LangChain RAG-递归文档树检索实施高级RAG优化理解
RAPTOR递归文档树是一种新型RAG优化策略,通过树状结构组织文本检索,解决长文本处理问题。其核心流程包括:文本分块→向量化→降维→聚类→LLM摘要→递归构建层次结构。相比传统方法,RAPTOR在保持高准确性的同时显著降低成本,支持多文档和超长上下文处理。论文提出了两种检索策略(树遍历和折叠树),后者因效率更高被推荐。实现上采用UMAP降维和GMM聚类,但存在数据更新复杂的缺陷。该技术适用于需要
01. RAPTOR 递归文档树策略
在传统的 RAG 中,我们通常依靠检索短的连续文本块来进行检索。但是,当我们处理的是长上下文时,我们就不能仅仅将文档分块嵌入到其中,或者仅仅使用上下文填充所有文档。相反,我们希望为 LLM 的长下文找到一种好的最小化分块方法,这就是 RAPTOR 的用武之地,在 RAPTOR 中,均衡了多文档、超长上下文、高准确性、超低成本 等特性。
RAPTOR 其实是一种用树状组织检索的递归抽象处理技术,它采用了一种自下而上的方法,通过对文本片段(块)进行聚类和归纳来形成一种分层结构,该技术在 https://arxiv.org/pdf/2401.18059 论文中被首次提出。
RAPTOR 的运行流程其实很简单,主要步骤如下:
- 对原始文本进行分块,拆分成合适的大小;
- 对拆分的文档块进行嵌入/向量化,向量目前处于高维,并将数据存储到向量数据库;
- 将高维向量进行降维,降低运算成本,例如降低成 2 维或者 3 维;
- 对降维向量进行聚类,找出同一类的文档组;
- 合并文档组的文本,使用 LLM 对合并文档进行摘要汇总得到新的文本,重复 ②-⑤ 的步骤;
- 直到最后只剩下一个 文档 并且该文档的长度符合大小时,结束整个流程;
可视化其运行流程后如下
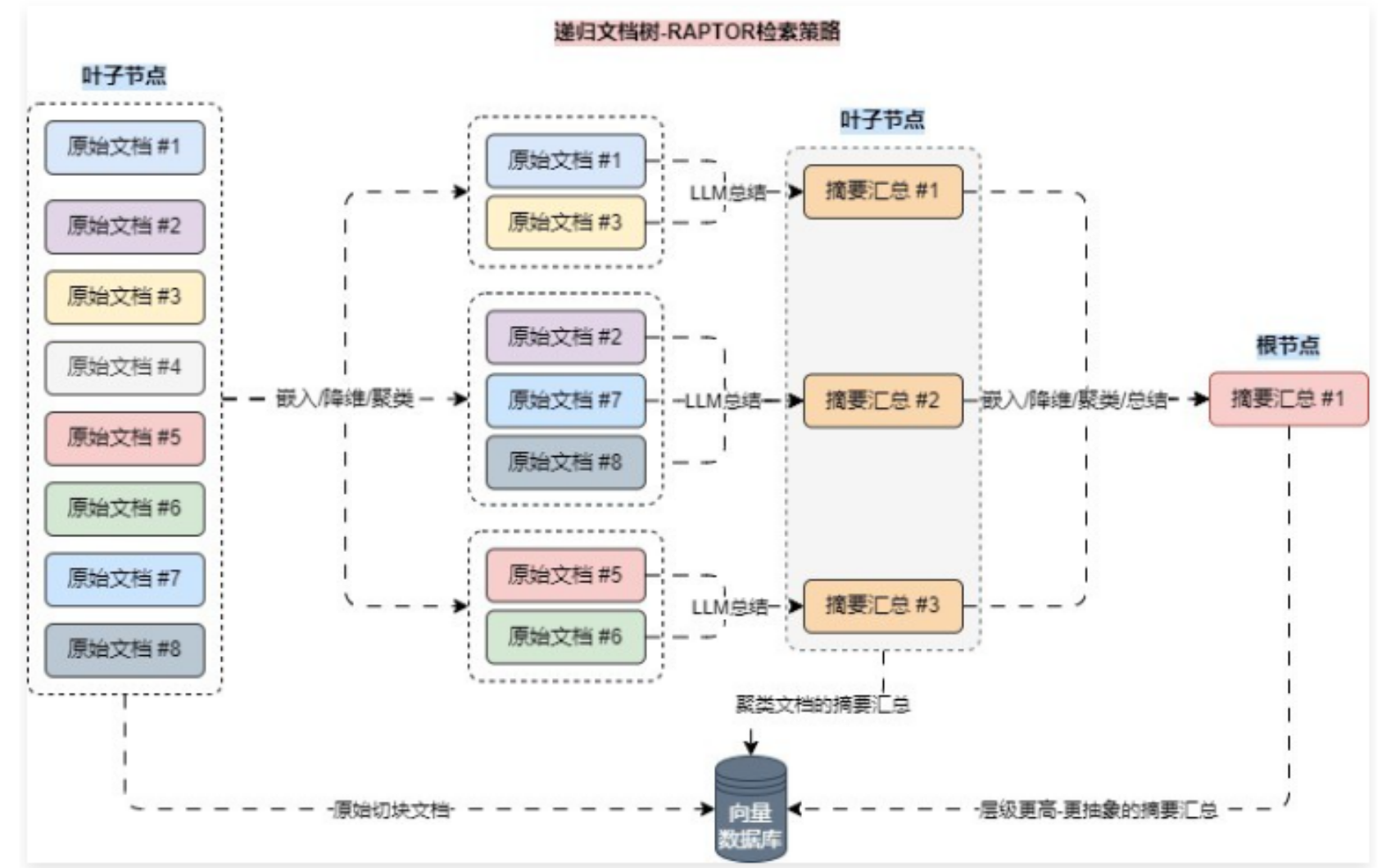
在执行检索的时候,RAPTOR 模型采用了两种主要的检索策略——树遍历 和 折叠树,对比两种策略,论文中更推荐 折叠树 检索策略。
树遍历 方法从树的根节点开始,逐层向下进行检索,在每一层它根据查询向量与节点嵌入的余弦相似性选择最相关的前 k 个节点,然后将这些节点的子节点作为下一层的候选节点集,并重复选择过程,直到达到叶节点,最终将所有选中的节点文本进行拼接,形成检索到的上下文。
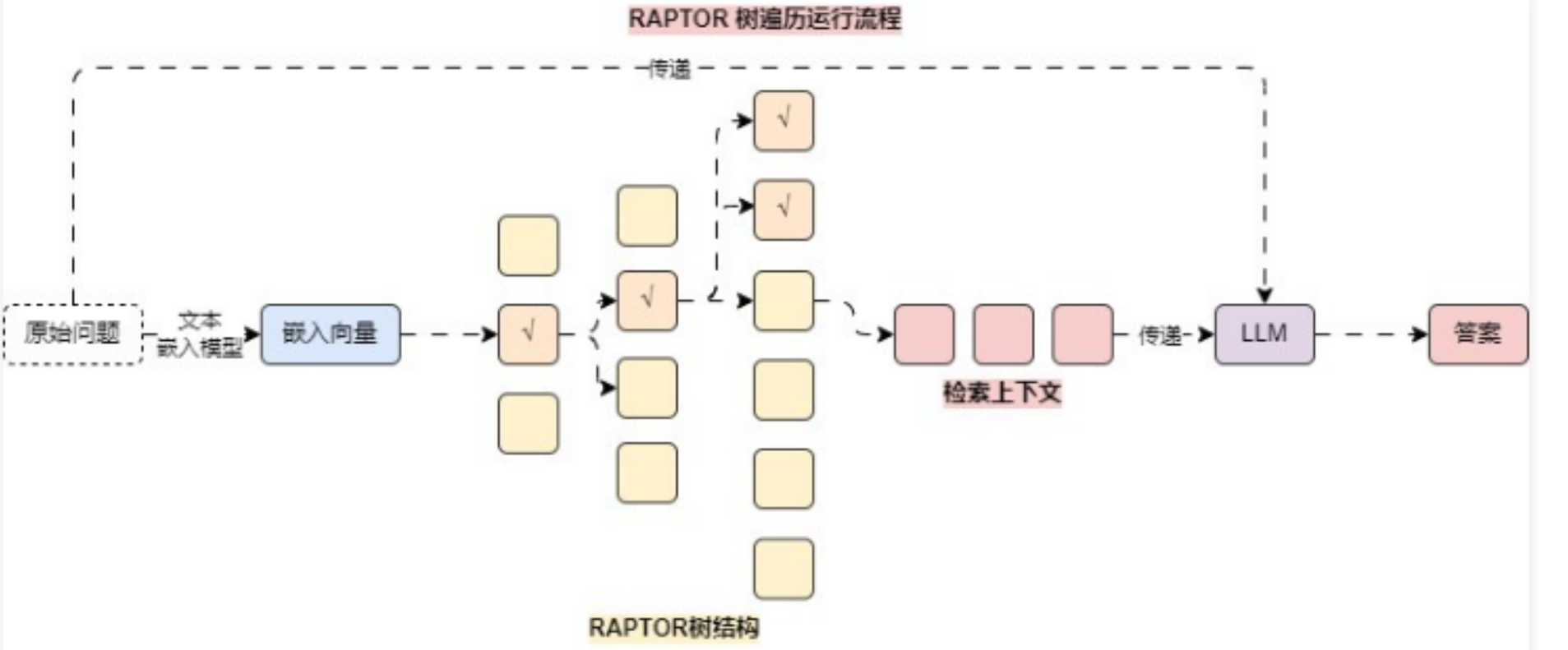
折叠树 方法会先将整个 RAPTOR 树展平为单个层,即所有节点在同一层级上进行比较,计算查询向量与所有节点嵌入的余弦相似性,并选择最相关的前 k 个节点

并且因为 折叠树 和 向量数据库基础搜索 一样都是遍历所有向量(同层),所以只需要将数据存储到向量数据库中,并执行 相似性搜索 其实就实现了 折叠树 检索策略。
对比其他的 RAG 优化策略,RAPTOR递归文档树 不仅保留了原始文档,还将同类文档进行层层抽象(层层总结),而且在 文本嵌入模型 参数较小的情况下,一般也能实现不错的效果(低成本、高性能),不过因为该数据存储的是 树状结构,每次在更新/新增数据时,操作对比其他优化策略麻烦很多。
该论文并没有提供更新/新增数据的策略,但是对于树状结构,一般的更新策略有:
- 重新构建树结构:新增了大量文档时,可以重新构建整个 RAPTOR 树,确保数据不会遗漏。
- 增量更新:如果新增的文档不是很多,可以考虑只更新部分树结构,将新文档的文本块作为新的叶子节点添加到树中,然后根据这些新节点的内容,调整或更新其上层节点的摘要信息。
- 利用现有节点:如果新文档与现有树中的某些节点内容相似,可以考虑将新文档的文本块与现有节点合并,然后重新生成这些节点的摘要,以此来更新树结构。
- 层次化更新:根据新文档的内容和重要性,选择在树的哪个层次上进行更新。如果新文档提供了对整个文档集的重要概述,可能需要在较高的层次上更新;如果新文档提供了细节信息,可能只需要在较低层次上更新。
02. RAPTOR 递归文档树的实现
在 LangChain 中并没有针对 RAPTOR 的实现,并且在该策略中涵盖了 高维数据降维、低维数据聚类、递归检索 等内容,对于该检索策略,目前使用得较少(更新与新增缺陷导致外挂文档增加时复杂度成倍递增),所以仅需要了解 RAPTOR 的运行流程即可。
首先安装特定的第三方 Python 包
pip install -U umap-learn scikit-learn tiktoken
实现代码如下:
from typing import Optional
import dotenv
import numpy as np
import pandas
import pandas as pd
import umap
import weaviate
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_openai import ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_weaviate import WeaviateVectorStore
from sklearn.mixture import GaussianMixture
from weaviate.auth import AuthApiKey
dotenv.load_dotenv()
# 1.定义随机数种子、文本嵌入模型、大语言模型、向量数据库
RANDOM_SEED = 224
embd = HuggingFaceEmbeddings(
model_name="thenlper/gte-small",
cache_folder="./embeddings/",
encode_kwargs={"normalize_embeddings": True},
)
model = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)
db = WeaviateVectorStore(
client=weaviate.connect_to_wcs(
cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud",
auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx"),
),
index_name="RaptorRAG",
text_key="text",
embedding=embd,
)
def global_cluster_embeddings(
embeddings: np.ndarray, dim: int, n_neighbors: Optional[int] = None, metric: str = "cosine",
) -> np.ndarray:
"""
使用UMAP对传递嵌入向量进行全局降维
:param embeddings: 需要降维的嵌入向量
:param dim: 降低后的维度
:param n_neighbors: 每个向量需要考虑的邻居数量,如果没有提供默认为嵌入数量的开方
:param metric: 用于UMAP的距离度量,默认为余弦相似性
:return: 一个降维到指定维度的numpy嵌入数组
"""
if n_neighbors is None:
n_neighbors = int((len(embeddings) - 1) ** 0.5)
return umap.UMAP(n_neighbors=n_neighbors, n_components=dim, metric=metric).fit_transform(embeddings)
def local_cluster_embeddings(
embeddings: np.ndarray, dim: int, n_neighbors: int = 10, metric: str = "cosine",
) -> np.ndarray:
"""
使用UMAP对嵌入进行局部降维处理,通常在全局聚类之后进行。
:param embeddings: 需要降维的嵌入向量
:param dim: 降低后的维度
:param n_neighbors: 每个向量需要考虑的邻居数量
:param metric: 用于UMAP的距离度量,默认为余弦相似性
:return: 一个降维到指定维度的numpy嵌入数组
"""
return umap.UMAP(
n_neighbors=n_neighbors, n_components=dim, metric=metric,
).fit_transform(embeddings)
def get_optimal_clusters(
embeddings: np.ndarray, max_clusters: int = 50, random_state: int = RANDOM_SEED,
) -> int:
"""
使用高斯混合模型结合贝叶斯信息准则(BIC)确定最佳的聚类数目。
:param embeddings: 需要聚类的嵌入向量
:param max_clusters: 最大聚类数
:param random_state: 随机数
:return: 返回最优聚类数
"""
# 1.获取最大聚类树,最大聚类数不能超过嵌入向量的数量
max_clusters = min(max_clusters, len(embeddings))
n_clusters = np.arange(1, max_clusters)
# 2.逐个设置聚类树并找出最优聚类数
bics = []
for n in n_clusters:
# 3.创建高斯混合模型,并计算聚类结果
gm = GaussianMixture(n_components=n, random_state=random_state)
gm.fit(embeddings)
bics.append(gm.bic(embeddings))
return n_clusters[np.argmin(bics)]
def gmm_cluster(embeddings: np.ndarray, threshold: float, random_state: int = 0) -> tuple[list, int]:
"""
使用基于概率阈值的高斯混合模型(GMM)对嵌入进行聚类。
:param embeddings: 需要聚类的嵌入向量(降维)
:param threshold: 概率阈值
:param random_state: 用于可重现的随机性种子
:return: 包含聚类标签和确定聚类数目的元组
"""
# 1.获取最优聚类数
n_clusters = get_optimal_clusters(embeddings)
# 2.创建高斯混合模型对象并嵌入数据
gm = GaussianMixture(n_components=n_clusters, random_state=random_state)
gm.fit(embeddings)
# 3.预测每个样本属于各个聚类的概率
probs = gm.predict_proba(embeddings)
# 4.根据概率阈值确定每个嵌入的聚类标签
labels = [np.where(prob > threshold)[0] for prob in probs]
# 5.返回聚类标签和聚类数目
return labels, n_clusters
def perform_clustering(embeddings: np.ndarray, dim: int, threshold: float) -> list[np.ndarray]:
"""
对嵌入进行聚类,首先全局降维,然后使用高斯混合模型进行聚类,最后在每个全局聚类中进行局部聚类。
:param embeddings: 需要执行操作的嵌入向量列表
:param dim: 指定的降维维度
:param threshold: 概率阈值
:return: 包含每个嵌入的聚类ID的列表,每个数组代表一个嵌入的聚类标签。
"""
# 1.检测传入的嵌入向量,当数据量不足时不进行聚类
if len(embeddings) <= dim + 1:
return [np.array([0]) for _ in range(len(embeddings))]
# 2.调用函数进行全局降维
reduced_embeddings_global = global_cluster_embeddings(embeddings, dim)
# 3.对降维后的数据进行全局聚类
global_clusters, n_global_clusters = gmm_cluster(reduced_embeddings_global, threshold)
# 4.初始化一个空列表,用于存储所有嵌入的局部聚类标签
all_local_clusters = [np.array([]) for _ in range(len(embeddings))]
total_clusters = 0
# 5.遍历每个全局聚类以执行局部聚类
for i in range(n_global_clusters):
# 6.提取属于当前全局聚类的嵌入向量
global_cluster_embeddings_ = embeddings[
np.array([i in gc for gc in global_clusters])
]
# 7.如果当前全局聚类中没有嵌入向量则跳过循环
if len(global_cluster_embeddings_) == 0:
continue
# 8.如果当前全局聚类中的嵌入量很少,直接将它们分配到一个聚类中
if len(global_cluster_embeddings_) <= dim + 1:
local_clusters = [np.array([0]) for _ in global_cluster_embeddings_]
n_local_clusters = 1
else:
# 9.执行局部降维和聚类
reduced_embeddings_local = local_cluster_embeddings(global_cluster_embeddings_, dim)
local_clusters, n_local_clusters = gmm_cluster(reduced_embeddings_local, threshold)
# 10.分配局部聚类ID,调整已处理的总聚类数目
for j in range(n_local_clusters):
local_cluster_embeddings_ = global_cluster_embeddings_[
np.array([j in lc for lc in local_clusters])
]
indices = np.where(
(embeddings == local_cluster_embeddings_[:, None]).all(-1)
)[1]
for idx in indices:
all_local_clusters[idx] = np.append(all_local_clusters[idx], j + total_clusters)
total_clusters += n_local_clusters
return all_local_clusters
def embed(texts: list[str]) -> np.ndarray:
"""
将传递的的文本列表转换成嵌入向量列表
:param texts: 需要转换的文本列表
:return: 生成的嵌入向量列表并转换成numpy数组
"""
text_embeddings = embd.embed_documents(texts)
return np.array(text_embeddings)
def embed_cluster_texts(texts: list[str]) -> pandas.DataFrame:
"""
对文本列表进行嵌入和聚类,并返回一个包含文本、嵌入和聚类标签的数据框。
该函数将嵌入生成和聚类结合成一个步骤。
:param texts: 需要处理的文本列表
:return: 返回包含文本、嵌入和聚类标签的数据框
"""
text_embeddings_np = embed(texts)
cluster_labels = perform_clustering(text_embeddings_np, 10, 0.1)
df = pd.DataFrame()
df["text"] = texts
df["embd"] = list(text_embeddings_np)
df["cluster"] = cluster_labels
return df
def fmt_txt(df: pd.DataFrame) -> str:
"""
将数据框中的文本格式化成单个字符串
:param df: 需要处理的数据框,内部涵盖text、embd、cluster三个字段
:return: 返回合并格式化后的字符串
"""
unique_txt = df["text"].tolist()
return "--- --- \n --- ---".join(unique_txt)
def embed_cluster_summarize_texts(texts: list[str], level: int) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
对传入的文本列表进行嵌入、聚类和总结。
该函数首先问文本生成嵌入,基于相似性对他们进行聚类,扩展聚类分配以便处理,然后总结每个聚类中的内容。
:param texts: 需要处理的文本列表
:param level: 一个整数,可以定义处理的深度
:return: 包含两个数据框的元组
- 第一个 DataFrame (df_clusters) 包括原始文本、它们的嵌入以及聚类分配。
- 第二个 DataFrame (df_summary) 包含每个聚类的摘要信息、指定的处理级别以及聚类标识符。
"""
# 1.嵌入和聚类文本,生成包含text、embd、cluster的数据框
df_clusters = embed_cluster_texts(texts)
# 2.定义变量,用于扩展数据框,以便更方便地操作聚类
expanded_list = []
# 3.扩展数据框条目,将文档和聚类配对,便于处理
for index, row in df_clusters.iterrows():
for cluster in row["cluster"]:
expanded_list.append(
{"text": row["text"], "embd": row["embd"], "cluster": cluster}
)
# 4.从扩展列表创建一个新的数据框
expanded_df = pd.DataFrame(expanded_list)
# 5.获取唯一的聚类标识符以进行处理
all_clusters = expanded_df["cluster"].unique()
# 6.创建汇总Prompt、汇总链
template = """Here is a sub-set of LangChain Expression Language doc.
LangChain Expression Language provides a way to compose chain in LangChain.
Give a detailed summary of the documentation provided.
Documentation:
{context}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model | StrOutputParser()
# 7.格式化每个聚类中的文本以进行总结
summaries = []
for i in all_clusters:
df_cluster = expanded_df[expanded_df["cluster"] == i]
formatted_txt = fmt_txt(df_cluster)
summaries.append(chain.invoke({"context": formatted_txt}))
# 8.创建一个DataFrame来存储总结及其对应的聚类和级别
df_summary = pd.DataFrame(
{
"summaries": summaries,
"level": [level] * len(summaries),
"cluster": list(all_clusters),
}
)
return df_clusters, df_summary
def recursive_embed_cluster_summarize(
texts: list[str], level: int = 1, n_levels: int = 3,
) -> dict[int, tuple[pd.DataFrame, pd.DataFrame]]:
"""
递归地嵌入、聚类和总结文本,直到达到指定的级别或唯一聚类数变为1,将结果存储在每个级别处。
:param texts: 要处理的文本列表
:param level: 当前递归级别(从1开始)
:param n_levels: 递归地最大深度(默认为3)
:return: 一个字典,其中键是递归级别,值是包含该级别处聚类DataFrame和总结DataFrame的元组。
"""
# 1.定义字典用于存储每个级别处的结果
results = {}
# 2.对当前级别执行嵌入、聚类和总结
df_clusters, df_summary = embed_cluster_summarize_texts(texts, level)
# 3.存储当前级别的结果
results[level] = (df_clusters, df_summary)
# 4.确定是否可以继续递归并且有意义
unique_clusters = df_summary["cluster"].nunique()
if level < n_levels and unique_clusters > 1:
# 5.使用总结作为下一级递归的输入文本
new_texts = df_summary["summaries"].tolist()
next_level_results = recursive_embed_cluster_summarize(
new_texts, level + 1, n_levels
)
# 6.将下一级的结果合并到当前结果字典中
results.update(next_level_results)
return results
# 2.定义文档加载器、文本分割器(中英文场景)
loaders = [
UnstructuredFileLoader("./流浪地球.txt"),
UnstructuredFileLoader("./电商产品数据.txt"),
UnstructuredFileLoader("./项目API文档.md"),
]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=0,
separators=["\n\n", "\n", "。|!|?", "\.\s|\!\s|\?\s", ";|;\s", ",|,\s", " ", ""],
is_separator_regex=True,
)
# 3.循环分割并加载文本
docs = []
for loader in loaders:
docs.extend(loader.load_and_split(text_splitter))
# 4.构建文档树,最多3层
leaf_texts = [doc.page_content for doc in docs]
results = recursive_embed_cluster_summarize(leaf_texts, level=1, n_levels=3)
# 5.遍历文档树结果,从每个级别提取总结并将它们添加到all_texts中
all_texts = leaf_texts.copy()
for level in sorted(results.keys()):
summaries = results[level][1]["summaries"].tolist()
all_texts.extend(summaries)
# 6.将all_texts添加到向量数据库
db.add_texts(all_texts)
# 7.执行相似性检索(折叠树)
retriever = db.as_retriever(search_type="mmr")
search_docs = retriever.invoke("流浪地球中的人类花了多长时间才流浪到新的恒星系?")
print(search_docs)
print(len(search_docs))
输出内容:
[Document(page_content='我们的船继续航行,到了地球黑夜的部分,在这里,阳光和地球发动机的光柱都照不到,在大西洋清凉的海风中,我们这些孩子第一次看到了星空。天啊,那是怎样的景象啊,美得让我们心醉。小星老师一手搂着我们,一手指着星空,看,孩子们,那就是半人马座,那就是比邻星,那就是我们的新家!说完她哭了起来,我们也都跟着哭了,周围的水手和船长,这些铁打的汉子也流下了眼泪。所有的人都用泪眼探望着老师指的方向,星空在泪水中扭曲抖动,唯有那个星星是不动的,那是黑夜大海狂浪中远方陆地的灯塔,那是冰雪荒原中快要冻死的孤独旅人前方隐现的火光,那是我们心中的太阳,是人类在未来一百代人的苦海中惟一的希望和支撑……\n\n在回家的航程中,我们看到了启航的第一个信号:夜空中出现了一个巨大的彗星,那是月球。人类带不走月球,就在月球上也安装了行星发动机,把它推离地球轨道,以免在地球加速时相撞。月球上行星发动机产生的巨大彗尾使大海笼罩在一片蓝光之中,群星看不见了。月球移动产生的引力潮汐使大海巨浪冲天,我们改乘飞机向南半球的家飞去。\n\n启航的日子终于到了!'), Document(page_content='离开木星时,地球已达到了逃逸速度,它不再需要返回潜藏着死亡的太阳,向广漠的外太空飞去,漫长的流浪时代开始了。\n\n就在木星暗红色的阴影下,我的儿子在地层深处出生了。\n\n第3章 叛乱\n\n离开木星后,亚洲大陆上一万多台地球发动机再次全功率开动,这一次它们要不停地运行500年,不停地加速地球。这500年中,发动机将把亚洲大陆上一半的山脉用做燃料消耗掉。\n\n从四个多世纪死亡的恐惧中解脱出来,人们长出了一口气。但预料中的狂欢并没有出现,接下来发生的事情出乎所有人的想像。\n\n在地下城的庆祝集会后,我一个人穿上密封服来到地面。童年时熟悉的群山已被超级挖掘机夷为平地,大地上只有裸露的岩石和坚硬的冻土,冻土上到处有白色的斑块,那是大海潮留下的盐渍。面前那座爷爷和爸爸度过了一生的曾有千万人口的大城市现在已是一片废墟,高楼钢筋外露的残骸在地球发动机光柱的蓝光中拖着长长的影子,好像是史前巨兽的化石……一次次的洪水和小行星的撞击已摧毁了地面上的一切,各大陆上的城市和植被都荡然无存,地球表面已变成火星一样的荒漠。'), Document(page_content='“可老师,我们来不及的,地球来不及的,它还来不及加速到足够快,航行足够远,太阳就爆炸了!”\n\n“时间是够的,要相信联合政府!这我说了多少遍,如果你们还不相信,我们就退一万步说:人类将自豪地去死,因为我们尽了最大的努力!”\n\n人类的逃亡分为五步:第一步,用地球发动机使地球停止转动,使发动机喷口固定在地球运行的反方向;第二步,全功率开动地球发动机,使地球加速到逃逸速度,飞出太阳系;第三步,在外太空继续加速,飞向比邻星;第四步,在中途使地球重新自转,掉转发动机方向,开始减速;第五步,地球泊入比邻星轨道,成为这颗恒星的卫星。人们把这五步分别称为刹车时代、逃逸时代、流浪时代I(加速)、流浪时代II(减速)、新太阳时代。\n\n整个移民过程将延续两千五百年时间,一百代人。'), Document(page_content='我们很快到达了海边,看到城市摩天大楼的尖顶伸出海面,退潮时白花花的海水从大楼无数的窗子中流出,形成一道道瀑布……刹车时代刚刚结束,其对地球的影响已触目惊心:地球发动机加速造成的潮汐吞没了北半球三分之二的大城市,发动机带来的全球高温融化了极地冰川,更给这大洪水推波助澜,波及到南半球。爷爷在三十年前亲眼目睹了百米高的巨浪吞没上海的情景,他现在讲这事的时候眼还直勾勾的。事实上,我们的星球还没启程就已面目全非了,谁知道在以后漫长的外太空流浪中,还有多少苦难在等着我们呢?')]
4
感兴趣的同学也可以阅读代码,在代码中,每一行我都添加上了对应的注释。
除了 RAPTOR 的优化思想,LangChain 团队在路演中,还演示了一种基于 Token2Text 的优化策略——ColBERT,该策略会为段落中的每个 Token 生成一个受上下文影响的向量,在计算文档得分时并不是使用文档的向量相似性计算,而是通过 查询嵌入 与 每个Token嵌入向量 的最大相似性之和,不过由于性能偏低,并且需要高昂的计算成本,带来的提升不大,导致目前应用并不广,接受度较低。
感兴趣的同学可以通过以下资料进行阅读学习:
- LangChain 文档:RAGatouille | 🦜️🔗 LangChain
- ColBERT 英文博文:How ColBERT Helps Developers Overcome the Limits of RAG | HackerNoon
03. 索引阶段优化策略总结
至此,在 RAG 的 索引阶段,这些具有代表性的优化策略其实我们已经讲解完了,涵盖了 分割策略(语义分割、递归字符分割)、多向量/表征检索、RAPTOR递归文档树检索,其中 特定Embeddings 即考虑使用维度更高的文本嵌入模型,并没有复杂的使用技巧。
目前在 索引阶段,使用最多的优化策略还是在 文档加载/分割 与 特定Embeddings 上,因为无论是 多向量/表征索引 还是 RAPTOR递归文档树,都会使用额外的 LLM 对文档进行相应的总结、信息提取、分类汇总等,数据越多,信息失真的概率会越大(所以谨慎使用)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)