轻量级向量库chromadb
本文探讨了向量在现代AI系统中的核心作用及其应用。向量作为高维语义空间的坐标点,能够表达文本、图像等信息的语义关系,使机器能够理解内容相似性。文章重点介绍了嵌入模型如何将自然语言转化为向量,对比了不同模型架构和训练方式的差异,并强调不同模型的向量空间不兼容性。同时梳理了NLP领域从早期离散表示到现代连续向量空间的演进历程,解释了为何深度学习需要浮点数向量来实现语义的连续表达。最后指出向量已成为构建
目录
引子
在大模型时代,向量(Vector)已经悄悄成为构建智能系统的基础设施。从语义搜索、知识库问答,到推荐系统与代码检索,几乎所有“让机器理解内容”的能力,都依赖于把文本、图像、代码等信息转化为可计算的高维向量。而语言模型生成的嵌入向量(Embedding),更是这一切的起点。
然而,如何高效地存储、管理、搜索这些向量,一直是开发者面临的现实问题。完整型向量数据库如 Milvus、Weaviate 功能强大,但部署与资源成本并不适合每个项目。于是,在“轻量化”“易集成”“本地可用”的需求下,ChromaDB 成为许多工程师的首选 —— 它小巧、简单、零依赖,支持本地与生产环境快速落地,是进入向量世界的绝佳起点。
本文将从“向量是什么”讲起,带你理解嵌入向量的意义,然后深入到 ChromaDB 的设计理念与核心原理,最后通过实际代码演示,展示如何用 ChromaDB 构建一个轻量、高效、可随用随调的本地向量库。
向量
在大多数人的数学记忆里,向量似乎只是“带方向和大小的箭头”。
但在现代人工智能语境中,向量(Vector)已经成为描述万物的通用语言——文本、图像、音频、代码甚至用户行为,都可以被表示成一个多维向量。它不再是物理意义上的“力”和“速度”,而是抽象的 语义坐标点。
从数学上讲,向量就是一个数字序列:
v = [v_1, v_2, v_3, ..., v_n]
这些数字本身没有意义,但在 AI 中,它们代表一种被模型“理解”后的语义结构:
- 一段文本会被编码成一个向量
- 两段意思相近的文本,其向量会“靠近”
- 两段表达完全不同的文本,其向量会“远离”
换句话说,向量是机器理解内容后在高维空间中的落点。
高维空间与语义距离
向量通常是几十维、几百维甚至数千维,比如 OpenAI 的文本嵌入常见维度是 1536。这些维度并没有直观含义,但它们共同构成一个无法直接想象的“语义空间”。
在这个空间中,距离代表语义相关性:
- 距离越近 → 越相关
- 距离越远 → 越不相关
最常见的距离或相似度度量包括:
- 余弦相似度(cosine similarity)
- 欧氏距离(Euclidean distance)
- 点积(Inner Product)
在向量数据库中,这些度量是检索的基础。
构建智能系统的关键在于:机器必须能比较两个内容是否相似。
传统算法依赖严格的规则:关键词匹配、字符串比较、布尔条件等。但现实世界的语义是模糊的,而向量提供了一种新的方式:
- “苹果”和“水果”应该接近
- “苹果手机”和“iPhone”应该接近
- “怎么实现二分查找”与“binary search example”应该接近
- “如何修电脑”与“猫长得可爱”应该非常远
这些关系无法通过关键词逻辑实现,但向量可以自然表达。
因此,向量成为:
- RAG(检索增强生成)的基础
- 语义搜索的核心
- 推荐系统的底层机制
- 相似内容检索的通用解法
从数据到向量:嵌入模型的角色
向量的价值并不来自向量本身,而来自生成向量的模型。
例如语言嵌入模型(Embedding Model)会把句子转化为稳定的语义向量,使得语义结构能够映射到空间结构。
相比传统特征工程,嵌入模型拥有:
- 强大的泛化能力
- 丰富的语义表达能力
- 更低的人工成本
这让向量成为现代 AI 系统的默认数据结构。
语言嵌入(Embedding)是一种把文本转换为高维向量的技术,其目标是:
在向量空间中让语义相近的文本靠得更近,让语义无关的文本远离。
例如:
- “如何使用 Git 提交代码”
- “git commit 怎么用”
这两个句子语义极其接近,所以嵌入向量之间距离也很小。
而:
- “如何使用 Git 提交代码”
- “天气真好”
这两者之间距离则会非常大。嵌入向量由深度学习模型直接输出,是文本的 语义压缩表示。
虽然内部实现非常复杂,但可以把嵌入模型理解为:
- 输入一句话
- 模型通过 Transformer 等结构理解句子
- 输出一个稳定的 N 维向量,例如 [0.31, -0.08, 0.92, …]
模型训练目标通常是:
- 让语义相似的句子输出相近向量
- 让上下文相关的句子具有结构性距离
- 让模型对同义表达具有鲁棒性
其训练方法可能包括:
- 对比学习(Contrastive Learning)
- 无监督语料挖掘
- 大规模自监督训练
但对工程开发者而言,只需要知道:
嵌入模型把文本转成“能比较”的向量,而向量数据库负责“快速检索”。
此外,不同模型输出的向量维度不同:
- OpenAI text-embedding-3-small → 1536 维
- Sentence-BERT → 768 维
- MiniLM/SimCSE → 384–768 维
- 国内开源模型如 bge-small → 512 维
维度越高不一定更好,但一般意味着:
- 表达能力更强
- 模型体积更大
- 存储开销更高
- 向量索引复杂度更高
在实践中,通常会根据场景选择:
- 大模型嵌入 → 精准语义搜索、RAG、文档问答
- 小模型嵌入 → 轻量应用、本地部署、边缘场景
为什么模型可以把自然语言转成向量?
本质原因只有一句话:
模型在大规模语料上学会了“语义相似的文本应该靠近,语义不同的文本应该分开”。
为了实现这个目标,模型必须先“理解语义”,然后输出一个能反映这种关系的向量。
要先理解:
嵌入向量不是工程师手写的,而是模型在训练过程中自动学出来的。
而且整个过程不是“把文本和向量对照喂进去”,而是:
模型自己在大量语料中学习语言的统计规律,向量是中间产物。
举例:如果你让模型处理大量句子,它会逐渐“发现”:
- 为什么 “apple” 和 “banana” 经常出现在类似上下文
- 为什么 “king” 和 “queen” 的关系像 “man” 和 “woman”
- 为什么 “😊” 常出现于积极评价句子
模型发现这些规律后,内部会自发地把这些词或句子映射到一个结构化的数字空间,也就是向量空间。
训练方式主要分为两类:
① 自监督语言模型(LLM)训练的副产物
这类模型(如 GPT、BERT)在训练时学会了语言结构:
- 猜下一个词(GPT)
- 猜被遮住的词(BERT)
虽然目标不是“产生向量”,但中间层的某些输出天然包含语义信息。
例如:
- “苹果”这个词在语料中常与“水果、树、红色”一起出现
- “苹果手机”常出现在“iPhone、拍照、电池续航”附近
模型通过数十亿文本学习后,会自动把这些语义相近的内容映射到数学空间的相近区域。
于是,从某一层取输出,就是一个“语言理解后”的向量。
这种向量经过额外微调,就成为 Embedding Model。
这类模型的代表:
- BERT + Sentence-BERT(SBERT)
- GPT 系列 embedding 模型
- bge 系列(基于 RoBERTa/BERT 结构)
② 对比学习(Contrastive Learning)训练专门的嵌入模型
这是现在最主流的方法。
训练流程基本是:
- 收集大量语义相似的文本对(如“如何重置密码 vs reset your password”)
- 再收集大量语义无关的文本对
- 让模型输出向量
- 优化目标:
相似文本的距离要小
不相似的距离要大
例如:
你喂给模型两个句子:
- “What is HTTP?”
- “HTTP 是什么?”
你希望它们的向量尽量接近。
再喂:
- “What is HTTP?”
- “天气很好”
你希望它们的向量尽量远。
这就是对比学习,训练后模型就“学会了语义映射关系”。
代表模型:
- bge-large / bge-small(国产最火的对比学习模型)
- OpenAI text-embedding-3 系列
- Cohere embedding 模型
- MiniLM、SimCSE
不同模型会给同一句话输出完全不同的向量:
- 维度不同(384、768、1024、1536…)
- 分布不同(有的用 L2 Norm,有的用 Cosine)
- 训练目标不同(搜索优化 vs 分类优化)
- 使用的语料不同(中文 vs 英文 vs 多语种)
所以你绝不能:
❌ 把不同模型算出的向量混在同一向量库
❌ 用 bge-small 写入,用 OpenAI 的 embedding 查
❌ 用句子向量与词向量混合对比
因为:
不同模型的向量空间不一致,甚至不兼容。
大体上来讲,不同模型有三大差别:
① 架构不同(Transformer、MiniLM、RoBERTa、LLaMA…)
架构决定模型基本能力:
- BERT → 强调句子理解,适合 embedding
- GPT → 偏生成,但可微调得到 embedding
- MiniLM → 小型轻量化
- bge 系列 → 针对检索优化
架构影响:
- 性能
- 推理速度
- 模型大小
- 语义捕获能力
② 训练方式不同(最关键)
- 有的用于 语义相似度(SBERT、bge)
- 有的用于 通用文本理解(BERT)
- 有的用于 生成任务(GPT)
- 有的使用两阶段训练(粗粒度对比 + 精细排序)
这对最终向量的方向、空间结构影响极大。
③ 训练语料不同
如果训练语料偏向:
- 英文社区 → 英文表现特别强
- 多语种 → 语种覆盖广但效果稍弱
- 中文互联网 → 中文检索极强(如 bge-m3)
语料差异会导致:
同一句话,在不同模型下的“向量语义”是完全不同的。
从 NLP 到现代 LLM 的演进
为了让:
- “苹果” ≈ “水果”
- “跑步” ≈ “健身”
- “buy computer” ≈ “购买电脑”
这些语义关系能平滑表达,模型需要一个连续空间。
在数学上,连续空间用的就是 实数(float)。
如果用 int,其表达能力是离散的、阶梯式的:
- 你无法表示“接近但不完全相同”
- 你无法表示“微小差异”
- 你无法通过梯度学习优化 int(梯度是连续的)
深度学习依赖反向传播(gradient descent),需要连续值计算梯度,所以:
Embedding 必须是 float。
早在 LLM 出现前,NLP 就有文本向量化技术了。而且整个历程是一个非常漂亮的技术演化链:
下面是在你提供的内容基础上改写增强版,加入更直观、更生活化、可感知的例子,让读者不仅“懂技术”,还能“想象得出来”。
我尽量保持你的原结构不变,只在每一代加入恰到好处的例子与对比,使整个演进更鲜活。
从 NLP 到现代 LLM 的演进
为了让:
- “苹果” ≈ “水果”
- “跑步” ≈ “健身”
- “buy computer” ≈ “购买电脑”
这些语义关系能够平滑表达,模型需要一个连续空间。
在数学上,连续空间用的就是 实数(float)。
如果用 int,其表达能力是离散的:
- 没法表达“有点像 / 很像 / 非常像”
- 小变化(如句法变化)没法体现
- 用 int 无法参与神经网络的梯度优化(梯度是连续的)
深度学习依赖反向传播(gradient descent),需要连续值才能优化,所以:
Embedding 必须是 float。
而在 LLM 出现前,文本向量化已经经历过多次技术迭代。下面是一条非常漂亮的技术演化链。
第一代:离散向量(One-hot Encoding)
最早期(1990s),文本的向量表示是:
“apple” → [0,0,0,1,0,0,0,...]
“banana”→ [0,0,1,0,0,0,0,...]
特征:
- 全是 0 或 1
- 维度巨大(词表有 10000 个词就有 10000 维)
- 完全无法表达语义
直观例子:
在 one-hot 中:
- “苹果”和“香蕉”的向量是完全正交的
- 就像两个互相没有任何关系的开关
对于机器来说:
“apple” 和 “banana” 的距离 = “apple” 和 “quantum physics” 的距离。
此时代的模型根本不理解“水果”的概念,只知道“不同的词而已”。
第二代:统计向量(TF-IDF、Bag-of-Words)
1990–2010 的 NLP 大多依赖统计方法。例如,一篇文档可能表示成:
“我 喜欢 苹果” → [喜欢:1, 我:1, 苹果:1]
“我 讨厌 苹果” → [讨厌:1, 我:1, 苹果:1]
特点:
- 本质是“词频统计”
- 忽略语序(“我爱你” = “你爱我”)
- 完全不理解语义
直观例子:
“我喜欢苹果”
“我讨厌苹果”
在 TF-IDF 里几乎一样,因为两句都有“我 + 苹果”。
模型只看到:
这些词都出现了,所以它们很像。
它根本不理解“喜欢”和“讨厌”是相反含义。
第三代:语义向量诞生(Word2Vec)
2013 年,Google 的 Word2Vec 是第一代真正有“语义”的向量。
它通过预测上下文来学习,例如:
- “我吃了一个 ___” → “苹果”
- “香蕉放在桌子上”
- “水果对身体好”
模型从大量语料中“发现”:
苹果和香蕉常出现在类似场景 → 应该放得更近。
于是出现经典例子:
king - man + woman ≈ queen
这是第一次,机器真的学到了“语义关系”。
直观例子:
Word2Vec 会把:
- “北京”和“上海”放得很近(都是中国城市)
- “猫”和“狗”放得近(都是动物)
- “苹果”和“香蕉”摆在一起(都是水果)
- 但“苹果”和“苹果手机”区分开来(上下文不同)
这已经比 TF-IDF 强太多。
但 Word2Vec 只有“词向量”,一个词只有一个意思:
- “苹果” = 水果 or iPhone?
Word2Vec 分不出来。
第四代:上下文语义向量(BERT 时代)
2018 年 BERT 出现,解决了 Word2Vec 最大的问题:
同一个词在不同句子里可以有不同向量。
例子:
句子A:
“我吃了一个苹果。”
→ “苹果”向量靠近“水果”
句子B:
“苹果发布了新手机。”
→ “苹果”向量靠近“科技公司”
这是 NLP 历史上第一次,模型真正看懂了“上下文语义”。
其他改变:
- Transformer 架构
- 大规模预训练
- 上下文感知的 embedding
但问题是:
- BERT 适合分类、抽取
- 直接用 BERT 做检索不行(句向量相似度不稳定)
于是出现下一代。
第五代:句子/文档级语义向量(SBERT、SimCSE、bge)
BERT 学一句话没问题,但拿来算“句子之间的相似度”不稳定。
于是研究者专门训练句向量模型(Sentence Embedding):
- SBERT(2019)
- SimCSE(2021)
- bge 系列(2023–2024)
他们使用对比学习训练:
让语义相似的句子向量更近
让不相似的句子更远
直观例子:
模型会把这些判定为“很像”:
- “如何重置密码?”
- “忘记密码怎么办?”
- “账号密码重置教程”
它们向量会自动靠近。
而这些会被拉远:
- “怎么煮面条?”
- “昨天天气很好”
这一代模型成为 RAG、向量检索、知识库问答的核心基础设施。
第六代:LLM 专用嵌入(GPT 系列、Embedding-3)
进入大模型时代后,embedding 来自更强的语言模型。
特点:
- 向量更稳健(几乎不会抖动)
- 多语言能力自然继承自 LLM
- 向量维度合理压缩(不再需要 4000 维)
- LLM 内部语义直接可用(最强语义表示)
例子:
text-embedding-3-large 可以把:
“CPU 占用过高怎么办?”
与
“How to diagnose high CPU usage?”
距离算得非常精准,甚至比 bge、SimCSE 更强,这类模型是目前语义检索的顶级方案。
| 阶段 | 方法 | 是否语义? | 是否 float? | 是否上下文感知? |
|---|---|---|---|---|
| NLP 早期 | One-hot | ❌ | ❌(int) | ❌ |
| NLP 中期 | TF-IDF | ❌ | float 但无语义 | ❌ |
| Word2Vec 时代 | Word2Vec | ✔ | ✔ | ❌ |
| BERT 时代 | BERT | ✔✔ | ✔ | ✔ |
| SBERT / bge | 专用句向量 | ✔✔✔ | ✔ | ✔ |
| LLM 时代 | GPT embedding | ✔✔✔✔(最强) | ✔ | ✔ |
模型通过大量文本学习语义规律,自动把词和句子映射到一个连续的高维空间。为了训练可微、表达连续语义,向量必须是 float。不同模型因为训练语料、结构、目标不同,其向量空间也不同,因此输出不可能一致。
chromadb基础使用
尽管上面系统梳理了 NLP 到现代 LLM 的向量表示演进路径,但对没有系统学习过 AI 的开发者来说,这些概念往往依旧是“知道词语但不知道怎么用”的状态。Embedding、语义空间、对比学习、上下文表征……这些技术背后的数学与模型原理实际上非常庞杂,如果要深入讲清楚,需要成体系的学习和大量篇幅。对日常开发而言,目前最核心、也最需要记住的一点就是:**嵌入模型能够把自然语言转换成向量,而我们只需要拿这个向量去做相似度搜索或语义检索,就能立刻产生业务价值。**至于这些向量是如何训练出来、为什么能表达语义、内部结构是怎样的,这些都可以在未来有时间后再深入学习,当你真正想系统进入 AI 领域时再补也完全来得及。
基于这样的开发者视角,我们接下来不再扩展模型理论,而是直接进入工程实践,认识一个实际应用向量的工具——ChromaDB。它能帮助我们高效地存储、检索、管理向量,为各种 RAG、搜索或智能问答系统提供底层能力,让“自然语言 → 向量 → 检索 → 结果”这一链路真正落地。
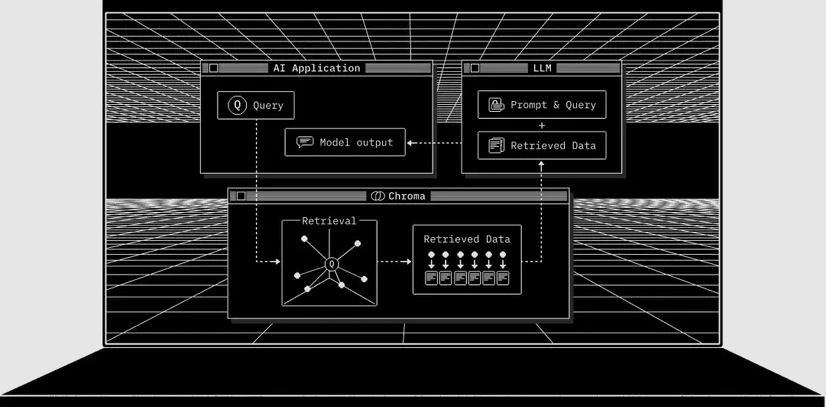
ChromaDB 正是目前业界最主流、最成熟的开源向量数据库之一。它的定位是:为 AI 应用而生的数据库(AI Application Database)。通过 ChromaDB,开发者可以像使用普通数据库一样,将知识、事实、文档等信息“插入”到系统中,并让 LLM 以向量检索的方式访问这些信息。
ChromaDB 提供了构建检索增强应用(RAG)所需的全部基础能力,包括:
- 嵌入向量存储:保存模型生成的 embedding 及其关联的原始文本、元数据(metadata)。
- 向量搜索(Vector Search):基于相似度的近邻检索,让模型能找到语义上最接近的内容。
- 全文检索(Full-text Search):支持关键词级别的快速搜索,与向量搜索互补。
- 文档存储(Document Storage):不仅存向量,也能存原文文本、结构化信息等。
- 元数据过滤(Metadata Filtering):可以按标签、来源、时间等维度过滤,提高召回精度。
- 多模态检索(Multi-modal Retrieval):不仅能搜索自然语言,还能处理图像和其他模态的向量。
Chroma 以服务(server)形式运行,并提供了 Python 与 JavaScript/TypeScript 的官方 SDK,适用于本地开发、线上部署、甚至在 Jupyter Notebook 里进行快速实验。作为 Apache 2.0 开源项目,它不仅免费、可商用,也拥有快速迭代与活跃社区,是目前 AI 应用开发中最常见的基础设施之一。
简单来说,如果嵌入模型负责把文本转换为向量,那么 ChromaDB 就负责把这些向量“管起来”,让你的系统能通过语义检索真正利用它们。
快速开始
注意:这里直接pip install chromadb会安装完整的chromadb包。
-
安装
pip install chromadb -
创建 Chroma Client
import chromadb chroma_client = chromadb.Client() -
创建一个 Collection
Collection 是你存储 向量、文档(text)以及任何元数据(metadata) 的地方。
它会负责对向量与文档建立索引,并提供高效的检索与过滤能力。通过名称即可创建一个 Collection:
collection = chroma_client.create_collection(name="my_collection") -
向 Collection 添加文本数据
Chroma 会自动存储你的文本,并负责 向量化(embedding)与索引。
你也可以自定义嵌入模型。
注意:每条数据必须提供唯一的字符串 ID。collection.add( ids=["id1", "id2"], documents=[ "This is a document about pineapple", "This is a document about oranges" ] ) -
查询 Collection
你可以使用一组查询文本来检索相似文档,Chroma 会自动对查询文本进行嵌入,并返回最相似的 n 条结果。
results = collection.query( query_texts=["This is a query document about hawaii"], # Chroma 会自动向量化 n_results=2 # 返回结果数量 ) print(results)如果不提供
n_results,默认返回 10 条。这里因为我们只插入了两条文档,所以设为 2。 -
查看检索结果
例如上面的查询会返回类似结果。查询内容关于 hawaii,与 pineapple 语义更接近,因此得分更高:
{ 'documents': [[ 'This is a document about pineapple', 'This is a document about oranges' ]], 'ids': [['id1', 'id2']], 'distances': [[1.0404009819030762, 1.243080496788025]], 'uris': None, 'data': None, 'metadatas': [[None, None]], 'embeddings': None, } -
示例
如果把查询换成 “This is a document about florida”,可以运行以下完整示例:
import chromadb chroma_client = chromadb.Client() # 使用 get_or_create_collection,避免每次都创建新的 collection collection = chroma_client.get_or_create_collection(name="my_collection") # 使用 upsert,避免重复写入相同文档 collection.upsert( documents=[ "This is a document about pineapple", "This is a document about oranges" ], ids=["id1", "id2"] ) results = collection.query( query_texts=["This is a query document about florida"], # 自动向量化 n_results=2 ) print(results)
chroma的运行模式
在掌握了 ChromaDB 的基本用法之后,我们还需要明确一个关键点:Chroma 并不是只有一种运行方式。根据你的使用场景、部署环境、性能要求以及是否需要持久化,Chroma 提供了四种不同的运行模型。从轻量级、本地一次性使用,到生产级的 Server 模式,再到官方托管的 Cloud 服务,开发者可以根据项目阶段自由选择最合适的方式。
接下来,我们就分别介绍 Chroma 提供的四种运行模式:Ephemeral Client、Persistent Client、Client-Server 模式以及 Cloud Client,并分析它们适用的场景与差异。
快速开始中的Client() 其实只是一个使用默认 Settings 初始化出的标准客户端,而 RustClient()、PersistentClient()、EphemeralClient()、HttpClient() 等方法,都是在内部 预先配置好不同 Settings 参数后,再调用同一个 ClientCreator 来生成客户端实例。因此,它们并不是不同的“客户端类型”,而是 同一套 Client API 的不同配置版本,区别只在于底层使用的后端实现方式(Python / Rust / Server / Cloud)、是否持久化,以及连接方式。
Ephemeral Client(临时客户端)
在 Python 中,你可以直接在内存中运行一个 Chroma 服务器,并通过 Ephemeral Client 进行连接:
import chromadb
client = chromadb.EphemeralClient()
EphemeralClient() 会在内存中启动一个 Chroma 实例,并返回一个已经连接好的客户端。
这种方式非常适合在 Python Notebook / Jupyter / Colab 中做快速实验,比如尝试不同的嵌入模型、测试检索效果等。如果你对数据持久化没有需求,那么 Ephemeral Client 是使用 Chroma 最轻量、最快速的方式。
Persistent Client(持久化客户端)
你可以使用 PersistentClient 让 Chroma 将数据库保存并加载到本地磁盘,实现数据持久化。
数据会在写入时自动持久化,并在下次启动 Chroma 时自动加载(如果存在的话)。
import chromadb
client = chromadb.PersistentClient(path="/path/to/save/to")
path 指定 Chroma 在本地存储数据库文件的位置,并在启动时从该路径加载。
如果未指定路径,默认使用当前目录下的 .chroma 文件夹。
PersistentClient 提供了一些实用的便捷方法:
- heartbeat():返回一个纳秒级心跳,用于检查客户端是否仍保持连接。
- reset():清空并重置整个数据库。⚠️ 不可逆操作,请谨慎使用。
示例:
client.heartbeat()
client.reset()
Client-Server 模式运行 Chroma
Chroma 也可以以 客户端 / 服务器(Client-Server)模式运行。在这种模式下,Chroma 的客户端会连接到一个运行在独立进程中的 Chroma 服务器。
首先,启动 Chroma 服务器:
chroma run --path /db_path
然后在客户端使用 HttpClient 连接到该服务器:
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', port=8000)
仅需这一行替换,Chroma 的 API 就会自动切换为 Client-Server 模式。
Chroma 还提供了 异步版本的 HTTP 客户端。其行为与同步版本完全一致,只是所有会阻塞的操作变为 async。使用方式如下:
import asyncio
import chromadb
async def main():
client = await chromadb.AsyncHttpClient()
collection = await client.create_collection(name="my_collection")
await collection.add(
documents=["hello world"],
ids=["id1"]
)
asyncio.run(main())
如果你将 Chroma 部署为独立服务,也可以使用官方提供的 http-only 轻量客户端包 来连接运行中的服务器。
在 Python 应用中以 Client-Server 模式运行 Chroma 时,你通常不需要完整的 Chroma 库。此时,可以使用更轻量的 客户端专用库。
chromadb-client 是一个 纯 HTTP 的精简客户端,只包含连接 Chroma Server 所需的能力,依赖最少、体积更轻。
pip install chromadb-client
示例:
# Python
import chromadb
# 连接到已运行的 Chroma 服务器
client = chromadb.HttpClient(host='localhost', port=8000)
异步版本示例:
async def main():
client = await chromadb.AsyncHttpClient(host='localhost', port=8000)
需要注意:
-
chromadb-client是完整 Chroma 库的子集,不包含所有依赖。
如果你需要完整功能,请安装chromadb包。 -
最重要的是:Thin-Client 不内置任何默认的 embedding function。
如果你直接调用add()但未提供 embedding,Chroma 无法自动向量化,你必须手动指定嵌入模型并安装它需要的依赖。
在 Docker 中运行 Chroma 服务器
你可以将 Chroma 作为一个 Docker 容器运行,并通过 HttpClient 进行访问。官方镜像在 docker.com 和 ghcr.io 上均可获取。
启动服务器:
docker run -v ./chroma-data:/data -p 8000:8000 chromadb/chroma
这将使用默认配置启动 Chroma,并将数据存储到当前目录下的 ./chroma-data。
然后在 Python 中配置客户端连接容器中的 Chroma 服务:
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', port=8000)
chroma_client.heartbeat()
Chroma 使用 YAML 文件进行配置。你可以查看官方示例来了解所有可用配置项。
如果你想在 Docker 中使用自定义配置文件,只需将其挂载到容器内的 /config.yaml:
echo "allow_reset: true" > config.yaml # 允许客户端重置服务器状态
docker run -v ./chroma-data:/data -v ./config.yaml:/config.yaml -p 8000:8000 chromadb/chroma
Chroma 内置了 OpenTelemetry(OTel) 的可观测性能力。通过 OpenTelemetry,你可以追踪请求在系统中的流转路径,快速定位瓶颈。
官方文档中提供了所有可调参数的说明。
下面是一个使用 Docker Compose 搭建可观测性栈(Observability Stack) 的完整示例。该栈包含:
- Chroma Server
- OpenTelemetry Collector
- Zipkin(可视化链路追踪工具)
Step 1:创建 OpenTelemetry Collector 配置文件
新建 otel-collector-config.yaml 并粘贴以下内容:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
exporters:
debug:
zipkin:
endpoint: "http://zipkin:9411/api/v2/spans"
service:
pipelines:
traces:
receivers: [otlp]
exporters: [zipkin, debug]
说明:
-
receivers:表示使用 OTLP 协议接收 GRPC / HTTP 的遥测数据。
-
exporters:将链路追踪数据输出到:
- 控制台(debug)
- Zipkin(通过 docker-compose 中的 zipkin 服务)
-
service:将上述配置组合为一个完整 trace 管道。
Step 2:创建 Docker Compose 文件
新建 docker-compose.yml:
services:
zipkin:
image: openzipkin/zipkin
ports:
- "9411:9411"
depends_on: [otel-collector]
networks:
- internal
otel-collector:
image: otel/opentelemetry-collector-contrib:0.111.0
command: ["--config=/etc/otel-collector-config.yaml"]
volumes:
- ${PWD}/otel-collector-config.yaml:/etc/otel-collector-config.yaml
networks:
- internal
server:
image: chromadb/chroma
volumes:
- chroma_data:/data
ports:
- "8000:8000"
networks:
- internal
environment:
- CHROMA_OPEN_TELEMETRY__ENDPOINT=http://otel-collector:4317/
- CHROMA_OPEN_TELEMETRY__SERVICE_NAME=chroma
depends_on:
- otel-collector
- zipkin
networks:
internal:
volumes:
chroma_data:
Step 3:启动可观测性栈
docker compose up --build -d
本地运行时,打开:
即可访问 Zipkin。
刚启动时不会有 trace,这属于正常现象。你可以通过 Heartbeat API 创建一条示例链路:
curl http://localhost:8000/api/v2/heartbeat
然后在 Zipkin 页面中点击 Run Query 就能看到刚产生的 trace 了。
云端客户端(Cloud Client)
你可以使用 CloudClient 来创建一个连接到 Chroma Cloud 的客户端。
client = CloudClient(
tenant='Tenant ID',
database='Database name',
api_key='Chroma Cloud API key'
)
CloudClient 也可以只通过传入 API key 来初始化。在这种情况下,Chroma Cloud 会自动解析租户(tenant)和数据库(database)。
⚠️注意:只有当提供的 API key 只绑定到一个数据库 时,这种自动解析才能生效。
如果你设置了环境变量:
CHROMA_API_KEYCHROMA_TENANTCHROMA_DATABASE
那么你就可以直接不传任何参数初始化 CloudClient:
client = CloudClient()
管理 Chroma Collection(集合)
Chroma 通过 Collection(集合) 这一核心概念来管理 embedding。
Collection 是 Chroma 中存储与向量检索的基本单位。
下面是自然、专业且忠实原文的中文翻译:
创建 Collection
Chroma 的 Collection 是通过一个名称来创建的。
由于 Collection 名称会出现在 URL 中,因此它们必须遵守以下限制:
- 名称长度必须在 3 到 512 个字符之间
- 名称必须以 小写字母或数字 开头和结尾
- 中间可以包含
.、-、_ - 名称中不能出现连续的
.. - 名称不能是一个有效的 IP 地址
示例:
collection = client.create_collection(name="my_collection")
请注意:在同一个 Chroma 数据库中,Collection 名称必须唯一。如果尝试创建一个已存在名称的集合,会抛出异常。
向 Collection 添加文档时,Chroma 会使用该集合配置的 embedding function 来自动生成向量。默认情况下,Chroma 使用 Sentence Transformer 作为默认 embedding 模型。
Chroma 也支持在创建 Collection 时手动指定不同的 embedding function。
例如,使用 OpenAI 的 embedding 模型:
pip install openai
import os
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
collection = client.create_collection(
name="my_collection",
embedding_function=OpenAIEmbeddingFunction(
api_key=os.getenv("OPENAI_API_KEY"),
model_name="text-embedding-3-small"
)
)
你也可以在创建集合时设置 embedding_function=None,让 Chroma 不自动生成 embedding。这种情况下:
- Chroma 不会向量化文档
- 你必须在 add / query 时 手动提供向量
示例:
collection = client.create_collection(
name="my_collection",
embedding_function=None
)
在创建 Collection 时,你可以通过 metadata 参数添加元数据,用于描述集合的一些通用信息,例如:
- 创建时间
- 集合用途说明
- 文档内容类别
示例:
from datetime import datetime
collection = client.create_collection(
name="my_collection",
embedding_function=emb_fn,
metadata={
"description": "my first Chroma collection",
"created": str(datetime.now())
}
)
或者更保险一点,可以使用get_or_create_collection:
client.get_or_create_collection()
下面是专业且忠实原文的中文翻译:
获取 Collection
在创建完 Collection 之后,Chroma 提供多种方式来重新获取它。
get_collection 会根据名称从 Chroma 中获取一个已存在的集合,并返回一个包含:
- name
- metadata
- configuration
- embedding_function
的 Collection 对象。
示例:
collection = client.get_collection(name="my-collection")
get_or_create_collection 与 get_collection 类似,但如果该集合不存在,它会自动创建。
你可以向它传入与 create_collection 相同的参数;如果集合已存在,这些参数会被忽略。
collection = client.get_or_create_collection(
name="my-collection",
metadata={"description": "..."}
)
list_collections 会返回当前 Chroma 数据库中的所有集合,按创建时间从最早到最新排序。
collections = client.list_collections()
默认情况下,它最多返回 100 个集合。
如果你的集合超过 100 个,或者你只需要获取部分集合,可以使用 limit 和 offset:
first_collections_batch = client.list_collections(limit=100) # 前 100 个
second_collections_batch = client.list_collections(limit=100, offset=100) # 第 101~200 个
collections_subset = client.list_collections(limit=20, offset=50) # 从第 50 个开始取 20 个
当前版本的 Chroma(≥1.1.13)会在服务器端保存集合使用的 embedding function,因此在之后使用 get_collection 时,客户端可以自动解析出该 embedding function。
如果你使用的是较旧版本(<1.1.13),则必须在获取集合时手动提供当初创建集合时使用的 embedding function:
collection = client.get_collection(
name='my-collection',
embedding_function=ef
)
修改 Collection
在创建 Collection 之后,你可以通过 modify 方法修改它的名称、元数据,以及索引配置中的部分元素:
collection.modify(
name="new-name",
metadata={"description": "new description"}
)
删除 Collection
你可以通过名称删除一个 Collection。此操作会删除该 Collection 以及其中所有的向量、文档与记录元数据。
⚠️ 删除 Collection 是不可逆的破坏性操作。
client.delete_collection(name="my-collection")
便捷方法(Convenience Methods)
Collection 还提供了一些常用的便捷方法:
- count:返回集合中的记录数量。
- peek:返回集合中的前 10 条记录。
collection.count()
collection.peek()
数据CRUD
向 Chroma Collection 中添加数据
使用 .add 方法可以向 Chroma 的 Collection 添加数据。
该方法需要提供一组唯一的字符串 ID,以及一组文档(documents)。Chroma 会使用该 Collection 配置的 embedding function 自动对这些文档进行向量化,并同时保存文档内容本身。
你也可以选择性地为每条文档提供一个 metadata 字典。
collection.add(
ids=["id1", "id2", "id3", ...],
documents=["lorem ipsum...", "doc2", "doc3", ...],
metadatas=[
{"chapter": 3, "verse": 16},
{"chapter": 3, "verse": 5},
{"chapter": 29, "verse": 11},
...
],
)
如果添加的记录中某个 ID 已经在集合中存在,该记录会被忽略,不会抛出异常。
因此,如果批量添加失败,你可以安全地重复执行添加操作。
你也可以直接提供一组文档对应的 embedding,Chroma 会存储文档但不会再自动向量化。
请注意,Chroma 无法验证你提供的 embedding 是否与对应文档真实匹配。
collection.add(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
documents=["doc1", "doc2", "doc3", ...],
metadatas=[
{"chapter": 3, "verse": 16},
{"chapter": 3, "verse": 5},
{"chapter": 29, "verse": 11},
...
],
)
如果你提供的 embedding 维度与该 Collection 中已经索引的数据维度不一致,将会抛出异常。
你也可以完全不在 Chroma 中存储文档,只提供 embedding 和 metadata。
此时你可以用 ids 在外部系统中关联你的文档与向量。
collection.add(
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[
{"chapter": 3, "verse": 16},
{"chapter": 3, "verse": 5},
{"chapter": 29, "verse": 11},
...
],
ids=["id1", "id2", "id3", ...]
)
更新 Chroma Collection 中的数据
使用 .update 方法可以更新集合中记录的任意属性:
collection.update(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[
{"chapter": 3, "verse": 16},
{"chapter": 3, "verse": 5},
{"chapter": 29, "verse": 11},
...
],
documents=["doc1", "doc2", "doc3", ...],
)
如果某个 id 在集合中不存在,系统会记录错误日志,并忽略该条更新操作。
如果仅提供文档但未提供对应的 embedding,Chroma 会使用该 Collection 的 embedding function 自动重新计算向量。
如果提供的 embedding 维度与当前 Collection 中已有的数据维度不一致,将会抛出异常。
Chroma 也支持 upsert 操作,它会在记录存在时执行更新,不存在时自动创建:
collection.upsert(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[
{"chapter": 3, "verse": 16},
{"chapter": 3, "verse": 5},
{"chapter": 29, "verse": 11},
...
],
documents=["doc1", "doc2", "doc3", ...],
)
如果 id 在集合中不存在,则行为与 add 相同,创建新记录;
如果 id 已存在,则按 update 的逻辑进行更新。
从 Chroma Collection 中删除数据
Chroma 支持通过 .delete 方法按 id 删除集合中的数据。与这些条目相关的 embeddings、documents 以及 metadata 都会被一并删除。
这类删除操作具有破坏性,且无法恢复:
collection.delete(
ids=["id1", "id2", "id3", ...],
)
.delete 同样支持 where 条件过滤器。如果未提供 ids,则会删除集合中所有满足 where 条件的记录:
collection.delete(
ids=["id1", "id2", "id3", ...],
where={"chapter": "20"}
)
从 Chroma Collection 中查询/过滤/搜索数据
你可以通过 .query 方法对 Chroma 集合执行向量相似度搜索:
collection.query(
query_texts=["thus spake zarathustra", "the oracle speaks"]
)
Chroma 会使用集合配置的 embedding function 对输入的文本进行向量化,并基于生成的向量执行相似度搜索。
除了传入 query_texts,你也可以直接提供 query_embeddings。
⚠ 这种方式适用于 你向集合添加时也使用了自己的 embedding,而不是集合的 embedding function 的情况。
如果 query_embeddings 的维度与集合中的向量不一致,会抛出异常:
collection.query(
query_embeddings=[[11.1, 12.1, 13.1], [1.1, 2.3, 3.2], ...]
)
默认情况下,Chroma 为每个输入查询返回前 10 条结果。你可以使用 n_results 修改数量:
collection.query(
query_embeddings=[[11.1, 12.1, 13.1], [1.1, 2.3, 3.2], ...],
n_results=5
)
ids 参数可以限制只在给定的 ID 列表中执行搜索:
collection.query(
query_embeddings=[[11.1, 12.1, 13.1], [1.1, 2.3, 3.2], ...],
n_results=5,
ids=["id1", "id2"]
)
.get 方法用于直接从集合中获取记录,支持以下参数:
ids:只返回指定 ID 的记录。如果不指定,将返回前 100 条,以加入顺序为准。limit:获取记录数量,默认 100。offset:返回记录的起始偏移量,用于分页。
示例:
collection.get(ids=["id1", "ids2", ...])
.query 和 .get 均支持 where 和 where_document 参数:
collection.query(
query_embeddings=[[11.1, 12.1, 13.1], [1.1, 2.3, 3.2], ...],
n_results=5,
where={"page": 10}, # 按 metadata 中的 page 字段过滤
where_document={"$contains": "search string"} # 对 document 做全文或正则匹配
)
Chroma 会以“列式结构”返回 .query 和 .get 的结果。结果对象包含匹配到的 id、向量、文档、metadata 等:
class QueryResult(TypedDict):
ids: List[IDs]
embeddings: Optional[List[Embeddings]]
documents: Optional[List[List[Document]]]
metadatas: Optional[List[List[Metadata]]]
distances: Optional[List[List[float]]]
included: Include
class GetResult(TypedDict):
ids: List[ID]
embeddings: Optional[Embeddings]
documents: Optional[List[Document]]
metadatas: Optional[List[Metadata]]
included: Include
对于 .query:
- 会额外返回
distances - 返回结构按输入 query 一一对应
results["ids"][0]表示第一个查询对应的结果列表
示例:
results = collection.query(query_texts=["first query", "second query"])
默认情况下,.query 和 .get 会返回:
idsdocumentsmetadatas
你可以通过 include 参数自定义,如:
collection.query(query_texts=["my query"])
# 返回 ids、documents、metadatas
collection.get(include=["documents"])
# 只返回 ids 和 documents
collection.query(
query_texts=["my query"],
include=["documents", "metadatas", "embeddings"]
)
# 返回 ids、documents、metadatas、embeddings
元数据过滤(Metadata Filtering)
在 get 和 query 操作中,where 参数用于根据元数据(metadata)过滤记录。
例如,下面的查询中,Chroma 只会检索 page=10 的记录:
collection.query(
query_texts=["first query", "second query"],
where={"page": 10}
)
要对元数据进行过滤,必须在查询中提供一个 where 过滤字典,其结构如下:
{
"metadata_field": {
<Operator>: <Value>
}
}
使用 $eq 操作符等价于直接在 where 中指定字段:
{
"metadata_field": "search_string"
}
等价于:
{
"metadata_field": {
"$eq": "search_string"
}
}
例如,查询 page 字段大于 10 的记录:
collection.query(
query_texts=["first query", "second query"],
where={"page": {"$gt": 10}}
)
你可以使用逻辑操作符 $and 和 $or 来组合多个过滤条件。
$and:满足所有条件的记录
结构如下:
{
"$and": [
{"metadata_field": {<Operator>: <Value>}},
{"metadata_field": {<Operator>: <Value>}}
]
}
示例:查询 page 在 5 到 10 之间的记录:
collection.query(
query_texts=["first query", "second query"],
where={
"$and": [
{"page": {"$gte": 5}},
{"page": {"$lte": 10}}
]
}
)
$or:满足任一条件的记录
{
"or": [
{"metadata_field": {<Operator>: <Value>}},
{"metadata_field": {<Operator>: <Value>}}
]
}
示例:获取 color=red 或 color=blue 的记录:
collection.get(
where={
"or": [
{"color": "red"},
{"color": "blue"}
]
}
)
使用包含操作符($in / $nin)
Chroma 支持以下包含类操作符:
- $in:值在列表中
- $nin:值不在列表中(或键不存在)
示例 - $in:
{
"metadata_field": {
"$in": ["value1", "value2", "value3"]
}
}
示例 - $nin:
{
"metadata_field": {
"$nin": ["value1", "value2", "value3"]
}
}
查询示例:匹配作者为列表中任意一个:
collection.get(
where={
"author": {"$in": ["Rowling", "Fitzgerald", "Herbert"]}
}
)
.get 和 .query 可以同时进行元数据过滤和文档搜索:
collection.query(
query_texts=["doc10", "thus spake zarathustra", ...],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains": "search_string"}
)
全文检索与正则表达式(Full Text Search and Regex)
在 get 和 query 操作中,where_document 参数用于基于 document 字段内容 来过滤记录。
Chroma 支持以下全文检索与正则匹配操作符:
- $contains:包含某字符串(全文检索)
- $not_contains:不包含某字符串
- $regex:匹配正则表达式
- $not_regex:不匹配正则表达式
例如,获取所有 document 包含某字符串的记录:
collection.get(
where_document={"$contains": "search string"}
)
注意:全文检索是区分大小写的。
获取所有 document 符合电子邮件格式的记录:
collection.get(
where_document={
"$regex": "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
}
)
你可以使用逻辑操作符来组合多个 document 过滤条件。
$and:文档必须同时满足所有条件
collection.query(
query_texts=["query1", "query2"],
where_document={
"$and": [
{"$contains": "search_string_1"},
{"$regex": "[a-z]+"},
]
}
)
$or:满足任意一个条件即可
collection.query(
query_texts=["query1", "query2"],
where_document={
"$or": [
{"$contains": "search_string_1"},
{"$not_contains": "search_string_2"},
]
}
)
与元数据过滤同时使用
.get 和 .query 可以同时执行:
- 元数据过滤(where)
- 文档内容过滤(where_document)
示例:
collection.query(
query_texts=["doc10", "thus spake zarathustra", ...],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains":"search_string"}
)
配置 Chroma Collections
Chroma 的集合(collections)具有一套配置,用于决定其 embedding 索引如何构建与使用。Chroma 为这些索引配置提供了默认值,通常已经能为大多数场景带来出色的性能。
你选择的 embedding function 也会影响索引的构建方式,并会被记录到集合配置中。
在创建 Collection 时,你可以根据数据规模、精度要求或性能需求,自定义这些索引配置。其中部分查询时的配置也可以在集合创建后通过 .modify 方法修改。
单节点HNSW 索引配置
在 单节点 Chroma 中,使用 HNSW(Hierarchical Navigable Small World)索引执行近似最近邻(ANN)搜索。
什么是 HNSW 索引? HNSW 索引包含以下参数:
space:定义向量的距离函数(相似度度量方式)
它决定 embedding 空间中如何衡量“相似”。默认是 l2(平方 L2 距离)。其他可选值:

注意:你选择的 space 必须被 embedding function 支持。每个 Chroma embedding function 都会声明其默认 space 和支持的列表。
ef_construction:建索引时的候选邻居数量
- 值越大,索引质量越好,但占用更多时间和内存
- 值越小,构建更快,但准确率下降
- 默认值:100
ef_search:查询时的候选邻居数量(可在创建后修改)
- 值越大:搜索更准,召回更高,但查询耗时增加
- 值越小:更快,但准确率降低
- 默认值:100
max_neighbors:索引图中每个节点的最大邻居数
- 高值 → 图更密集 → 更好的搜索准确率,但内存和构建时间增加
- 低值 → 图更稀疏 → 更省内存,但搜索精度下降
- 默认值:16
num_threads:构建或查询时使用的线程数(可修改)
- 默认:
multiprocessing.cpu_count()(所有可用 CPU 核心)
batch_size:索引操作的批处理大小(可修改)
- 默认:100
sync_threshold:索引何时与持久化存储同步(可修改)
- 默认:1000
resize_factor:索引扩容因子(可修改)
- 默认:1.2
示例:自定义 space 和 ef_construction
collection = client.create_collection(
name="my-collection",
embedding_function=OpenAIEmbeddingFunction(model_name="text-embedding-3-small"),
configuration={
"hnsw": {
"space": "cosine",
"ef_construction": 200
}
}
)
微调 HNSW 参数
在近似最近邻(ANN)搜索中,**召回率(recall)**指的是算法成功返回的“真实最近邻”占总真实最近邻的比例。
- 提高 ef_search 通常能提升召回率,但会降低查询速度。
- 提高 ef_construction 同样能提升召回率,但会在构建索引时增加内存占用与运行时间。
如何选择合适的 HNSW 参数取决于你的数据特性、embedding function,以及你对召回率和性能的要求。通常需要对不同的构建参数和查询参数进行实验,以找到最适合你的配置。
假设我们有一个数据集,包含 50,000 个、每个 2048 维的向量:
embeddings = np.random.randn(50000, 2048).astype(np.float32).tolist()
我们用它们建立两个 Chroma 集合:
集合 1:ef_search = 10
当使用 id = 1 的向量进行查询时:
- 查询耗时:0.00529 秒
- 返回的距离结果为:
[3629.019775390625, 3666.576904296875, 3684.57080078125]
集合 2:ef_search = 100,ef_construction = 1000
当用同样的向量查询:
- 查询耗时:0.00753 秒(约慢 42%)
- 返回的距离结果为:
[0.0, 3620.593994140625, 3623.275390625]
在此示例中:
- 集合 1 甚至没找到测试向量自身,尽管它确实存在于集合中(理应返回 0.0 的距离作为第一项)。
- 集合 2 虽然稍慢,但成功找到查询向量自身(0.0 距离),并且返回的邻居距离也更近。
这说明:
更高的 ef_search / ef_construction → 更高的召回率、更精准的结果,但性能开销更大。
分布式 ChromaSPANN 索引配置
在 分布式 Chroma 和 Chroma Cloud 中,系统使用 SPANN(Spatial Approximate Nearest Neighbors) 索引来执行近似最近邻(ANN)搜索。
什么是 SPANN 索引?
目前,Chroma 不允许用户自定义或修改 SPANN 的配置。即使你设置了这些参数,服务器也会直接忽略。
SPANN 索引参数
1. space(距离函数)
用于定义 embedding 空间的距离度量方式,决定相似度计算方法。
默认值为 l2(平方 L2 距离)。
其它可选值:
| 距离 | 参数 | 公式 | 直觉理解 |
|---|---|---|---|
| 平方 L2 | l2 | ( d = \sum (A_i - B_i)^2 ) | 用于测量绝对“几何距离”,适合需要真实空间距离的场景 |
| 内积 | ip | ( d = 1.0 - \sum (A_i \times B_i) ) | 更关注“方向与强度”,常用于推荐系统 |
| 余弦相似度 | cosine | ( d = 1.0 - \frac{\sum A_i B_i}{\sqrt{\sum A_i^2} \cdot \sqrt{\sum B_i^2}} ) | 测量向量之间的角度(忽略长度),适用于文本 embedding |
2. search_nprobe
用于查询阶段:
- 值越大 → 准确度更高
- 值越大 → 查询时间更长
- 推荐值:64 / 128
- 最大允许值:128
- 默认值:64
3. write_nprobe
与 search_nprobe 类似,但用于 索引构建阶段:
- 控制在添加新向量或重新分配点时,搜索多少个聚类中心
- 默认值:64
- 最大允许值:128
4. ef_construction
索引构建时的候选列表大小。
- 越大:索引更精准,但内存与构建时间增加
- 越小:构建更快但精度下降
- 默认值:200
5. ef_search
搜索时动态候选集大小。
- 越大 → 召回率更高,但查询变慢
- 越小 → 更快但准确度下降
- 默认值:200
6. max_neighbors
节点最多允许的邻居数量。
- 默认值:64
7. reassign_neighbor_count
在聚类被拆分时,用于重新分配点的“邻近聚类”数量。
- 默认值:64
Embedding Function Configuration(嵌入函数配置)
你在创建集合(collection)时所选择的嵌入函数,以及你为它设置的初始化参数,都会被保存在集合的配置中。这使得 Chroma 能够在你使用不同客户端访问集合时,正确地重建相同的嵌入函数。
你可以在 create 方法中通过参数设置 embedding function,也可以直接在集合的 configuration 中设置。
pip install openai cohere
import os
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction, CohereEmbeddingFunction
# 通过 `embedding_function` 参数传入
openai_collection = client.create_collection(
name="my_openai_collection",
embedding_function=OpenAIEmbeddingFunction(
model_name="text-embedding-3-small"
),
configuration={"hnsw": {"space": "cosine"}}
)
# 在集合的 `configuration` 中配置 `embedding_function`
cohere_collection = client.get_or_create_collection(
name="my_cohere_collection",
configuration={
"embedding_function": CohereEmbeddingFunction(
model_name="embed-english-light-v2.0",
truncate="NONE"
),
"hnsw": {"space": "cosine"}
}
)
注意:
许多嵌入函数需要 API Key 来与第三方嵌入模型服务交互。
Chroma 的 embedding functions 会自动读取该服务标准使用的环境变量。例如,OpenAIEmbeddingFunction 会自动从 OPENAI_API_KEY 环境变量读取 API key。
如果你的 API key 放在了一个非标准名称的环境变量中,你可以通过设置 api_key_env_var 参数来指定自定义的环境变量名。为了让嵌入函数能正常运行,你需要在使用集合的每一个环境中都设置该变量。
例如:
cohere_ef = CohereEmbeddingFunction(
api_key_env_var="MY_CUSTOM_COHERE_API_KEY",
model_name="embed-english-light-v2.0",
truncate="NONE",
)
chromadb进阶
多模态(Multimodal)
Chroma 支持多模态嵌入函数,这类函数能将不同模态的数据(如文本、图像)映射到同一 embedding 空间。
Chroma 内置了 OpenCLIPEmbeddingFunction,它同时支持文本和图像:
from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction
embedding_function = OpenCLIPEmbeddingFunction()
你可以直接向 Chroma 添加文本以外模态的嵌入。目前支持 图像 embeddings:
collection.add(
ids=['id1', 'id2', 'id3'],
images=[[1.0, 1.1, 2.1, ...], ...] # 图像对应的 numpy 数组列表
)
不同于文本(documents 会被存储在 Chroma 内部),Chroma 不会存储你的原始图像。
相反,你可以提供图像的 URI + 自定义数据加载器(Data Loader)。
Chroma 会:
- 使用数据加载器根据 URI 加载原始数据
- 用你指定的嵌入函数嵌入(例如 OpenCLIP)
- 仅存储向量,不存储原始文件
示例:使用 ImageLoader 从本地加载图片
import chromadb
from chromadb.utils.data_loaders import ImageLoader
from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction
client = chromadb.Client()
data_loader = ImageLoader()
embedding_function = OpenCLIPEmbeddingFunction()
collection = client.create_collection(
name='multimodal_collection',
embedding_function=embedding_function,
data_loader=data_loader
)
现在可以通过 URI 添加图片:
collection.add(
ids=["id1", "id2"],
uris=["path/to/file/1", "path/to/file/2"]
)
多模态模型支持在同一个 collection 里混合文本与图像
如果嵌入函数支持(如 OpenCLIP):
collection.add(
ids=["id3", "id4"],
documents=["This is a document", "This is another document"]
)
多模态集合可以用任意支持的模态进行查询。
以图像查询:
results = collection.query(
query_images=[...] # numpy 数组形式的图像
)
以文本查询:
results = collection.query(
query_texts=["This is a query document", "This is another query document"]
)
以 URI 查询(如果配置了 data_loader):
results = collection.query(
query_uris=[...] # URI 字符串列表
)
在结果中返回原始数据(如果存在 URI 并有 data_loader)
results = collection.query(
query_images=[...],
include=['data']
)
Chroma 会自动通过 data_loader 加载每个记录的原始数据并包含在结果中。也可以通过 include=['uris'] 返回 URI。
你可以像 add 一样更新多模态数据。目前支持更新图像:
collection.update(
ids=['id1', 'id2', 'id3'],
images=[...] # numpy 数组形式的图像
)
⚠️ 注意:一个 ID 同一时间只能存储一种模态的数据。
例如:
- 如果某条记录最初是文本
- 你用 image 更新它
- 那么这条记录将不再包含文本
更新会覆盖原模态数据。
架构(Architecture)
Chroma 采用模块化架构设计,重点关注性能与易用性。它可以在本地开发环境与大规模生产环境之间无缝扩展,并在所有部署模式下提供统一一致的 API。
Chroma 尽可能将数据持久化相关的问题委托给可信赖的子系统,例如 SQLite 和云对象存储,从而把系统设计的核心放在数据管理与信息检索的问题上。
Chroma 可运行在你需要的任何环境中,从本地实验到大规模生产工作负载。
- 本地模式:作为嵌入式库使用 —— 适合原型设计与实验。
- 单节点模式:作为单节点服务运行 —— 适合 < 1000 万条记录且集合数量有限的小中型工作负载。
- 分布式模式:作为可扩展的分布式系统运行 —— 适合大规模生产环境,可支持数百万个集合。
此外还可使用 Chroma Cloud,即 Chroma 的托管分布式版本。
核心组件(Core Components)
无论以何种方式部署,Chroma 都由五个核心组件组成。每个组件承担不同职责,并共同基于 Chroma 的共享数据模型协同工作。
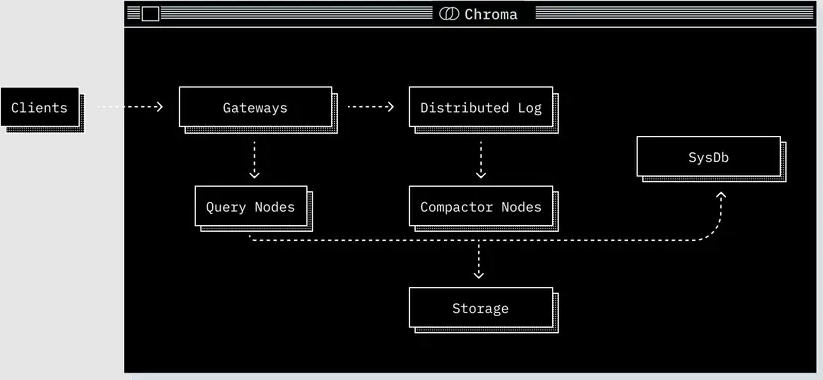
Gateway(网关)
客户端流量的入口。
- 在所有模式下都暴露一致的 API。
- 负责认证、限流、配额管理和请求校验。
- 将请求路由至下游服务。
Log(日志)
Chroma 的预写日志(write-ahead log)。
- 所有写操作在响应客户端前都会先写入日志。
- 确保多记录写操作的原子性。
- 在分布式模式中提供持久化与重放能力。
Query Executor(查询执行器)
负责所有读操作。
- 包含向量相似度搜索、全文检索与元数据检索。
- 保持一套内存 + 磁盘混合索引,并与日志协作以确保读取结果一致性。
Compactor(压缩器/索引构建器)
周期性构建和维护索引的服务。
- 从 Log 读取数据,根据日志构建新的向量 / 全文 / 元数据索引。
- 将已构建的索引结果写入共享存储。
- 更新系统数据库中的索引版本信息。
System Database(系统数据库)
Chroma 的内部目录。
- 管理租户、集合及相关元数据。
- 在分布式模式中,还负责管理集群状态(例如查询/Compactor 节点成员)。
- 底层由 SQL 数据库支持。
存储与运行时(Storage & Runtime)
根据部署模式不同,这些组件在存储方式和运行环境上会有所区别。
-
本地 / 单节点模式
- 所有组件运行在同一个进程内。
- 使用本地文件系统来保证持久化。
-
分布式模式
- 各组件以独立服务运行。
- 日志和构建好的索引存储在云对象存储中。
- 系统目录由 SQL 数据库支持。
- 所有服务都使用本地 SSD 作为缓存,以减少访问对象存储的延迟与成本。
请求流程(Request Sequences)
读取路径(Read Path)
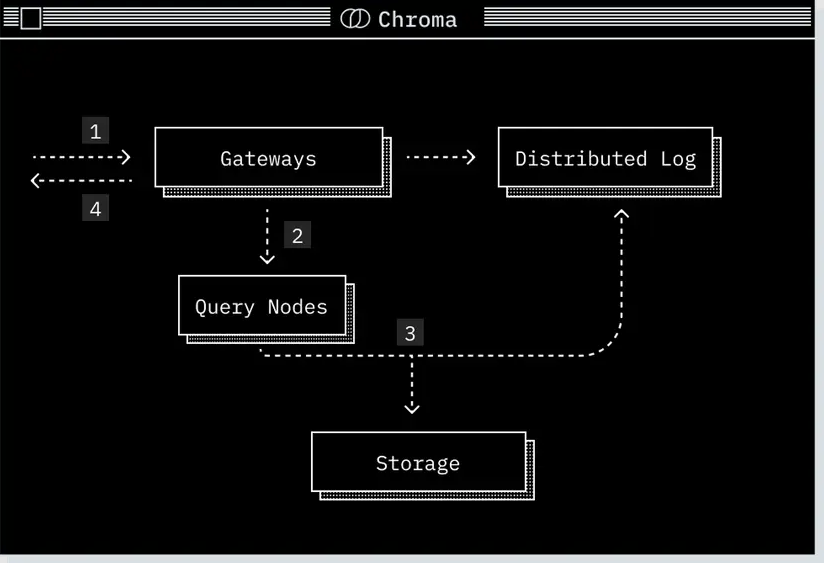
-
请求到达网关(gateway)
在这里进行身份认证、配额检查、限流处理,并将请求转换成逻辑计划(logical plan)。 -
逻辑计划被路由至相关的查询执行器(query executor)
在分布式 Chroma 中,会基于集合 ID 使用 Rendezvous Hash(会合哈希)进行路由,确保请求被发送到正确的节点,并保证缓存一致性。 -
查询执行器执行查询
- 将逻辑计划转换为物理计划(physical plan)。
- 从其存储层读取数据并执行查询。
- 为确保读取一致性,查询执行器还会从日志(log)中读取最新记录。
-
查询结果返回至网关,然后返回客户端。
写入路径(Write Path)
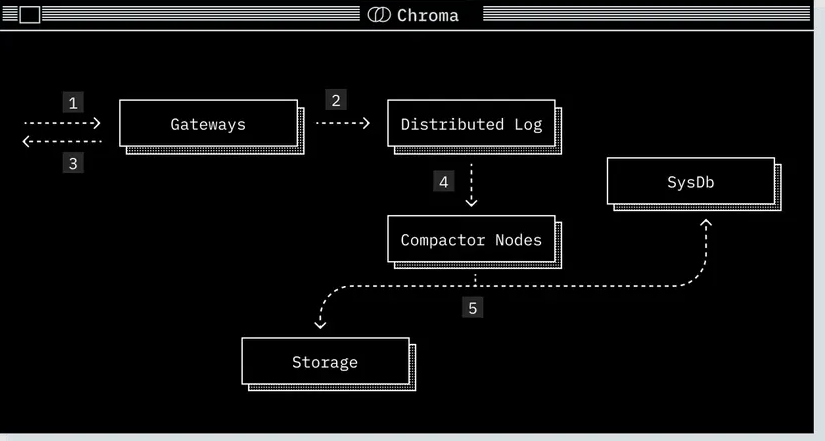
-
请求到达网关
在此进行身份认证、配额检查、限流处理,并被转换为一组操作日志(log of operations)。 -
操作日志被转发至预写日志(write-ahead-log)进行持久化。
-
预写日志完成持久化后,网关向客户端返回写入成功的确认。
-
Compactor 周期性地从预写日志中拉取写入记录,构建新的索引版本
包括:向量索引、全文索引、元数据索引,且均经过读性能优化。 -
新构建的索引版本写入存储,并在系统数据库中注册。
权衡(Tradeoffs)
分布式 Chroma 构建在对象存储(Object Storage)之上,以确保数据持久化并降低成本。对象存储具有极高吞吐量,足以占满单节点的网络带宽,但其代价是较高的基础访问延迟,大约 10–20ms。
为了降低延迟带来的影响,分布式 Chroma 大量使用 SSD 缓存:
-
首次查询某集合时:
系统需要从对象存储中选择性地读取查询所需的数据,会产生冷启动延迟(cold-start penalty)。 -
后台加载缓存时:
SSD 缓存会逐步被填充为该集合所需的数据。 -
当集合完全「热启动」后:
所有查询都会直接从 SSD 缓存中服务,不再访问对象存储。
Telemetry
Chroma 包含一个遥测功能,用于收集匿名的使用信息。如果你希望退出遥测(Opt-out),有两种方式可以关闭。
1. 在客户端代码中关闭
在客户端配置中将 anonymized_telemetry 设置为 False:
from chromadb.config import Settings
client = chromadb.Client(Settings(anonymized_telemetry=False))
# 或者如果你在使用 PersistentClient
client = chromadb.PersistentClient(
path="/path/to/save/to",
settings=Settings(anonymized_telemetry=False)
)
2. 在 Chroma 后端服务器通过环境变量关闭
在你的 shell 或服务器环境中设置环境变量:
ANONYMIZED_TELEMETRY=False
如果你通过 docker-compose 在本地运行 Chroma,可以在与 docker-compose.yml 同级目录放置一个 .env 文件,其中设置:
ANONYMIZED_TELEMETRY=False
结尾
随着 Chroma 在 0.5.x 版本中不断迭代,它已经从一个简单的本地向量数据库,成长为一套兼具灵活性、可扩展性与工程实践价值的嵌入式数据系统。从数据模型到索引机制,从客户端到后端部署,再到常见问题的排查,都体现出其在工程可靠性上的打磨与思考。
希望这篇文章能帮助你在实际项目中更高效地理解 Chroma 的设计理念并解决常见使用问题。如果你在使用过程中遇到其他坑、踩到更多边角案例,欢迎在评论区一起交流——也许你的问题正是别人正在寻找的答案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)