CVPR 2024|TRINS:迈向具备阅读能力的多模态语言模型
大型多模态语言模型在图像理解与编辑上表现卓越,但多数经视觉调优的模型受训练数据限制,难以理解图像中嵌入的文本。为此,本研究提出 TRINS 数据集(富含文本的图像指令数据集),核心目标是提升这类模型的文本阅读能力。该数据集基于 LAION (即大规模人工智能开放网络)构建,采用机器与人类辅助结合的混合标注策略,包含 39,153 张含文本图像、对应描述及 102,437 个问答样本,且每条标注平均

论文地址:http://arxiv.org/pdf/2406.06730v1
一、论文信息
- 题目:TRINS: Towards Multimodal Language Models that Can Read
- 作者: Hongyun Zhou, Xiangyu Lu, Wang Xu, Conghui Zhu, Tiejun Zhao, Muyun YangRuiyi Zhang , Yanzhe Zhang , Jian Chen , Yufan Zhou , Jiuxiang Gu ,Changyou Chen , Tong Sun
- 单位:Adobe Research,Georgia Institute of Technology,State University of New York at Buffalo
- 会议:CVPR 2024(第四十一届国际计算机视觉与模式识别会议)
二、论文主要贡献
大型多模态语言模型在图像理解与编辑上表现卓越,但多数经视觉调优的模型受训练数据限制,难以理解图像中嵌入的文本。为此,本研究提出 TRINS 数据集(富含文本的图像指令数据集Text-Rich image INStruction dataset),核心目标是提升这类模型的文本阅读能力。该数据集基于 LAION (即大规模人工智能开放网络 Large-scale Artificial Intelligence Open Network)构建,采用机器与人类辅助结合的混合标注策略,包含 39,153 张含文本图像、对应描述及 102,437 个问答样本,且每条标注平均词数显著多于现有相关数据集,带来新的训练挑战。同时,研究提出简洁高效的 LaRA(语言 - 视觉阅读助手)架构,其擅长理解图像文本内容,在 TRINS 及其他经典基准测试中,性能均优于当前最先进的多模态语言模型。此外,通过 TRINS 在各类含文本图像的理解与生成任务上的全面评估,充分验证了该数据集的有效性。
三、论文创新点
3.1 构建富含文本的图像指令数据集(TRINS)
3.1.1 TRINS 中文档图像的采集流程
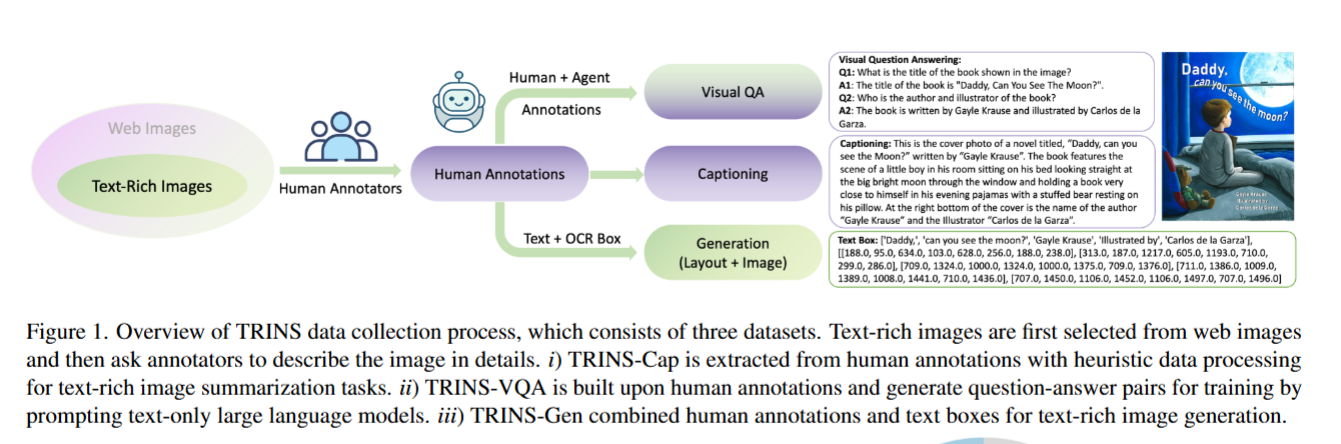
- 从网络图像中筛选出 “富含文本的图像”(比如示例中右侧的书籍封面,包含标题、作者等文本),该步骤详见方法部分的 “机器辅助的富含文本图像筛选” 。
- 人工标注者(Human Annotators)提供基础标注,人机协作(Human + Agent)辅助优化标注质量,最终产出 “Human Annotations(人工标注内容)”,该步骤详见方法部分的“标注的具体流程、规则、方法”。
- 基于人工标注内容,衍生出三个任务对应的子数据集:
- Visual QA(视觉问答,对应 TRINS-VQA)
输入:人工标注内容;
输出:“问题 - 答案” 对(如示例中 “书名是什么?”“作者是谁?” 及对应回答),用于训练模型理解图像文本并回答问题。 - Captioning(图像描述,对应 TRINS-Cap)
输入:人工标注内容;
输出:详细的图像描述文本(如示例中对书籍封面的场景、文字信息的完整描述),用于训练模型将含文本的图像转化为连贯文字。 - Generation(图像生成,对应 TRINS-Gen)
输入:人工标注内容 + 文本边界框(Text + OCR Box);
输出:包含文本内容 + 位置坐标的生成指令(如示例中 “Daddy, can you see the Moon?” 的文字及对应的坐标),用于训练模型生成含指定文本的图像。
3.1.2 TRINS 数据集的标注信息汇总

这是TRINS 数据集的标注信息汇总表,展示了该数据集在数据标注方面的核心统计指标:
- 图片数量:共 39,153 张
- 人工标注数量:与图片数一致(39,153 条),说明每张图对应 1 条人工标注
- 人工标注平均字数:每条标注约 65.1 个词
- 问答(QA)对数量:总计 102,437 对
- 问题平均字数:每个问题约 10.5 个词
- 回答平均字数:每个回答约 23.9 个词
这些数据反映了 TRINS 数据集的规模(图片、标注、QA 对的数量),以及标注内容、问答内容的文本长度特征。
3.2 视觉 - 语言阅读助手(LaRA)模型
为验证我们所构建数据集的有效性,我们采用了一种基于LLaVA的简洁模型架构,用于搭建视觉 - 语言阅读助手,具体结构如下图所示。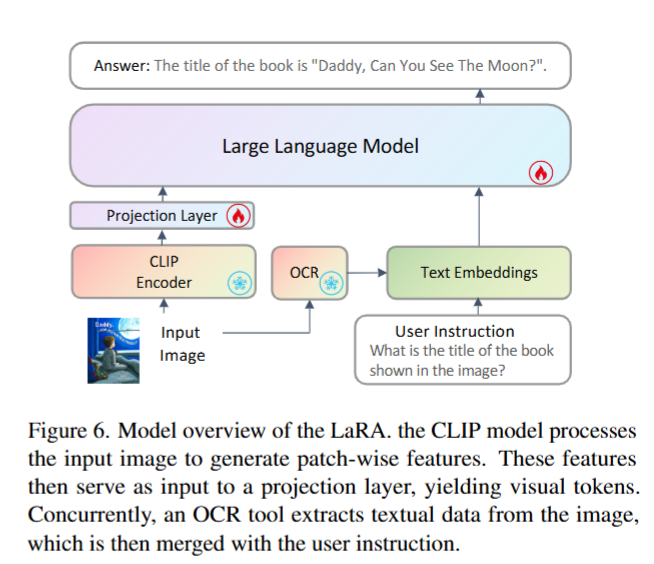
- 输入图像经CLIP 编码器生成图像块特征,再通过投影层转换为视觉 token;同时用OCR 工具提取图像中的文本信息。
- OCR 提取的文本与用户指令(例:“图片中的书名是什么?”)合并为文本嵌入。
- 视觉 token 与文本嵌入共同输入大语言模型,最终生成任务结果(例:书名回答)。
四、方法
4.1 机器辅助的富含文本图像筛选
从大规模网络图像库中筛选出符合 TRINS 数据集要求的富含文本图像的完整流程,核心是 “机器筛选为主、人工优化为辅” 的半自动化策略,具体步骤如下:
- 数据来源
以大规模开源图像数据集 LAION-5B 为初始数据源。 - 分类器训练
构建二分类数据集:将自然图像与文档图像混合,形成 “含文本图像 / 不含文本图像” 的二分类样本。
模型选型与微调:采用 DiT 基础骨干网络作为分类器,在 RVL-CDIP 数据集上进行微调,使其具备预测图像是否含文本的能力。 - 初步筛选(机器主导)
利用训练好的分类器筛选 LAION-5B 图像,筛选出的图像同时满足 3 个条件:
图像含文本的预测概率 > 0.8;
图像含水印的概率 < 0.8;
图像含不安全内容的概率 < 0.5(后两个概率来自 LAION-5B 的元数据)。
由此构建出一个子集。由于分类器的局限性会引入噪声,我们进一步引入人工判断来优化数据集。 - 聚类与人工筛选(优化环节)
对初步筛选后的图像,我们从筛选后的图像中随机抽取了 20,000 张图像,基于 CLIP-ViT-B/32 视觉特征聚类为 50 个分组。在人工检视聚类结果后精心挑选出其中一个分组,该分组包含海报、封面、广告、教育文档等多样化富含文本图像的分组。该分组对应的聚类模型,最终作为 TRINS 数据集的图像筛选机制。 - 数据特征分析
用 CLIP(Contrastive Language–Image Pretraining,对比语言 - 图像预训练) 做分类分析,展示图像分布如下,发现书籍封面是主要类别。
用 RAM 模型(通用识别模型) 提取图像标签并生成词云,核心关键词为 “book” 和 “poster”。
尽管光学字符识别(OCR)工具的性能表现稳定,但仍可能引入噪声信息。为解决这一问题,我们同时采用 Azure Read API 与 PaddleOCR 两款工具来提取文本信息。我们在给大语言模型(LLMs)的系统提示词中,标注了 OCR 结果可能存在的不可靠性,以此指导模型生成答案确定的问题。最终,我们直接利用大语言模型的输出结果构建了 TRINS-VQA 数据集。用 Azure Read API + PaddleOCR 提取图像文本并生成词云,核心关键词为 “book” 、“author” 和 “title”。
统计光学字符识别( OCR )词数分布:TRINS 图像平均含 31.4 个 OCR 词,远超 TextCap(多数不足 10 词),且因小尺寸文本多,识别难度更高。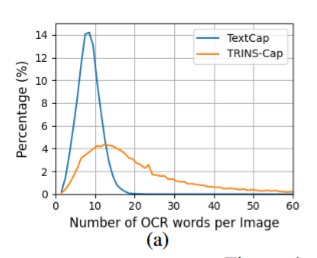
该核心方法的特点:
高效性:借助预训练模型(DiT、CLIP等)大幅降低人工标注成本,提升筛选效率;
精准性:通过多条件过滤(文本概率、水印、不安全内容)和人工优化,减少噪声数据;
多样性:筛选出的图像涵盖多种富含文本场景,满足多模态任务需求。
4.2 标注的具体流程
保障标注质量的全流程管控措施包含标注人员筛选、启发式过滤、人工审核、敏感图像筛查四个维度,具体如下:
- 标注人员筛选
人员资质:选用英语母语者,且具备文档标注经验,拥有 100% 任务完成率和顶级优选标注员资质。
岗前准备:先让标注员完成 200 张图像的标注任务,并提供附带多组示例的详细标注指南;采用 Labelbox 作为标注工具,同时设置质量校验问题。 - 启发式过滤器处理
文本提取条件:使用 EasyOCR 提取图像文本,仅保留字符数>3、高度>画布高度 5%、置信度分数>0.1的文本短语。
匹配算法:针对 OCR 结果可能存在的误差,采用基于编辑距离的字符串匹配算法,在人工生成的图像描述文本中搜索每个短语的最优匹配子字符串。
评估指标:将所有提取短语的平均匹配分数作为标注质量的评估依据。 - 人工审核流程
分层处理标注结果:采纳指标分数高的标注结果;驳回分数最低的结果并要求返工;对其余标注结果开展人工审核。 - 敏感图像筛选
采用 “神经网络模型 + 人工” 的协作过滤方式,分为两步执行:
第一步:由 2-3 名工作人员进行初步筛选,剔除不适用于训练的敏感图像。
第二步:安排额外人员进行二次筛查,并邀请来自不同国家的标注人员对筛选后的图像进行核验。
4.3 关于TRINS-Cap:富含文本的图像描述
TRINS-Cap 是一个完全由人工标注完成的数据集,最终得到 39153 组图像 - 标注配对数据。该数据集被划分为训练集、验证集和测试集三个部分,样本量分别为 29153 组、5000 组和 5000 组。我们为所有标注人员提供了详尽的标注指南,确保每份标注都涵盖以下三方面内容:
(1)对图像视觉元素的详细描述;
(2)说明文本的位置、属性,并将文本内容融入标注中;
(3)可选的补充见解或概括性描述。
标注流程的核心目标,是助力人类或机器在无需直接查看图像的前提下,充分理解图像所传达的全部信息。基于此目标,TRINS 数据集标注文本的平均长度达到65.1 个单词,显著超过 COCO 数据集(10.6 个单词)与 TextCaps 数据集(12.4 个单词)。下图展示了 TRINS-Cap、COCO 和 TextCaps 这三个数据集的标注文本长度分布情况,直观体现出 TRINS-Cap 标注内容的全面性。TRINS 数据集具备更丰富的文本语境,通常能够更好地描述那些难以用简短标注文本呈现的复杂图像。因此,在 TRINS 数据集上微调的大语言模型(LLMs),可以更精准地理解包含复杂文本与版面布局的图像(验证见实验部分)。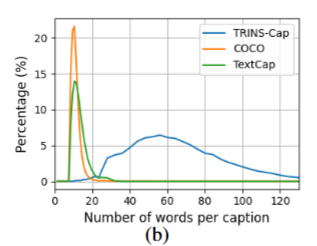
4.4 关于TRINS-VQA:多模态问答
为了给 TRINS-VQA 生成高质量的视觉问答数据,我们引入了半自动标注方法。为了充分利用现有的海量高质量标注资源,我们将半自动标注整合到数据标注流程中,具体方式为借助大型语言模型(LLMs)—— 例如 OpenAI 的 GPT-4 与 Llama-70B。我们向这些大型语言模型提供了图像的光学字符识别(OCR)结果与详细描述信息,此外还为其配备了高质量的人工编写示例以及详尽的标注规则。其中一组示例聚焦于抽取式问题的设计,另一组则侧重于抽象类问题的生成,以此构建出一个类别分布更为均衡的数据集。
在已有研究的基础上,我们基于问题关键词,在下图中对指令内容进行了可视化呈现。内环展示了问题首词的分布情况,外环则呈现了通过精心设计的启发式算法提取出的关键词。问题类型依据从问题中提取的关键词进行划分。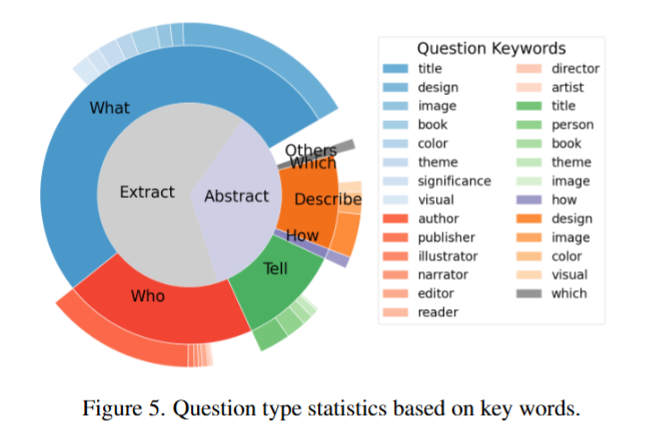
每组问答对的单词数量,与相关研究成果进行对比结果如下。总体而言,TRINS-VQA 数据集的问题平均长度为10.5 个单词,超过了 DocVQA(8.3 个单词)、OCR-VQA(6.5 个单词)与 TextVQA(7.1 个单词)这三个数据集。同时,TRINS 数据集的答案平均长度达到23.9 个单词,显著长于同类数据集(这些数据集的答案平均长度均不足 4 个单词)。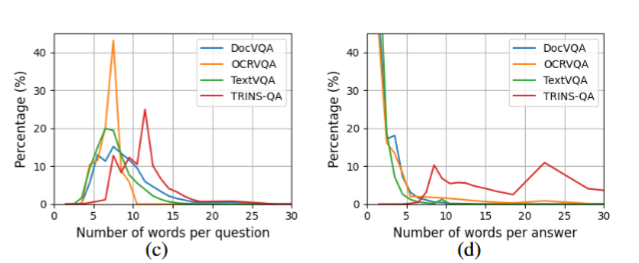
这一差异的成因在于,TRINS 数据集包含更多抽象类问题,而这类问题通常对应更长的答案表述。
五、实验分析
5.1 实验配置
所有实验均在 NVIDIA A100 80GB 显卡上完成。微调过程中,我们采用余弦退火学习率调度策略,初始学习率设为 2 e − 5 2e^{-5} 2e−5,批次大小设为 32。
5.2 实验部分
5.2.1 围绕TRINS-VQA 数据集展开模型性能实验
- 零样本性能基准测试
实验方案:在经典基准数据集上评估 LaRA 模型的零样本性能,结果如下图。
核心结论:LaRA 在所有数据集上均实现显著性能提升;即使不引入 OCR 模块,其在多数场景下仍优于其他模型,体现出处理视觉问答任务的鲁棒性与有效性;融入 OCR 后性能进一步增强,证明大语言模型可高效利用文本信息;LaRA 凭借简洁架构,突破了预训练图像编码器的局限性,大幅提升了模型在富含文本图像任务上的表现。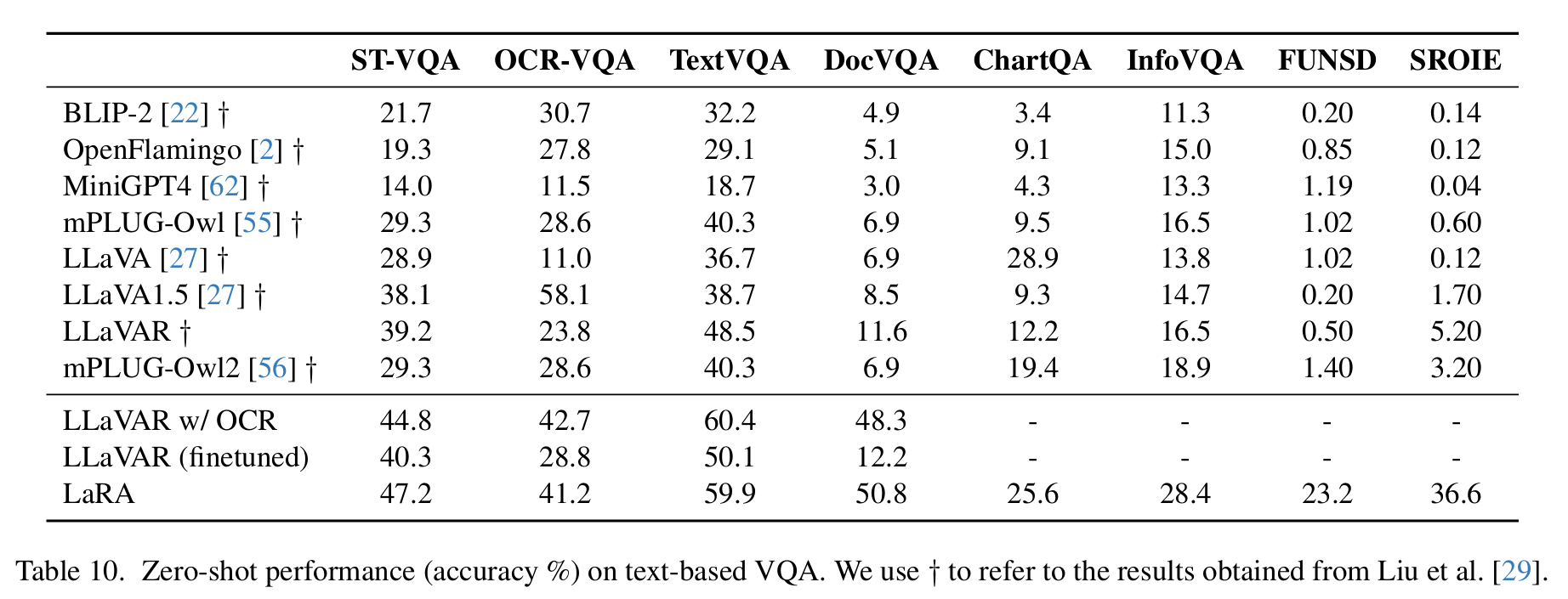
ST-VQA:场景文本视觉问答(Scene Text Visual Question Answering)
OCR-VQA:OCR 视觉问答(OCR-based Visual Question Answering)
TextVQA:文本视觉问答(Text-based Visual Question Answering)
DocVQA:文档视觉问答(Document Visual Question Answering)
ChartQA:图表视觉问答(Chart-based Visual Question Answering)
InfoVQA:信息视觉问答(Information Visual Question Answering)
FUNSD:财务票据理解数据集(Form Understanding in Noisy Scanned Documents,是一个表单理解任务)
SROIE:收据理解数据集(Sales Receipts OCR and Information Extraction,是一个收据信息提取任务)
- TRINS-VQA 数据集上的方法对比
评估指标设计:针对抽取式问题,采用与 WUPS(基于语义网络的文本相似度度量方法)作为评估指标;针对答案为长句的抽象类问题,选用 BLEU、ROUGE等文本相似度指标。
模型性能对比结论:
零样本推理中,融合 OCR 的 LLaVAR 表现最佳,印证了文本信息提取对任务的关键作用。
mPLUG-Owl2 与 QwenVL 在抽取式问题上表现最优,证明高分辨率编码器能显著提升模型性能。
Instruct-BLIP 在抽取式问题上效果良好,但因生成答案简洁短小,在抽象类问题上表现欠佳。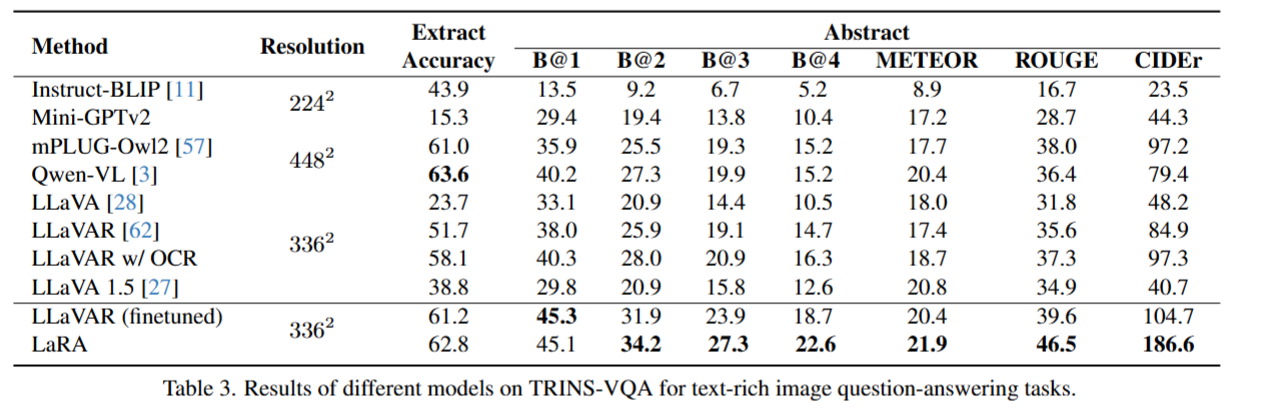
Resolution:分辨率(模型处理图像时采用的尺寸,如 224² 表示 224×224 像素)
Extract Accuracy:提取准确率(衡量模型从文本密集型图像中提取信息的精准度)
Abstract:抽象问答(对应文本生成类的问答任务,以下是其下子指标)
B@1~B@4:BLEU-1 到 BLEU-4(衡量生成文本与参考文本的匹配度,数值越高匹配度越好)
METEOR:一种综合考虑词匹配、词干匹配等的文本生成评价指标(分数越高,回答质量越优)
ROUGE:基于召回率的文本生成评价指标(常用于衡量摘要类任务的质量)
CIDEr:以图像描述为核心的评价指标(侧重生成文本的信息量与相关性)
- 抽象类问题的模型响应案例分析
案例展示:以下为不同模型在抽象类 TRINS-VQA 数据集上的响应示例。


各模型响应特点:Qwen-VL 的回答包含全部细节,但缺乏如人工标注标准答案般的高层次见解;mPLUG-Owl2 与 GPT-4V 两款模型均存在生成幻觉问题。
5.2.2 围绕TRINS-Cap 数据集开展图像描述任务实验
- 实验设计
任务目标:要求多模态大模型基于富含文本的图像生成描述文本。
数据集划分:将 TRINS-Cap 划分为训练集、验证集和测试集。
对比模型:选取 InstructBLIP、Mini-GPT4、LLaVA、LLaVAR、mPLUG-Owl2、Qwen-VL 等主流多模态模型作为基准;因 BLIP-2 在该任务中生成的描述不够全面且缺乏有效信息,故选用 InstructBLIP 作为其替代方案。
输入设置:对所有参与对比的方法,均从 10 条提示词中随机选取 3 条作为模型的输入指令,具体细节如下。

- 实验结果与核心结论
整体性能对比:下表的经典图像描述指标结果显示,视觉文本理解能力增强的模型,整体性能优于 LLaVA、Mini-GPT4 等通用多模态模型。
LaRA 模型不同版本的性能分析:
零样本设置下的 LaRA(在 TRINS-QA 数据集上微调)已展现出性能提升。
对比不同微调版本的 LaRA 发现,无 OCR 模块的方法文本识别能力受限,原因是 CLIP 编码器或特征投影过程会造成视觉信息丢失;解决该问题的思路包括采用在富含文本图像上训练更充分的编码器、设计更精细的模型架构,这是未来的探索方向。
当 LaRA 在 TRINS-Cap 数据集上微调后,性能显著提升,凸显了高质量人工标注数据对模型效果的关键作用。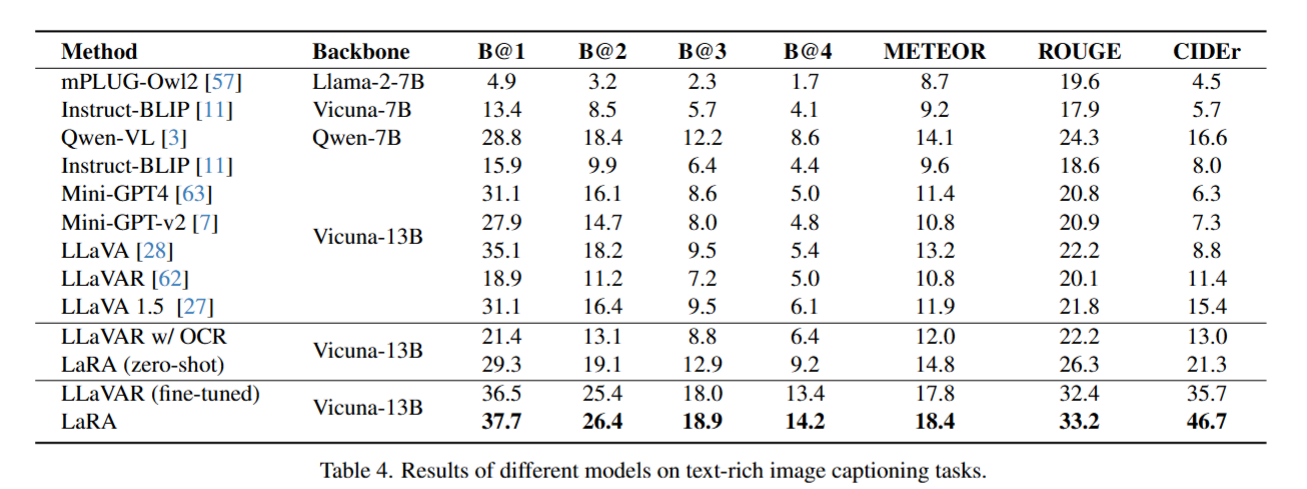
Backbone:模型的基础大语言模型
3.案例验证
下图展示了不同模型在 TRINS-Cap 基准测试集上的生成示例,直观体现出 LaRA 具备优异的文本识别能力,以及将文本与视觉语境关联的能力,印证了 TRINS 数据集的有效性。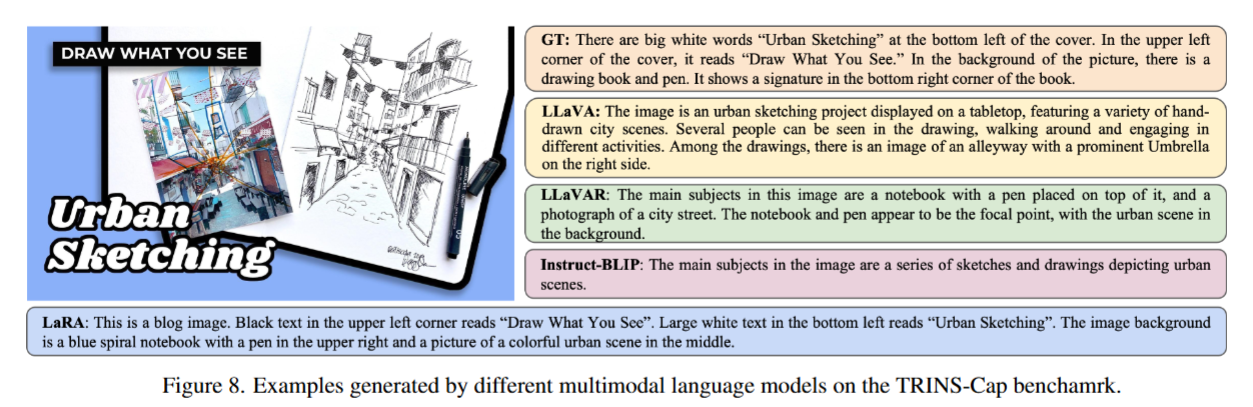
5.3 补充实验
5.3.1 实验一:TRINS 微调后模型在通用视觉任务上的性能验证
实验设计:沿用 MiniGPTv2 的评估方案,在传统视觉问答基准数据集上,对比 LaRA 与 LLaVA 的性能,结果记录于表 5。
结论:在这 4 个公共视觉基准任务中,LaRA 的综合性能优于 LLaVA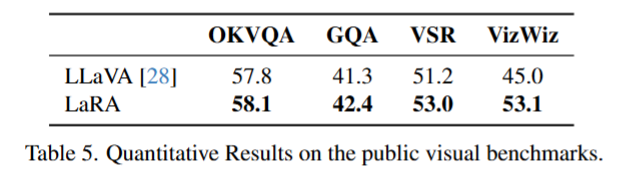
OKVQA:需要外部知识的视觉问答任务;
GQA:复杂场景下的视觉推理问答任务;
VSR:视觉语义推理任务;
VizWiz:针对视障用户的真实场景视觉问答任务。
5.3.2 实验二:文本到文档生成任务 —— 构建 TRINS-Gen 基准数据集
任务背景:基于扩散模型的文本到图像生成技术已取得突破,但精准文本渲染仍是难点;现有 MARIO-Eval 基准的提示词篇幅较短,无法有效评估模型处理复杂真实指令的能力。
数据集构建:
依托 TRINS-Cap 的人工标注数据,构建TRINS-Gen 基准数据集。
针对单图像难以渲染过多文字的技术痛点,过滤掉 OCR 词数超过 20 的图像,最终筛选出 2104 张高质量图像。
根据每张图像的OCR 词数和最长 OCR 字符串长度,将数据集划分为简易集和困难集,其中简易集图像的 OCR 词数均少于 9 个。
评估方案:利用各方法的公开模型检查点评估现有模型性能,核心结果见表 6,详细结果见表 9。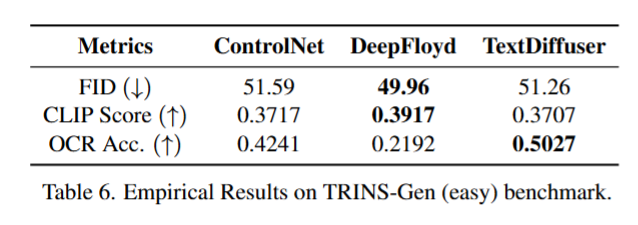
Metrics:评价指标
FID (↓):弗雷歇 inception 距离(数值越小,生成图像的质量 / 真实性越高);
CLIP Score (↑):CLIP 匹配得分(数值越大,生成图像与文本描述的匹配度越高);
OCR Acc. (↑):OCR 准确率(数值越大,生成图像中的文字越清晰、可识别)。
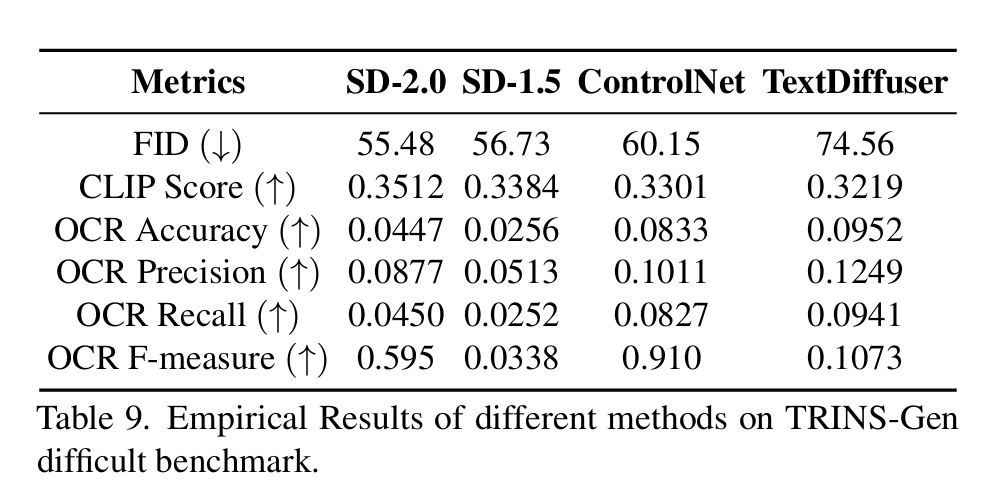
OCR Precision (↑):OCR 精确率(数值越大,代表 OCR 识别结果中正确识别的文字占比越高)
OCR Recall (↑):OCR 召回率(数值越大,代表图像中实际存在的文字被 OCR 识别出来的比例越高)
OCR F-measure (↑):OCR 的 F 值(是精确率和召回率的综合指标,数值越大,代表 OCR 的整体性能越好)
六、个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解有限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)