AI 驱动的报表系统:从传统到智能的落地与演进
大模型规模化落地时代,传统报表如何低成本升级 AI 报表?从技术选型、3 大核心场景落地到工程化部署,附完整代码与开源 / 大厂方案盘点,报表开发者零 AI 经验也能快速上手!
摘要
本文基于《报表系统的那些事:四部演进史》的基础架构,聚焦当下大模型规模化落地背景,探讨报表系统智能升级路径。通过对比传统报表与 AI 报表核心差异,明确其 “自然语言交互、智能异常检测、动态指标推荐” 优势;详解新手友好的技术栈选型、三大核心场景落地思路与关键代码,以及工程化架构设计与动态管理方案;同时盘点热门开源项目与大厂布局,展望多模态等未来趋势,为传统报表开发者提供低成本、易落地的从 0 到 1 AI 拓展指南。
一、引言:报表系统的 AI 变革
1. AI 报表新机遇
基于《报表系统的那些事:四部演进史》中构建的 “手工定制→配置化→商业集成→混合计算” 基础架构,当下大模型应用开发爆发式增长,为报表系统带来了革命性的落地场景。传统报表系统长期困于 “被动响应需求、操作门槛高、价值密度低” 的瓶颈,而 AI 技术(尤其是大模型与轻量化算法)的融入,让报表系统从 “数据展示工具” 升级为 “智能决策助手” 成为可能 —— 无需复杂配置,无需精通 SQL,业务人员即可通过自然语言获取精准报表、发现数据异常、获得决策建议,这正是报表系统在 AI 时代的核心机遇。
2. 传统报表 vs AI 报表:核心差异
|
维度 |
传统报表 |
AI 报表(智能拓展后) |
|
交互方式 |
手动选维度 / 指标、编写 SQL |
自然语言提问,自动解析意图生成报表 |
|
异常处理 |
人工排查数据异常,依赖经验判断 |
系统自动识别异常,生成根因分析与解决方案 |
|
指标配置 |
人工梳理业务需求,手动添加指标 |
智能推荐高价值指标,适配业务场景 |
|
落地逻辑 |
依赖开发人员编码实现,响应周期长 |
插件化集成 AI 能力,复用现有架构 |
|
价值输出 |
提供数据展示,需人工解读价值 |
主动输出洞察,支撑直接决策 |
二、AI 报表核心技术栈选型
AI 报表无需颠覆传统报表技术栈,核心是 “复用现有底座 + 集成 AI 能力”,选型遵循 “新手友好、成熟稳定、低成本落地” 原则:
|
技术类型 |
核心选型(新手优先) |
核心作用 |
学习成本 |
|
大模型调用 |
Spring AI(统一封装)+ 通用大模型 API(通义千问 / 文心一言) |
自然语言转意图、生成 SQL、解释数据洞察 |
低(会调用接口即可) |
|
轻量化算法 |
规则引擎 + 基础统计算法(3σ 原则、关联规则) |
异常检测、指标推荐、数据合法性校验 |
中(理解逻辑即可复用) |
|
数据存储 / 计算 |
复用传统报表的 ClickHouse/Spark/MySQL |
承载报表数据存储与批量计算,无需重构 |
无 |
|
工程化支撑 |
插件化框架(如 Spring Boot Starter)+ 配置中心(Apollo) |
独立部署 AI 能力,动态调整参数 |
低(复用报表现有工程化体系) |
|
可视化支撑 |
复用传统报表的 ECharts/Tableau |
承接 AI 生成的报表数据,自动适配图表类型 |
无 |
三、AI 报表核心场景落地
每个场景围绕 “传统报表痛点→AI 解决思路→步骤拆解→关键代码片段” 展开,代码聚焦核心逻辑:
3.1 场景 1:自然语言生成报表(最易落地)
核心思想
用大模型解决 “业务人员不会 SQL” 的痛点,通过 “自然语言→结构化意图→SQL 生成→报表渲染” 的闭环,实现报表自助生成,复用传统报表的 SQL 执行与可视化能力。
步骤拆解
- 接收用户自然语言需求(如 “查 2025 年 10 月渠道 A 的佣金总额”);
- 大模型解析需求为结构化意图(指标、维度、筛选条件、时间范围);
- 简单规则校验意图合法性(避免无效指标 / 维度);
- 大模型基于意图生成合规 SQL;
- 复用传统报表的 SQL 执行逻辑,获取数据;
- 自动推荐可视化类型,渲染最终报表。
关键代码片段
@Service
public class Nl2ReportService {
// Spring AI统一大模型客户端(新手只需配置API Key)
private final AiClient aiClient;
// 复用传统报表的SQL执行工具
private final ReportSqlExecutor sqlExecutor;
public ReportResult generate(String naturalLanguage) {
try {
// 步骤1:大模型解析自然语言为结构化意图
String intentPrompt = """
请将报表需求转为JSON,仅返回JSON(无多余内容):
{
"metrics": ["指标名"],
"dimensions": ["维度名"],
"filters": ["筛选条件"],
"dateRange": {"start": "开始日期", "end": "结束日期"}
}
需求:%s
""".formatted(naturalLanguage);
String intentJson = aiClient.generate(intentPrompt);
NlIntent intent = JsonUtils.parseObject(intentJson, NlIntent.class);
// 步骤2:合法性校验(新手可手动维护支持的指标/维度)
if (!validateIntent(intent)) {
return ReportResult.fail("不支持的指标或维度");
}
// 步骤3:大模型生成SQL(固定表结构,降低难度)
String sqlPrompt = """
基于意图生成ClickHouse查询SQL,仅返回SQL:
表名:commission_detail
字段:commission_amount(佣金金额)、channel_id(渠道)、create_date(日期)
意图:%s
""".formatted(intentJson);
String sql = aiClient.generate(sqlPrompt);
// 步骤4:复用传统报表执行SQL
List<Map<String, Object>> data = sqlExecutor.execute(sql);
// 步骤5:自动推荐可视化(简单规则判断)
String visualType = recommendVisual(intent);
return ReportResult.success(data, sql, visualType);
} catch (Exception e) {
// 兜底:AI生成失败转人工处理
return ReportResult.fail("生成失败,请联系数据人员:" + e.getMessage());
}
}
// 简单规则校验(新手可直接扩展)
private boolean validateIntent(NlIntent intent) {
List<String> validMetrics = List.of("佣金总额", "订单数", "客单价");
List<String> validDimensions = List.of("渠道", "日期", "商品品类");
// 校验指标合法性
return intent.getMetrics().stream().allMatch(validMetrics::contains)
&& intent.getDimensions().stream().allMatch(validDimensions::contains);
}
// 可视化推荐规则(新手友好)
private String recommendVisual(NlIntent intent) {
if (intent.getDimensions().contains("日期")) return "折线图";
if (intent.getMetrics().size() == 1 && intent.getDimensions().isEmpty()) return "饼图";
return "柱状图";
}
// 意图实体类(新手可直接复制)
@Data
static class NlIntent {
private List<String> metrics;
private List<String> dimensions;
private List<String> filters;
private Map<String, String> dateRange;
}
}3.2 场景 2:异常数据智能提醒
核心思想
用 “简单统计算法 + 大模型” 解决 “人工排查异常效率低” 的痛点,通过 3σ 原则自动识别偏离正常范围的数据,再用大模型生成易懂的异常说明与处理建议,主动推送相关人员。
步骤拆解
- 定时提取传统报表中核心指标的历史数据(如近 30 天日佣金);
- 用 3σ 原则计算数据正常范围,识别异常值;
- 触发异常后,调用大模型生成自然语言说明(现象 + 推测 + 建议);
- 复用传统报表的消息推送能力(钉钉 / 企业微信)。
关键代码片段
@Service
public class AnomalyReminderService {
// 复用传统报表的指标数据查询能力
private final MetricRepository metricRepo;
private final AiClient aiClient;
// 复用传统报表的消息推送服务
private final MessagePushService pushService;
// 定时任务(每天9点检查昨日数据)
@Scheduled(cron = "0 0 9 * * ?")
public void checkAnomaly() {
// 步骤1:查询近30天核心指标数据
List<Double> last30DaysData = metricRepo.queryLast30Days("佣金总额");
double yesterdayData = last30DaysData.get(last30DaysData.size() - 1);
// 步骤2:3σ原则识别异常(新手可直接复用)
if (isAnomaly(last30DaysData, yesterdayData)) {
// 步骤3:大模型生成异常说明
String prompt = """
昨日佣金总额:%.2f元,偏离近30天正常范围。
请生成100字内提醒文案:含现象、初步推测、处理建议。
""".formatted(yesterdayData);
String reminder = aiClient.generate(prompt);
// 步骤4:推送提醒
pushService.push("运营组", "数据异常提醒", reminder);
}
}
// 3σ异常检测核心逻辑
private boolean isAnomaly(List<Double> dataList, double target) {
double avg = dataList.stream().mapToDouble(Double::doubleValue).average().orElse(0);
double std = calculateStd(dataList, avg);
// 超出[avg-3*std, avg+3*std]即为异常
return target < (avg - 3 * std) || target > (avg + 3 * std);
}
// 标准差计算(新手可直接复制)
private double calculateStd(List<Double> dataList, double avg) {
double sum = dataList.stream().mapToDouble(d -> Math.pow(d - avg, 2)).sum();
return Math.sqrt(sum / dataList.size());
}
}3.3 场景 3:智能指标推荐
核心思想
用 “关联规则” 解决 “业务人员遗漏高价值指标” 的痛点,基于用户常用指标与预设的指标关联关系,自动推荐相关指标,减少人工配置成本。
步骤拆解
- 查询用户历史常用指标(复用传统报表的用户行为日志);
- 基于预设的关联规则,匹配推荐指标;
- 去重并排除用户已选指标,返回 Top3 推荐结果。
关键代码片段
@Service
public class MetricRecommendService {
// 复用传统报表的用户行为数据
private final UserBehaviorRepository behaviorRepo;
public List<String> recommend(String userId, List<String> selectedMetrics) {
// 步骤1:查询用户常用指标
List<String> commonMetrics = behaviorRepo.queryCommonMetrics(userId);
// 步骤2:预设指标关联规则(新手可手动扩展)
Map<String, List<String>> relationMap = new HashMap<>();
relationMap.put("佣金总额", List.of("佣金率", "有效订单数"));
relationMap.put("订单数", List.of("客单价", "转化率"));
relationMap.put("商品销量", List.of("库存周转率", "复购率"));
// 步骤3:生成推荐列表(去重+排除已选)
return commonMetrics.stream()
.flatMap(metric -> relationMap.getOrDefault(metric, List.of()).stream())
.distinct()
.filter(metric -> !selectedMetrics.contains(metric))
.limit(3)
.collect(Collectors.toList());
}
}四、AI 报表工程化落地
4.1 架构设计:插件化集成(不重构传统系统)
核心原则:AI 能力作为独立插件接入,复用传统报表的核心底座(数据存储、计算、可视化),避免大规模重构。
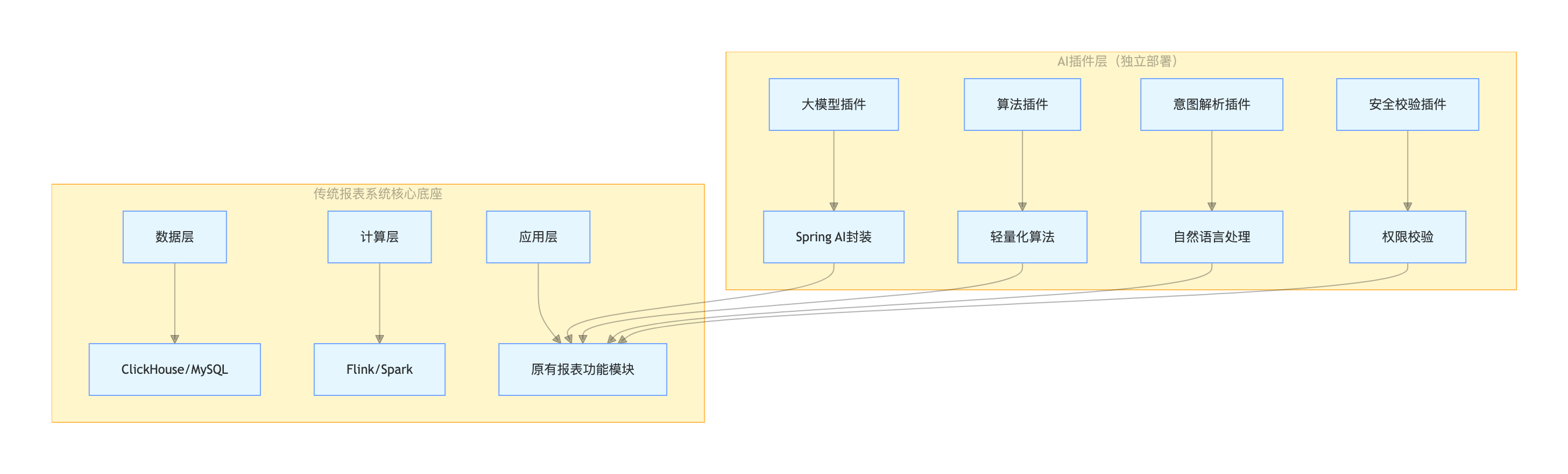
4.2 落地步骤(按难度排序)
- 基础准备:集成 Spring AI,配置大模型 API Key,打通与传统报表的 SQL 执行接口;
- 场景落地:先落地 “自然语言生成报表”,再逐步实现 “异常提醒”“指标推荐”;
- 安全加固:添加 SQL 权限校验、敏感数据脱敏、AI 生成结果兜底机制;
- 迭代优化:基于业务反馈调整大模型 Prompt、异常阈值、指标关联规则。
4.3 关键保障措施
- 安全防护:AI 生成的 SQL 需经过权限校验(仅允许查询)、敏感字段过滤(如手机号脱敏);
- 性能优化:缓存高频 SQL 生成结果与指标推荐列表,降低大模型调用频率;
- 监控告警:监控大模型调用成功率、SQL 生成准确率、异常检测误报率,设置阈值告警;
- 灰度发布:先对内部用户开放 AI 功能,验证稳定后再推广至全业务线。
4.4 算法升级路径(从简单到复杂)
随着业务场景深化,可逐步将 “新手友好的规则 / 统计算法” 升级为 “更精准的机器学习算法”,以下是分阶段升级对比:
|
应用场景 |
初期方案(新手落地) |
升级方案(进阶优化) |
升级价值 |
落地条件 |
|
异常检测 |
3σ 原则(基于统计分布) |
孤立森林 / LOF 算法(无监督学习) |
降低误报率,适配非正态分布数据 |
积累足够历史数据(≥3 个月)、具备 Python 算法开发能力 |
|
指标推荐 |
手动配置关联规则 |
协同过滤 + 互信息算法 |
推荐更精准,适配用户个性化需求 |
积累用户行为数据(≥1 万条)、搭建算法服务框架 |
|
可视化推荐 |
固定规则判断(日期→折线图等) |
决策树分类算法(预训练模型) |
适配复杂数据场景(多指标 + 多维度) |
覆盖≥20 种报表场景、具备模型训练能力 |
升级落地建议
- 初期:优先用 “规则 / 统计” 算法快速验证场景价值,不追求技术先进性;
- 中期:当数据量、用户量达到阈值后,将核心场景算法封装为独立 Python 服务,通过 API 对接报表系统;
- 长期:搭建算法迭代平台,支持模型训练、部署、监控全流程自动化。
4.5 动态管理:告别 “固定表 / 指标 / 维度”
第三章中为降低新手落地难度,采用了 “固定表结构、固定指标、固定维度” 的方式,工程化落地阶段可通过以下方案实现 “智能动态管理”,适配业务变化:
4.5.1 核心思路
搭建 “元数据管理中心”,统一维护表结构、指标、维度的元信息,通过大模型 + 规则联动,实现 “元数据自动识别、动态适配”。
4.5.2 具体实现方案
|
管理对象 |
动态管理方式 |
关键技术 / 工具 |
落地效果 |
|
表结构(表名 / 字段) |
元数据自动采集 + 向量检索匹配 |
数据库元数据采集工具(如 Flink CDC)、Milvus 向量库 |
新增表后自动同步元数据,大模型可识别新表字段 |
|
指标(名称 / 计算逻辑) |
指标字典配置 + 大模型语义理解 |
Apollo 配置中心、大模型 Prompt 工程 |
新增指标后无需修改代码,大模型可解析指标含义 |
|
维度(分类 / 属性值) |
维度分层管理 + 关联规则自动学习 |
维度建模工具、关联规则挖掘算法 |
支持维度动态新增,自动适配报表生成逻辑 |
4.5.3 关键代码片段(元数据动态适配)
@Service
public class MetaDataDynamicService {
// 元数据管理中心客户端(对接Apollo+向量库)
private final MetaDataClient metaDataClient;
private final AiClient aiClient;
// 动态校验指标/维度合法性(替代固定规则)
public boolean validateDynamicIntent(NlIntent intent) {
// 步骤1:从元数据中心获取所有有效指标/维度
List<String> validMetrics = metaDataClient.queryAllMetrics();
List<String> validDimensions = metaDataClient.queryAllDimensions();
// 步骤2:大模型语义匹配(处理用户输入的同义表述,如“佣金”→“佣金总额”)
List<String> matchedMetrics = matchSemantic(intent.getMetrics(), validMetrics);
List<String> matchedDimensions = matchSemantic(intent.getDimensions(), validDimensions);
// 步骤3:更新意图为匹配后的标准名称
intent.setMetrics(matchedMetrics);
intent.setDimensions(matchedDimensions);
// 步骤4:校验是否存在无效项
return matchedMetrics.size() == intent.getMetrics().size()
&& matchedDimensions.size() == intent.getDimensions().size();
}
// 大模型语义匹配(解决用户输入不标准问题)
private List<String> matchSemantic(List<String> userInputs, List<String> standardList) {
String prompt = String.format("""
请将用户输入的指标/维度匹配到标准列表,无法匹配的返回空:
用户输入:%s
标准列表:%s
输出格式:匹配后的标准名称列表(逗号分隔)
""",
String.join(",", userInputs),
String.join(",", standardList)
);
String response = aiClient.generate(prompt);
return Arrays.stream(response.split(","))
.map(String::trim)
.filter(s -> !s.isEmpty())
.collect(Collectors.toList());
}
// 动态生成SQL(适配新增表/指标/维度)
public String generateDynamicSql(NlIntent intent) {
// 从元数据中心获取表-字段-指标/维度关联关系
Map<String, Map<String, List<String>>> tableMetricDimMap = metaDataClient.queryTableMetricDimRelation();
String prompt = String.format("""
基于以下信息生成ClickHouse SQL,仅返回SQL:
表-指标-维度关联关系:%s
报表意图(指标+维度+筛选条件):%s
要求:自动选择匹配的表和字段,支持多表关联
""",
JsonUtils.toJson(tableMetricDimMap),
JsonUtils.toJson(intent)
);
return aiClient.generate(prompt);
}
}4.5.4 落地价值
- 业务侧:新增表、指标、维度后,无需开发介入,业务人员可直接通过自然语言调用;
- 开发侧:告别硬编码的表结构、指标列表,减少重复开发与维护成本;
- 系统侧:适配业务快速迭代,提升 AI 报表的灵活性与扩展性。
五、当下 AI 驱动下的报表系统热门盘点
5.1 热门开源项目
当前大模型应用爆发后,开源社区涌现出多款聚焦 AI 报表落地的工具,核心围绕 “降低开发门槛、适配大模型集成” 展开:
|
开源项目名称 |
核心定位 |
核心 AI 能力 |
优势亮点 |
适用场景 |
|
DataAgent(Spring AI Alibaba) |
通用 NL2SQL 工具 |
Schema 匹配、多表关联 SQL 生成、SQL 语法校验 |
适配多数据库、与 Spring 生态无缝集成 |
Java 技术栈企业、需快速集成 NL2SQL 场景 |
|
JimuReport(积木报表) |
免费可视化 AI 报表工具 |
AI 报表生成优化、拖拽式设计 + AI 辅助配置 |
永久免费、类 Excel 操作、多端适配(大屏 / 移动端) |
中小团队、快速搭建可视化 AI 报表 |
|
Smartbi OpenAPI 版 |
企业级 AI+BI 开源框架 |
Agent 协作分析、指标语义底座、RAG 增强 |
信创兼容、行业方案丰富、支持二次开发 |
央国企、金融行业、需定制化 AI 报表场景 |
|
FineReport 开源模块 |
传统 BI+AI 拓展工具 |
大模型 API 对接、智能预警、预测分析集成 |
生态成熟、可视化能力强、文档完善 |
已有传统 BI 基础、需增量 AI 拓展场景 |
5.2 大厂 AI 报表布局
当前大模型应用开发爆发后,大厂纷纷将 AI 报表作为核心落地场景,或自用赋能内部业务,或封装为服务对外售卖:
|
大厂 / 平台 |
产品 / 服务名称 |
核心定位 |
落地模式(自用 / 售卖) |
核心 AI 能力亮点 |
|
阿里系 |
阿里云 DataWorks AI 报表模块 |
企业级数据开发 + AI 报表一体化平台 |
对外售卖 |
集成通义千问、智能数据清洗、多模态报表输出、跨系统联动 |
|
字节跳动 |
火山引擎 Data Agent |
实时计算 + AI 分析一体化报表工具 |
对外售卖 + 内部自用 |
依托字节实时技术,支持秒级异常检测、多智能体协作分析、原生对接火山大模型 |
|
思迈特软件 |
Smartbi AIChat 白泽 |
Agent BI 先行者,智能决策报表平台 |
对外售卖 |
指标驱动语义底座、多智能体协作、60 + 行业场景化方案、全栈国产化适配 |
|
帆软 |
FineBI AI 增强版 |
传统 BI 升级 AI 的轻量化解决方案 |
对外售卖 |
Excel 深度集成、零代码 AI 配置、生态模板丰富、支持自定义大模型接入 |
|
腾讯云 |
智能报表助手(Tencent Cloud BI) |
低代码 AI 报表平台 |
对外售卖 + 内部自用 |
文心一言深度融合、语音生成报表、企业微信无缝推送、轻量化预测分析 |
|
华为云 |
华为云智能 BI 报表 |
信创体系下 AI 报表解决方案 |
对外售卖 + 政企合作 |
鲲鹏芯片适配、盘古大模型赋能、数据安全合规强化、国产化生态兼容 |
六、AI 报表未来趋势与扩展场景
- 多模态报表生成:结合文本、图表、语音、视频,生成多模态报表(如语音播报报表结论)
- 跨系统智能联动:报表 AI 与业务系统联动(如发现销量下滑,自动触发营销系统推送优惠券)
- 自助式 AI 报表平台:非技术用户通过拖拽配置,自定义 AI 报表场景(如自定义异常监控规则)
- 大模型原生报表架构:基于大模型重构报表系统,实现 “自然语言交互 + 自动数据处理 + 智能可视化” 全流程
七、总结
大模型应用的爆发式增长,让 AI 报表从 “概念” 走向 “规模化落地”—— 对报表开发者而言,无需从零学习 AI 技术,核心是 “识别报表痛点,选择合适的 AI 能力,以低成本、低侵入的方式落地”。
从开源工具的轻量化集成到大厂的商业化布局,AI 报表的核心价值始终是 “解决实际问题” 而非技术堆砌。当下的 AI 报表不需要复杂的算法与架构,关键是 “复用现有经验、插件化集成、小场景落地”;未来的 AI 报表,将通过多模态、预测性、跨系统联动等细分场景的深化,从 “被动响应需求” 走向 “主动创造价值”,成为企业数字化决策的核心支撑。
对报表开发者来说,AI 不是颠覆,而是在现有经验基础上的自然拓展 —— 抓住 “解决痛点、低成本落地、持续迭代” 的核心,就能在 AI 时代让报表系统焕发新的价值。
📚 我的技术博客导航:[点击进入一站式查看所有干货]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)