MYSQL的学习
核心作用:定义 / 修改 / 删除数据库对象(表、索引、视图、触发器、数据库等)的结构,操作会直接生效(无需事务提交)。核心关键字CREATE(创建)、ALTER(修改)、DROP(删除)、TRUNCATE(清空表,属于 DDL 而非 DML)、RENAME(重命名)。执行后通常需要COMMIT(提交)确认修改,或ROLLBACK(回滚)撤销修改(事务控制)。-- 创建用户表age INT,--
mysql的分类
mysql在其内部根据功能的不同分为不同的语言
一、数据查询语言(DQL, Data Query Language)
核心作用:从数据库中查询 / 检索数据(仅读取,不修改数据),是最常用的 SQL 类别。
核心关键字:SELECT(核心)、FROM、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT、JOIN 等。
-- 查询年龄大于20的用户姓名和手机号,按年龄降序排列
SELECT name, phone
FROM users
WHERE age > 20
ORDER BY age DESC
-- LIMIT 10;二、数据操作语言(DML, Data Manipulation Language)
核心作用:操作(增 / 删 / 改)数据库中的数据(仅修改数据内容,不改变表结构)。
核心关键字:INSERT(新增)、UPDATE(修改)、DELETE(删除)、MERGE(合并,部分数据库支持)。
-- 新增一条用户记录
INSERT INTO users (name, age, phone) VALUES ('张三', 25, '13800138000');
-- 修改用户手机号
UPDATE users SET phone = '13900139000' WHERE id = 1;
-- 删除年龄小于18的用户
DELETE FROM users WHERE age < 18;三、数据定义语言(DDL, Data Definition Language)
核心作用:定义 / 修改 / 删除数据库对象(表、索引、视图、触发器、数据库等)的结构,操作会直接生效(无需事务提交)。
核心关键字:CREATE(创建)、ALTER(修改)、DROP(删除)、TRUNCATE(清空表,属于 DDL 而非 DML)、RENAME(重命名)。
执行后通常需要
COMMIT(提交)确认修改,或ROLLBACK(回滚)撤销修改(事务控制)。
-- 创建用户表
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT,
phone VARCHAR(20) UNIQUE
);
-- 给用户表新增email字段
ALTER TABLE users ADD COLUMN email VARCHAR(100);
-- 删除用户表
DROP TABLE users;
-- 清空用户表(删除所有数据且不可回滚)
-- TRUNCATE TABLE users;四、数据控制语言(DCL, Data Control Language)
核心作用:管理数据库的权限和事务,控制用户对数据库的访问权限、事务提交 / 回滚等。
核心关键字:GRANT(授权)、REVOKE(撤销权限)、COMMIT(提交事务)、ROLLBACK(回滚事务)、SAVEPOINT(保存点)、SET TRANSACTION(设置事务属性)。
-- 授予用户test对users表的查询/插入权限
GRANT SELECT, INSERT ON users TO 'test'@'localhost';
-- 撤销test用户的插入权限
REVOKE INSERT ON users FROM 'test'@'localhost';
-- 提交事务(确认DML操作)
COMMIT;
-- 回滚事务(撤销未提交的DML操作)
ROLLBACK;五、事务控制语言(TCL, Transaction Control Language)
补充说明:部分分类体系中,TCL 会从 DCL 中独立出来,专门聚焦事务管理(本质是 DCL 的子集)。
核心关键字:COMMIT、ROLLBACK、SAVEPOINT。
-- 开启事务(部分数据库需显式声明)
START TRANSACTION;
UPDATE users SET age = 26 WHERE id = 1;
-- 设置保存点
SAVEPOINT sp1;
DELETE FROM users WHERE id = 2;
-- 回滚到保存点(仅撤销删除操作,修改操作保留)
ROLLBACK TO sp1;
-- 提交最终修改
COMMIT;核心总结表
| 分类 | 核心作用 | 核心关键字 | 典型操作 |
|---|---|---|---|
| DQL | 查询数据 | SELECT、FROM、WHERE | 多表查询、统计 |
| DML | 增删改数据 | INSERT、UPDATE、DELETE | 新增记录、改值 |
| DDL | 定义 / 修改数据库结构 | CREATE、ALTER、DROP | 建表、删索引 |
| DCL | 权限 / 事务控制(广义) | GRANT、REVOKE、COMMIT | 授权、提交事务 |
| TCL | 事务控制(狭义) | COMMIT、ROLLBACK、SAVEPOINT | 回滚、保存点 |
表的创建
在mysql中一切数据都是基于表存在的,我们需要搭建框架才能将数据容纳进去。
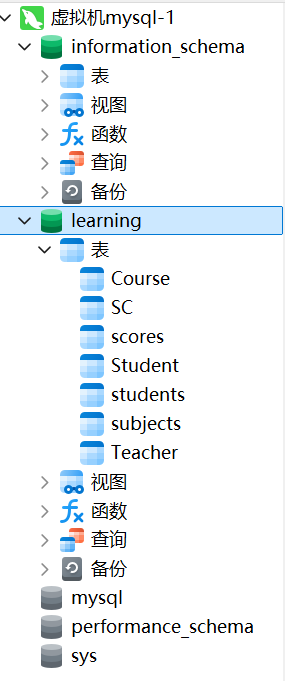
注意,学习或者工作时要创建新的数据库,不要放在默认数据库内。
Navicat中创建(逐行创建表头,包含了名称,数据类型等)
CREATE TABLE `students` (
`stu_id` bigint(10) DEFAULT NULL COMMENT '学生学号',
`stu_name` varchar(255) DEFAULT NULL COMMENT '学生姓名',
`gender` varchar(255) DEFAULT NULL COMMENT '学生性别',
`age` int(10) DEFAULT NULL COMMENT '学生年龄',
`major` varchar(255) DEFAULT NULL COMMENT '学生专业',
`clazz` varchar(255) DEFAULT NULL COMMENT '学生班级',
`year` bigint(20) DEFAULT NULL COMMENT '入学年份'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;命令行中创建
CREATE TABLE `scores` (
`stu_id` bigint(10) DEFAULT NULL COMMENT '学生学号',
`subject_id` int(10) DEFAULT NULL COMMENT '科目编号',
`score` int(10) DEFAULT NULL COMMENT '考试分数',
`type` varchar(255) DEFAULT NULL COMMENT '考试类型'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `scores` (
`stu_id` bigint(10) DEFAULT NULL COMMENT '学生学号',
`subject_id` int(10) DEFAULT NULL COMMENT '科目编号',
`score` int(10) DEFAULT NULL COMMENT '考试分数',
`type` varchar(255) DEFAULT NULL COMMENT '考试类型'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;导入数据
Navicat导入向导
插入单条数据
insert into students values(20250101,'张三','男',20,'计算机科学与技术','计科2501',2025);多行数据插入
insert into students(id,name,gender,age,major,clazz,year) values(20250101,'张三','男',20,'计算机科学与技术','计科2501',2025)
,(20250102,'李四','女',20,'计算机科学与技术','计科2501',2025)
,(20250103,'王五','男',19,'计算机科学与技术','计科2501',2025)
,(20250201,'赵六','女',20,'软件工程','软工2502',2025)
,(20250202,'孙七','男',20,'软件工程','软工2502',2025)
,(20250301,'周八','女',20,'大数据技术','大数据2501',2025)
,(20250302,'吴九','男',19,'大数据技术','大数据2501',2025)
,(20250401,'郑十','女',20,'人工智能','智能2501',2025)
,(20250104,'钱十','男',20,'计算机科学与技术','计科2501',20)
,(20250203,'孙十','女',20,'软件工程','软工2502',2025);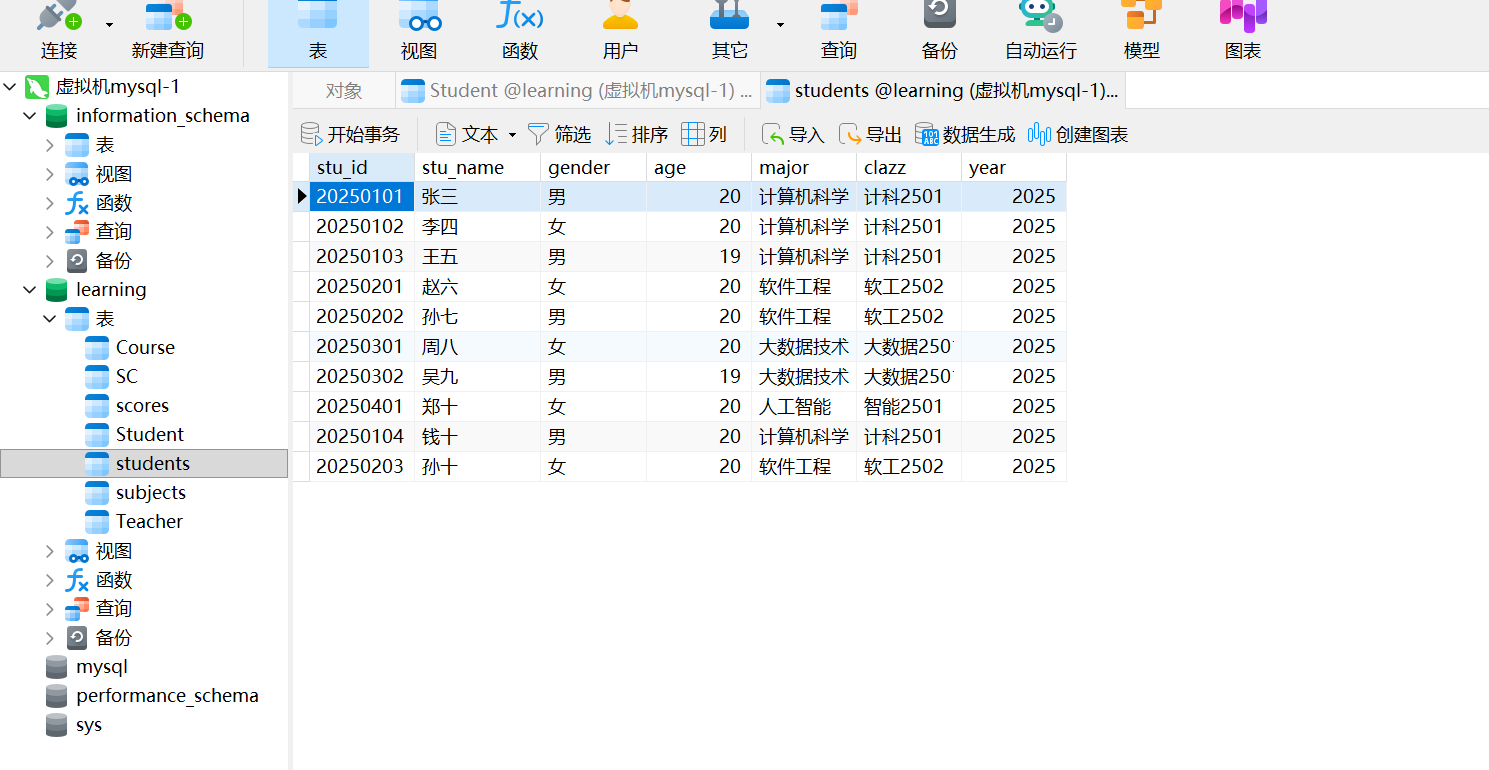
load data local infile 'D:\\Desktop\\mysqlmd\\data\\students.txt' into table students fields terminated by ',';
导出数据
Navicat导出向导
命令导出
# 不建议加密码,不安全 mysqldump -uroot -p stu students > /root/data/students.sql
xshell导入导出数据
不是在mysql中运行 是在shell中执行 即终端
-
导入数据
load data local infile '路径' into table 表名 fields terminated by '分隔符';-
导出数据
# 数据库stu 表students 路径
mysqldump -uroot -p stu students > /root/data/mydb.sql
# 可以加到.bashrc中
alias db_backup='mysqldump -uroot -p stu students > /root/data/mydb_$(date +%Y%m%d).sql'
# 备份并压缩(生成 .sql.gz,节省空间)
alias db_backup='mysqldump -uroot -p --single-transaction stu students | gzip > /root/data/mydb_$(date +%Y%m%d).sql.gz'查看DDL & 查看当前数据库
-- 查看DDL语句
show crete table students;
-- 查看当前数据库
select database();
限制查询
-
limit 关键字
select * from students limit 10;
表修改
ALTER语句
使用 ALTER TABLE 语句追加, 修改, 或删除列的语法
-
add
-- 增加字段
alter table students add [column] dateT date;
-- 设置默认值
alter table students add dateT date DEFAULT "2025-12-12";-
modify
MODIFY后必须明确指定「字段类型」(哪怕只是修改注释,也要重新声明类型)
-- 修改字段类型,属性
alter table students modify dataT datetime;
alter table students modify dateT date comment "日期";
-- 修改字段默认不为空
alter table students modify stu_id int not null;
-- 修改字段默认可以为空
alter table students modify stu_id int default null;-
drop
-- 删除字段
alter table students drop length;
-- 另外写法
drop table table_name-
change
-- 修改字段名称
alter table students change stu_id sid varchar(255);-
character set
-- 修改表的字符集
alter table students character set utf8;-
rename to
-- 修改表名
alter table students rename to student;
-- 另外一种写法
rename table students to student;表删除
-- 删除表
drop table [if not exist] students;mysql基本语句
SQL基础语句
select语句
SELECT column1, column2, ... FROM table_name WHERE condition;其中,SELECT关键字用于指定要查询的列,可以使用*代表所有列;FROM关键字用于指定要查询的表;WHERE关键字用于指定查询的条件。
select * from student where sex=’男’;insert语句
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);其中,table_name是要插入数据的表名,column1、column2等是表中的列名,value1、value2等是要插入的值。
update语句
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE some_column = some_value;其中,table_name是要更新数据的表名,column1、column2等是要修改的列名,value1、value2等是要修改的值,WHERE子句是用于指定要更新的行的条件。
delete语句
DELETE
FROM table_name
WHERE some_column = some_value;其中,table_name是要删除数据的表名,WHERE子句是用于指定要删除的行的条件。
注意:如果不指定条件相当于删除表中所有数据
SQL基本查询
where子句
WHERE子句是结构化查询语言(SQL)中用于筛选数据的关键字。通过WHERE子句,您可以指定一个或多个条件来限制从数据库中检索的数据行。以下是WHERE子句的使用方式:
SELECT * FROM table_name
WHERE some_column = some_value;-
操作符:
WHERE子句可以使用以下比较运算符:
=(等于)
<(小于)
>(大于)
<=(小于或等于)
>=(大于或等于)
<>或!=(不等于)
还可以使用逻辑运算符(AND、OR和NOT)来组合多个条件。例如:
SELECT * FROM students WHERE sex = ‘男’ and age > 23;-
模糊搜索
-- 多字符匹配
SELECT * FROM students WHERE clazz like 'xx%'
-- 单字符匹配
SELECT * FROM students WHERE stu_name LIKE '张_';
-- 多关键词匹配:找姓名含“张”或“李”或“王”的学生
SELECT * FROM students WHERE name RLIKE '张|李|王'
-- 范围匹配:找姓名含“张”且后面跟1-2个字符的学生(如“张三”“张三丰”)
SELECT * FROM students WHERE name RLIKE '张.{1,2}';-
in
返回选项中的内容
select * from students where clazz in ('xx','xx','xx');-
BETWEEN AND
返回年龄在22到24的学生
select * from students where age BETWEEN 22 AND 24;order by子句
ORDER BY子句用于对查询结果按照一个或多个列进行排序。它接受一个或多个列名或表达式作为参数,并可指定每个列的排序方式(ASC:升序,DESC:降序)。语法如下:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...group by子句
GROUP BY子句用于将查询结果按照一个或多个列进行分组,并对每个组进行聚合计算(如COUNT、SUM、AVG等)。语法如下:
SELECT column1, column2, ..., avg(column_name)
FROM table_name
GROUP BY column1, column2, ...
-- 嵌套where
select * from
(SELECT column1, column2, ..., aggregate_function(column_name) f
FROM table_name
GROUP BY column1, column2, ...) as t1
where t1.f > xxx;having子句
HAVING子句用于对分组后的结果进行过滤,只返回符合条件的分组。它接受一个或多个聚合函数作为参数,并可指定每个函数的过滤条件。语法如下:
SELECT column1, column2, ..., aggregate_function(column_name)
FROM table_name
GROUP BY column1, column2, ...
HAVING condition;limit子句
LIMIT用于限制查询结果集的行数,其中,number是你想要返回的行数。其语法如下:
SELECT column1, column2, ...
FROM table_name
LIMIT number;-- 多行查询 从number1起 limit number2个
SELECT column1, column2, ...
FROM table_name
LIMIT number1,number2;offsite子句
OFFSET用于指定查询结果集的偏移量。
其中,number是你想要返回的行数,offset_num是从查询结果集的起始位置偏移的行数。
SELECT column1, column2, ...
FROM table_name
LIMIT number OFFSET offset;数据连接
外连接 内连接
内连接 join | inner join
SELECT s.*, sc.subject_id, su.subject_name
FROM (
students s
JOIN
scores sc
JOIN
subjects su
ON s.stu_id = sc.stu_id and sc.subject_id = su.subject_id
);外连接 left join / right join / full join
# 在score末行添加一个假数据
# 2000 1 100 期末
SELECT *
FROM(
students as s
RIGHT JOIN
scores as sc
ON s.stu_id = sc.stu_id
);union 操作
先拼接,再去重(删除重复行)
-- 合并“成绩≥90”和“成绩≤60”的学生信息(UNION 自动去重)
SELECT s.stu_id, s.stu_name, sc.score, su.subject_name
FROM students s
JOIN scores sc ON s.stu_id = sc.stu_id
JOIN subjects su ON sc.subject_id = su.subject_id
WHERE sc.score >= 90
UNION
SELECT s.stu_id, s.stu_name, sc.score, su.subject_name
FROM students s
JOIN scores sc ON s.stu_id = sc.stu_id
JOIN subjects su ON sc.subject_id = su.subject_id
WHERE sc.score <= 60
ORDER BY score DESC;union all操作
直接拼接结果,不做任何去重 / 排序
-- 添加一个student 张三 19
SELECT name FROM students WHERE age = 20
UNION ALL
SELECT name FROM students WHERE age = 19;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 36
36 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)