可解释人工智能:概念谱系、方法体系、评估范式与大模型时代的新议题
可解释人工智能(XAI)研究综述了机器学习模型解释的关键问题与方法体系。随着复杂模型在医疗、司法等高风险领域的应用,解释需求从性能评估扩展到决策依据、公平性等维度。文章系统梳理了解释方法的两大路线:透明模型设计与后验解释技术,包括LIME、SHAP等局部解释方法,以及反事实解释、数据归因等新兴方向。
目录
3.1 局部替身模型:LIME与“可在局部被线性逼近”的想象
3.2 统一归因框架:SHAP与“唯一满足一组公理”的加性解释
3.3 规则型解释:Anchors把“通常成立”换成“高精度成立”
9 标准、治理与文档化:解释不是“加一个按钮”,而是生命周期工程
1 引言
在过去十余年里,机器学习模型从“可被人读懂的统计模型”逐步演化为参数规模巨大、结构高度非线性、训练数据高度异质的复杂系统。性能的跃升带来了应用边界的扩张:从推荐、广告到医疗、司法、金融、公共治理,模型输出被越来越多地用作“行动依据”。与此同时,一个愈发尖锐的矛盾也浮出水面:当模型影响真实世界的资源分配与权利义务时,我们不仅要问“预测准不准”,还要问“为什么会这样”“它依据了什么证据”“在什么条件下不可靠”“它是否可能系统性地伤害某些人”。这便是可解释人工智能(Explainable AI, XAI)成为长期热点的根本原因之一。
但“解释”并不是一个单一目标。它既包含面向终端用户的可理解叙事,也包含面向工程师的调试证据;既可能是对单次决策的局部说明,也可能是对整体规律的全局总结;既可以追求“看上去合理”,也可以追求“与模型真实机制一致”。解释的多义性,直接导致研究与实践中常见的分歧:有人把可解释性当作透明度(模型本身易懂),有人把它当作后验说明(黑盒外再套一层解释器),有人强调人因与社会心理(解释要符合人的认知偏好),也有人强调科学性与可检验性(解释必须可证伪、可反事实检验)。这类张力在综述文献中被反复讨论:Lipton 指出“可解释性”话语往往被混用、动机彼此不兼容,从而使“解释”变成一个滑动的口号而非可操作的科学目标。 (arXiv)
进入大模型时代,问题进一步复杂化。大语言模型不仅输出标签或分数,还能输出“像解释一样”的自然语言理由,这让“解释的生成”变得廉价,却也让“解释的可信”更加困难:模型可以给出流畅且令人信服的理由,但这些理由是否真是模型内部推理的因果来源?在 NLP 社区,Jacovi & Goldberg 对“忠实性(faithfulness)与可读性/合理性(plausibility)”的区分,几乎成为后来评估讨论的坐标系;而 Lyu 等在更近期的综述中进一步系统化了“忠实解释”的方法族谱与评价范式,提示我们:当解释本身也由模型生成时,传统的“看起来对不对”很可能只衡量了可读性而非忠实性。 (ACL Anthology)
2 概念与范畴:解释、可解释性、可理解性到底在说什么
“解释”在人工智能语境中往往被赋予工程意义,但它同时是一种社会心理行为。Miller 的综述强调,社会科学关于解释的研究已经积累了大量结论:人们偏好对比性的解释(为什么是A而不是B),偏好与目的相关的解释(对我有什么用),偏好简短、可操作、与既有信念兼容的叙事;这些偏好并不保证解释忠实,却强烈影响“解释是否被接受”。因此,把 XAI 简化为“输出一组特征重要性”经常会失焦:同一解释对象,在不同受众、不同情境下需要完全不同的解释形式。 (科学直接)
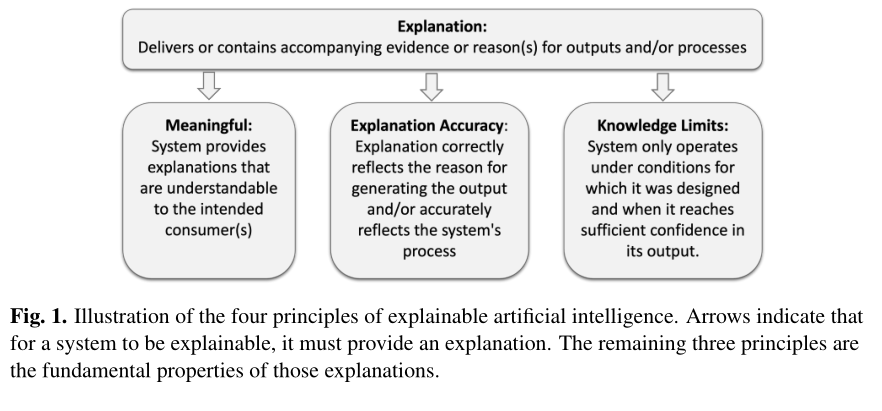
在标准与治理侧,NIST 提出“可解释AI四原则”,用更工程化的语言把目标拆成四类:系统应提供解释(Explanation),解释对目标用户应有意义(Meaningful),解释应与系统过程相一致(Explanation Accuracy),并且系统应知道自己何时超出能力边界(Knowledge Limits)。这种表述的价值在于:它把“解释”从单点产物(某张图、某段话)提升为系统属性(何时解释、解释给谁、解释是否准确、何时拒答/降级)。 (NIST出版物)
为了避免“概念先天含混”,学界常用若干对立维度把问题空间切开:透明(intrinsic)vs 后验(post-hoc),局部(local)vs 全局(global),模型无关(model-agnostic)vs 模型相关(model-specific),以人为中心(human-centered)vs 以机制为中心(mechanistic/faithfulness-centered)。Doshi-Velez & Kim 进一步提出三类评估场景:仅依赖形式指标的“功能性评估(functionally grounded)”、带有人类但不含真实任务的“人类评估(human-grounded)”、以及在真实任务中检验解释是否提升决策质量的“应用性评估(application-grounded)”。这套框架在今天仍非常实用,因为它提醒我们:许多争论并非方法优劣,而是评估场景不同导致的目标函数不同。 (arXiv)
表1 关键术语的常用界定与典型落点(“解释”不是一个指标,而是一组指标的折中)
| 术语 | 常见界定 | 典型“落地形态” | 常被忽略的风险点 |
|---|---|---|---|
| 可解释性/可理解性(Interpretability) | 人是否能理解模型/输出/依据 | 可读规则、可视化、因果叙述 | “理解”是相对的:受众差异巨大 |
| 解释(Explanation) | 对某个输出给出证据/理由 | 特征重要性、反事实、样例、自然语言理由 | 解释可以“看似合理但不忠实” |
| 忠实性(Faithfulness) | 解释是否反映模型真实因果机制 | 干预/反事实检验、删特征测性能 | 很难通过人评直接判断 (ACL Anthology) |
| 稳健性(Stability/Robustness) | 小扰动下解释是否稳定 | 邻域一致性、重复采样一致性 | 解释可能被“对抗性操纵” (arXiv) |
| 有意义(Meaningful) | 解释是否对用户有用 | 可行动建议、可争辩理由 | 可能牺牲忠实性换取“好懂” (NIST出版物) |
3 方法体系综述:从“透明模型”到“后验解释器”
XAI 的第一条路线并不是给黑盒“配翻译”,而是尽量直接使用结构上就可理解的模型。Rudin 在高风险场景中强烈主张:与其事后解释黑盒,不如从一开始就设计可解释模型;因为后验解释可能掩盖错误机制,甚至在制度层面提供“看似合规”的遮羞布。她的观点并非否认后验解释的价值,而是强调:当决策后果重大时,解释的可验证性与责任归属尤为关键,越是不能出错的地方越不应把安全押在“解释器是否靠谱”上。 (Nature)
然而工程现实是:高性能模型常常已经存在,且替换成本巨大。于是第二条路线——后验解释——成为主流实践。后验解释又分为两大思路:一类输出“特征对预测的贡献”(归因/重要性),另一类输出“如果改变哪些输入,结果会不同”(反事实/可行动解释)。前者更像诊断工具,后者更像沟通工具:它天然满足 Miller 所说的“对比性解释”偏好,因为用户往往更关心“怎样才能从拒绝变成通过”而非“模型内部的全部逻辑”。 (科学直接)
表2 主流解释方法的“坐标系”概览
| 方法族 | 局部/全局 | 模型无关/相关 | 主要输出 | 典型用途 |
|---|---|---|---|---|
| 透明模型(线性/规则/可加) | 多为全局 | 相关 | 参数/规则 | 合规、审计、可追责 (Nature) |
| 局部替身模型(LIME等) | 局部 | 无关 | 局部线性权重/文本高亮 | 单例解释、快速诊断 (KDD) |
| 一致性加性解释(SHAP) | 局部→可聚合全局 | 多为无关 | Shapley值归因 | 对比分析、特征贡献排序 (NeurIPS 会议论文集) |
| 规则锚点(Anchors) | 局部 | 无关 | 高精度规则前提 | 生成“足够条件”的解释 (华盛顿大学计算机科学主页) |
| 梯度归因(IG/Grad-CAM) | 局部 | 相关 | 像素/Token重要性图 | 视觉/文本归因、调试 (NeurIPS) |
| 概念解释(TCAV等) | 介于局部/全局 | 相关 | “概念敏感度” | 用人类概念检验模型 (arXiv) |
| 样例解释(Influence等) | 局部 | 相关/半相关 | 关键训练样本 | 数据错误定位、追责 (arXiv) |
| 反事实解释(Wachter等) | 局部 | 多为无关 | 最小可行变更 | 申诉、指导、合规沟通 (Studocu) |
3.1 局部替身模型:LIME与“可在局部被线性逼近”的想象
Ribeiro 等提出的 LIME 之所以影响深远,是因为它把解释问题转化为一个直观的工程套路:在某个样本附近采样扰动点,用黑盒模型给这些点打分,再训练一个人能读懂的小模型(常是稀疏线性模型或小规则集)去拟合这一局部行为,从而把“黑盒在这一点附近怎么看输入”翻译成“可读的权重”。 (KDD) 这一思路的魅力在于普适:不管是文本分类、图像分类还是表格模型,只要你能定义“扰动”与“局部邻域”,就能套用。与此同时,它的脆弱性也来自同一处:邻域如何定义、扰动是否符合数据分布、替身模型复杂度如何取舍,这些细节会显著改变解释结论,而这些变化对非技术用户往往不可见。正因如此,LIME 常被用作探索性工具,而不应被当作“唯一真相”。
3.2 统一归因框架:SHAP与“唯一满足一组公理”的加性解释
Lundberg & Lee 将一类常见解释形式抽象为“加性特征归因模型”,并证明在若干性质(如一致性)约束下,Shapley值提供了唯一解,从而把多个既有方法纳入统一框架并给出可计算近似。 (NeurIPS 会议论文集) 在实践中,SHAP 的强项在于可比较:你可以在不同样本间比较某特征的贡献分布,也可以把局部归因聚合为全局重要性画像。其广泛传播也得益于成熟工具链(如官方文档与 explainers 体系)。 (SHAP) 但需要反复强调的一点是:SHAP 解释的是“在给定背景分布与特征联合结构假设下,特征对预测的贡献分摊”,它不是因果结论。SHAP 文档中也专门提示过在寻求因果洞见时要格外谨慎。 (SHAP)
3.3 规则型解释:Anchors把“通常成立”换成“高精度成立”
如果说 LIME 的输出仍像“统计权重”,Anchors 则尝试输出更像人类语言的规则:在某个预测附近,找一组前提(锚点)使得只要满足这些前提,模型就以高精度给出同一预测。 (华盛顿大学计算机科学主页) 这种解释的好处在于可操作:它回答“在什么条件下你可以确信模型会这么判”。代价是覆盖率:高精度规则往往只覆盖输入空间的一小片区域。换句话说,Anchors 更像“模型行为的局部契约”,而不是“模型的整体逻辑”。
4 深度学习解释:梯度、显著图、概念与对抗脆弱性
在视觉与深度网络语境里,“解释”经常被简化为显著图(saliency map):哪些像素/区域对当前输出最重要。Grad-CAM 利用梯度在卷积特征图上做加权聚合,生成可视化的热力图,因其直观与易用而成为事实标准之一。 (SpringerLink) Integrated Gradients 则从公理化角度定义“从基线到输入的路径积分归因”,试图规避单点梯度噪声与饱和问题。 (NeurIPS) 这两类方法共同代表了“模型相关的梯度归因”路线:直接读模型的微分信息,以期得到更贴近机制的解释。
但“看起来像机制”并不意味着“真的忠实”。Adebayo 等提出的“显著图理智检验(sanity checks)”展示了一个刺痛行业的事实:不少显著图方法在随机化模型参数后仍能产生相似的可视化,这意味着它们可能更多捕捉了输入结构或可视化先验,而非模型学到的判别依据。 (NeurIPS) 更进一步,Ghorbani 等指出解释的脆弱性:在预测标签不变、输入变化几乎不可察觉的情况下,解释可以被系统性地操纵而发生巨大改变;这提示我们,解释本身也可能成为攻击面或误导源。 (arXiv) 因而,在深度学习场景里,“解释=热力图”最多只是起点,任何严肃应用都需要把解释放进可检验的评估框架里。
表3 深度网络常见解释方法、优势与主要风险
| 方法 | 核心思想 | 优势 | 主要风险/误用点 |
|---|---|---|---|
| Grad-CAM | 梯度加权卷积特征图得到定位热图 | 直观、适合视觉定位 (SpringerLink) | 可能对层选择敏感;热图“像注意力”但未必是因果 |
| Integrated Gradients | 基线→输入路径积分归因 | 公理化、可控基线 (ResearchGate) | 基线选择影响巨大;仍需忠实性检验 (NeurIPS) |
| 显著图类(统称) | 梯度/扰动生成重要性图 | 实现简单 | 可能通过 sanity checks 暴露为“非模型依赖” (NeurIPS) |
| 概念解释(TCAV) | 用人类概念方向测试敏感度 | 更接近“概念层”理解 (arXiv) | 概念数据集构造偏差;概念方向不唯一 |
| 解释稳健性研究 | 检验解释是否易被操纵 | 揭示风险边界 (arXiv) | 说明“漂亮解释”可能不可信,带来制度层误用 |
5 反事实解释:从“为什么”走向“怎么办”
在信贷拒绝、招聘筛选、风控拦截等场景里,用户的核心诉求经常不是“模型内部逻辑是什么”,而是“怎样才能得到不同结果”。Wachter 等提出的反事实解释强调:不必打开黑盒,只需给出使结果翻转的最小输入变化,即可同时满足可理解、可行动与可争辩等目标。 (Studocu) 这种解释与 Miller 所总结的人类解释偏好高度契合——它天然提供对比(A而不是B)、提供行动建议、并且避免泄露模型细节,从而在商业保密与用户权利之间取得某种张力平衡。 (科学直接)
然而反事实解释在技术上并不只是“找最近的翻转点”。如果模型输入包含不可变属性(性别、出生地)或受保护属性,反事实的可行动性与公平性就会变成硬约束;如果特征高度相关(收入与职业、教育与年龄),反事实还需遵守数据流形,否则会给出“统计上不可能”的建议。也正因此,反事实解释更适合作为“与制度结合的沟通接口”,而不是纯粹的数学最优化产物:它需要业务规则、伦理边界与合规要求共同塑形。
表4 反事实解释的“质量维度”示例(同一解释很难同时极致优化)
| 维度 | 含义 | 典型冲突 |
|---|---|---|
| 距离最小 | 变更幅度尽量小 | 可能不可行动(改不了的特征) |
| 可行动 | 变更应可由当事人实现 | 可能牺牲最小距离 |
| 合法/合规 | 不鼓励歧视、符合规则 | 可能牺牲个体最优 |
| 可信/在分布内 | 不违反数据分布常识 | 可能变得复杂难懂 |
| 稳健 | 小扰动下仍成立 | 可能牺牲简洁 |
6 样例解释与数据归因:把“责任”追溯到训练数据
当模型被质疑偏见、错误或泄露隐私时,“解释”常常意味着追责:这个输出与哪些训练样本有关?Koh & Liang 将稳健统计中的 influence functions 引入现代模型,提供一种追溯单个预测“受哪些训练点影响最大”的思路,并展示了它在调试、发现数据错误等任务上的实用性。 (arXiv) 与特征归因相比,样例归因更贴近工程修复:你不仅知道“模型看重什么特征”,还可能直接定位“哪批训练数据导致了这种偏差”,从而指向数据清洗、重采样或标注修复等具体行动。
但这一方向同样面临“解释是否稳定”的挑战:Ghorbani 等指出基于样例的解释也可能出现脆弱性,即在预测不变时解释样例发生显著变化。 (arXiv) 因而,在把样例归因用于法律或合规证据之前,仍需要严谨的稳健性评估与可重复性保障。
7 评估与“反解释陷阱”:从好看走向可检验
解释研究最难的部分,往往不是提出一个新解释器,而是证明它“有用且可信”。这正是 Doshi-Velez & Kim 所谓“解释科学尚不严谨”的根源:缺少统一定义、缺少可比基准、缺少与任务风险匹配的评估协议。 (arXiv) 在实践里,一个常见误区是把用户喜好当作忠实性:人类确实能评价解释是否清晰、是否令人信服,但 Jacovi & Goldberg 明确提醒,忠实性不是人能直接标注的对象;如果人能准确判断解释是否忠实,那么解释本身就失去了存在意义。 (ACL Anthology)
为应对这种困境,近年来出现了两条互补路径。第一条是“干预式评估”:删掉解释指出的重要特征,看预测是否显著变化;或对模型内部表示做因果干预,看解释是否预测了这种变化。第二条是“稳健性与理智检验”:Adebayo 的 sanity checks 通过随机化权重等方式检验解释是否真正依赖模型。 (NeurIPS) 与此同时,Vilone & Longo 从系统综述角度整理了“解释应满足的多种要求”以及相应评估方法,强调评价不应只看单一指标,而应明确面向谁、用于何事、承担多大风险。 (科学直接)
表5 常见评估框架与代表性观点
| 框架/观点 | 核心主张 | 代表来源 |
|---|---|---|
| 三类评估场景(功能/人类/应用) | 解释评价应与使用场景绑定 | Doshi-Velez & Kim (arXiv) |
| 忠实性≠可读性 | 人评更像“合理性”,忠实性需机制检验 | Jacovi & Goldberg (ACL Anthology) |
| 理智检验 | 随机化后解释仍像原来则说明不可信 | Adebayo et al. (NeurIPS) |
| 解释脆弱性 | 解释可被对抗操纵,需稳健性评估 | Ghorbani et al. (AAAI) |
| 多维要求与层级评估 | 解释要求多元,需层级化整理与评估 | Vilone & Longo (科学直接) |
8 NLP与大模型时代:从“注意力即解释”到“机制可解释”
在 NLP 场景中,解释问题长期与“文本依据”纠缠在一起:高亮哪些词、哪些句子是模型做出判断的依据。一度流行的说法是“注意力权重就是解释”,但这一说法在忠实性层面屡遭挑战。Jacovi & Goldberg 对此给出更一般的批评:如果我们不区分忠实性与可读性,就会把“看起来像依据”的信号误当作“真实因果依据”。 (arXiv) 更近一步,Lyu 等在综述中把忠实解释方法分为相似性、内部结构分析、反传归因、反事实干预、自解释模型等类别,并系统讨论每类方法的忠实性假设与评估策略,这对于今天处理“模型会说理由”尤其关键。 (ACL Anthology)
大语言模型使得“生成解释”几乎成为默认能力,但这并不自动带来可解释性。相反,它放大了“解释幻觉”:模型可以在不暴露真实内部机制的情况下,产出高度连贯的解释文本,甚至对解释风格进行迎合。于是,XAI 的前沿正在部分回到“机制解释(mechanistic interpretability)”:不是让模型讲故事,而是尽量还原模型内部的表示、回路与算法。近年来,Anthropic 的 transformer-circuits 系列持续发布机制解释研究与方法,包括用稀疏自编码器抽取可解释特征并讨论可扩展性;这些工作强调从“特征—回路—算法”多层级理解模型。 (变压器电路) OpenAI 也发布了与稀疏结构和可解释回路相关的研究,例如关于权重稀疏 transformer 的可解释电路以及“通过稀疏回路理解神经网络”的研究博客,试图通过结构约束与分析工具让回路更可分解、更易被人类命名与检验。 (OpenAI) 与此同时,学术界也出现面向稀疏自编码器与机制解释的综述与系统化整理(例如 2025 年在 ACL Findings 出现的 SAE 综述),反映该方向正在从“少数团队的手工技艺”走向更标准化的研究范式。 (ACL Anthology)
表6 大模型时代“解释”的两条主线及其张力
| 主线 | 典型产物 | 优势 | 主要风险 |
|---|---|---|---|
| 语言化解释(模型自述理由) | 自然语言 rationale/链式理由 | 低成本、易沟通 | 容易只提升“可读性”而非忠实性 (ACL Anthology) |
| 机制解释(回路/特征/干预) | 可解释特征、回路图、因果干预结果 | 更可检验、更接近机制 | 成本高、工具链仍在演进 (变压器电路) |
9 标准、治理与文档化:解释不是“加一个按钮”,而是生命周期工程
当 AI 进入监管视野,解释从“锦上添花”变成“制度接口”。欧盟《AI Act》围绕风险分级提出系统性义务,其中对于高风险系统强调透明性与向部署者提供信息(例如能力与限制、如何理解输出、风险与维护等),使得“解释/信息提供”成为合规的一部分。 (欧洲人工智能法案) 与之相呼应,模型与数据文档化框架(Model Cards、Datasheets for Datasets)把“如何报告模型表现、适用边界、数据来源与限制”制度化,目的不是生成漂亮文档,而是让组织在发布与部署时对风险、偏差与失效模式承担更清晰的责任。 (arXiv)
从工程视角看,这意味着 XAI 不应只存在于“事后给一张图”的界面层,而应嵌入从需求、数据、训练、评测、上线、监控到迭代的全链路:在训练前明确解释需求与受众,在训练中进行可解释性诊断与数据归因,在上线后用解释辅助监控漂移与异常,在事故发生时用可追溯证据支持复盘与问责。否则,解释会沦为合规“装饰”,既不能提升安全,也不能提升信任。
10 未来方向:更忠实、更可用、更可治理
未来几年,XAI 可能会沿着三条“更难但更必要”的方向演进。第一条是忠实性:把解释从审美问题变成科学问题,强调可干预、可证伪、可重复,并对解释的脆弱性给出系统防护。Adebayo 的理智检验与 Ghorbani 的脆弱性研究已经告诉我们:不经检验的解释很可能是一种幻象。 (NeurIPS) 第二条是人因与任务融合:解释不是给所有人同一种形态,而是与用户的决策任务、时间压力、专业背景相耦合;Miller 与 NIST 的工作提醒我们,“有意义”本身是解释质量的重要组成部分。 (科学直接) 第三条是治理化:解释与透明性将越来越多地以法律义务、行业标准、文档模板、审计流程的形式固化;Model Cards、Datasheets 与 AI Act 的透明义务已经把这条路打开。 (arXiv)
在大模型时代,这三条路线会更紧密地缠绕在一起:语言化解释提高可用性却可能降低忠实性,机制解释提高忠实性却提升门槛与成本,治理要求推动标准化却也可能诱发“合规形式主义”。真正成熟的 XAI 体系,必须能在这些张力之间给出可操作的折中:明确场景风险、明确受众需求、明确可检验指标,并在全生命周期持续校验解释是否仍然可靠。
参考文献
-
Ribeiro, M. T., Singh, S., & Guestrin, C. “Why Should I Trust You?” Explaining the Predictions of Any Classifier. KDD 2016. (KDD)
-
Lundberg, S. M., & Lee, S.-I. A Unified Approach to Interpreting Model Predictions. NeurIPS 2017. (NeurIPS 会议论文集)
-
Ribeiro, M. T., Singh, S., & Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. AAAI 2018. (华盛顿大学计算机科学主页)
-
Sundararajan, M., Taly, A., & Yan, Q. Axiomatic Attribution for Deep Networks (Integrated Gradients). ICML 2017(常见版本见 arXiv/公开稿)。 (ResearchGate)
-
Selvaraju, R. R., et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. IJCV 2020(早期版本广泛流传于 2017-2018)。 (SpringerLink)
-
Kim, B., et al. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). ICML 2018. (arXiv)
-
Koh, P. W., & Liang, P. Understanding Black-box Predictions via Influence Functions. ICML 2017. (arXiv)
-
Wachter, S., Mittelstadt, B., & Russell, C. Counterfactual Explanations Without Opening the Black Box. 2017/2018(常见为 GDPR 语境论文)。 (Studocu)
-
Doshi-Velez, F., & Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. 2017. (arXiv)
-
Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. Artificial Intelligence, 2019. (科学直接)
-
Lipton, Z. C. The Mythos of Model Interpretability. 2016(及其后在 CACM/Queue 的扩展讨论)。 (arXiv)
-
Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nature Machine Intelligence, 2019. (Nature)
-
Adebayo, J., et al. Sanity Checks for Saliency Maps. NeurIPS 2018. (NeurIPS)
-
Ghorbani, A., Abid, A., & Zou, J. Interpretation of Neural Networks is Fragile. AAAI 2019 / arXiv 2017. (AAAI)
-
Jacovi, A., & Goldberg, Y. Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? ACL 2020. (ACL Anthology)
-
Lyu, Q., Apidianaki, M., & Callison-Burch, C. Towards Faithful Model Explanation in NLP: A Survey. Computational Linguistics, 2024. (ACL Anthology)
-
NIST IR 8312. Four Principles of Explainable Artificial Intelligence. 2021. (NIST出版物)
-
Broniatowski, D. A. Psychological Foundations of Explainability and Interpretability in AI. NIST IR 8367. 2021. (NIST出版物)
-
Vilone, G., & Longo, L. Notions of explainability and evaluation approaches for explainable AI. Information Fusion, 2021. (科学直接)
-
Mitchell, M., et al. Model Cards for Model Reporting. 2018/2019. (arXiv)
-
Gebru, T., et al. Datasheets for Datasets. 2018(及后续在 CACM 的版本)。 (arXiv)
-
EU AI Act 透明与信息提供条款解读(Article 13 等)与议会信息页。 (欧洲人工智能法案)
-
Anthropic Transformer Circuits(机制可解释系列与“Scaling Monosemanticity”等)。 (变压器电路)
-
OpenAI 关于稀疏回路与可解释性研究材料(示例:权重稀疏 transformer、稀疏回路理解)。 (OpenAI)
-
ACL Findings 2025:Sparse Autoencoders 综述(LLM 机制解释方向的整理)。 (ACL Anthology)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)