大模型你别再失忆了!你尔多隆吗?
摘要:大模型本身不具备记忆功能,每次对话都需重新发送完整上下文。由于注意力机制、内存限制等问题,模型存在最大上下文限制(如DeepSeek V3.2支持128K)。现代技术通过稀疏注意力、RAG等方法优化长文本处理,但未根本解决无限上下文问题。上下文工程通过结构化数据(如JSON)、分步推理、对话压缩及MCP协议(替代传统function call)提升模型效率。例如,MCP允许模型自主调用外部服

前言
你问大模型一句:“今天天气如何?”,它可能给你查一下本地今天的天气。
你再问它:“那北京的呢?”,他开始科普起了北京,完全忘了上文中的对话,推算出我们是需要他接着回答北京的天气。
以上是发生在早期各家 AI 助手中出现的问题,丢失上下文记忆。随着技术的发展,模型越来越“大”,这个问题出现的时间点(对话轮数)也越来越靠后。那么问题来了,模型是如何记住上下文的?我们该如何优化,在有限上下文中做更多事情?
大模型根本不记
下面是我在开发AI应用的一个简单的解析图
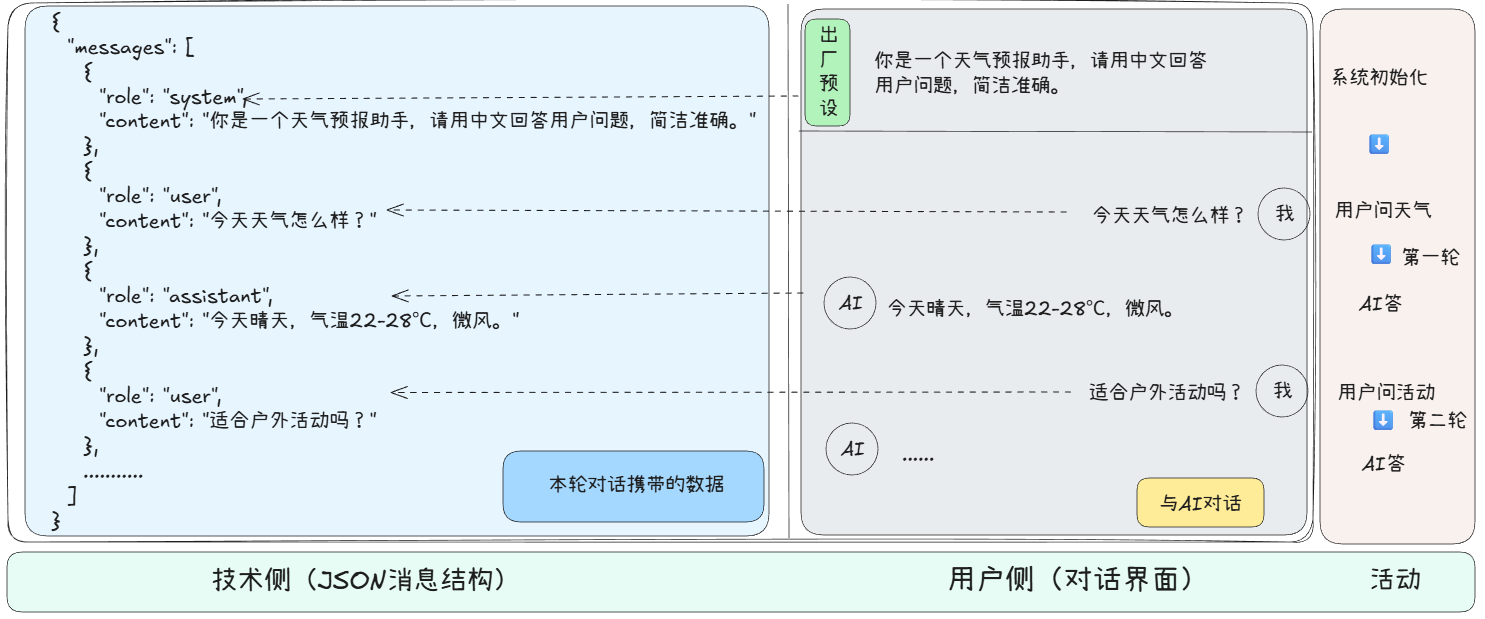
是的,没错。我们每次的对话,包括之前的内容,都要一起发送给大模型。大模型本身不会去存储这些内容。既然不用存储,那如果不限制时间,岂不是能无限推理?那为何所有模型都有最大上下文?
为何不能无上限推理
我们用开会类比,让所有人(上下文中的每个token)都互相交流(注意力机制计算关联),同时你要记住所有人的发言(上下文),这时会遇到以下几个问题。
- 注意力算不过来:人越多,沟通成本便会指数级爆炸
- 内存装不下:GPU的“脑子”不够大
- 太长反而抓不住重点:就像是人类的“注意力”也会衰减
所以,在质量与数量权衡下,就会有这么一个最大上下文。例如DeepSeek的最新模型DeepSeek V3.2的官方数据是128K。根据换算大概是 8 万字(0.75左右的比例,可以看官方文档)。超过之后就开始失忆了,建议重新开一个对话。
现代如何破局?
现在经常有模型支持百万的上下文,看似突破了限制,其实是使用了稀疏注意力、滑动窗口等技巧。讲人话就是,只计算有关联的部分。或者使用上下文工程之一的RAG(Retrieval-Augmented Generation,检索增强生成),通过一个外部的存储,需要时再查询对应知识。
本质上,仍然没有解决无限上下文,只是优化了对长文的处理方式。
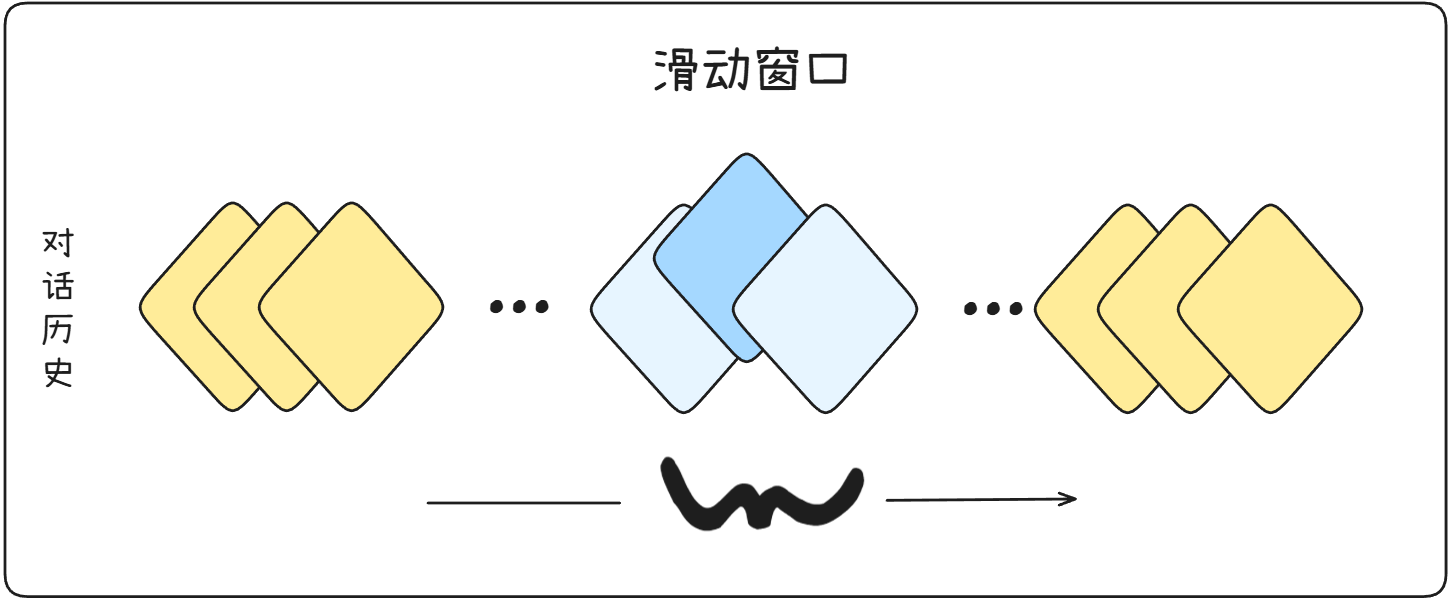
上下文工程
通过前面我们知道了,大模型超级聪明,但是他记忆力不太好(有上下文限制),自己也不太会抓重点。所以就需要这么一个中间人来帮助我们更好的使用大模型。上下文工程就是咱们引导大模型如何理顺眼前的推理任务的一个利器。通过设计,组织和优化输入(Prompt),让他更精准的干活。那上下文工程都要如何实现呢?
信息结构化
回归本质,说到底大模型还是一个计算机程序,对于结构化的内容理解起来,比一大段文字更迅速。在计算机中常见的结构化数据有,列表、表格、JSON。下面使用JSON来展示一下,如何结构化问题。
例子:用户说“我买了件蓝色M码卫衣,订单号456,想退货,因为线头多”,结构化后变成:
{
"订单号": "456",
"商品": "卫衣",
"规格": {"颜色": "蓝", "尺码": "M"},
"诉求": "退货",
"原因": "线头多"
}
另外,如果想标记重点,可以使用双引号,【】或者Markdown语法中的加重(**)来突出。
边做边想边反思
有时候特别复杂的问题,模型能力弱的情况下,大模型不会一下理解你的全部意图。我们所需要就是,首先和大模型对齐认知,不着急去推理后续,先列个计划清单。
然后拆解问题,反思或者总结。
以下是一个示例提示词
请基于以下要求直接给出最终答案,过程中需隐含完成以下思维步骤(无需显式写出):
1. **拆解问题**:识别核心要素、约束条件和潜在陷阱
2. **多视角推演**:列举至少2种合理路径/观点,评估各自优劣
3. **关键验证**:交叉检验矛盾点,排除逻辑漏洞
4. **收敛结论**:综合最优解并预判用户潜在追问
问题:[在此插入具体问题]
测试效果
以上就是完成了一轮思考。想要多轮还需在程序中设计一个循环判断,这里不过多展示。
压缩对话
我们在与AI对话的过程中,绝大部分内容是推理产物,是可以忽略的。不过,传统编码出来的程序是不会分析语义从而做到内容删减的。这恰好是大模型擅长的东西。
当与AI对话的内容上下文超过90%后,可以将之前进行总结,形成新的上下文,然后新开对话,把压缩后的内容发给大模型。
function call、MCP
大模型是将某个时间节点以前所有的知识学习后的产物,如果不开启联网,那么它就是知识停留在那个时间点以前的很聪明的“古人”。
你问它一个最近的热点新闻,大模型光靠自己可不会像人类一样去百度一下,而是通过设定好的流程先去将搜索引擎查询十到几十条数据,作为背景知识一起"喂"给大模型。所以,假设一款模型不支持联网,你完全可以手动复制粘贴给他。
在早期,我们在开发AI应用时,像联网、天气、股票查询等操作,就可以通过function call技术来实现。它就是一个暴漏给大模型的传统接口。但这项技术也有一定局限,因为它是一个固定的流程,只有开关可调控的组件。并且接口五花八门,还需要开发者去再次开发。
那么有没有把权利放给大模型自主决定操作的方案呢?MCP出现了。
MCP(模型上下文协议,Model Context Protocol)。看名字就能知道它是专门为大模型应用开发所诞生的,相比于上个技术,消除了不同接口之间的差异,并且由大模型自主决定是否调用。下面演示一下神奇之处。
下面我以腾讯位置服务MCP + Cherry Studio + 混元大模型做例子
提示词
从腾讯北京总部大楼去首都机场T3航站楼有多远,到那需要多长时间?
结果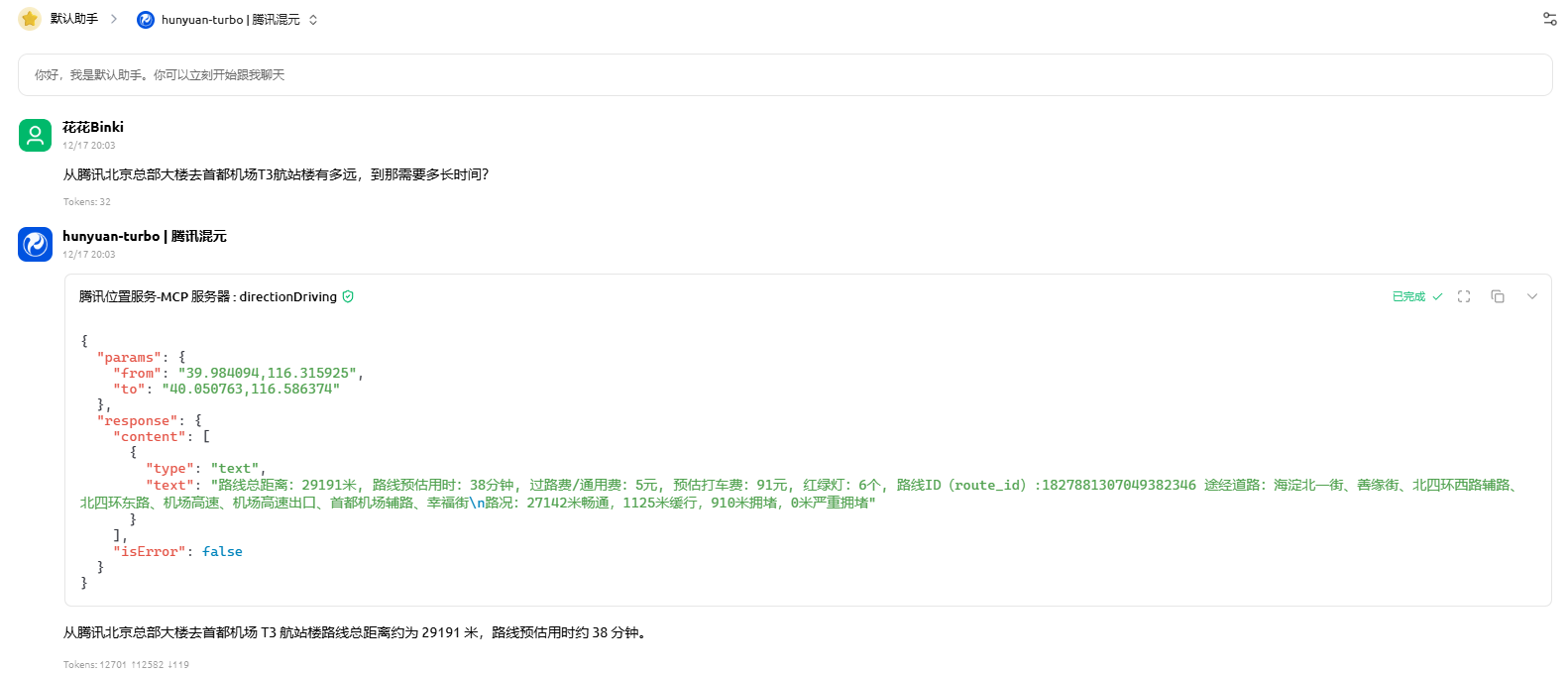
最后
上下文工程还在发展,在Agent开发中或是AI Coding中感受尤为明显。不过,对于大部分使用者,当大模型出现失忆的情况,这边建议是整理下内容,新开个对话!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)