什么是RAG重排序? 3 分钟落地最强轻量级重排序模型 BGE-Reranker-v2-m3
文章摘要:本文介绍了在RAG系统中部署BGE-Reranker-v2-m3的重要性,该模型能通过交叉编码器架构深度分析查询与文档的语义关系,解决传统向量搜索的模糊匹配问题。文章包含原理分析、环境准备步骤和核心代码实现,通过示例演示了Reranker如何识别关键词陷阱并锁定逻辑答案,从而提升大模型输出的准确性。标准RAG流程建议先进行向量搜索粗排,再用Reranker精排,最终筛选出最相关的文档喂给
文章目录
前言
在构建 RAG(检索增强生成)系统时,很多人会发现:即便用了向量数据库,检索回来的前几个文档依然可能“牛头不对马嘴”。这是因为向量搜索(粗排)侧重于语义空间的距离,而 Reranker(精排) 能够深度分析查询句与文档句之间的细微逻辑关系。
今天我们部署由智源研究院(BAAI)开发的 BGE-Reranker-v2-m3,它是目前性价比最高、支持多语言的重排序利器。
一、 原理浅析:为什么 RAG 需要重排序?
在传统的 RAG 流程中,我们通常使用 Embedding(向量化) 来检索文档。但向量搜索本质上是“模糊匹配”,它存在两个硬伤:
1. Bi-Encoder(双编码器)的局限性
向量检索(如 BGE-Embedding)采用的是 Bi-Encoder 架构:问题(Query)和文档(Doc)是分开计算向量的。
- 优点:速度极快,适合从海量数据(百万级/亿级)中初步捞取。
- 缺点:Query 和 Doc 在编码阶段没有任何交互,无法捕捉到深层语义的细微差别。
2. Cross-Encoder(交叉编码器)的降维打击
而 BGE-Reranker 采用的是 Cross-Encoder 架构:它将 Query 和 Doc 同时输入到模型中进行全注意力的深度计算。
- 原理:模型像一位细心的审稿员,同时盯着问题和答案,逐字逐句对比它们的逻辑匹配度。
- 效果:它能识别出“词相同但意思不同”的干扰项,也能识别出“词不同但意思相同”的精准答案。
3. 标准 RAG 流程:粗排 + 精排
为了平衡效率和精度,工业界的标准做法是:
- 粗排(Embedding):从 100 万个文档里快速找回相关度前 100 个。
- 精排(Reranker):对这 100 个进行“选美”,精准挑出前 5 个最能解决问题的,最后喂给大模型。
二、 环境准备
在部署之前,由于当前 Python 环境库的兼容性问题,我们需要特别注意 tf-keras 的安装。
1. 安装核心库
打开终端,执行以下命令:
# 安装官方模型库
pip install -U FlagEmbedding
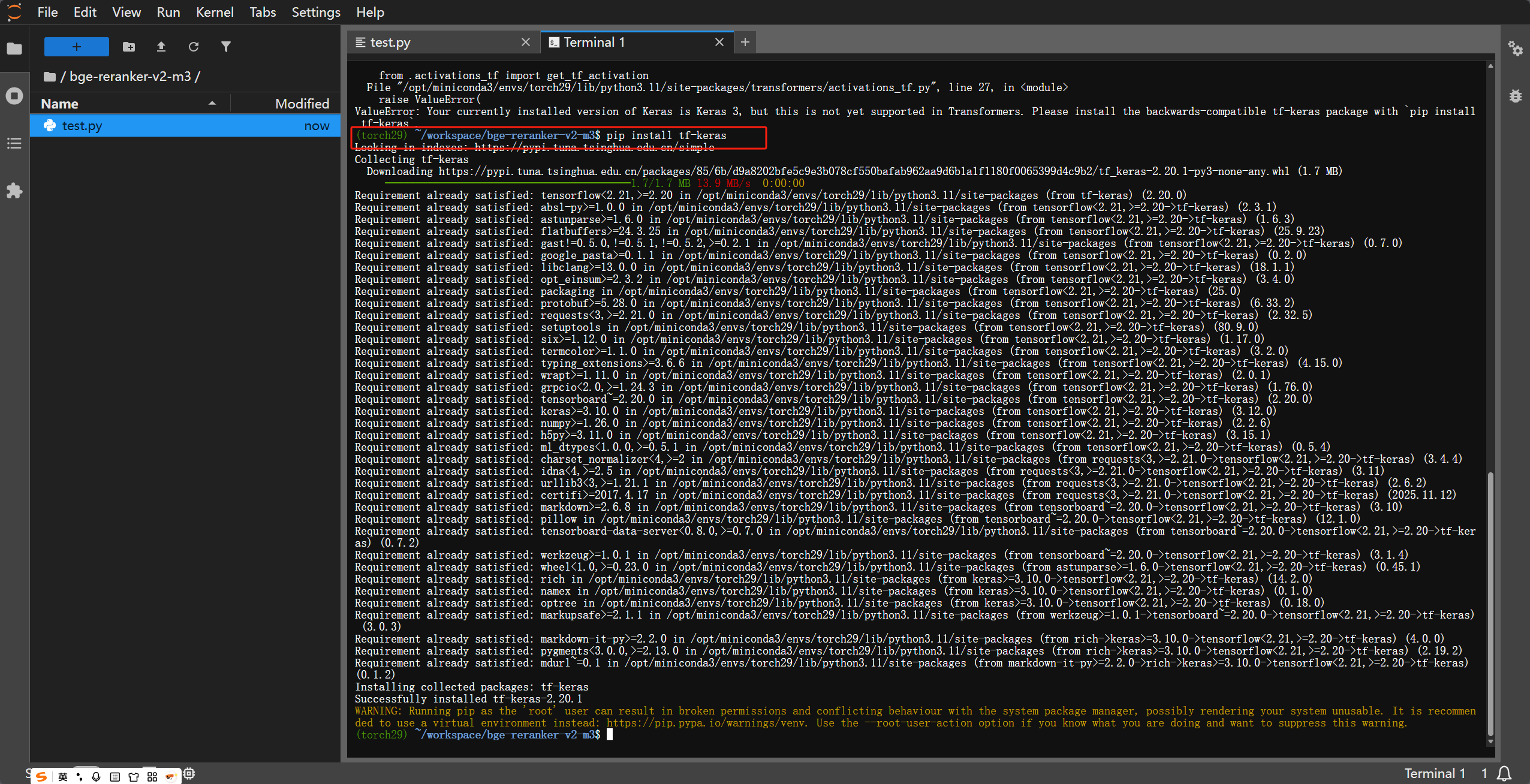
# 关键一步:解决 Transformers 与新版 Keras 3 的兼容性报错
# 如果不装这个,运行代码时可能会报 "ValueError: Your currently installed version of Keras is Keras 3..."
pip install tf-keras
2. (可选) 设置环境变量
如果你在运行中遇到 TensorFlow 相关的报错,可以在脚本开头或终端设置:
export USE_TORCH=1
三、 核心部署代码
BGE-Reranker 的使用极其简单。它不像大语言模型那样需要复杂的 Prompt,它只负责给“问题-文档”对打分。
from FlagEmbedding import FlagReranker
# 1. 初始化模型
# use_fp16=True 可以加快推理速度并减少显存占用
reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True)
# 2. 准备数据
query = "什么是重排序模型?"
passages = [
"重排序模型用于在初步检索后提高文档的排序精度。", # 极度相关
"今天天气不错,适合出去郊游。", # 完全无关
"BGE模型是由北京人工智能研究院开发的开源项目。" # 部分相关(提及了开发者)
]
# 3. 计算得分
# 注意:输入是 [query, passage] 的列表嵌套
scores = reranker.compute_score([[query, p] for p in passages])
print(f"查询语句: {query}")
for p, s in zip(passages, scores):
print(f"得分: {s:.4f} | 文档: {p}")
代码第一次运行的时候需要下载模型,大概需要几分钟的时间,稍微等待既可
结果解读:分数越高,表示该文档越能回答或满足查询的需求。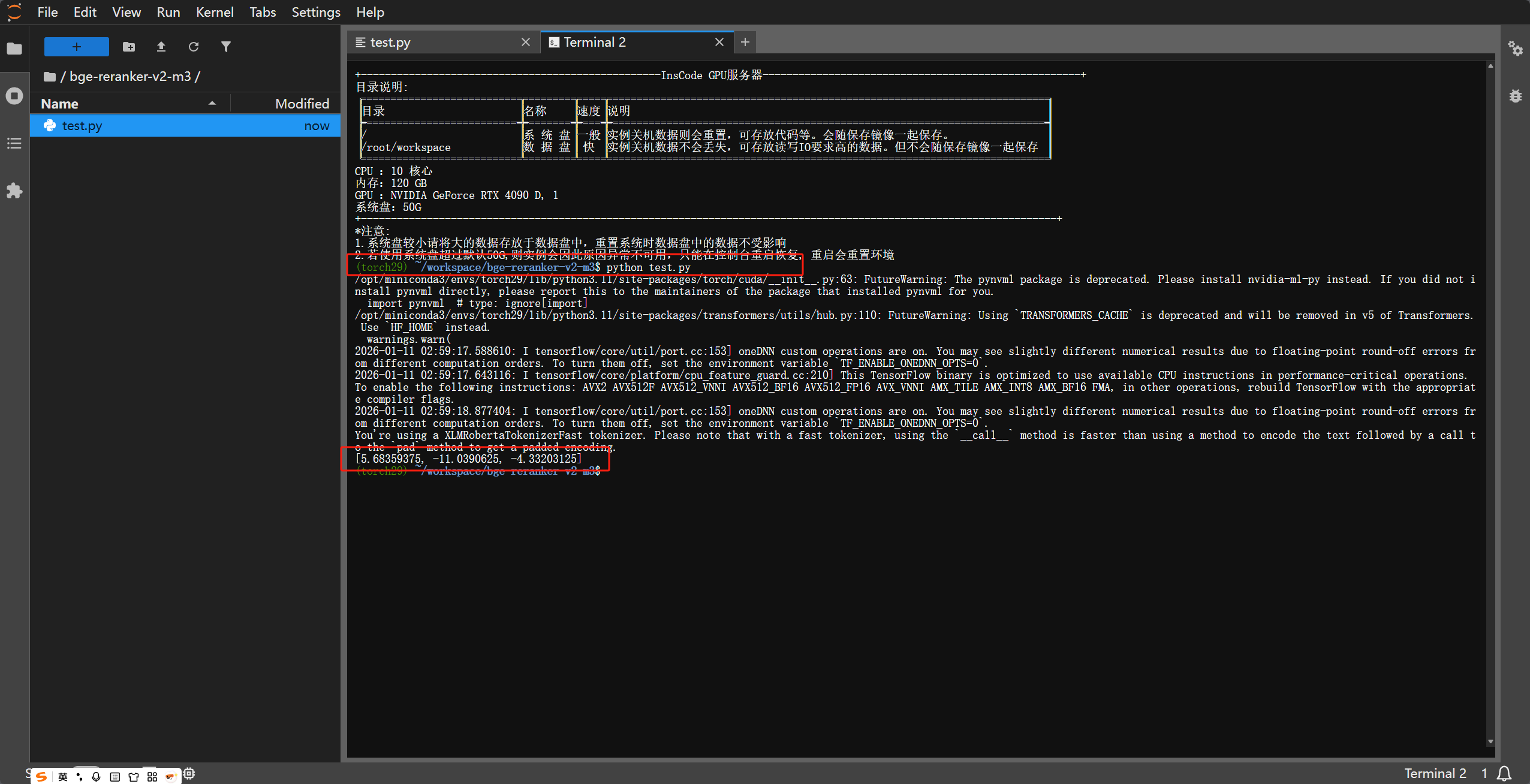
四、进阶程序:直观体验 Reranker 的“语义照妖镜”作用
为了让大家理解为什么 RAG 必须要有 Reranker,这个程序模拟了传统关键词匹配与Reranker 语义重排的区别。
场景:关于“猫”的科普查询
我们设置了一个陷阱:有的文档包含大量关键词但意思不对,有的文档没提核心词但语义完全吻合。
import time
from FlagEmbedding import FlagReranker
def run_visual_demo():
print("正在加载模型,请稍候...\n")
# 强制使用 CPU 或 GPU 加速
reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True)
# 用户的真实问题
query = "猫咪能不能喝牛奶?"
# 模拟从向量库检索出来的“候选文档”(粗排结果)
# 传统搜索可能会因为关键词“猫”和“牛奶”匹配到很多干扰项
candidates = [
"1. 奶牛场里有很多猫,它们在草地上抓老鼠,非常可爱。", # 关键词重合度高,但完全没回答问题
"2. 很多成年猫患有乳糖不耐症,摄入乳制品会导致腹泻或呕吐,建议喂食专门的猫奶粉。", # 完美回答
"3. 超市里的纯牛奶正在打折,适合人类饮用,但不确定宠物是否喜欢。", # 提及了牛奶,相关度一般
"4. 养猫需要准备猫砂、猫粮和干净的饮用水,水是生命之源。", # 提及了养猫,但无关牛奶
]
print(f"用户问题: 【{query}】")
print("-" * 60)
print("原始粗排顺序(模拟向量搜索回来的结果):")
for c in candidates:
print(c)
# 开始重排序
print("\n--- Reranker 正在深度分析语义中... ---")
start = time.time()
input_pairs = [[query, c] for c in candidates]
scores = reranker.compute_score(input_pairs)
end = time.time()
# 排序结果
results = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
print(f"\nReranker 精排后的结果(耗时 {end-start:.3f}s):")
for i, (doc, score) in enumerate(results):
# 简单的可视化进度条
bar = "█" * int(abs(score) if score > 0 else 1)
status = "✅ 最佳匹配" if i == 0 else "❌ 干扰项"
print(f"Rank {i+1} | 分数: {score:7.4f} | {status}")
print(f"内容: {doc}")
print("-" * 40)
if __name__ == "__main__":
run_visual_demo()
运行结果如下: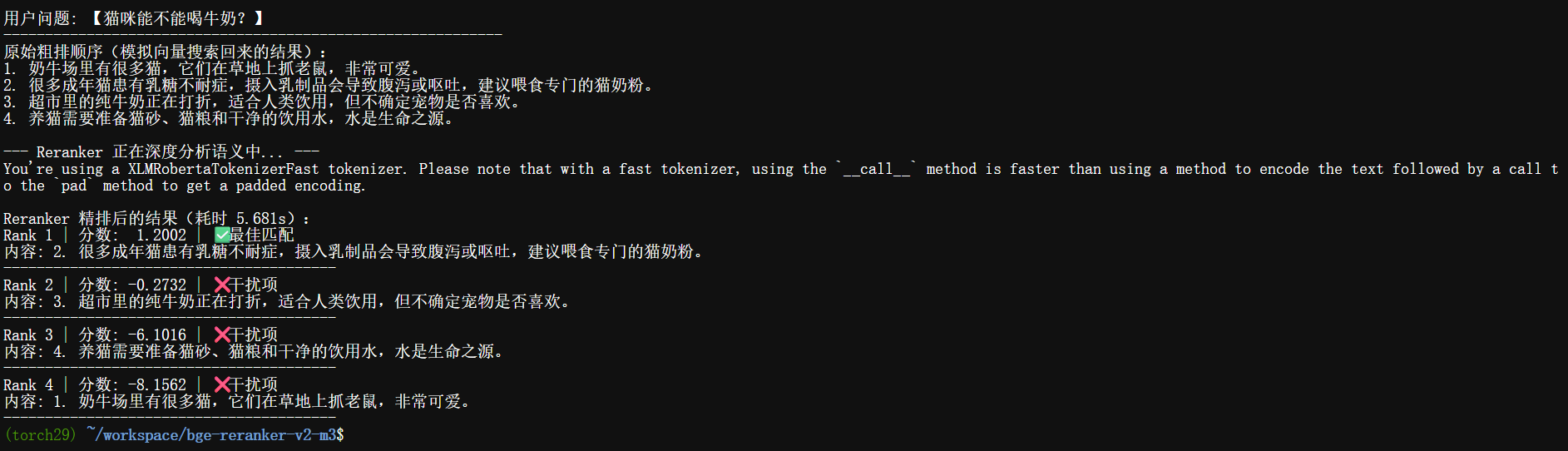
为什么这个程序能让大模型“开窍”?
- 识别关键词陷阱:文档 1 包含了“奶牛”、“猫”,在传统搜索或弱向量搜索中分很高。但 Reranker 能识别出它在讲“抓老鼠”,从而给它打低分。
- 锁定逻辑答案:文档 2 解释了“乳糖不耐症”,这是问题的核心逻辑。Reranker 会敏锐地捕获到这种逻辑对应关系,将其排在第一。
- 这就是 RAG 的“最后一步”:在把文档塞给 GPT 之前,通过 Reranker 过滤掉 Rank 2/3/4 的干扰,能极大减少大模型的“幻觉”现象。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)