揭秘 xLLM 背后的性能密码:昇腾 ATB 加速库如何成为大模型推理 “加速器”
答案是肯定的,通过将首次 kenrel 计算出的 tiling 和 kernel 本身储存起来,后续需要使用该 kernel 和计算 tiling 时,优先寻找是否有可以复用的 kernel 和 tiling,如果有就不重复计算,从而减少 GraphOperation 的 Setup 耗时。观察使用 Setup、Execute 二级流水后的流水图可以发现:图与图之间的空泡仍然存在,其来源在于图的
在探索大模型推理性能优化的道路上,我们早已告别了"闭门造车"的时代。昇腾 CANN 将大量的高性能算子开源,正是拥抱开发、协同创新的体现。如果将 AI 模型的推理比作一场交响乐,那么原始的深度学习框架或许能确保每个音符正确,但演出效果可能平淡无奇。而昇腾 CANN 开源 ATB 加速库(ascend-transformer-boost),就如同一位技艺高超的指挥家,他能调动每一位乐手(高性能算子)的潜能,确保整场演出(推理过程)行云流水、精准高效。
在这场性能交响乐中,优化贯穿了两个“舞台”:负责调度与协调的 Host 侧(CPU),以及负责核心计算的Device 侧(NPU)。本文将带您走进后台,揭秘这位“指挥家”的乐谱——看他如何在 Host 侧优化流水线,在 Device 侧榨干算力资源。我们还将通过关键的代码片段,让这些优化技术变得可触可感,助您将模型的推理性能推向新的巅峰。
🔗 项目地址:
-
ATB加速库外部开发者自定义算子目录:https://atomgit.com/cann/ascend-transformer-boost/tree/master/ops_customize
-
xLLM-service:https://gitcode.com/xLLM-AI/xllm-service?source_module=search_result_repo
问题
常见的单算子下发由于需要在 Host 侧准备算子输入(包含 tiling 计算)使得 Host 侧的耗时大部分场景下都大于算子在 Device 侧的执行耗时。导致上一个算子执行完成但是下一个算子还未下发,在 Device 侧的执行流水上造成大量的空泡。这就是我们通常所说的 Host Bound。
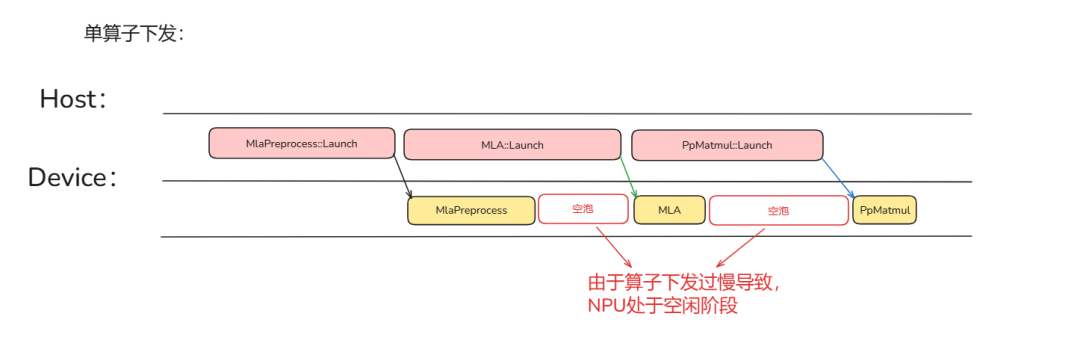
如何解决 Host Bound
为了减少 Host 侧的耗时,ATB 加速库引入了单算子(Operation)图算子(GraphOperation)的概念。
一个单算子内可以包含多个核函数(Kernel)。一个图算子内可以包含多个单算子和图算子。以 DeepSeek 组图为例:
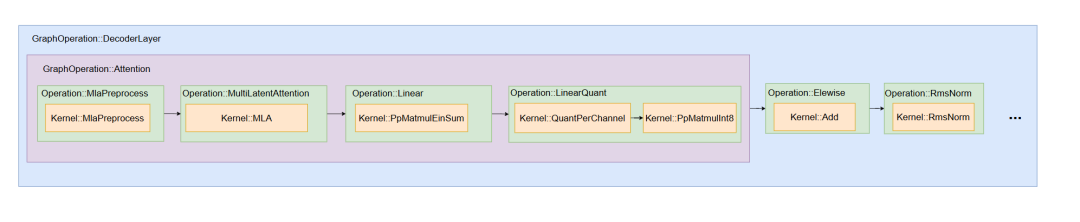
基于 ATB 加速库要在 NPU 上执行算子(Operation、GraphOperation)需要进行两个步骤:Setup、Execute。
-
Setup 阶段主要是计算 Operation 所需的 Device 侧空间大小(workspaceSize),以及准备算子输入(包含tiling 计算)。
-
Execute 阶段主要是将准备好的输入输出 tensor、tiling、workspace、算子作为一个任务(task)下发到Device 侧。
因此基于 ATB 加速库的下发流水如下:
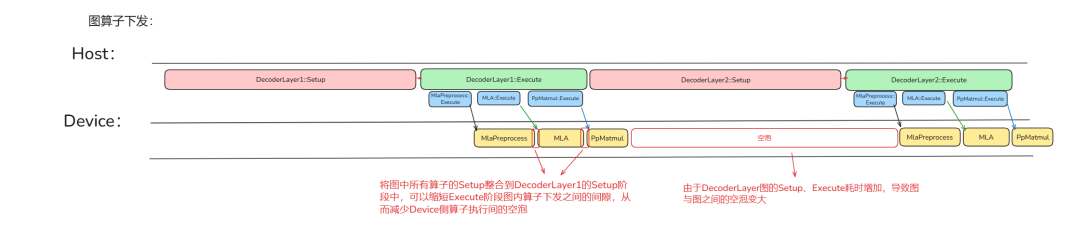
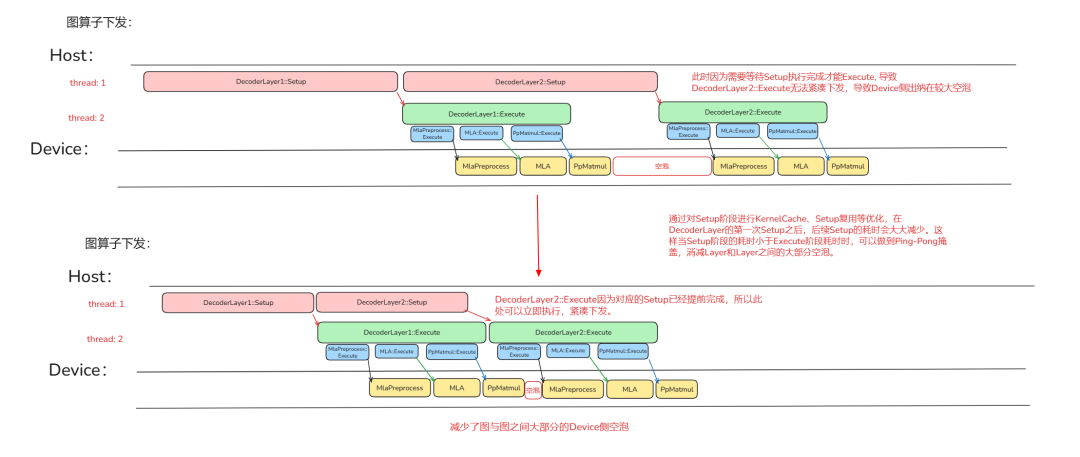
可以发现,Device 侧图内算子执行间的空泡变小了,但是图与图之间的空跑变大了。这是由于 ATB 加速库将图内所有算子的 Setup、Execute 操作都整合到图的 Setup、Execute 阶段完成,这使得 Setup 阶段和 Execute 阶段耗时增加。但由于组图构造图算子的原因,ATB 加速库可以获取到图结构以及对应要传入各个单算子的输入信息(param、输入输出 tensor 信息),使得 ATB 加速库可以根据此进行对应的性能优化。
Setup、Execute 二级流水
将原来算子的下发阶段拆分成 Setup、Execute 两个部分,虽然对于单个算子(Operation、GraphOperation)来说,Execute 阶段依赖于 Setup 阶段的结果,Setup、Execute 阶段仍然无法并行进行。但是对于多个算子来说,由于 ATB 加速库对于数据内容的封装,可以使得不同算子的 Setup、Execute 阶段可以并行进行,从而做到相互掩盖。
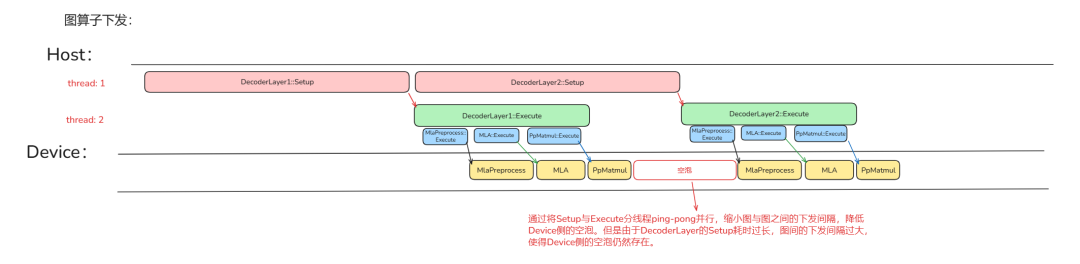
Setup 优化
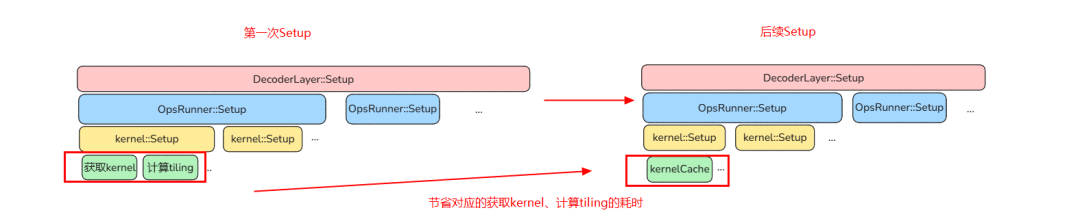
观察使用 Setup、Execute 二级流水后的流水图可以发现:图与图之间的空泡仍然存在,其来源在于图的 Setup 过长导致图间的 Execute 下发间隔过大造成了 Device 侧的执行空泡。这里需要注意的是因为 Transformer 结构下,每一层的结构是相同的,在反复运行时我们不需要对此进行过多的修改。基于这一特性,有两个好处,一是组图下发优化,二是算子在层内和不同层之间的复用。
KernelCache
首先想到相同 kernel 的 tiling 能否复用呢?答案是肯定的,通过将首次 kenrel 计算出的 tiling 和 kernel 本身储存起来,后续需要使用该 kernel 和计算 tiling 时,优先寻找是否有可以复用的 kernel 和 tiling,如果有就不重复计算,从而减少 GraphOperation 的 Setup 耗时。这里简单介绍一下 ATB 加速库的 KernelCache 机制。
Setup 复用
如果再进一步进行优化,能否对算子的 Setup 阶段进行复用呢?答案也是肯定的,在 Operation 进行 Setup 操作时,ATB 加速库会将 Setup 的结果存储起来。当 Operation 的 Setup 场景与上一次的场景相同时,本次的 Setup 可以直接复用上次存储的 Setup 结果,跳过本次的 Setup 操作。减少后续 Setup 阶段的耗时。

优化效果
Execute优化
Execute 分线程
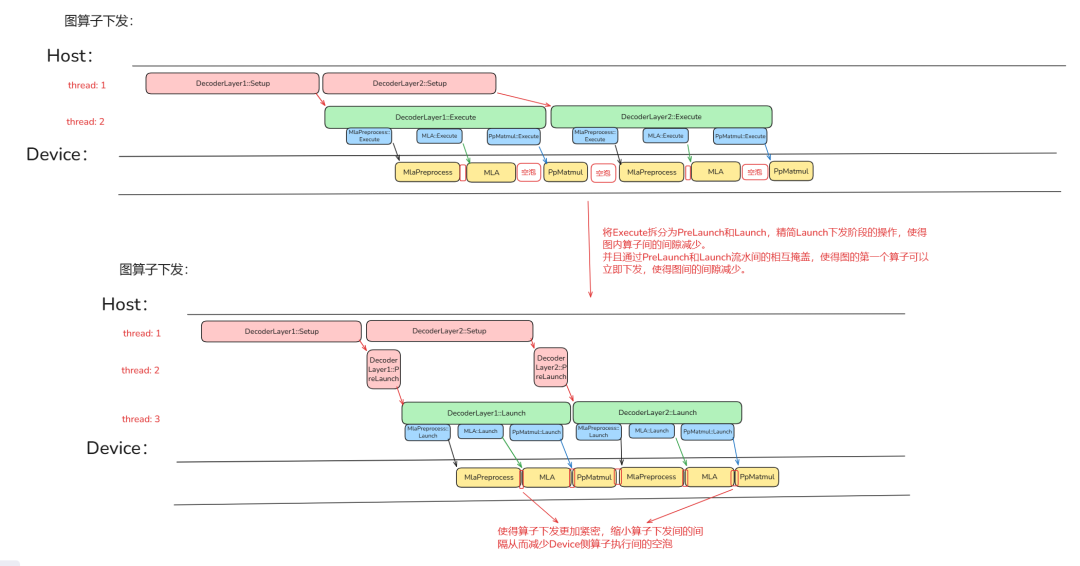
对 Setup 进行优化之后,如果存在下图中 Device 侧算子和算子执行之间的空泡,那就需要考虑如何优化 Execute 阶段。在下图场景下,图算子 Execute 阶段算子间的下发间隔过大导致 Device 侧图内算子执行间存在较大空泡。
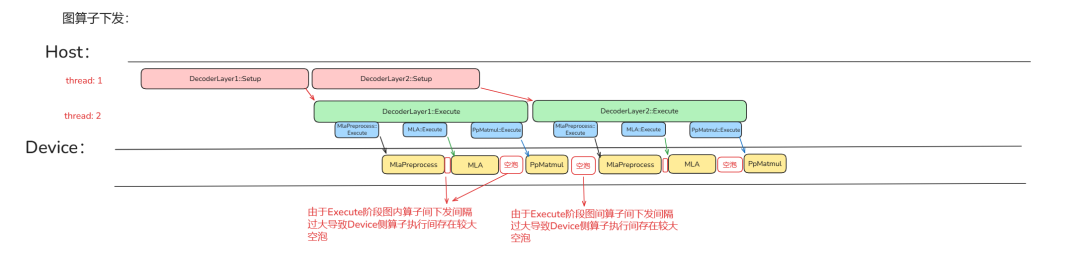
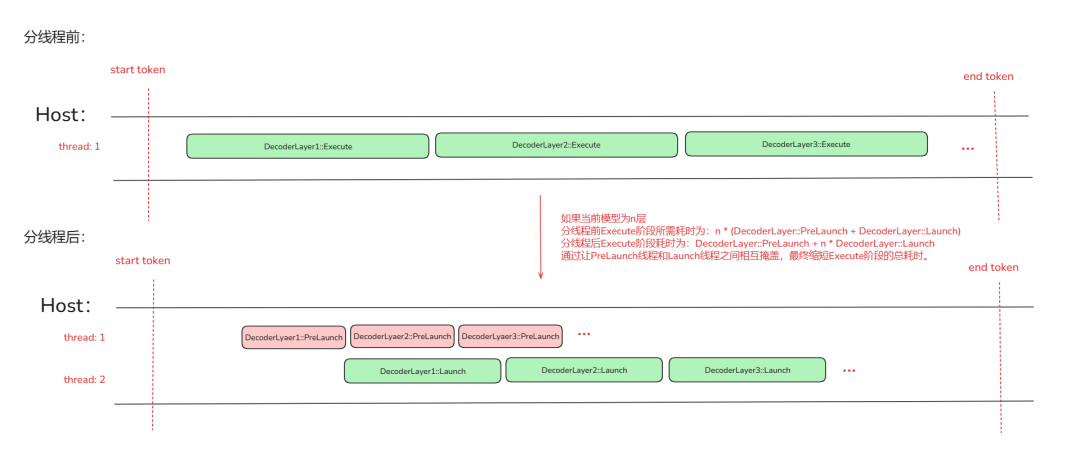
这时就需要对 Execute 阶段进行再拆分并行从而缩小算子与算子间的下发间隔。ATB 加速通过将 Execute 阶段中校验、传递数据等准备操作独立为 PreLaunch 阶段,将更加精简的下发操作独立为 Launch 阶段。
-
PreLaunch:负责整个 GraphOperation 的 Execute 前的准备工作和各个算子下发前的数据搬运、参数校验等准备工作。
-
Launch:只负责 GraphOperation 中各个算子的下发。并且支持通过流水 Ping-pong 并行策略进一步加速算子下发。
优化效果
对比 aclGraph 的优势
相较于 aclGraph 通过捕获 Stream 任务到模型中,将模型固化在 Device 侧,后续直接执行 Device 侧上的模型的操作。他要求模型中的算子、输入输出大小不发生改变,一旦发生改变就需要重新捕获,从而丧失了对于 Host 侧开销的优化。ATB 加速库通过提前根据模型构造对应的图结构,使得在图算子下发机制上,在 Prefill 和 Decoder 阶段均展现出了一定的优势。
-
Prefill 阶段: 在 Prefill 阶段由于 prompt 长度(seqence length)是不固定的,取决于用户的输入。若使用 aclGraph,在不进行 padding 的情况下,由于输入 shape 变化,无法充分发挥 Host 侧优化效果;而若采用 padding,在长序列场景下又会带来巨大的显存开销。相比之下,ATB 加速库借助图算子结构,能够对图内算子的下发流程实施更细粒度的优化。即便模型输入 shape 发生变化,其内部层间与层内算子仍可沿用前述 Host 侧优化策略,兼顾灵活性与性能。
-
Decoder 阶段: 随着生成次数增加,总序列长度(total sequence length)不断增长,导致 KV Cache 的 shape 动态变化。在使用 aclGraph 时,需对 PA 等 Attention 类算子进行额外处理(如单独更新或将其从图中剥离),这不仅引入额外的 Host 侧开销,也提高了推理框架的适配复杂度。而 ATB 加速库将 PA 等 Attention 类算子的更新过程封装于图算子内部,由 ATB 框架自动管理,对外无感知,显著降低了 Decoder 阶段的集成与适配难度。
支持 aclGraph
当前 ATB 加速库也同样支持 aclGraph,并且提供了以下两种调用方式:外部捕获、内部捕获。
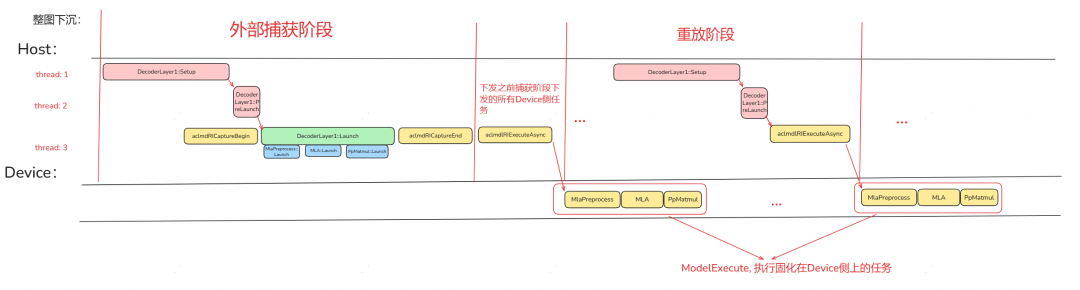
外部捕获
用户通过手动调用 aclmdRICaptureBegin、aclmdRICaptureEnd 接口确定捕获范围,调用aclmdlRIExecuteAsync 进行模型执行。好处在于所需要捕获的内容可以由用户自行决定更加灵活。
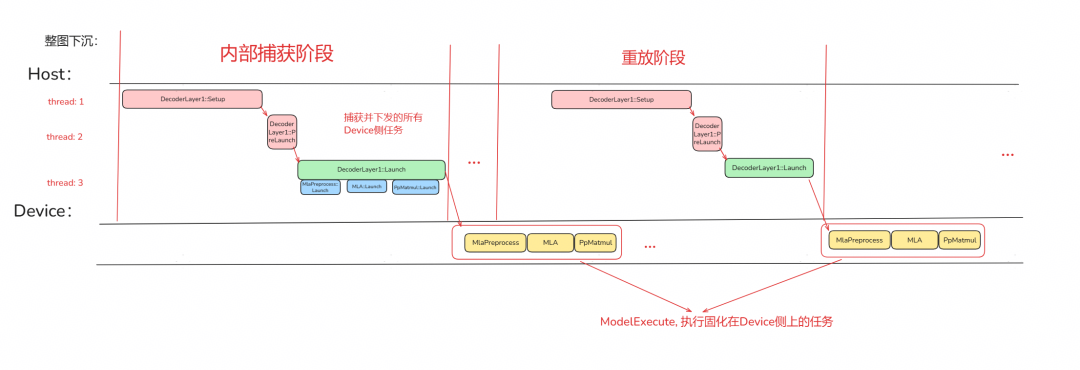
内部捕获
相较于外部捕获,内部捕获将 aclmdRICaptureBegin、aclmdRICaptureEnd 和 aclmdlRIExecuteAsync 接口封装进了 Execute 阶段,使得用户从 ATB 加速库的图算子下发切换到整图下沉流程上不需要感知太多的变化。
自定义算子库
ATB 加速库在提供一系列高性能 Transformer 算子的同时,也支持用户集成并使用自定义的外部算子。用户可参考 ATB 加速库自定义算子目录,开发符合自身需求的高性能算子,并通过 ATB 框架直接调用。目前,ATB 已将该自定义算子目录与框架主体实现解耦,既避免了嵌入式修改,也支持独立编译。用户既可以选择将开发的算子代码贡献至 ATB 开源仓库,也可基于该目录自行开发并维护私有算子库,兼顾开放性与灵活性。
总结
这些优化特性所带来的显著性能提升,并非只是纸上谈兵。正如当前广受关注的 xLLM 引擎,其便选择了 ATB 加速库作为算子下发加速库,这无疑是一次极具说服力的最佳实践。我们也欢迎更多开发者集成并使用 ATB 加速库,开启您的高性能推理探索,与我们共筑大模型应用的未来。
🔗 项目地址:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)