LangChain4j实战之五:图像模型
在LangChain4j框架下体验大模型的图片处理能力
·
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
LangChain4j实战全系列链接
本篇概览
- 从标题就能看出本篇的目标非常明确,就是学习图像有关的模型,简单来说分为三部分:创建、修改、理解,他们分别用到了不同的模型,这里用表格对它们详细说明
| 功能 | 模型 | 模型对象创建方式 |
|---|---|---|
| 创建图片 | wan2.2-t2i-plus | 阿里的dashscope库,提供通义万相2的build方法 |
| 修改图片 | qwen-image-edit-plus | 没有模型对象,阿里的dashscope库,提供调用API |
| 理解图片 | qwen3-vl-plus | 阿里模型提供OpenAI兼容服务,所以用OpenAI模型对象 |
- 接下来立即动手,顺序是先编码再运行体验
源码下载(觉得作者啰嗦的,直接在这里下载)
- 如果您只想快速浏览完整源码,可以在GitHub下载代码直接运行,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
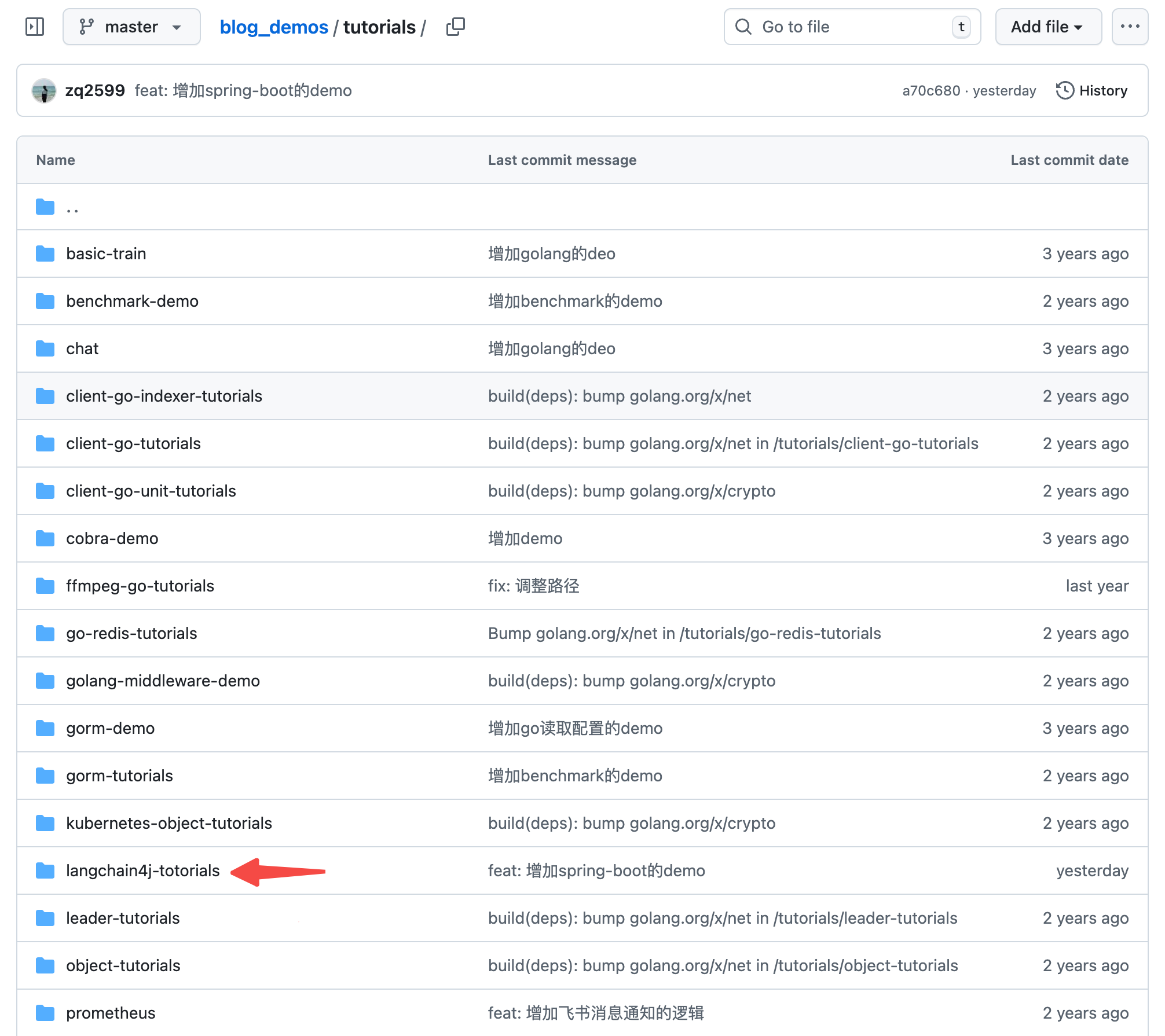
- 这个git项目中有多个文件夹,本篇的源码在langchain4j-tutorials文件夹下,如下图红色箭头所示:
编码:父工程调整
- 《准备工作》中创建了整个《LangChain4j实战》系列代码的父工程,本篇实战会在父工程下新建一个子工程,所以这里要对父工程的pom.xml做少量修改
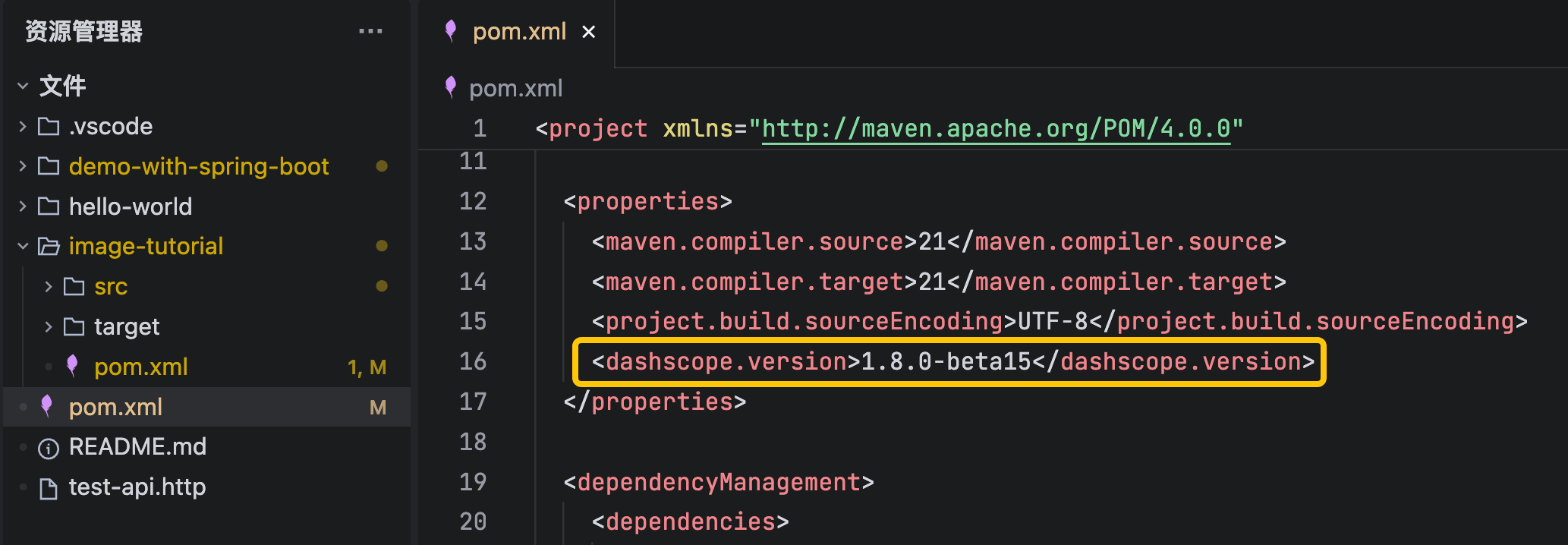
- 增加一个自定义变量dashscope.version,这样可以把所有依赖库的版本号集中起来管理,如下图黄框所示
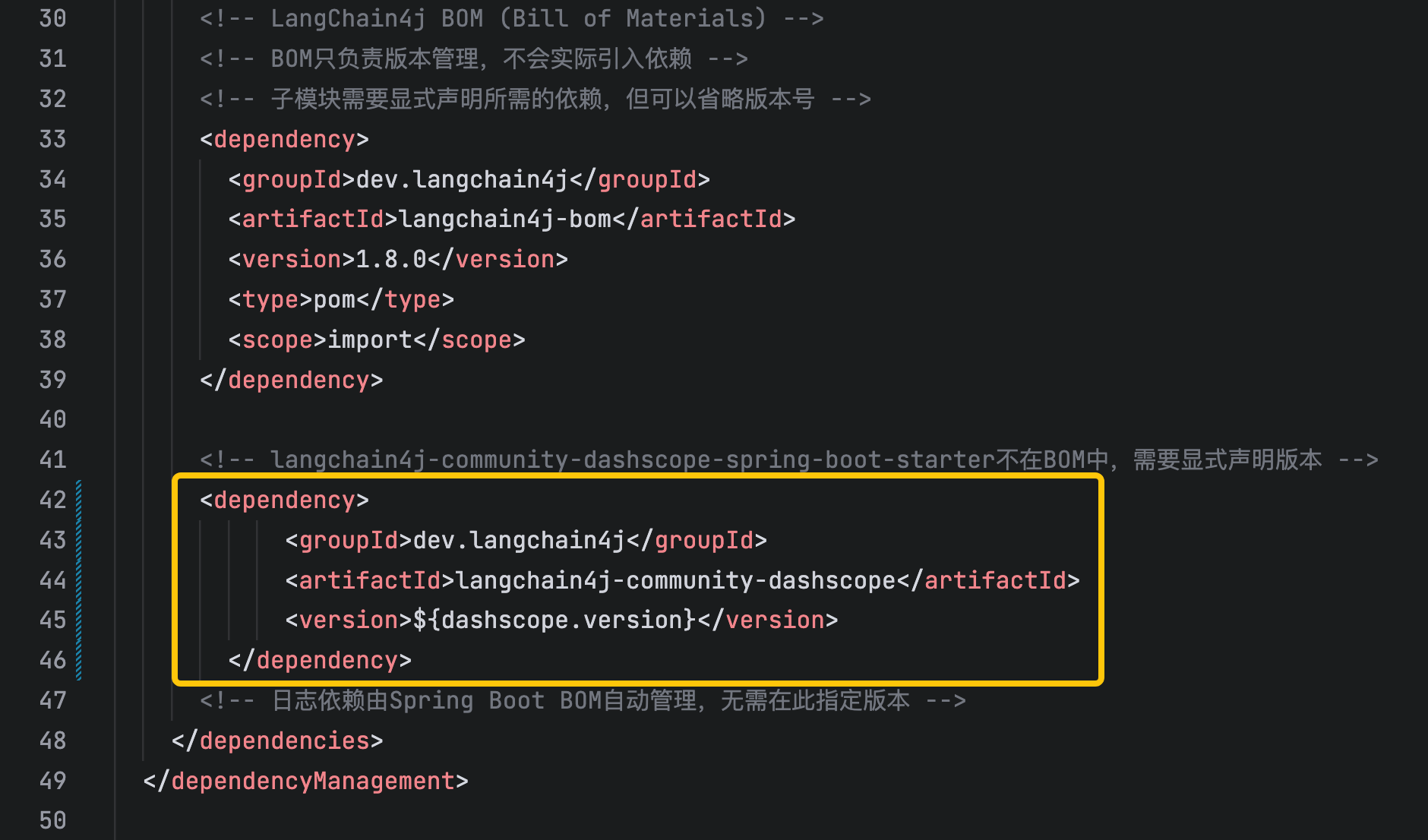
- 增加阿里模型SDK的依赖,如下图黄框所示
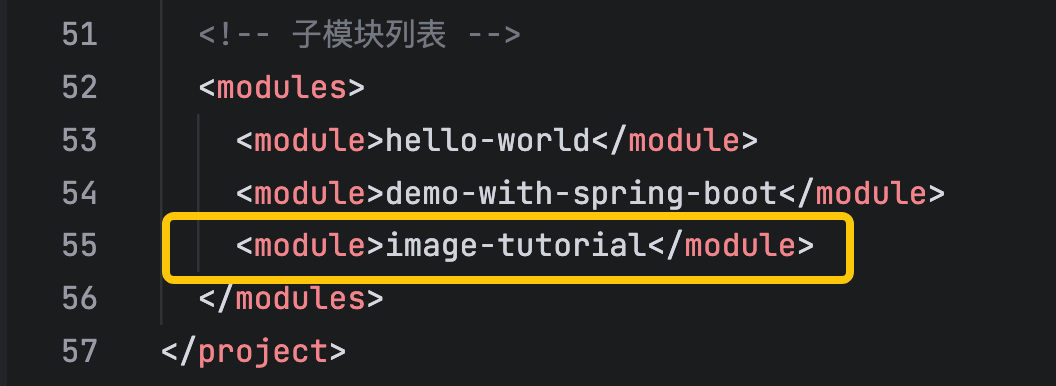
- modules中增加一个子工程,如下图黄框所示
编码:新增子工程
- 新增名为image-tutorial的子工程
- langchain4j-totorials目录下新增名image-tutorial为的文件夹
- image-tutorial文件夹下新增pom.xml,内容如下,可见主要是引入阿里SDK的依赖(langchain4j-community-dashscope)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.bolingcavalry</groupId>
<artifactId>langchain4j-totorials</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>image-tutorial</artifactId>
<packaging>jar</packaging>
<dependencies>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot Test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- JUnit Jupiter Engine -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<scope>test</scope>
</dependency>
<!-- Mockito Core -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<scope>test</scope>
</dependency>
<!-- Mockito JUnit Jupiter -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-junit-jupiter</artifactId>
<scope>test</scope>
</dependency>
<!-- LangChain4j Core -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-core</artifactId>
</dependency>
<!-- LangChain4j OpenAI支持(用于通义千问的OpenAI兼容接口) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<!-- 官方 langchain4j(包含 AiServices 等服务类) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Spring Boot Maven Plugin -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>3.3.5</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
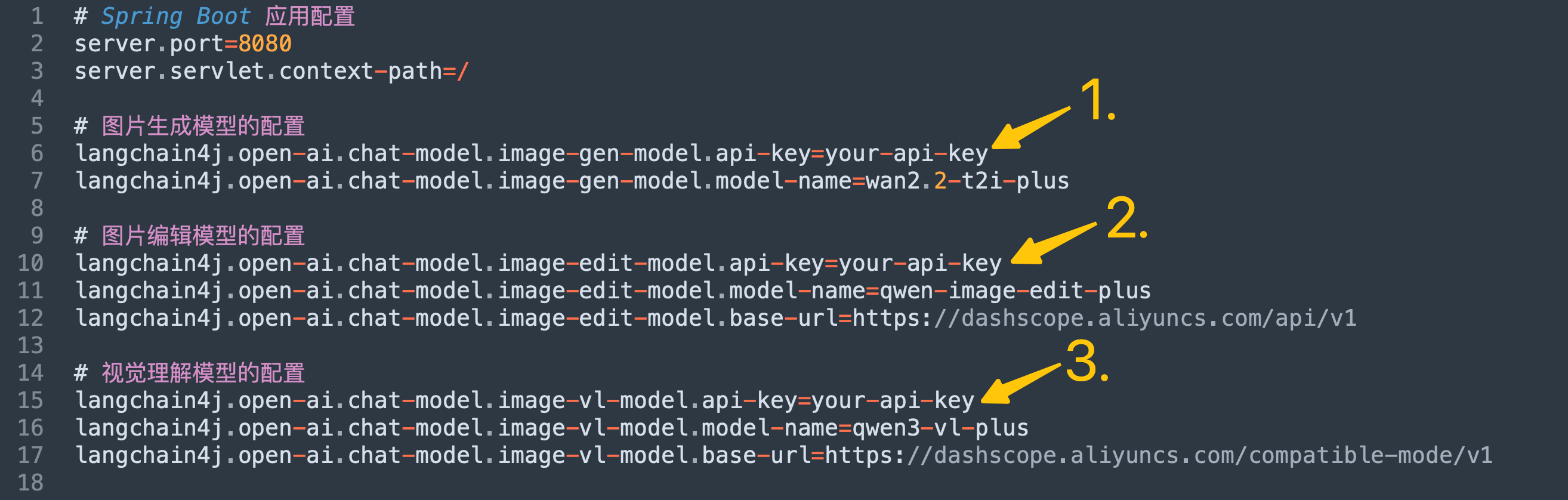
- 在langchain4j-totorials/image-tutorial/src/main/resources新增配置文件application.properties,内容如下,主要是三个模型的配置信息,记得把your-api-key换成您自己的apikey
# Spring Boot 应用配置
server.port=8080
server.servlet.context-path=/
# 图片生成模型的配置
langchain4j.open-ai.chat-model.image-gen-model.api-key=your-api-key
langchain4j.open-ai.chat-model.image-gen-model.model-name=wan2.2-t2i-plus
# 图片编辑模型的配置
langchain4j.open-ai.chat-model.image-edit-model.api-key=your-api-key
langchain4j.open-ai.chat-model.image-edit-model.model-name=qwen-image-edit-plus
langchain4j.open-ai.chat-model.image-edit-model.base-url=https://dashscope.aliyuncs.com/api/v1
# 视觉理解模型的配置
langchain4j.open-ai.chat-model.image-vl-model.api-key=your-api-key
langchain4j.open-ai.chat-model.image-vl-model.model-name=qwen3-vl-plus
langchain4j.open-ai.chat-model.image-vl-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
# 日志配置
logging.level.root=INFO
logging.level.com.bolingcavalry=DEBUG
logging.pattern.console=%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
# 应用名称
spring.application.name=image-tutorial
- 新增启动类,依旧平平无奇
package com.bolingcavalry;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* Spring Boot应用程序的主类
*/
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
- 现在新的子工程已经创建好了,接下来开始写功能代码
编码:数据结构
- 如下图红框,前面在梳理三种模型时,提到修改图片的模型没有对应的模型对象,而是靠调用API来完成功能的,所以要准备一个数据结构,里面保存了调用API时用到的数据,如apikey

- 这个数据结构名为ImageEditModelParam,没有任何功能,单纯的保存数据
package com.bolingcavalry.config;
import lombok.Data;
@Data
public class ImageEditModelParam {
private String modelName;
private String baseUrl;
private String apiKey;
}
编码:工具类
- 在理解图片的功能中,需要把图片内容传给大模型,所以这里做个工具类,专门负责根据URL下载图片
package com.bolingcavalry.util;
import dev.langchain4j.data.image.Image;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.StandardCopyOption;
import java.util.Base64;
/**
* 图片处理工具类,用于处理在线图片的加载和保存
*/
public class ImageUtils {
private static final Logger logger = LoggerFactory.getLogger(ImageUtils.class);
/**
* 从URL创建Image对象
* @param imageUrl 图片的URL地址
* @return langchain4j的Image对象
* @throws IOException 如果图片加载失败
*/
public static Image createImageFromUrl(String imageUrl) throws IOException {
logger.info("从URL创建Image对象: {}", imageUrl);
// 下载图片数据并转换为字节数组
byte[] imageBytes = downloadImage(imageUrl);
// 将字节数组转换为Base64编码
String base64Data = Base64.getEncoder().encodeToString(imageBytes);
logger.info("图片下载成功,原始大小: {} 字节,Base64编码后: {} 字符",
imageBytes.length, base64Data.length());
// 使用Base64数据创建Image对象
Image image = Image.builder()
.base64Data(base64Data)
.build();
return image;
}
/**
* 下载图片并返回字节数组
* @param imageUrl 图片的URL地址
* @return 图片的字节数组
* @throws IOException 如果下载失败
*/
private static byte[] downloadImage(String imageUrl) throws IOException {
try (InputStream in = new URL(imageUrl).openStream();
ByteArrayOutputStream out = new ByteArrayOutputStream()) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = in.read(buffer)) != -1) {
out.write(buffer, 0, bytesRead);
}
return out.toByteArray();
}
}
/**
* 从URL下载图片并保存到本地文件
* @param imageUrl 图片的URL地址
* @param targetPath 保存到本地的文件路径
* @return 保存的文件路径
* @throws IOException 如果下载或保存失败
*/
public static Path saveImageFromUrl(String imageUrl, Path targetPath) throws IOException {
logger.info("从URL下载图片到本地: {} -> {}", imageUrl, targetPath);
// 确保目标目录存在
Path parentDir = targetPath.getParent();
if (parentDir != null) {
Files.createDirectories(parentDir);
}
// 使用Java标准库下载图片
try (InputStream in = new URL(imageUrl).openStream()) {
Files.copy(in, targetPath, StandardCopyOption.REPLACE_EXISTING);
}
logger.info("图片保存成功: {}", targetPath);
return targetPath;
}
/**
* 获取图片的Base64编码数据
* @param image langchain4j的Image对象
* @return Base64编码的字符串
*/
public static String getImageBase64(Image image) {
String base64Data = image.base64Data();
if (base64Data == null) {
logger.error("Image对象的base64Data为null");
throw new IllegalStateException("图片数据未正确加载");
}
return base64Data;
}
/**
* 将Base64编码的图片数据保存为文件
* @param base64Data Base64编码的图片数据
* @param targetPath 保存到本地的文件路径
* @return 保存的文件路径
* @throws IOException 如果保存失败
*/
public static Path saveBase64Image(String base64Data, Path targetPath) throws IOException {
logger.info("保存Base64编码的图片到: {}", targetPath);
// 确保目标目录存在
Path parentDir = targetPath.getParent();
if (parentDir != null) {
Files.createDirectories(parentDir);
}
// 解码Base64数据并保存
byte[] imageBytes = Base64.getDecoder().decode(base64Data);
Files.write(targetPath, imageBytes);
logger.info("Base64图片保存成功: {}, 大小: {} 字节", targetPath, imageBytes.length);
return targetPath;
}
}
编码:配置类
- 配置类LangChain4jConfig会拿到properties中的配置信息,在创建模型实例时传入这些配置,另外前面提到的数据结构ImageEditModelParam也在这里创建
package com.bolingcavalry.config;
import dev.langchain4j.community.model.dashscope.WanxImageModel;
import dev.langchain4j.community.model.dashscope.WanxImageSize;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* LangChain4j配置类
*/
@Configuration
public class LangChain4jConfig {
// 图片生成模型的配置
@Value("${langchain4j.open-ai.chat-model.image-gen-model.api-key}")
private String imageGenModelApiKey;
@Value("${langchain4j.open-ai.chat-model.image-gen-model.model-name}")
private String imageGenModelName;
// 图片编辑模型的配置
@Value("${langchain4j.open-ai.chat-model.image-edit-model.api-key}")
private String imageEditModelApiKey;
@Value("${langchain4j.open-ai.chat-model.image-edit-model.model-name}")
private String imageEditModelName;
@Value("${langchain4j.open-ai.chat-model.image-edit-model.base-url}")
private String imageEditModelBaseUrl;
// 视觉理解模型的配置
@Value("${langchain4j.open-ai.chat-model.image-vl-model.api-key}")
private String imageVLModelApiKey;
@Value("${langchain4j.open-ai.chat-model.image-vl-model.model-name}")
private String imageVLModelName;
@Value("${langchain4j.open-ai.chat-model.image-vl-model.base-url}")
private String imageVLModelBaseUrl;
/**
* 创建并配置用于图像生成的OpenAiChatModel实例
*
* @return OpenAiChatModel实例,Bean名称为imageGenModel
*/
@Bean("imageGenModel")
public WanxImageModel imageGenModel() {
return WanxImageModel.builder()
.apiKey(imageGenModelApiKey)
.modelName(imageGenModelName)
.size(WanxImageSize.SIZE_1024_1024)
.build();
}
/**
* 创建数据结构实例,这只是个保管数据的对象,里面包含了图像编辑模型的配置参数
*
* @return ImageEditModelParam实例,Bean名称为imageEditModelParam
*/
@Bean("imageEditModelParam")
public ImageEditModelParam imageEditModelParam() {
ImageEditModelParam param = new ImageEditModelParam();
param.setModelName(imageEditModelName);
param.setBaseUrl(imageEditModelBaseUrl);
param.setApiKey(imageEditModelApiKey);
return param;
}
/**
* 创建并配置用于视觉理解的OpenAiChatModel实例
*
* @return OpenAiChatModel实例,Bean名称为imageVLModel
*/
@Bean("imageVLModel")
public OpenAiChatModel imageVLModel() {
return OpenAiChatModel.builder()
.apiKey(imageVLModelApiKey)
.modelName(imageVLModelName)
.baseUrl(imageVLModelBaseUrl)
.build();
}
}
编码:服务类(重要)
- 最重要的代码就是服务类了,这里是完成具体业务功能的地方,先看代码,有几处重要的地方稍后会细说
package com.bolingcavalry.service;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.bolingcavalry.config.ImageEditModelParam;
import com.bolingcavalry.util.ImageUtils;
import dev.langchain4j.community.model.dashscope.WanxImageModel;
import dev.langchain4j.data.image.Image;
import dev.langchain4j.data.message.*;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.output.Response;
import com.alibaba.dashscope.common.Role;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
/**
* 通义千问服务类,用于与通义千问模型进行交互
*/
@Service
public class QwenService {
private static final Logger logger = LoggerFactory.getLogger(QwenService.class);
// 注入OpenAiChatModel,用于图像理解任务
private final OpenAiChatModel imageVLModel;
// 注入WanxImageModel,用于图像生成任务
private final WanxImageModel imageGenModel;
// 注入WanxImageModel,用于图像编辑任务
private final ImageEditModelParam imageEditModelParam;
/**
* 构造函数,通过依赖注入获取QwenChatModel实例
*
* @param openAiChatModel QwenChatModel实例
* @param imageModel 用于图像理解的QwenChatModel实例
* @param imageGenModel 用于图像生成的QwenChatModel实例
*/
public QwenService(@Qualifier("imageVLModel") OpenAiChatModel imageVLModel,
@Qualifier("imageGenModel") WanxImageModel imageGenModel,
@Qualifier("imageEditModelParam") ImageEditModelParam imageEditModelParam) {
this.imageVLModel = imageVLModel;
this.imageGenModel = imageGenModel;
this.imageEditModelParam = imageEditModelParam;
}
/**
* 使用图片理解模型根据提示词处理图片
*
* @param imageUrl 图片URL
* @param prompt 图片处理提示词
* @return 处理结果或错误信息
*/
public String useImage(String imageUrl, String prompt) {
try {
logger.info("开始处理图片: {}", imageUrl);
// 使用ImageUtils类来创建Image对象,这样可以确保图片数据被正确加载
Image image = ImageUtils.createImageFromUrl(imageUrl);
// 验证图片是否成功加载(通过检查base64数据是否存在且有一定长度)
String base64Data = ImageUtils.getImageBase64(image);
if (base64Data == null || base64Data.isEmpty() || base64Data.length() < 10) {
logger.error("图片加载失败:Base64数据无效或为空");
return "图片加载失败,请检查URL或网络连接[from useImage]";
}
logger.info("图片成功加载,Base64数据长度: {} 字符", base64Data.length());
// 创建图片内容
ImageContent imageContent = new ImageContent(image, ImageContent.DetailLevel.HIGH);
// 用户提问
UserMessage messages = UserMessage.from(List.of(
TextContent.from(prompt),
imageContent));
// 调用模型进行处理
logger.info("将图片内容发送给模型处理...");
String result = imageVLModel.chat(messages).aiMessage().text();
logger.info("模型返回结果: {}", result);
return result + "[from useImage]";
} catch (Exception e) {
logger.error("处理图片时发生错误: {}", e.getMessage(), e);
return "处理图片时发生错误: " + e.getMessage() + "[from useImage]";
}
}
/**
* 使用通义千问qwen3-image-plus模型生成图片
*
* @param prompt 图片生成提示词
* @return 生成的图片URL或相关信息
*/
public String generateImage(String prompt, int imageNum) {
try {
logger.info("开始生成图片,提示词: {}", prompt);
// 使用imageGenModel生成图片
Response<List<Image>> result = imageGenModel.generate(prompt, imageNum);
logger.info("图片生成成功,结果: {}", result);
return result + "[from generateImage]";
} catch (Exception e) {
logger.error("生成图片时发生错误: {}", e.getMessage(), e);
return "生成图片时发生错误: " + e.getMessage() + "[from generateImage]";
}
}
public String editImage(List<String> imageUrls, String prompt) {
MultiModalConversation conv = new MultiModalConversation();
var contents = new ArrayList<Map<String, Object>>();
for (String imageUrl : imageUrls) {
contents.add(Collections.singletonMap("image", imageUrl));
}
contents.add(Collections.singletonMap("text", prompt));
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(contents)
.build();
// qwen-image-edit-plus支持输出1-6张图片,此处以两张为例
Map<String, Object> parameters = new HashMap<>();
parameters.put("watermark", false);
parameters.put("negative_prompt", " ");
parameters.put("n", 2);
parameters.put("prompt_extend", true);
// 仅当输出图像数量n=1时支持设置size参数,否则会报错
// parameters.put("size", "1024*2048");
MultiModalConversationParam param = MultiModalConversationParam.builder()
.apiKey(imageEditModelParam.getApiKey())
.model(imageEditModelParam.getModelName())
.messages(Collections.singletonList(userMessage))
.parameters(parameters)
.build();
try {
MultiModalConversationResult result = conv.call(param);
return result + "[from editImage]";
} catch (Exception e) {
logger.error("编辑图片时发生错误: {}", e.getMessage(), e);
return "编辑图片时发生错误: " + e.getMessage() + "[from editImage]";
}
}
}
- 这里说一下几处重要的地方
- 生成图片时,用的是WanxImageModel实例,这是通义万相2的专用模型对象
- 编辑图片时,使用了MultiModalConversation的call方法,并未使用模型对象
- 理解图片时,使用的模型对象是OpenAI兼容的OpenAiChatModel对象,因为该模型提供了OpenAI兼容的接口,另外就是要先把图片下载好再转为base64传给模型
编码:http响应(controller类)
- 最后就是http响应的代码了,这样就能通过不同的http请求来调用各个service服务,有一处要注意的是定义了数据结构PromptRequest来接收http请求参数
package com.bolingcavalry.controller;
import com.bolingcavalry.service.QwenService;
import lombok.Data;
import java.util.List;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 通义千问控制器,处理与大模型交互的HTTP请求
*/
@RestController
@RequestMapping("/api/qwen")
public class QwenController {
private final QwenService qwenService;
/**
* 构造函数,通过依赖注入获取QwenService实例
*
* @param qwenService QwenService实例
*/
public QwenController(QwenService qwenService) {
this.qwenService = qwenService;
}
/**
* 提示词请求实体类
*/
@Data
static class PromptRequest {
private String prompt;
private int imageNum;
private String imageUrl;
private List<String> imageUrls;
}
/**
* 响应实体类
*/
@Data
static class Response {
private String result;
public Response(String result) {
this.result = result;
}
}
/**
* 检查请求体是否有效
*
* @param request 包含提示词的请求体
* @return 如果有效则返回null,否则返回包含错误信息的ResponseEntity
*/
private ResponseEntity<Response> check(PromptRequest request) {
if (request == null || request.getPrompt() == null || request.getPrompt().trim().isEmpty()) {
return ResponseEntity.badRequest().body(new Response("提示词不能为空"));
}
return null;
}
/**
* 处理POST请求,接收提示词并返回模型响应
*
* @param request 包含提示词的请求体
* @return 包含模型响应的ResponseEntity
*/
@PostMapping("/useimage")
public ResponseEntity<Response> useImage(@RequestBody PromptRequest request) {
ResponseEntity<Response> checkRlt = check(request);
if (checkRlt != null) {
return checkRlt;
}
try {
// 调用QwenService获取模型响应
String response = qwenService.useImage(request.getImageUrl(), request.getPrompt());
return ResponseEntity.ok(new Response(response));
} catch (Exception e) {
// 捕获异常并返回错误信息
return ResponseEntity.status(500).body(new Response("请求处理失败: " + e.getMessage()));
}
}
@PostMapping("/generateimage")
public ResponseEntity<Response> generateImage(@RequestBody PromptRequest request) {
ResponseEntity<Response> checkRlt = check(request);
if (checkRlt != null) {
return checkRlt;
}
try {
// 调用QwenService获取模型响应
String response = qwenService.generateImage(request.getPrompt(), request.getImageNum());
return ResponseEntity.ok(new Response(response));
} catch (Exception e) {
// 捕获异常并返回错误信息
return ResponseEntity.status(500).body(new Response("请求处理失败: " + e.getMessage()));
}
}
@PostMapping("/editimage")
public ResponseEntity<Response> editImage(@RequestBody PromptRequest request) {
ResponseEntity<Response> checkRlt = check(request);
if (checkRlt != null) {
return checkRlt;
}
try {
// 调用QwenService获取模型响应
String response = qwenService.editImage(request.getImageUrls(), request.getPrompt());
return ResponseEntity.ok(new Response(response));
} catch (Exception e) {
// 捕获异常并返回错误信息
return ResponseEntity.status(500).body(new Response("请求处理失败: " + e.getMessage()));
}
}
}
- 这个controller没有什么难度,就是三个http接口的响应,具体内容都是直接调用service的能力
- 至此,编码结束,咱们跑起来体验一下能力吧
- 再次提醒:要把application.properties中的三个api-key替换成您自己的apikey,如下图
运行
- 在image-tutorial目录执行以下命令即可启动应用
mvn spring-boot:run
验证:生成图片
- 首先体验文生图片的功能,就是输入提示词让大模型生成图片
- 继续使用REST Client插件,请求信息如下,可见是要求大模型生成两张图片
### POST 使用图像模型生成图片
POST http://localhost:8080/api/qwen/generateimage
Content-Type: application/json
Accept: application/json
{
"prompt": "生成一张图片,内容是三国演义中的威震逍遥津",
"imageNum": 2
}
- 得到原始响应如下,可见是个JSON,里面的url字段就是图片的地址
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Date: Sun, 07 Dec 2025 01:01:23 GMT
Connection: close
{
"result": "Response { content = [Image { url = \"https://dashscope-result-wlcb-acdr-1.oss-cn-wulanchabu-acdr-1.aliyuncs.com/1d/cd/20251207/df817e52/97abf67f-7ff6-4360-98b1-8f40f9ac03181606122819.png?Expires=1765155682&OSSAccessKeyId=LTAI5tKPD3TMqf2Lna1fASuh&Signature=%2BIy41kMW3epTejDskb4O9hv23FA%3D\", base64Data = null, mimeType = null, revisedPrompt = \"史诗级战争场景绘画,东吴大军围攻合肥,张辽披甲持戟立于城楼,目光凌厉,战袍猎猎。脚下尸横遍野,烟尘滚滚,远处战马嘶鸣,箭雨纷飞。天空阴沉,乌云压城,火光与金属反光交织。背景可见“逍遥津”石碑残垣。写实工笔重彩风格,细节精密,动态张力十足,广角远景构图。\" }, Image { url = \"https://dashscope-result-wlcb-acdr-1.oss-cn-wulanchabu-acdr-1.aliyuncs.com/1d/38/20251207/df817e52/97abf67f-7ff6-4360-98b1-8f40f9ac03181606122820.png?Expires=1765155682&OSSAccessKeyId=LTAI5tKPD3TMqf2Lna1fASuh&Signature=24dbtD%2BaFtOlPGhOf5C%2BYlB1Jvc%3D\", base64Data = null, mimeType = null, revisedPrompt = \"史诗级战争场景绘画,东吴大军围攻合肥,张辽披甲持戟立于城楼,目光凌厉,战袍猎猎。脚下尸横遍野,烟尘滚滚,远处战马嘶鸣,箭雨纷飞。天空阴沉,乌云压城,火光与金属反光交织。背景可见“逍遥津”石碑残垣。写实工笔重彩风格,细节精密,动态张力十足,广角远景构图。\" }], tokenUsage = null, finishReason = null, metadata = {} }[from generateImage]"
}
- 复制一个上述url字段的值,在浏览器打开,看到效果还是不错的

- 另外就是响应中的revisedPrompt字段,该字段含义是:模型在内部对原始 prompt 做“智能改写”后,最终真正用于扩散生成的提示词文本,有了这个文本,我们可以拿来继续修改,以生成更符合要求的图片
验证:编辑图片
- 编辑图片的功能是输入几张图片,然后告诉大模型拿着这些图片做什么
- 请求如下,图一是一个女生,图二是一件裙子,图三是个人体姿态说明
### POST 使用图像模型编辑图片
POST http://localhost:8080/api/qwen/editimage
Content-Type: application/json
Accept: application/json
{
"prompt": "图1中的女生穿着图2中的黑色裙子按图3的姿势坐下",
"imageUrls": [
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png"
]
}
- 响应如下
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Date: Sun, 07 Dec 2025 14:01:11 GMT
Connection: close
{
"result": "MultiModalConversationResult(requestId=2afcdb5d-2e50-42f7-bf01-6479887cd222, usage=MultiModalConversationUsage(inputTokens=null, outputTokens=null, totalTokens=null, imageTokens=null, videoTokens=null, audioTokens=null, imageCount=2, width=832, height=1248, seconds=null, inputTokensDetails=null, outputTokensDetails=null, characters=null), output=MultiModalConversationOutput(choices=[MultiModalConversationOutput.Choice(finishReason=null, message=MultiModalMessage(role=assistant, content=[{image=https://dashscope-result-hz.oss-cn-hangzhou.aliyuncs.com/7d/eb/20251207/31eda923/f546ac30-5076-4b23-917a-d25e8c766636-1.png?Expires=1765721870&OSSAccessKeyId=LTAI5tKPD3TMqf2Lna1fASuh&Signature=%2FdUYzAW2TMCiyC83uJ2LmiZx4Mo%3D}, {image=https://dashscope-result-hz.oss-cn-hangzhou.aliyuncs.com/7d/44/20251207/31eda923/98eacf90-372a-496c-a6d8-c9d270219b0d-1.png?Expires=1765721870&OSSAccessKeyId=LTAI5tKPD3TMqf2Lna1fASuh&Signature=zcDCzOrmJtac9kaB%2B0d2C8qI5zM%3D}], toolCalls=null, toolCallId=null, name=null, reasoningContent=null, annotations=null))], audio=null, finishReason=null))[from editImage]"
}
- 最终生成了两张图片,取一张看看效果,确实是修改了原始图片的衣服和身体姿态

验证:理解图片
- 最后体验一下理解图片的大模型,把一张图片传给大模型,让它返回理解的结果
- 图片就用刚刚编辑得到的那张吧,请求如下
### POST 使用 ChatRequest 作为入参
POST http://localhost:8080/api/qwen/useimage
Content-Type: application/json
Accept: application/json
{
"imageUrl": "https://dashscope-result-hz.oss-cn-hangzhou.aliyuncs.com/7d/eb/20251207/31eda923/f546ac30-5076-4b23-917a-d25e8c766636-1.png?Expires=1765721870&OSSAccessKeyId=LTAI5tKPD3TMqf2Lna1fASuh&Signature=%2FdUYzAW2TMCiyC83uJ2LmiZx4Mo%3D",
"prompt": "图片中的人手上拿着什么?"
}
- 响应如下,可见理解的非常准确
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Date: Sun, 07 Dec 2025 14:13:55 GMT
Connection: close
{
"result": "根据图片内容,图中女子**右手拿着一把浅色的圆形团扇**。\n\n这把扇子具有以下特征:\n* **形状**:圆形(或近似椭圆形),是典型的“团扇”样式。\n* **材质**:扇面由细密的竹条或类似植物纤维编织而成,呈浅黄色或米色。\n* **扇柄**:与扇面颜色和材质一致,是一根细长的木柄或竹柄。\n\n她将这把团扇举在脸侧,姿态优雅。同时,她的左手边石台上还放着一块切好的西瓜。[from useImage]"
}
- 至此,图片模型的开发和体验就全部完成了,如果您正在开发图片相关的AI应用,希望本文能给您提供一些参考,后面的文章中,咱们还会继续深入学习LangChain4j的各种能力
你不孤单,欣宸原创一路相伴

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)