谷歌Deep Research Agent:从System 1到System 2的架构性突破
摘要: OpenAI的GPT-5.2通过扩展推理链(CoT)提升任务准确率,但面临指数级成本增长和错误累积问题;谷歌的Gemini采用混合架构,结合检索增强与工具调用,显著降低成本至GPT-5Pro的1/10。技术本质是端到端推理与分层系统的碰撞:OpenAI依赖单一模型的高强度计算,而谷歌通过任务分解、并行检索和轻量级模型协同实现高效资源分配。DeepSearchQA评测体系强调过程性指标(如成
当OpenAI用GPT-5.2 Thinking模式在SWE-Bench上刷到55.6%时,谷歌在同一天开源了Gemini Deep Research Agent,并在成本上做到了GPT-5 Pro的1/10。这不是简单的参数调优或工程优化,而是两种根本性架构范式的碰撞:
端到端推理(End-to-End Reasoning)vs 混合架构系统(Hybrid Architecture System)
一、技术本质:CoT的尽头是什么?
1.1 OpenAI的困境:推理链的指数级成本
GPT-5.2 Thinking本质上是对Chain-of-Thought(CoT)的极致化:
- 通过扩展中间推理token数量(可能达到数万甚至数十万token)来提升准确率
- 在MRCR测试中,256k上下文窗口下接近100%准确率
- 但代价是推理成本与token数量呈超线性增长
这背后的数学问题很明确:对于一个需要n步推理的问题,如果每步的token开销是T,那么总成本是O(n·T)。但更致命的是,中间步骤的错误会累积传播,导致需要引入self-correction机制,进一步推高成本。
用公式表达就是:
Total_Cost = Σ(T_i × P(correct|step_i)) + Correction_Cost
其中 Correction_Cost = Σ(T_j × P(error_detected))这就是为什么GPT-5.2 Pro在解决复杂问题时"思考时间"会非常长——它实际上在做内部蒙特卡洛搜索。
1.2 谷歌的方案:检索增强 + 工具调用的混合架构
Deep Research Agent的核心创新是把推理成本分摊到外部系统:
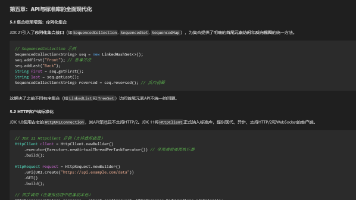
# 伪代码展示架构差异
# OpenAI方式(纯推理)
def solve_research_question(question):
context = model.extend_context(question, max_tokens=256k)
reasoning_chain = model.generate_cot(context)
answer = model.synthesize(reasoning_chain)
return answer
# 谷歌方式(混合架构)
def solve_research_question(question):
# 第一层:任务分解(小模型即可)
subtasks = agent.decompose(question)
# 第二层:并行检索(外包给搜索引擎)
results = []
for task in subtasks:
results.append(search_engine.query(task))
# 第三层:信息综合(只在关键节点调用大模型)
synthesized = model.synthesize(results, context_window=32k)
# 第四层:验证与迭代(可选)
if needs_verification:
synthesized = agent.verify_and_refine(synthesized)
return synthesized关键差异在于:
- OpenAI:把所有计算压力放在模型推理上,追求"一次性给出完美答案"
- 谷歌:把问题拆解成"搜索-过滤-综合"的pipeline,每个环节用最合适的工具
1.3 从复杂度理论看两种方案
用计算复杂度分析:
纯推理方案:
- 时间复杂度:O(n² × d),其中n是推理步骤数,d是模型维度
- 空间复杂度:O(n × context_length)
- 瓶颈:单点计算能力
混合架构方案:
- 时间复杂度:O(k × log(n) + m × d),其中k是子任务数,m是综合步骤数
- 空间复杂度:O(k × avg_doc_size)
- 瓶颈:IO延迟和数据质量
对于大多数"信息密集型"任务(如研究报告、市场分析),k和m远小于n,因此混合架构在总成本上有数量级优势。
二、DeepSearchQA:一个被低估的benchmark设计
2.1 为什么900个任务还不够?
传统benchmark的问题是评估粒度太粗:
- SWE-Bench只看"问题解决了吗",不看"用了多少资源"
- HumanEval只测"代码能跑吗",不测"代码可维护吗"
- MMLU只问"答案对吗",不问"推理过程合理吗"
DeepSearchQA的创新在于引入了过程性评估指标:
评分 = α × Accuracy + β × Completeness + γ × Citation_Quality + δ × Cost_Efficiency
其中:
- Accuracy: 答案正确性(传统指标)
- Completeness: 是否覆盖所有必要子问题
- Citation_Quality: 引用来源的权威性和相关性
- Cost_Efficiency: 达到目标所需的token数/API调用次数这套评估体系实际上是在说:"我不仅要你答对,还要你证明你是怎么答对的,并且不能浪费资源。"
2.2 Inference Time Scaling的深层含义
DeepSearchQA中有个关键图表:Inference Time Scaling。它展示了随着"pass@n"增加,准确率如何提升。
这背后隐藏着一个重要洞察:Agent的可靠性本质上是一个采样问题。
传统模型是:
P(correct) = P(model generates correct answer in one shot)Agent模式是:
P(correct) = 1 - Π[1 - P(path_i leads to correct answer)]当你有多个并行路径(多次搜索、多个来源、多种推理策略)时,整体可靠性会快速提升。这就是为什么Deep Research Agent在pass@8时能达到89.5%——它不是"推理能力"更强,而是"试错空间"更大。
三、Interactions API:被忽视的技术突破
3.1 状态管理:Agent系统的核心难题
传统API的问题是无状态:
# 传统方式
response1 = model.generate("搜索量子计算最新论文")
response2 = model.generate("总结这些论文的核心观点")
# 问题:response2不知道response1搜到了什么Interactions API引入了可序列化的对话状态:
interaction = client.interactions.create(
model="gemini-3-pro-preview",
input="Research quantum computing trends",
tools=[{"type": "google_search"}]
)
# 状态可持久化
state = interaction.get_state()
# 可以暂停、恢复、分叉
interaction.resume(state, new_input="Focus on error correction")这解决了一个长期困扰Agent开发的问题:如何在保持上下文的同时控制成本?
3.2 工具调用的状态空间管理
更深层的技术创新在于解耦了"推理状态"和"工具状态":
# 传统方式:推理和工具耦合
context = [system_prompt, user_query, search_results, previous_response]
next_action = model.decide(context) # 所有信息混在一起
# Interactions API:分层状态管理
interaction.reasoning_state # 模型的推理上下文
interaction.tool_state # 各个工具的执行历史
interaction.user_state # 用户提供的背景信息
# 这样可以做selective attention
next_action = model.decide(
reasoning_context=interaction.reasoning_state[-3:], # 只看最近3步
tool_summary=interaction.tool_state.summarize(), # 工具状态摘要
user_context=interaction.user_state # 完整用户背景
)这种架构的好处是:
- 降低每次推理的token消耗(不需要重复传递历史信息)
- 支持异步和并行执行(工具调用可以独立于推理)
- 便于调试和回滚(状态可追溯)
3.3 与LangChain/AutoGPT的本质区别
很多人会问:这不就是LangChain吗?
关键区别在于集成深度:
| 维度 | LangChain | Interactions API |
|---|---|---|
| 状态管理 | 应用层(Python对象) | 模型层(原生支持) |
| 工具调用 | 通过prompt engineering | 通过structured API |
| 错误处理 | 需要手动编排 | 内置retry和fallback |
| 成本优化 | 依赖开发者 | 系统级优化(缓存、增量更新) |
本质上,LangChain是"用prompt模拟Agent",而Interactions API是"从模型架构层面支持Agent"。
四、成本的数学:为什么便宜90%?
4.1 Token经济学分解
假设一个典型的研究任务:
OpenAI GPT-5 Pro方式:
输入:用户问题(200 tokens)
推理:内部CoT(50,000 tokens,扩展上下文)
输出:完整报告(3,000 tokens)
总计:53,200 tokens
成本 = 53,200 × $0.03/1k ≈ $1.60Gemini Deep Research Agent方式:
任务分解:200 tokens × 1次 = 200 tokens
搜索查询:50 tokens × 5次 = 250 tokens(搜索本身不计费)
信息过滤:1,000 tokens × 5次 = 5,000 tokens(轻量级模型)
最终综合:3,000 tokens × 1次 = 3,000 tokens(完整模型)
总计:8,450 tokens
成本 = 8,450 × $0.002/1k ≈ $0.017成本差异 ≈ 94倍
4.2 更深层的差异:Compute Allocation Strategy
这不仅是token数量的差异,更是计算资源分配策略的差异:
OpenAI:把所有计算压在单一推理过程
- 优势:结果一致性好,适合需要强逻辑推理的任务
- 劣势:无法利用外部知识库,成本随任务复杂度指数增长
谷歌:把计算分散到多个轻量级步骤
- 优势:可以利用搜索引擎、数据库等外部资源,成本线性增长
- 劣势:需要精心设计pipeline,对任务分解能力要求高
用公式表达:
OpenAI: C_total = C_inference(f(task_complexity))
其中 f 可能是指数函数
谷歌: C_total = Σ C_step_i
其中每个 C_step_i 相对固定五、架构演进:从Transformer到Agent-Oriented Architecture
5.1 Transformer的局限性
Transformer的核心创新是自注意力机制,但它有个根本性问题:
所有信息必须被编码到模型参数或上下文中。
这导致:
- 模型规模必须足够大才能"记住"足够多的知识
- 上下文窗口必须足够长才能处理复杂任务
- 推理成本与序列长度呈平方关系(O(n²))
5.2 Agent-Oriented Architecture的范式转变
Deep Research Agent代表的新范式是:
把模型当作"控制器"而非"知识库"。
传统架构:
Input → [Huge Model with all knowledge] → Output
Agent架构:
Input → [Lightweight Controller] → [Tool1, Tool2, ..., ToolN] → [Synthesizer] → Output这类似于计算机体系结构中的冯诺依曼架构 vs 哈佛架构:
- 冯诺依曼:指令和数据在同一存储空间(类比Transformer)
- 哈佛:指令和数据分离存储(类比Agent系统)
5.3 技术实现细节:Multi-Agent Orchestration
虽然谷歌没有公开完整实现,但从API设计可以推测其内部架构:
class DeepResearchAgent:
def __init__(self):
self.planner = LightweightLM(model="gemini-1.5-flash") # 任务规划
self.searcher = SearchTool() # 信息检索
self.evaluator = MediumLM(model="gemini-2.0-flash") # 信息质量评估
self.synthesizer = HeavyLM(model="gemini-3-pro") # 最终综合
def research(self, question):
# 阶段1:生成研究计划(低成本)
plan = self.planner.generate_plan(question)
# 阶段2:并行执行搜索(外包给搜索引擎)
search_results = []
for query in plan.queries:
results = self.searcher.search(query, max_results=10)
filtered = self.evaluator.filter_relevant(results, query)
search_results.append(filtered)
# 阶段3:迭代式精化(中等成本)
for iteration in range(3):
gaps = self.evaluator.identify_gaps(search_results, question)
if not gaps:
break
additional_results = self.searcher.search(gaps)
search_results.extend(additional_results)
# 阶段4:最终综合(高成本,但只用一次)
report = self.synthesizer.generate_report(
question=question,
sources=search_results,
format_spec=plan.format
)
return report关键优化:
- 计算分层:轻量级模型处理高频低价值任务,重量级模型只在关键节点使用
- 并行化:搜索可以并行执行,不受模型推理速度限制
- 增量式:只在发现信息缺口时才追加搜索,避免过度检索
六、对AI发展方向的启示
6.1 模型规模不是唯一答案
过去几年的AI发展有个明显趋势:模型越大越好。
但Deep Research Agent的成功说明:架构创新可以替代规模扩张。
这类似于芯片行业的发展:
- 早期:提升单核频率(对应增大模型参数)
- 现代:多核并行 + 异构计算(对应Agent系统)
6.2 "智能"需要被重新定义
传统对AI智能的定义是:在单次推理中正确解决问题的能力。
但现实世界的智能更多体现为:在资源约束下高效解决问题的能力。
从这个角度看:
- GPT-5.2 Thinking是"学霸式智能"(单打独斗,追求完美)
- Deep Research Agent是"项目经理式智能"(善用工具,追求效率)
6.3 开源的战略价值
谷歌选择开源Deep Research Agent,表面上是在"让利",实际上是在建立技术标准。
类比历史案例:
- 微软闭源Windows,赢得了桌面市场,但失去了服务器市场(Linux)
- 谷歌开源Android,虽然自己不赚钱,但控制了移动生态
当开发者习惯了"Agent + Gemini"的开发范式后,迁移成本会成为谷歌的护城河。
七、结语:技术战争的下一幕
OpenAI和谷歌的竞争,表面上是GPT vs Gemini,深层是两种技术哲学的碰撞:
- OpenAI:相信足够强大的模型可以解决一切问题(AGI理想主义)
- 谷歌:相信模型+工具的组合才是最优解(工程实用主义)
从技术演进的角度看,这两条路线都有其合理性:
- 短期:OpenAI的纯推理方案在benchmark上会继续领先
- 中期:谷歌的混合架构会在企业应用中占据优势
- 长期:两者可能会融合,形成"强推理能力 + 高效工具调用"的统一架构
但有一点是确定的:AI的竞争已经从"谁更聪明"转向"谁更会用工具"。
这不是智力的退化,而是智慧的进化。
技术问题:
如果让你设计一个Agent系统,你会选择:
- 用一个超大模型做端到端推理?
- 用多个小模型 + 工具调用的pipeline?
- 两者的混合?
理由是什么?成本和效果如何权衡?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)