内容审核与文本安全技术综述:检测、过滤与对齐
检测质量高度依赖数据。毒性/仇恨/冒犯语言检测领域形成了一批经典数据集,但它们的标签体系差异很大:例如 OLID(OffensEval)强调“是否冒犯—冒犯类型—目标对象”三层结构;HateXplain 在“hate/offensive/normal”三分类之外,还提供目标群体与人类标注的 rationale span;RealToxicityPrompts 则不做离散标签,而是用毒性分数来研究“
目录
3 检测技术综述:从分类器到“LLM-as-judge”的复合检测
5.1 对齐与审核的关系:安全不是外挂,而是模型行为分布的一部分
5.2 机制性研究:越狱为何有效,以及如何在表示空间里“加固边界”
6.1 基准化趋势:HarmBench、JailbreakBench 与“红队工业化”
7 典型系统蓝图:把“检测—过滤—对齐”组合成可落地的审核架构
1 引言
过去十年里,内容审核(content moderation)从“黑名单词表+正则规则”的工程实践,逐步演化为以深度学习为核心的语义识别系统;而近两年,大模型(LLM)把这一链条再次打断并重组:同样的“文本”,既可能是需要审核的用户生成内容(UGC),也可能是提示词(prompt)、系统指令(system prompt)、工具调用参数、检索到的外部文档,甚至是模型自己生成的中间推理与最终输出。于是,文本安全不再只是“对一段文本做分类”,而是贯穿“输入—理解—生成—后处理—分发”的全链路工程:一端要面对对抗性提示、越狱(jailbreak)与提示注入(prompt injection)不断升级的攻防;另一端要兼顾误杀(false positive)带来的体验损害、跨语言与跨文化语境的定义漂移,以及监管合规、可追责与可审计等治理要求。近期的研究也因此从单点模型性能竞争,转向更系统的框架化思考:既要有检测模型,也要有过滤与缓解机制,更要在训练层面讨论对齐(alignment)如何形成“可泛化的安全边界”。在这一背景下,“内容审核与文本安全”成为典型的社会技术系统问题:技术路线与组织流程相互塑形,评测基准与政策文本相互影响,模型能力提升又会反过来放大攻击面与误用风险。Spotify 等作者提出的 “policy-as-prompt” 视角强调:当政策可以被直接写进提示词并让大模型执行时,传统“政策—标注—训练—上线”的流水线将被重构,但也会带来可追踪性、提示结构敏感性、组织分工与治理问责等新的挑战。(arXiv) 另一方面,面向“负面能力”的系统评测正在快速补齐:JailbreakBench 以开放的攻防流水线与可复现工件库推动越狱基准化,HarmBench 以标准化自动红队评测与“稳健拒答(robust refusal)”为核心目标进行大规模对比,新的 RefusalBench 则进一步把“该拒绝时拒绝、该回答时回答”的选择性拒答能力拆解为可诊断的生成式评测任务。
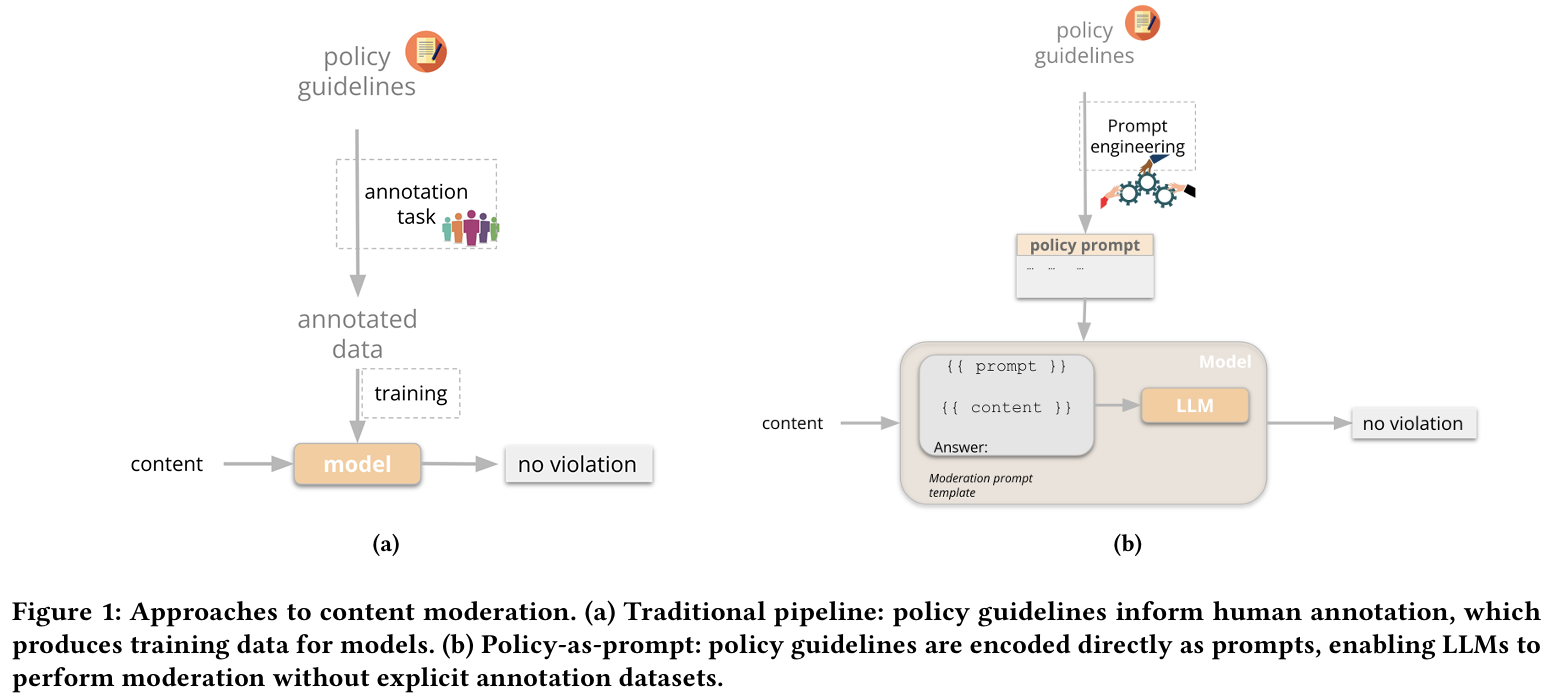
图1 传统审核流水线与 policy-as-prompt 对比
本综述以“检测、过滤与对齐”为主线,试图把文本安全理解为三层相互耦合的能力栈:第一层是检测(Detection),解决“识别风险”的问题;第二层是过滤/缓解(Filtering & Mitigation),解决“把风险拦在系统边界之外,同时尽量不伤害正常能力”的问题;第三层是对齐(Alignment),解决“为何模型会在长尾语境下仍然越界、以及如何在训练中形成更稳健的安全边界”的问题。我们会尽量以近年的综述性文献为骨架,并补充 2024–2025 年代表性研究与基准中的真实数据点,避免凭空编造。
2 内容审核与文本安全的任务边界与范式演进
内容审核在实践中往往以“类别—阈值—动作”来落地:类别包括仇恨、骚扰、色情、暴力、自残、违法活动、极端主义与欺诈等;动作包括放行、降权、打标签、进入人工复核、直接拦截或升级处置。问题在于:这些类别本身并非天然客观,它们来自平台政策、法律语境与社会共识的交集,而且会随时间和地区变化。于是同一段文本在不同平台、不同国家、不同场景下可能被赋予不同标签,这也是为什么近年的“综述”越来越强调:内容审核不仅是算法选择,更是政策Operationalization(把抽象政策转成可执行规则)的工程。Policy-as-Prompt 工作把这一点推到极致:它把“政策文本”直接作为提示输入给大模型,让模型在无需额外标注训练的情况下做审核决策,从而获得快速迭代与细粒度控制的能力;但它也指出这种范式会让系统对提示结构和格式高度敏感,且提示版本演化必须具备可追踪性与可审计性,否则很难解释“为什么昨天可以、今天不行”。(arXiv)
与此同时,攻击者视角也在重塑任务边界。越狱研究的综述性工作给出了较系统的攻防分类:攻击可以按黑盒/白盒、按发生阶段(数据收集与预训练、微调与对齐、推理与交互、后处理与审计)来划分;防御也可分为提示级(prompt-level)与模型级(model-level),并强调评测应区分“攻击成功率”与“过度拒答率”等多维指标。(arXiv) 这类分类的意义在于:它让我们意识到“内容审核”不再只面对用户内容本身,而是要面对一整套能操控模型行为的输入通道(系统提示、工具描述、检索文档、历史对话、多模态信号等),因此单点分类器的边界天然不稳,需要系统化的多层防线。
表1 文本安全中的风险类型、常见触发语境与处置动作(综述整合)
| 风险类型(示例) | 典型语境特征 | 容易误判的边界情形 | 常见处置动作与系统点位 |
|---|---|---|---|
| 仇恨/歧视/骚扰 | 侮辱、贬损、去人化隐喻、群体指称 | 反讽、引用、转述、学术讨论 | 输入/输出检测;降权与人工复核;训练时偏见缓解与对齐 |
| 自残/自杀风险 | 求助、计划、手段描述、绝望语义 | 文学表达、隐喻、自嘲 | 高风险优先人工;危机资源提示;模型拒答策略 |
| 色情/露骨内容 | 性行为细节、未成年人相关风险 | 医学科普、性教育 | 分级标签;年龄门槛;输出过滤与重写 |
| 暴力/违法活动 | 制作、购买、实施的可操作步骤 | 新闻报道、历史讨论 | 强拒答;检索结果过滤;日志留存 |
| 欺诈/社工/钓鱼 | 冒充身份、诱导转账、收集敏感信息 | 合法营销、客服话术 | 风险提示;拦截链接;账号风控联动 |
| 越狱/提示注入 | “忽略规则/扮演/系统提示泄露” | 合规测试、红队评估 | 入口校验;系统提示隔离;对抗评测与加固 |
(该表的分类与阶段化视角与“责任大模型/越狱综述/Policy-as-Prompt”中对风险维度与干预阶段的讨论一致,属于跨文献整合表达。(arXiv))
3 检测技术综述:从分类器到“LLM-as-judge”的复合检测
3.1 整体框架结构
传统文本审核检测大多是监督学习分类:输入一段文本,输出一个或多个风险标签与分数。随着对抗攻击与长语境交互普及,检测逐渐演化为“复合式判定”:一方面保留高效的小模型分类器用于快速拦截与粗筛;另一方面使用更强的模型做上下文推理与解释,并把“判定理由”用于审计与回溯。JailbreakBench 的评测设计就体现了这一趋势:它不仅比较攻击与防御,还显式比较不同“裁判模型(judge)”与人工标注的一致性,并报告了候选裁判的 agreement、FPR、FNR 等指标,说明“用模型判模型”本身也需要被评测与校准。 这一点在实际系统里尤其关键:当输出过滤依赖 LLM-as-judge 时,裁判模型的偏差会直接变成平台的“隐性政策”。
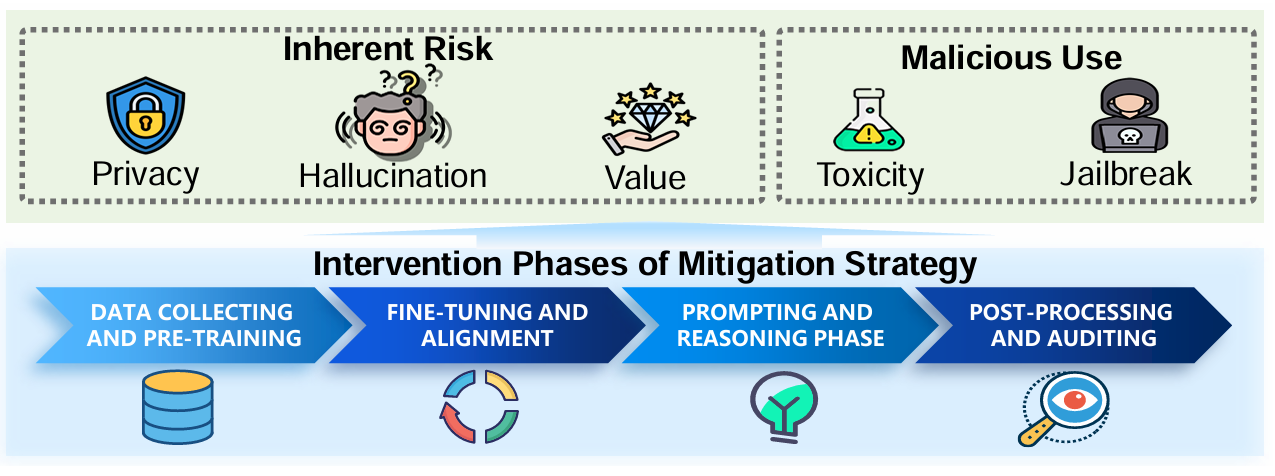
图2 责任大模型的总体框架与四阶段干预
3.2 数据集与标注:定义漂移与可迁移性问题
检测质量高度依赖数据。毒性/仇恨/冒犯语言检测领域形成了一批经典数据集,但它们的标签体系差异很大:例如 OLID(OffensEval)强调“是否冒犯—冒犯类型—目标对象”三层结构;HateXplain 在“hate/offensive/normal”三分类之外,还提供目标群体与人类标注的 rationale span;RealToxicityPrompts 则不做离散标签,而是用毒性分数来研究“模型续写时的毒性退化”。(ACL 汇编) 更重要的是,标注的社会语境会漂移:某些词在某些群体语境里是自我指称,在另一些语境里是侮辱;某些表述在新闻报道里是事实陈述,在社交对话里却可能是煽动。于是“跨域迁移”成为检测综述的核心主题之一:研究不再只问“这个模型在某个测试集上多少分”,而是问“它在新平台、新文化、新语言里是否仍然可用”。这也是为何近年出现面向“定义一致性/可解释性/偏见度量”的数据与评测框架,例如 HateXplain 及后续围绕其 rationale 的研究,都在试图把“为什么判为有害”这件事也变成可学习、可评测的对象。(AAAI)
表2 典型文本安全数据集与真实规模信息(按任务覆盖面选取)
| 数据集 | 主要任务 | 规模/统计(来自论文或官方说明) | 标签/信号形态 | 典型用途 |
|---|---|---|---|---|
| RealToxicityPrompts (Gehman et al., 2020) | 毒性退化评测 | 100K 自然出现的 prompts;平均 11.7±4.2 tokens;其中 22K prompts 的毒性分数≥0.5 (ACL 汇编) | 连续毒性分数 | 生成模型毒性评测、去毒方法比较 |
| Civil Comments(以综述论文引用) | 毒性分类/解释 | 约 1.8 million 帖子;约 8% 标为 toxic(论文复用时给出)(ACL 汇编) | 多标签/毒性比例 | 大规模毒性检测与偏见研究 |
| OLID / OffensEval (Zampieri et al., 2019) | 冒犯语言识别 | “over 14,000 English tweets” (ACL 汇编) | 三层分级标签 | 冒犯检测、目标识别、迁移学习 |
| HateXplain (Mathew et al., 2021) | 可解释仇恨/冒犯检测 | 20K 帖子;后续文献具体到 20,148 条(Gab+Twitter)(AAAI) | 三分类 + 目标群体 + rationale span | 可解释检测、偏见分析、span 监督 |
| ReachOut Self-harm (CLPsych 相关) | 自残风险分级 | 训练 947 帖;测试 280 帖(共享任务设置)(ACL 汇编) | 多级风险标签 | 风险分级、危机干预研究 |
3.3 模型路线:判别式、生成式与混合式
检测模型大致可分三类:其一是判别式分类器(BERT/RoBERTa 等),优点是延迟低、可批处理、易部署;其二是生成式判定(把审核当成指令跟随任务,让模型“先解释后裁决”或“输出结构化标签”),优点是能利用上下文与规则文本,但容易受提示注入影响;其三是混合式架构,即先用轻量分类器做粗筛,再对边界样本交给更强的推理模型,最后把解释与证据写入审计日志。Policy-as-Prompt 属于第二类思路的代表:它让政策被直接编码为提示,从而绕过大规模人工标注与重新训练,但也因此把“提示工程质量”和“提示版本治理”提升为核心工程问题。(arXiv) 与之相对,越狱综述与安全综述类工作提醒:生成式判定的攻击面更大,必须与输入隔离、模板硬化、输出校验等机制配合,才能避免“让裁判也被攻击者带偏”。(arXiv)
表3 检测/裁判模型在基准中的一致性示例(JailbreakBench 报告)
| 裁判/检测模型(候选) | 与人工标注一致性(agreement) | 备注 |
|---|---|---|
| Llama-3-70B | >90% | 与 GPT-4 同属最高梯队之一 |
| GPT-4 | >90% | 在该基准中作为强裁判参考 |
| Llama Guard 2 | 87.7% | 略低于最强裁判,但接近 |
| HarmBench(裁判模型) | 78.3% | 明显低于最强裁判 |
| Llama Guard(早期版本) | 72.0% | 一致性更低,提示需要校准 |
这一组数字的意义不在于“谁最好”,而在于它把一个常被忽略的事实量化了:当我们把“安全判定”外包给另一个模型时,裁判本身的误差会成为系统误差;更现实的是,裁判模型的版本变化会带来“策略漂移”,因此需要像管理推荐模型一样管理审核裁判:固定版本、回归测试、阈值校准、漂移监控。
4 过滤与缓解:把安全做成“多层防线”的系统工程
4.1 过滤的点位:输入、上下文、生成过程与输出
过滤与缓解的核心矛盾,是在有限的误杀率下尽可能降低漏检(尤其是高危类)。工程上最常见的做法并非依赖单一模块,而是将风险控制分布到多个点位:在用户输入端拦截显式违规与明显越狱提示;在上下文端对检索文档、工具描述、历史对话做隔离与清洗,降低提示注入的“二次传播”;在生成阶段用约束解码、拒答策略或安全前缀进行引导;在输出端再做一次审核与必要的重写/打码/拒答。Policy-as-Prompt 之所以引发关注,也因为它改变了过滤点位的组织方式:政策本来通过标注数据与模型阈值“固化在模型里”,现在则可能通过提示词“注入到推理时”,从而更灵活,但也更依赖治理与版本控制。(arXiv)
表4 过滤/缓解在生成系统中的典型点位与手段
| 点位 | 典型手段 | 主要收益 | 主要风险/代价 |
|---|---|---|---|
| 输入端(Prompt) | 关键词/模式拦截;越狱检测;意图分类 | 低成本挡住显式恶意 | 对抗变体多;易误杀正常讨论 |
| 上下文端(RAG/工具) | 文档净化;指令隔离;工具 schema 校验 | 降低提示注入与数据污染 | 清洗过度会损失信息;需要可追溯 |
| 生成端(解码/策略) | 安全系统提示;拒答模板;约束解码 | 直接影响输出分布 | 可能造成过度拒答与能力退化 |
| 输出端(Post-check) | LLM-as-judge;小模型分类;重写/打码 | 最贴近最终风险 | 裁判偏差;延迟与成本 |
| 人工与治理 | 抽检、复核、申诉;策略回归测试 | 处理长尾与争议 | 成本高;时效性压力大 |
4.2 过滤效果的“副作用”:过度拒答与体验损害
越狱与防御研究逐渐把“拒答率”与“正常能力损失”作为核心副指标。JailbreakBench 在图2中展示了不同防御在 benign behaviors 上的拒答率差异,并强调这类评估可以用来快速发现“防御把正常请求也一并打掉”的问题。 更近的 RefusalBench 则把“选择性拒答”作为独立能力来评测,指出在多文档任务上,一些前沿模型的拒答准确率会跌到 50% 以下,并揭示“过度自信回答”与“过度谨慎拒答”都可能同时存在。(arXiv) 这意味着:把安全做成“更强的拒答倾向”并不等于更安全;真正可用的安全系统,需要在“不该做的事坚决不做”和“该做的事别装死”之间找到稳定平衡,而这往往需要评测、阈值、策略与训练共同作用。
5 对齐:从 RLHF 到“安全边界”的可解释与可加固
5.1 对齐与审核的关系:安全不是外挂,而是模型行为分布的一部分
当我们讨论对齐(alignment)时,实际上是在追问一个更根的问题:为什么模型在训练中学到了“可能生成有害内容”的能力?为什么在一些提示下会把系统规则当成可被讨论、可被绕过的对象?责任大模型综述提出的分阶段干预框架把这个问题拆成四个阶段:预训练数据与隐私/价值风险、微调与对齐带来的行为塑形、推理阶段的提示操控,以及后处理审计。(arXiv) 这提醒我们:内容审核不是只在“最后输出”打一层补丁,而应在训练与系统设计层面形成更稳健的“安全边界”。
5.2 机制性研究:越狱为何有效,以及如何在表示空间里“加固边界”
2025 ACL 的一项工作用超过 30,000 条样本分析越狱在模型内部激活空间中的表现,报告其数据集包含 32,507 个样本(benign/harmful/jailbreak 三类),并在图1中可视化三类激活投影,指出“越狱激活与良性激活在多数层并非线性可分”,这对“用简单线性探针检测越狱”构成了直接挑战;同时它提出 Activation Boundary Defense(ABD),并在表1中给出不同攻击下的防御成功率(DSR)对比。 这种研究的价值在于:它把“安全对齐”从经验调参拉回到机制层讨论——如果越狱本质上是把激活推过某个边界,那么防御就不应只在表层拒答,而应在表示空间里约束这种越界。
表5 机制型越狱研究的真实规模与结果摘要(ACL 2025 示例)
| 项目 | 论文报告信息 | 含义 |
|---|---|---|
| 分析样本规模 | “over 30,000 samples”;数据集 32,507 样本 | 机制结论不依赖小样本投影偶然性 |
| 激活可分性结论 | benign/harmful/越狱激活大量重叠,难线性分割 | 简单探针检测可能不足 |
| 防御评测输出 | 表1给出不同攻击与防御的 DSR 对比 | 把“边界约束”转化为可测指标 |
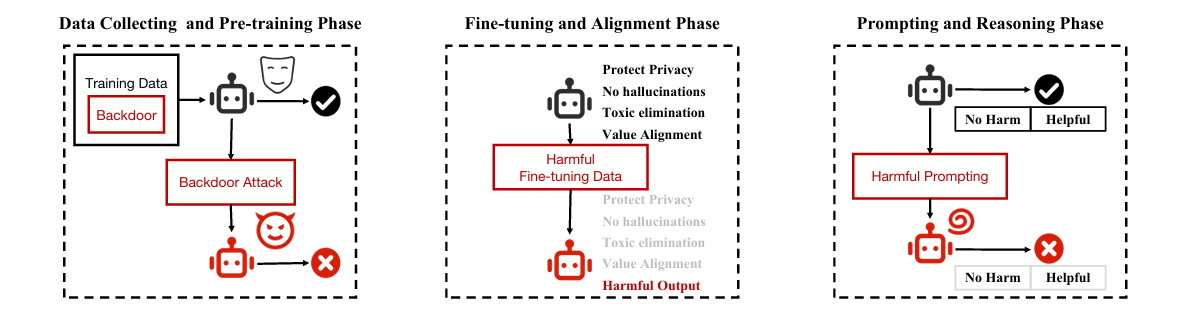
图3 越狱攻击在不同阶段的示意与分类
6 攻防与评测:从越狱基准到多模态红队与稳健拒答
6.1 基准化趋势:HarmBench、JailbreakBench 与“红队工业化”
文本安全研究近一年最明显的变化,是“可复现的基准化”。HarmBench 在其公开仓库中明确报告:比较了 18 种自动红队方法与 33 个目标 LLM/防御,并提供标准化流水线与工件。(GitHub) JailbreakBench 作为 NeurIPS 2024 数据与基准论文,则强调公开评测网站与工件库,图1展示其网站界面,图2则给出 benign behaviors 上的拒答率评估示例。 这种基准化的直接收益是:研究可以围绕“同一套攻击、同一套防御、同一套裁判与日志”迭代,而不是各做各的、互相不可比;更深层的收益是:它迫使社区把“过度拒答”“裁判偏差”“查询成本”等工程现实纳入学术讨论。

6.2 多模态与新通道:音频越狱与更复杂的攻击面
越狱不再只发生在文本提示词里。2025 的 JALMBench 明确把音频引入越狱评测框架:它报告支持 12 个 ALM、8 种越狱攻击(含文本迁移与音频来源)与 5 种防御方法,并包含 245,355 个音频样本。(arXiv) 这意味着“内容审核”必须开始面对更广义的输入通道:语音转写误差会带来新的绕过方式,音频隐写与对抗扰动会让“先转写再审核”的传统流水线出现盲点。对于平台而言,这些变化会把安全工程从 NLP 小组推向更综合的多模态安全治理。
表6 代表性越狱/安全评测基准的真实信息对比(2024–2025)
| 基准/工作 | 年份 | 论文/仓库报告的规模信息 | 覆盖重点 |
|---|---|---|---|
| HarmBench | 2024 | 18 红队方法;33 目标 LLM/防御 (GitHub) | 自动红队、稳健拒答 |
| JailbreakBench | 2024 | 图1为在线榜单;图2评测 benign behaviors 的拒答率 | 攻防可复现、工件库与裁判评估 |
| AdvBench(被多篇工作引用) | 2023/2024 | 500 harmful behaviors(ICLR 2024 论文中说明)(proceedings.iclr.cc) | 指令型有害行为集合 |
| Bag of Tricks(NeurIPS 2024) | 2024 | 约 354 次实验、约 55,000 GPU hours;7 攻击×6 防御(论文摘要段)(proceedings.neurips.cc) | 攻防设置对结果的影响、系统化基线 |
| JALMBench | 2025 | 12 ALMs;8 攻击;5 防御;245,355 音频样本 (arXiv) | 多模态(音频)越狱评测 |
| RefusalBench | 2025 | 176 种扰动策略;评测 30+ 模型;多文档任务拒答准确率 <50%(摘要)(arXiv) | 选择性拒答、可诊断生成式评测 |
7 典型系统蓝图:把“检测—过滤—对齐”组合成可落地的审核架构
如果把上述技术栈落到一个现实的生成式产品里,一个更可行的蓝图往往是“多模型、多策略、多层审计”的组合:入口处用轻量检测器与规则拦住显式恶意与常见越狱;中间层把系统提示、工具描述与检索文档做隔离与规范化,避免用户文本与系统指令混写;生成后用裁判模型做结构化判定,并把判定理由与证据写入审计日志;对高风险类别引入人工复核与申诉渠道;而在训练与持续迭代层面,利用 HarmBench/JailbreakBench/RefusalBench 这类基准做回归测试,防止“加固某类风险导致另一类过度拒答”。HarmBench 提供的流水线思路(生成用例—生成回答—评估回答)以及 JailbreakBench 对裁判一致性的量化,都可以直接迁移到企业内部的“安全回归套件”。(GitHub) Policy-as-Prompt 则提供了另一种组织方式:把政策文本当成可版本化的提示资产,让“策略变化”不必等待重新标注与再训练,但这要求提示演化必须可追踪、可回滚,并且必须与对抗测试共同迭代,否则策略越灵活,安全面越脆弱。(arXiv)
表7 攻击类型与防御层的对应关系(基于越狱综述与责任 LLM 综述整合)
| 攻击家族 | 常见手法与阶段 | 更有效的防御层组合(经验整合) |
|---|---|---|
| 提示层越狱 | 角色扮演、忽略规则、多轮诱导(推理阶段)(arXiv) | 输入端越狱检测 + 系统提示硬化 + 输出端裁判 |
| 提示注入 | 通过检索文档/工具描述注入“新指令”(上下文端)(arXiv) | 上下文隔离/净化 + schema 校验 + 最终输出复核 |
| 白盒对抗/梯度攻击 | 针对模型参数或安全头(微调/对齐阶段)(arXiv) | 训练期对抗加固 + 机制性防御(如边界约束思路) |
| 数据投毒/后门 | 预训练数据污染(预训练阶段)(arXiv) | 数据溯源与清洗 + 训练审计 + 发布前红队 |
| 多模态绕过 | 音频/跨模态迁移攻击 (arXiv) | 多模态一致性检测 + 转写鲁棒性 + 端到端评测 |
8 结语:未来两年的关键矛盾与研究方向
综合近两年的综述与基准化趋势,可以看到文本安全正在从“模型能力竞赛”走向“系统可靠性竞赛”。第一,检测会继续朝“多裁判、多信号融合”发展,但裁判一致性与漂移治理将成为刚性工程需求,JailbreakBench 给出的裁判 agreement 差异已经足以说明:把安全判断交给模型并不自动可靠。 第二,过滤将越来越强调“点位分层”与“副作用控制”,选择性拒答被提升为核心能力,RefusalBench 把这一能力拆成可诊断维度,揭示“安全并不等于拒绝更多”。(arXiv) 第三,对齐研究会更多触及机制层:像 ACL 2025 这类从激活空间讨论安全边界的工作,可能推动新的训练目标与防御结构出现,使得“安全边界”不再只是策略文本,而是模型内部可解释、可加固的结构。 第四,审核范式会在“policy-as-prompt 的灵活性”与“可追责可审计的治理需求”之间拉扯:提示版本管理、策略回归测试、红队常态化与多模态通道的安全评测,会从研究议题变成行业基础设施。(arXiv)
参考文献(节选)
-
Konstantina Palla et al. Policy-as-Prompt: Rethinking Content Moderation in the Age of Large Language Models. arXiv, 2025. (arXiv)
-
Sibo Yi et al. Jailbreak Attacks and Defenses Against Large Language Models: A Survey. arXiv, 2024 (v2). (arXiv)
-
Miles Q. Li, Benjamin C. M. Fung. Security Concerns for Large Language Models: A Survey. arXiv, 2025. (arXiv)
-
(责任与风险综述)A Survey on Responsible LLMs: Inherent Risk, Malicious Use, and Mitigation Strategy. arXiv, 2025. (arXiv)
-
Peiyi Chao et al. JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models. NeurIPS 2024 (Datasets and Benchmarks Track) / OpenReview PDF.
-
Center for AI Safety. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal(项目与说明仓库,含规模信息). 2024. (GitHub)
-
Samuel Gehman et al. RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models. Findings of EMNLP 2020 (ACL Anthology). (ACL 汇编)
-
Marcos Zampieri et al. SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval). ACL Anthology, 2019. (ACL 汇编)
-
Binny Mathew et al. HateXplain: A Benchmark Dataset for Explainable Hate Speech Detection. AAAI 2021 (PDF). (AAAI)
-
I. Salles et al. COLING 2025 论文中对 HateXplain 规模(20,148)与 rationale 的引用说明(用于精确规模佐证). (ACL 汇编)
-
T. Xiang et al. ToxCCIn: Toxic Content Classification with Interpretability. WASSA 2021(文中引用 Civil Comments 规模与毒性比例). (ACL 汇编)
-
Z. Xu et al. Bag of Tricks: Benchmarking of Jailbreak Attacks on LLMs. NeurIPS 2024 (Datasets and Benchmarks Track). (proceedings.neurips.cc)
-
Y. Huang et al. ICLR 2024 论文中对 AdvBench(500 harmful behaviors)等基准规模的说明(用于规模佐证). (proceedings.iclr.cc)
-
Z. Peng et al. JALMBench: Benchmarking Jailbreak Vulnerabilities in ... arXiv, 2025(含 245,355 音频样本与攻击/防御数量)。(arXiv)
-
Aashiq Muhamed et al. RefusalBench: Generative Evaluation of Selective Refusal in Grounded Language Models. arXiv/OpenReview, 2025. (arXiv)
-
A. Yates et al. Depression and Self-Harm Risk Assessment in Online Forums. EMNLP 2017 (ACL Anthology)(含 ReachOut 数据划分信息)。(ACL 汇编)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)