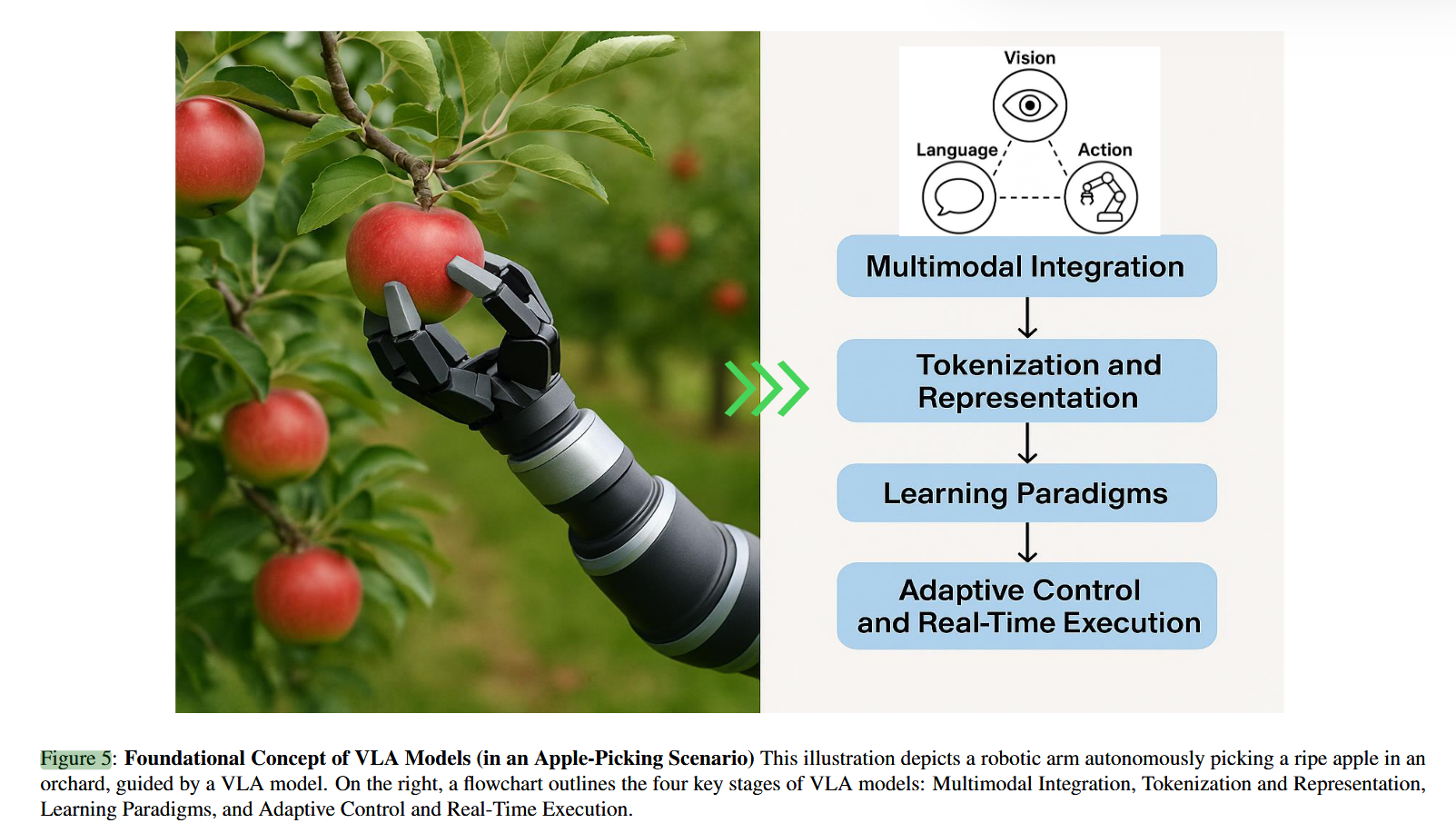
此类模型通常采用多模态融合机制(如交叉注意力、嵌入拼接或统一令牌化),将感官观测与语言指令对齐。与传统视觉-动作流水线不同,VLA支持语义接地(semantic grounding),从而实现上下文感知推理、可操作性(affordance)识别与时序动作规划。典型VLA系统通过摄像头或传感器感知环境,理解以自然语言表达的目标(如“拿起红色苹果”,见图5),并输出高低层级的动作序列。
近期进展通过引入模仿学习、强化学习或检索增强模块,显著提升了样本效率与泛化能力。VLA已从早期多模态融合架构演进为可部署于机器人、导航及人机协作等真实场景的通用智能体。
本质上,VLA是一种端到端的多模态人工智能框架,将视觉感知、语言理解与物理动作生成统一于一体,使智能体能够自主解读多源输入、把握语境意图,并在真实世界中可靠执行任务——从根本上弥合了传统系统中感知、语言与行动长期割裂的鸿沟(如图5所示)。
2.1 发展趋势与时间线
2022至2025年间,视觉-语言-动作(VLA)模型的快速发展可划分为三个清晰的演进阶段:
1. 基础融合阶段(2022–2023年)
早期VLA模型通过多模态融合架构初步实现视觉-动作协调。代表性工作包括:CLIPort [157] 首次将CLIP嵌入与运动基元结合;Gato [141] 在604项任务中展现通用能力;RT-1 [18] 基于规模化模仿学习在操作任务中达到97%成功率;VIMA [86] 引入基于Transformer的规划器以支持时序推理。至2023年,RT-2 [224] 实现视觉链式思维(visual chain-of-thought)推理,Diffusion Policy [34] 则通过扩散过程实现随机动作预测。尽管这些工作有效解决了低层控制问题,但在组合式推理方面仍显不足 [216],由此催生了以VoxPoser [78] 为代表的可操作性(affordance)接地方法。
2. 专业化与具身推理阶段(2024年)
第二代VLA模型引入领域特定的归纳偏置以增强任务适应性。Deer-VLA [202] 通过检索增强训练提升小样本适应能力;Uni-NaVid [210] 融合3D场景图优化导航;ReVLA [39] 采用可逆架构提升内存效率;Occllama [183] 借助物理感知注意力机制应对部分可观测性。同时,ShowUI [108] 强化人机交互,Octo [167] 和Diffusion Policy [34] 则分别通过可扩展数据流水线与随机建模提升泛化性。此外,Occllama [183] 与ShowUI [108] 分别在遮挡鲁棒性与用户交互方面取得突破。这些进展推动了新型评测基准的发展 [196]。
3. 泛化能力与安全关键部署阶段(2025年)
当前VLA系统聚焦于鲁棒性、可部署性与人本对齐。SafeVLA [205] 引入形式化验证以支持风险感知决策;Humanoid-VLA [42] 通过分层VLA实现全身协同控制;MoManipVLA [190] 集成记忆机制提升长期任务能力;Gr00t N1 [13] 与SpatialVLA [136] 分别推进跨具身模拟到真实(sim-to-real)迁移与空间语义接地。新兴范式如Affordance Chaining [100] 和神经符号融合 [102] 进一步增强因果推理与跨平台泛化。同时,ShowUI [108] 等工作通过自然语言接地构建人在环路(human-in-the-loop)接口,强化人机协同。
如图6所示,2022–2025年间共47个VLA模型的发展轨迹清晰呈现了该领域的演进逻辑:从CLIPort、Gato、RT-1、VIMA等早期模块化系统,经由ACT、RT-2、VoxPoser、Octo等支持推理与泛化的中间代模型,**发展至Deer-VLA、ReVLA、Quar-VLA、RoboMamba等专业化架构,最终迈向SafeVLA、Humanoid-VLA、Gr00t N1等强调安全、泛化与具身智能的通用智能体。**这一历程标志着VLA模型已从任务特定的感知-动作映射,逐步演进为具备强泛化能力、可安全部署、深度融入物理与社会环境的通用具身智能系统。
2.2 多模态融合:从孤立流水线到统一智能体
VLA模型的核心突破在于其多模态融合能力——即在统一架构中联合处理视觉、语言与动作。传统机器人系统将感知、自然语言理解与控制视为彼此隔离的模块,通常依赖人工设计的接口或数据转换规则进行串联 [109, 20, 168]。例如,经典流水线框架需先由感知模块输出符号化标签,再由规划器将其映射为具体动作,该过程往往依赖领域特定的手工工程 [138, 90]。此类方法适应性差,在模糊或新异环境中易失效,且无法泛化至预设模板之外的指令。
相比之下,**现代VLA模型借助大规模预训练编码器与基于Transformer的架构,实现端到端的多模态融合 [188]。**视觉与语言信息在共享的计算空间中被联合表征,从而支持灵活、上下文感知的推理 [99]。以指令“拿起那个成熟红色的苹果”为例(见图5):视觉编码器(通常为ViT或ConvNeXt)对场景中的物体(如苹果、树叶、背景)进行分割与分类,并提取颜色与成熟度等属性 [187];语言模型(如T5、GPT或BERT变体)则将指令编码为高维嵌入。二者通过交叉注意力或联合令牌化机制融合,形成统一的隐空间,直接驱动动作策略 [68]。
这一多模态协同机制最早在CLIPort [157] 中得以有效实现:其利用CLIP嵌入进行语义接地,并通过卷积解码器实现像素级操作,无需显式语言解析即可将自然语言直接用于条件化视觉-动作策略。VIMA [86] 进一步采用Transformer编码器联合处理以物体为中心的视觉令牌与指令令牌,显著提升了空间推理任务中的小样本泛化能力。
近期研究更将融合拓展至时空维度:VoxPoser [78] 通过体素级推理解决3D对象选择中的歧义;RT-2 [224] 将视觉-语言令牌统一于单一Transformer中,支持对未见指令的零样本泛化;Octo [167] 则引入记忆增强型Transformer,实现跨场景的长时程决策,彰显了感知-语言-动作联合学习的可扩展性。
尤为重要的是,VLA为现实世界中的语义接地难题提供了鲁棒解决方案。例如,Occllama [183] 利用注意力机制处理被遮挡物体的指代,ShowUI [108] 则通过自然语言接口使非专业用户可通过语音或文本指令操控智能体。这些能力之所以可能,正源于其融合机制不仅停留在表层特征拼接,而是实现了跨模态在语义、空间与时间维度上的深度对齐。
**2.3 令牌化(Token)与表征:VLA如何编码世界
VLA模型区别于传统视觉-语言架构的核心创新在于其基于令牌(token)的统一表征框架,该框架支持对感知、语言与物理动作空间的整体性推理 [125, 215, 106]。受自回归生成模型(如Transformer)启发,现代VLA将视觉、语言、状态与动作统一编码为离散令牌,嵌入共享的隐空间 [110],从而不仅理解“做什么”(语义推理),还能生成“如何做”(控制策略),且具备可学习性与组合性 [192, 117, 170]。
-
前缀令牌(Prefix Tokens):编码上下文与指令
前缀令牌构成VLA的语境主干 [195, 83],将环境视觉输入(如图像/视频)与自然语言指令分别通过视觉编码器(如ViT、ConvNeXt)和语言模型(如T5、LLaMA)转化为紧凑嵌入,共同初始化模型对任务目标与场景布局的理解(见图7)。例如,在“将绿色积木叠到红色托盘上”任务中,该联合表征支持跨模态语义接地,使系统能准确解析空间指代(如“左边”、“蓝杯旁”)与对象语义(如“绿色积木”)。 -
状态令牌(State Tokens):嵌入机器人本体配置
除感知外部环境外,VLA还需感知自身状态。状态令牌编码机器人实时本体信息——如关节角度、末端位姿、夹爪状态、力/力矩及邻近物体位置 [186, 111, 97],对操作安全与情境感知至关重要 [163, 81]。如图8a所示,在机械臂靠近易碎物体时,状态令牌提供本体感知反馈,使模型能预判碰撞并调整轨迹或力输出;在移动机器人中(图8b),状态令牌融合里程计、LiDAR与惯性数据,支持地形自适应导航与避障。状态令牌与前缀令牌持续融合,使自回归解码器能生成兼顾内外状态的精准动作序列。 -
动作令牌(Action Tokens):自回归控制生成
动作令牌是VLA输出层的核心 [93, 94],由模型自回归生成,表征下一控制步。每个令牌对应低层控制信号(如关节角、扭矩、轮速)或高层动作基元 [64]。推理时,模型以前缀令牌与状态令牌为条件,逐步预测动作令牌,将VLA转化为“语言驱动的策略生成器” [54, 161]。该设计天然支持变长动作序列 [10, 77],并可结合模仿学习或强化学习进行微调 [214]。RT-2 [224] 与 PaLM-E [47] 即为典型:感知、指令与具身状态被统一为单一令牌流,实现端到端动作生成。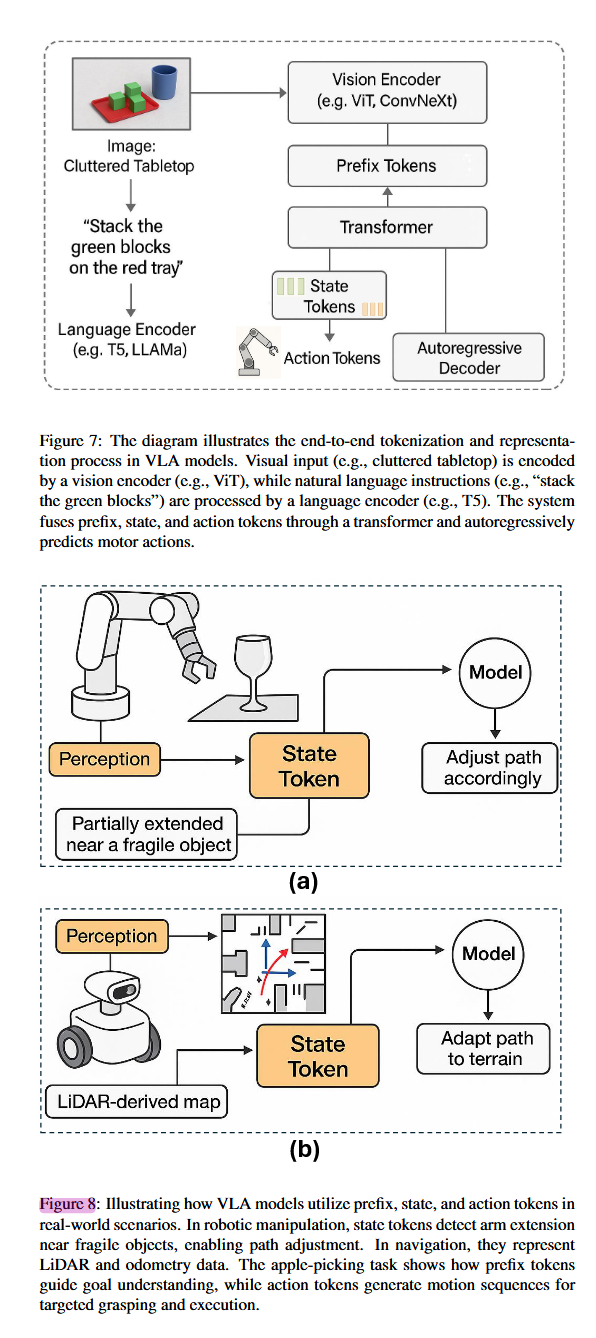
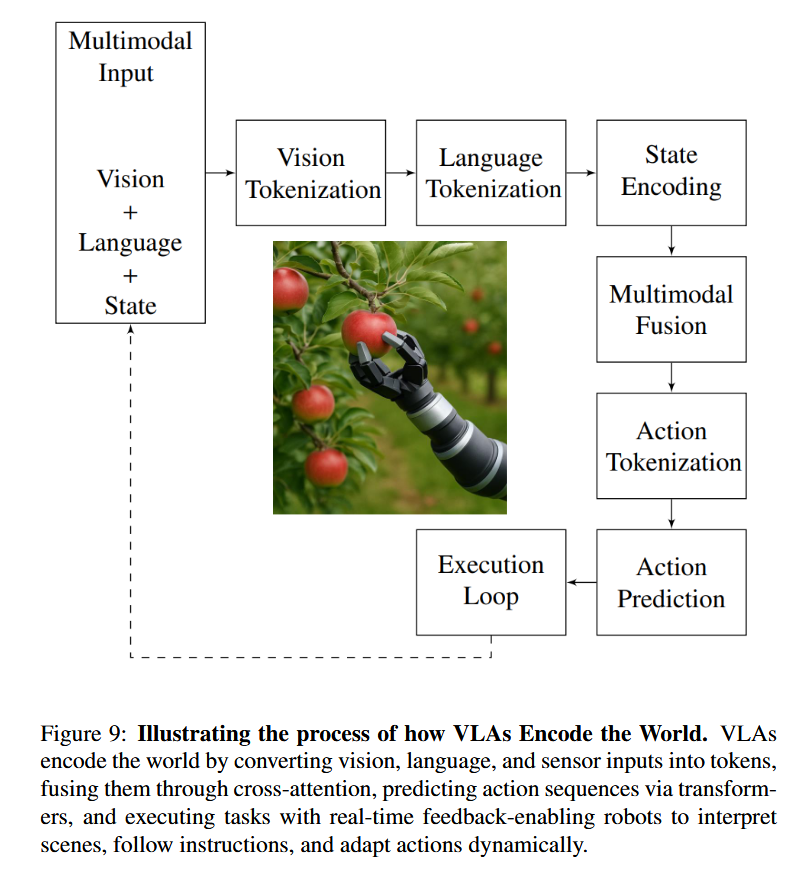
如图9所示,VLA通过端到端令牌化管道实现世界编码:
- 多模态输入:采集RGB-D图像、自然语言指令与本体状态(如关节角);
- 独立令牌化:ViT生成视觉令牌(如400个),BERT/T5生成语言令牌(如12个),MLP编码状态为64维嵌入;
- 跨模态融合:通过交叉注意力机制联合推理对象语义、空间布局与物理约束,形成512维融合表征;
- 动作生成:自回归Transformer解码器(如FAST [133])输出50个动作令牌,经反令牌化转换为电机指令序列。
该闭环机制使机器人能动态适应扰动、物体位移或遮挡 [206, 120, 194]。其本质是将物理动作生成类比为自然语言生成——“句子”即运动轨迹。如算法1与伪代码所示,该架构模块清晰、可扩展,支持跨任务、跨形态泛化,适用于采摘、家务、导航等真实场景,并为未来研究(如分层规划、符号接地)提供基础。
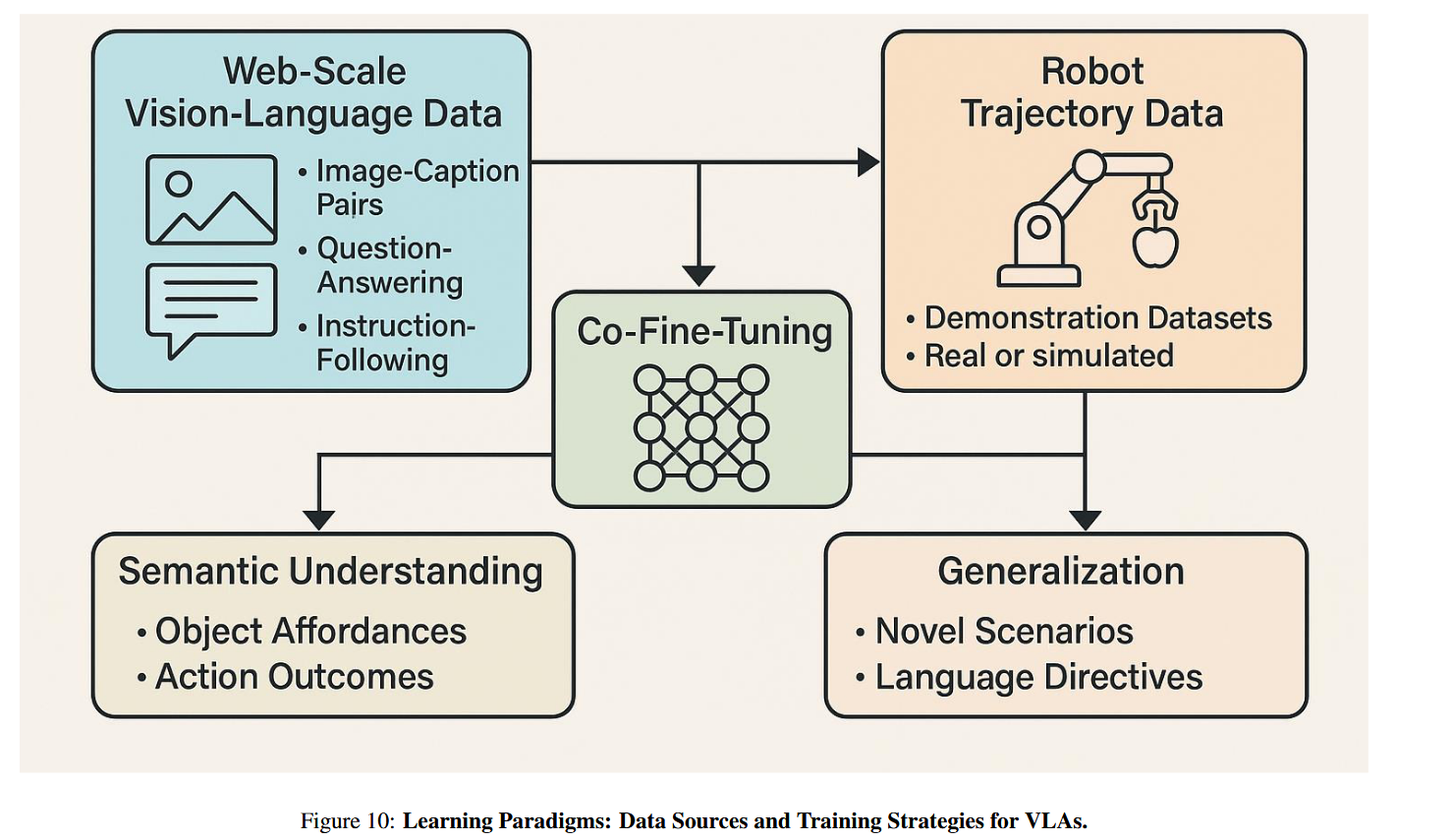
2.4 学习范式:数据来源与训练策略
VLA训练依赖混合学习范式,融合互联网语义知识与机器人任务数据(见图10):
- 语义预训练:利用大规模网络数据(如LAION400M、HowTo100M、VQA)预训练视觉-语言编码器,通过CLIP式对比学习或掩码建模对齐模态 [146, 199],赋予模型世界常识,支撑组合泛化、零样本迁移与对象接地 [28, 15]。
- 具身微调:在机器人轨迹数据集(如RoboNet、BridgeData、RT-X)上微调策略解码器,通过行为克隆、模仿学习或强化学习 [55, 65],将语言-视觉表征映射为动作令牌,实现语义到动作的接地 [178]。
近期工作多采用多阶段训练:先在视觉-语言数据上预训练,再在机器人演示数据上以自回归损失微调 [94, 221];或引入课程学习 [217]、域自适应(如OpenVLA [94])及sim-to-real迁移 [96],弥合仿真与现实差距。通过协同微调,模型不仅学习对象可操作性(如“苹果可抓取”)与动作结果(如“提举需力与轨迹”),还能泛化至新场景——例如将厨房操作经验迁移至果园采摘。
以RT-2 [224] 为例,其将动作生成视为文本生成,动作令牌对应离散控制指令。得益于网络规模多模态数据 + 千级机器人演示的联合训练,该模型可灵活解析新指令并实现对未见物体/任务的零样本执行,远超传统控制或早期多模态系统。
2.5 自适应控制与实时执行
VLA的另一优势在于实时自适应控制:通过传感器反馈动态调整行为 [153]。在果园、家庭或医院等非结构化环境中,风动、光照变化或人员介入常导致任务参数偏移。此时,状态令牌实时更新,驱动模型重规划动作。例如,若目标苹果位移或视野中出现干扰物,VLA可即时重解释场景并调整抓取轨迹。这种类人适应能力,是VLA超越传统流水线机器人系统的关键优势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)