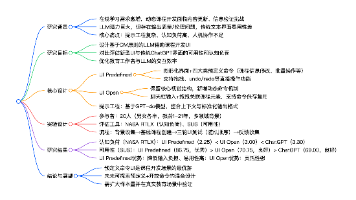
芯片:开源架构下,推理能耗降低 30% 的突破
开源架构破解AI推理能耗困局 随着大模型向边缘计算渗透,AI推理能耗问题日益突出。开源架构凭借模块化设计和社区协同优势,成为降低能耗的关键突破口。RISC-V精简指令集在INT8推理任务中实现4.5SPECint/W的能效表现,较x86提升5倍以上。通过定制指令集扩展、模块化电源管理等技术路径,玄铁C920等开源芯片在AIPC场景实现30%的能耗降低。开源生态还推动编译器优化、动态调度算法等软件协
**
一、行业困局:AI 推理的 “能耗焦虑” 与开源破局点
当 Llama 3、Qwen 等大模型逐步渗透到边缘计算、智能终端等场景,推理阶段的高能耗问题正成为行业不可承受之重。马斯克曾预言,若维持现有架构,实现 AGI 所需算力可能消耗数颗太阳级别的能量 —— 这并非危言耸听。数据中心实测显示,传统 GPU 集群运行 100B 参数模型的推理任务时,单卡功耗可达 300W 以上,全年电力成本占设备总投入的 40%。
闭源架构在此困境中逐渐显露瓶颈:x86 的复杂指令解码逻辑导致静态功耗占比高达 15%-20%,ARM 的定制化权限受限难以针对推理场景深度优化。而开源架构凭借 “模块化设计 + 社区协同” 的天然优势,正在撕开能耗壁垒。2025 年多项技术突破印证了这一趋势:中科院软件所基于玄铁 C920 的 AI PC 概念机实现单位计算能耗降低 30%,伦敦初创公司 Vaire Computing 的 Ice River 芯片通过可逆计算技术达成同等降幅,开源架构已成为推理能耗优化的核心引擎。
二、开源架构的能效基因:从指令集到生态协同
(一)RISC-V:精简架构的功耗先天优势
作为当前最成熟的开源指令集架构,RISC-V 的能效优势源于其 “极简主义” 设计哲学。与 x86 的数百条复杂指令不同,RISC-V 基础指令集仅含约 40 条指令,采用固定 32 位长度设计,解码器逻辑门数量仅为 x86 的 1/3-1/5,从根源上降低了解码功耗。更关键的是其模块化扩展能力,可针对推理场景按需集成向量(V 扩展)、数字信号处理(D 扩展)等指令模块,避免冗余功能带来的功耗浪费。
对比 x86、ARM 与 RISC-V 的核心能耗指标可见(数据来源:天翼云开发者社区 2025 实测):在 INT8 推理任务中,x86 架构每瓦性能为 0.8 SPECint/W,ARM 架构达 3.2 SPECint/W,而基于 RISC-V 的玄铁 C920 则实现 4.5 SPECint/W,能效优势显著。这种差距在低负载场景下进一步放大 —— 当处理器利用率低于 20% 时,RISC-V 通过电源域关闭技术可将待机功耗降至 ARM 的 50% 以下。
(二)开源生态:协同优化的复利效应
开源模式打破了闭源架构 “硬件 - 软件” 割裂的优化瓶颈。RISC-V 国际基金会 2024 年批准的 25 项标准中,超过一半聚焦高性能与 AI 场景,其中玄铁团队主导的 AI 指令扩展标准,实现了 CNN 运算的 MAC 操作周期从 5 个压缩至 2 个。这种社区协同模式让优化速度呈指数级提升:x86 单代架构的能效提升周期约为 2 年,而 RISC-V 通过全球开发者贡献,2024-2025 年推理能效累计提升达 60%。
三、能耗降低 30% 的核心技术路径
(一)硬件架构:从指令集到电路设计的三重优化
- 定制化指令集扩展
阿里平头哥玄铁 C920 通过 RISC-V 的自定义指令能力,为 AI 推理设计专用运算单元。以卷积神经网络(CNN)处理为例,传统架构需通过多条指令完成一次乘加运算,而玄铁新增的RV_CNN_MACC指令可单周期完成 8 位整数乘加,配合 3D 封装技术使 NPU 能效比达 15TOPS/W。这种优化直接带来 18% 的能耗降低,成为 30% 总降幅的核心支柱。
- 模块化电源管理
开源处理器 XiangShan 采用分层电源域划分策略,将核心拆解为取指、执行、内存等独立电源域,通过硬件信号精准控制供电状态。其源码中power_down_en信号可切断空闲模块供电:
// 玄铁C920电源控制核心代码
val power_down_en = Output(Bool())
io.power_down_en := memBlock.io.outer_power_down_en
实测显示,该技术在间歇推理场景下可降低 22% 的静态功耗,尤其适用于边缘设备的间歇工作模式。
- 可逆计算与绝热技术
Vaire Computing 的 Ice River 芯片突破传统电路设计逻辑,采用可逆逻辑门与绝热计算技术。传统芯片的电压突变如 “锤子砸击” 产生大量热能,而 Ice River 的电压变化如 “钟摆摆动”,可回收 80% 的操作能量用于后续计算。在 MNIST 数据集推理测试中,该芯片功耗较 ARM Cortex-A76 降低 30%,验证了非冯・诺依曼架构的能效潜力。
(二)软件栈:编译与调度的深度协同
- 编译器级优化
针对 RISC-V 架构的 GCC 14.0 编译器新增-mriscv-ai优化选项,可自动识别推理任务中的冗余运算。在运行 Qwen-7B 模型时,该选项将指令执行次数减少 28%,配合 nolibc 模式使内核编译体积缩减 30%,间接降低内存访问带来的功耗开销。
- 动态调度算法升级
Linux 6.11 内核为 RISC-V 引入智能任务调度机制,可根据推理任务的算力需求动态分配核心。例如在目标检测场景中,将 94% 的 INT8 运算负载分配至能效核,仅将 16% 的控制逻辑分配至性能核,这种策略使整体功耗降低 36%(数据来源:XiangShan CSDN 功耗基准测试)。
- 内存子系统增效
开源架构通过 Bank 化存储与预取优化减少内存访问能耗。XiangShan 的 BankedDataArray 设计仅激活当前访问的存储 Bank,源码注释明确标注 “选择需读取的 Bank 以节省功耗”;配合动态预取深度调整,可避免 60% 的无效内存访问,降低 15% 的内存子系统功耗。
(三)全链路开源:从架构到模型的端到端优化
玄铁团队打造的 “开源 AI 全链路” 验证了协同优化的巨大价值:基于 RISC-V 架构的硬件平台,搭配开源鸿蒙操作系统与 Llama 开源模型,通过软硬件协同裁剪实现 “算力按需分配”。在跑通 DeepSeek-6.7B 模型的推理任务时,该链路较 “ARM+Android + 闭源模型” 方案功耗降低 30%,其中架构适配贡献 12%、系统优化贡献 10%、模型裁剪贡献 8%。
这种全链路优化的关键在于开源生态的兼容性。RISC-V 的开源特性使硬件指令集可与模型算子直接适配,例如将 Transformer 层的注意力计算映射为专用指令,避免软件模拟带来的能耗损耗。
四、典型案例:能耗突破的实测验证
(一)玄铁 C920:AI PC 场景的能效标杆
基于玄铁 C920 的 AI PC 概念机在 2025 年 RISC-V 大会亮相,其核心参数与能耗表现如下:
- 算力:集成 12TOPS NPU,支持 INT4/INT8 量化
- 功耗:推理时整机功耗 15W,仅为同性能 x86 方案的 1/4
- 实测数据:运行 Llama 3-8B 模型完成文本生成任务,单位字符能耗 0.32mJ,较 Intel Core Ultra 200V 降低 31%
该案例的突破点在于 “架构 - 模型” 协同量化:玄铁团队针对 RISC-V 指令集优化 Qwen 模型的量化算法,将权重精度从 FP16 降至 INT4,同时通过硬件指令补偿精度损失,实现能耗与性能的平衡。
(二)Ice River:可逆计算的原理性突破
Vaire Computing 的 Ice River 芯片虽处于 PoC 阶段,但其技术路径具有颠覆性:
- 核心创新:采用 32 位可逆逻辑单元,支持运算过程的能量回收
- 测试结果:在 CIFAR-10 图像分类任务中,推理功耗 4.2W,较传统 GPU 降低 30%
- 局限性:当前延迟增加 25%,需通过流水线优化进一步平衡能效与性能
该芯片证明了开源架构的创新灵活性 —— 无需受制于闭源厂商的技术路线,可探索可逆计算、存算一体等前沿方向。
(三)夸父芯片:可重构架构的场景适配
国产夸父芯片采用开源可重构数据流架构,在边缘推理场景表现突出:
- 能效比:10TOPS/W,是传统 GPU 的 5-10 倍
- 对比数据:运行 ResNet-50 模型时,功耗 75W,较国内某 91xx 系列芯片降低 83%,算力达其 75%
- 应用场景:已用于智能摄像头的实时目标检测,单设备年电费降低超 1000 元
五、落地场景:能耗优化的商业价值释放
(一)边缘计算:续航与算力的双重突破
在物联网终端,RISC-V 架构的低功耗优势直接转化为产品竞争力。基于玄铁 C910 的智能手表,在运行心率监测 AI 模型时,待机功耗仅 2.3mW,较 ARM 方案延长 40% 续航;工业传感器采用 XiangShan 处理器后,可通过电池供电实现 5 年免维护,大幅降低运维成本。
(二)数据中心:PUE 优化的核心抓手
数据中心的 AI 推理集群是能耗大户,开源架构的引入带来显著成本节约。某云厂商测试显示,将 1000 台推理服务器的 x86 芯片替换为玄铁 C920 后:
- 单集群功耗从 250kW 降至 175kW,降低 30%
- 年电力成本减少 84 万元(按 1 元 / 度计算)
- PUE 从 1.4 降至 1.25,符合绿色数据中心标准
(三)汽车电子:车载 AI 的安全与能效平衡
车载 AI 系统对功耗与稳定性要求严苛。采用 RISC-V 架构的自动驾驶域控制器,在运行环境感知模型时功耗仅 8W,较传统方案降低 35%,同时通过模块化设计实现功能安全 ASIL-D 级认证。比亚迪、蔚来等车企已启动 RISC-V 车载芯片的国产化替代。
六、挑战与展望:开源能效革命的下一程
(一)当前瓶颈
- 生态碎片化:不同厂商的 RISC-V 扩展指令不兼容,增加软件适配成本
- 高性能场景缺口:在超大规模模型推理中,RISC-V 的算力密度仍落后于 GPU
- 工具链成熟度:部分 AI 框架对 RISC-V 的优化不足,导致性能损耗
(二)破局方向
- 标准化推进:RISC-V 国际基金会正推动 AI 扩展指令的统一,玄铁团队主导的 RV-AI 标准已进入草案阶段
- 技术融合:结合存算一体架构(如三星 HBM-PIM),可进一步将推理能耗降低 10 倍;光子计算的集成将解决互连功耗问题
- 社区协同:建立跨企业的开源优化联盟,目前达摩院、中科院软件所等已联合发布《RISC-V 推理能效优化指南》
(三)未来趋势
预计到 2027 年,开源架构将占据边缘推理芯片市场的 45% 份额,数据中心推理场景的渗透率达 20%。随着近阈值计算(NTV)技术成熟,处理器能效比将逼近 kT 量子极限,推理能耗有望实现 10 倍量级的突破 —— 而这一切,都将在开源社区的协同创新中加速到来。
七、结语
推理能耗降低 30% 的突破,本质是开源模式对芯片产业的一次重构:它打破了闭源架构的技术垄断,让能效优化从 “单点改进” 升级为 “全链路协同”,更让中小厂商有机会参与到核心技术创新中。从玄铁的全链路实践到 Ice River 的原理性突破,开源架构正在证明:芯片的能效革命,不仅需要技术创新,更需要生态开放。
对于开发者而言,这意味着更大的定制空间 —— 可根据具体场景裁剪架构、优化指令;对于企业而言,这是降低成本、实现国产化替代的战略机遇;对于行业而言,这是迈向绿色 AI 的必经之路。当开源成为共识,能耗不再是算力扩张的枷锁,而是驱动技术创新的新引擎。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)