2026年大模型三大核心技术对比:RAG、In-Context Learning与微调如何选?从0到1彻底讲清
文章详细对比了RAG(检索增强生成)、In-Context Learning(上下文学习)和Fine-tuning(微调)三种大模型技术的本质区别和适用场景。通过生动比喻和实际案例分析,阐述了各技术的优缺点、成本构成和决策逻辑,强调先判断是能力问题还是知识问题,再根据具体场景选择最适合的技术方案。文章还提供了组合使用策略和未来趋势预判,帮助开发者避免技术选型陷阱,节省时间和资源。
简介
文章详细对比了RAG(检索增强生成)、In-Context Learning(上下文学习)和Fine-tuning(微调)三种大模型技术的本质区别和适用场景。通过生动比喻和实际案例分析,阐述了各技术的优缺点、成本构成和决策逻辑,强调先判断是能力问题还是知识问题,再根据具体场景选择最适合的技术方案。文章还提供了组合使用策略和未来趋势预判,帮助开发者避免技术选型陷阱,节省时间和资源。
引言:一次错误的技术选型,可能浪费整个项目
在AI项目开发中,技术选型至关重要。选错方向,不仅浪费时间和资源,还可能导致项目失败。
当面对一个实际业务需求时,你是否也曾困惑:
- 该用RAG检索外部知识?
- 还是通过In-Context Learning提供示例?
- 或者直接Fine-tuning微调模型?
今天,我们用最通俗的语言和生动的比喻,彻底讲清楚这三种技术的本质区别,以及如何在项目中做出正确选择。
🔍 方法一:RAG(检索增强生成)
什么是RAG?
RAG的完整流程分为三步:
- 接收用户问题
- 从外部知识库检索相关知识
- 将知识放入Prompt,调用大模型生成回答
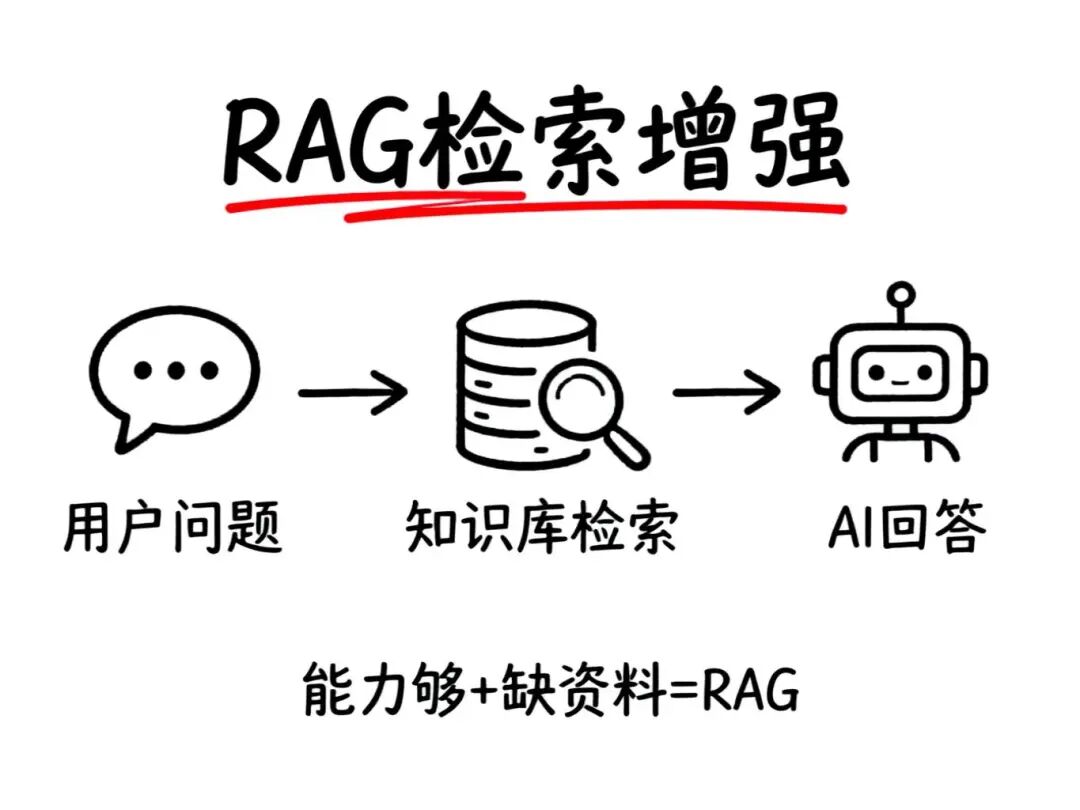
RAG的核心本质
大模型本身能力是够的,只是缺少相关背景知识。
只要把参考资料(知识库)提供给模型,它就能帮我们解决问题。
一个生动的比喻
想象这样一个场景:
张三是大模型领域的专家,帮过很多企业做销售智能化,对销售领域很熟悉。
现在有家新企业找他做智能质检项目。但张三之前没做过质检:
- 不清楚什么是质检
- 不了解质检流程
- 不知道质检的痛点
**解决方案:**企业把质检相关的背景资料、业务流程、痛点文档给张三,他凭借自己的AI能力,就能把项目做出来!
这就是RAG的本质——能力OK,但缺背景资料。
RAG的适用场景
RAG特别适合处理动态更新的外部知识:
✅ 企业业务数据 - 每天都在变化的订单、客户、产品信息
✅ 实时新闻资讯 - 更新频率高,不可能把所有新闻都训练进模型
✅ 专业领域知识库 - 法律条文、医疗文献、技术文档等
✅ 个人/组织的私有数据 - 聊天记录、工作文档、会议纪要
关键特征
- 知识存储在外部数据库
- 知识可以随时更新,无需重新训练模型
- 模型本身不需要改动
⚠️ RAG的三大陷阱
在实际项目中,RAG看似简单,但有三个常见陷阱需要警惕:
陷阱1:检索质量差导致答案错误
Garbage in, Garbage out! 如果检索系统返回的知识不准确或不相关,大模型再强也无济于事。
**真实案例:**某公司的RAG系统因为向量模型选择不当,经常检索到无关内容,导致回答质量极差。后来更换为领域定制的embedding模型,准确率从60%提升到92%。
陷阱2:知识库更新不及时
很多团队上线RAG后,忽略了知识库的持续维护。过时的信息比没有信息更危险!
陷阱3:检索成本被低估
每次查询都要经过:向量化 → 相似度计算 → Top-K检索 → 重排序,这些步骤都有成本。高并发场景下,检索成本可能占总成本的30%-40%。
💡 方法二:In-Context Learning(上下文学习)
什么是In-Context Learning?
通过在Prompt中提供示例,来激发大模型在某个方面的能力。
一个工作中的例子
同事小李不太会写某段代码。
最好的教学方式是什么?给他一个例子!
“你看这段代码,这样写就行,你照着这个思路改改自己的代码。”
很多时候,小李看完例子就知道怎么做了。
这就是In-Context Learning——通过例子激发能力。
工作原理
模型在某方面能力不足时,我们通过示例来"提示"它:
Prompt示例:
【任务】判断文章质量
【示例1】
文章:"今天天气真好..."
评价:差(内容空洞,缺乏深度)
【示例2】
文章:"AI技术的发展经历了三次浪潮..."
评价:好(逻辑清晰,内容丰富)
【现在请你评价】
文章:"大模型是..."
In-Context Learning的特点
优点:
- ✅ 无需训练模型
- ✅ 快速实验和调整
- ✅ 灵活性强
缺点:
- ❌ Prompt会变得很长
- ❌ 推理效率降低
- ❌ 有时提供再多例子也激发不了能力
📉 真实案例:为什么我们放弃了ICL
某互联网公司的客服智能化项目经历:
**第一阶段:**使用In-Context Learning做情绪分类(积极/消极/中性)
- 提供5个精心挑选的示例
- 初期测试效果不错,准确率85%
遇到的问题:
- 客服场景差异巨大(售前咨询、售后投诉、技术支持…)
- 5个例子覆盖不全,准确率降到70%
- 增加到20+个例子,准确率才勉强到达90%
成本失控:
- Prompt长度达到3200+ tokens
- 每次调用成本是之前的6倍
- 月度API费用从$5000暴增到$30000
**最终方案:**转向Fine-tuning
- 标注1000条数据进行微调
- Prompt恢复到正常长度(~200 tokens)
- 成本降低70%,准确率提升到94%
**教训:**ICL适合快速验证,但到了规模化阶段,Fine-tuning往往更经济。
🎯 方法三:Fine-tuning(微调)
什么是Fine-tuning?
对大模型进行训练改动,得到一个新的模型,将能力嵌入模型内部。
核心观点
数据代表能力。
想增强哪方面的能力,就收集对应的数据进行训练。
Fine-tuning的特点
- 需要对模型进行改动
- 能力永久嵌入模型内部
- 推理时不需要额外的Prompt
- 效率更高
与In-Context Learning的关系
Fine-tuning和In-Context Learning的目标相同:激发或增强大模型某方面的能力。
区别在于:
- In-Context Learning:能力"游离"在模型外部(通过Prompt提供)
- Fine-tuning:能力"嵌入"在模型内部(通过训练固化)
💸 Fine-tuning的隐藏成本
很多团队在评估Fine-tuning时,只看到了GPU训练费用,却忽略了更大的隐藏成本:
1. 数据标注成本(最容易被低估!)
- 高质量标注:每条$0.5-$2(取决于任务复杂度)
- 需要1000-10000条数据,成本$500-$20000
- 标注质量直接决定模型效果,不能省
2. 训练时间成本
- 首次训练:几小时到几天
- 迭代优化:每次调整都要重新训练
- 工程师时间成本:可能比GPU成本更贵
3. 模型维护和更新成本
- 业务变化时需要重新收集数据、重新训练
- 不像RAG那样"改知识库就行"
- 需要建立完整的训练pipeline
4. 版本管理的复杂度
- 需要管理多个模型版本
- A/B测试、回滚策略
- 部署和监控的基础设施成本
**真实数据:**某金融公司Fine-tuning一个客服模型,总成本构成:
- 数据标注:$15,000(60%)
- GPU训练:$3,000(12%)
- 工程开发:$5,000(20%)
- 基础设施:$2,000(8%)
💰 成本对比:哪个最省钱?
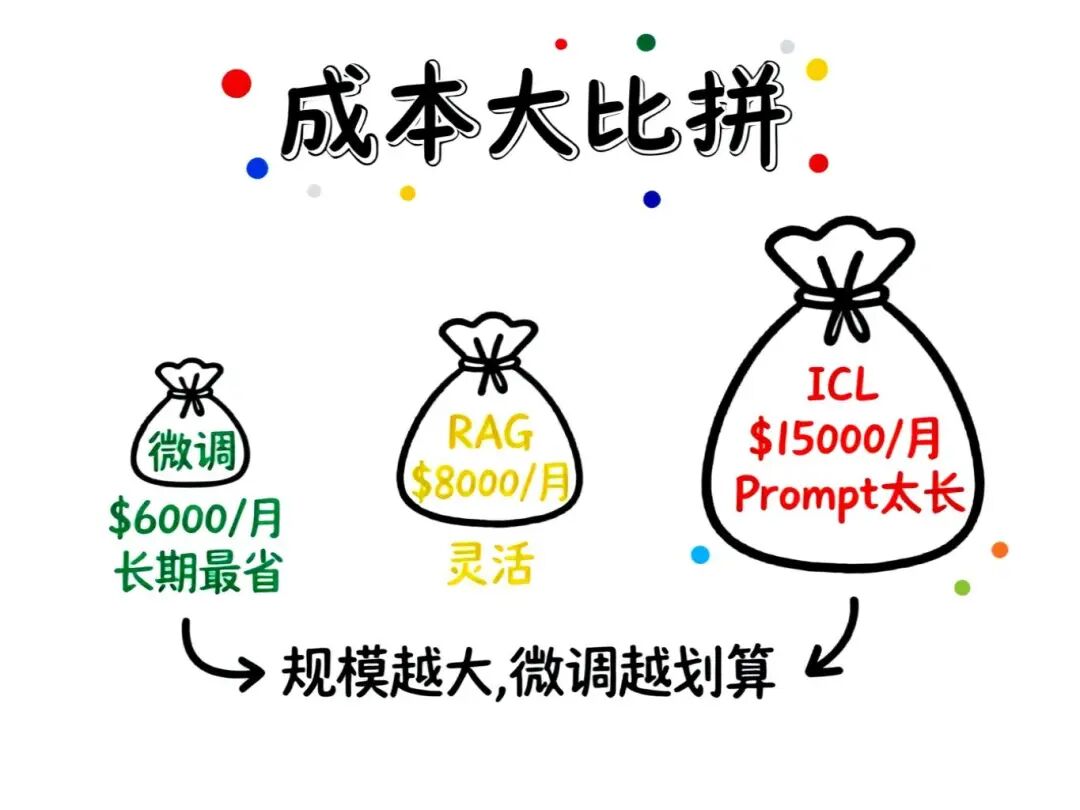
在实际项目中,成本往往是决策的关键因素。下面是三种方法的TCO(总拥有成本)对比:
| 成本维度 | RAG | In-Context Learning | Fine-tuning |
|---|---|---|---|
| 初始成本 | 中(构建知识库) | 低(编写示例) | 高(数据标注+训练) |
| 运行成本 | 中(检索+推理) | 高(长Prompt推理) | 低(纯推理) |
| 维护成本 | 低(更新知识库) | 低(调整示例) | 高(重新训练) |
| 灵活性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
| 扩展性 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
典型场景的成本对比(月度,1000万次调用):
- **RAG:**检索成本$3000 + 推理成本$5000 = $8000
- **ICL:**推理成本(长Prompt)$15000 = $15000
- **Fine-tuning:**推理成本$4000 + 分摊训练成本$2000 = $6000
结论:
- 长期、大规模使用:Fine-tuning最省钱
- 灵活性要求高、知识变化快:RAG最合适
- 快速验证、小规模应用:ICL最灵活
🆚 三种方法的本质区别
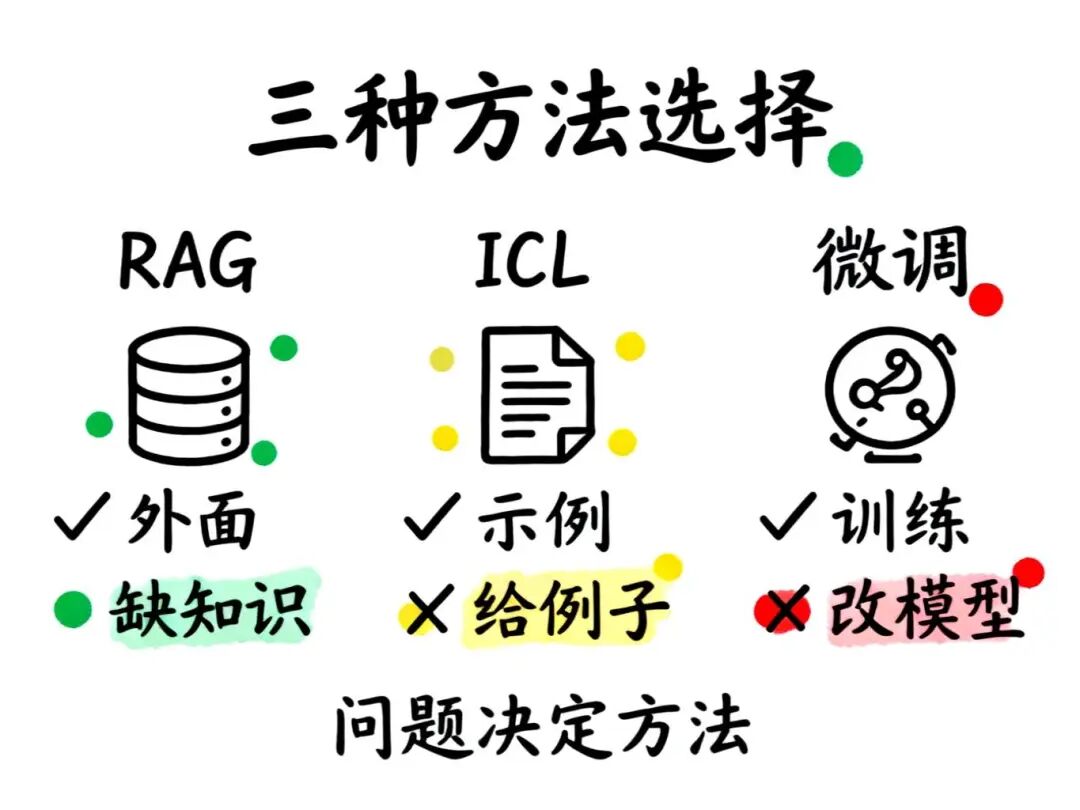
第一层对比:RAG vs (In-Context Learning + Fine-tuning)
RAG关注的问题:
模型能力够,但缺参考资料,暂时没法解决问题
In-Context Learning & Fine-tuning关注的问题:
模型能力不够,需要激发或增强能力才能解决问题
用人来做比喻
假设有两个人要接同一个AI客服项目:
第一个人:
- 🎓 大学AI专业毕业
- 💪 AI基本功扎实
- ✅ 做过很多AI项目
缺什么? 缺对"客服业务"的理解(业务背景、流程、痛点)
解决方案? 给他提供项目背景资料,他就能做出来 → 对应RAG
第二个人:
- 📚 文科专业毕业
- 📖 没接触过AI知识
- ❌ 没做过AI项目
缺什么? 缺AI能力本身
解决方案? 即使给他背景资料,也做不出来。必须先补AI能力 → 对应In-Context Learning或Fine-tuning
🔄 In-Context Learning vs Fine-tuning:如何选择?
既然两者都是为了提升能力,什么时候用哪个?

场景一:领悟能力强 → In-Context Learning
**问自己:**提供几个示例,模型能学会吗?
- 能快速学会 → 选择In-Context Learning
- 学不会,需要大量训练 → 选择Fine-tuning
步骤3:考虑效率因素
**问自己:**In-Context Learning的Prompt会不会太长影响效率?
- Prompt太长,效率低 → 转为Fine-tuning
- 效率可接受 → 继续使用In-Context Learning
🔥 高级玩法:组合使用策略
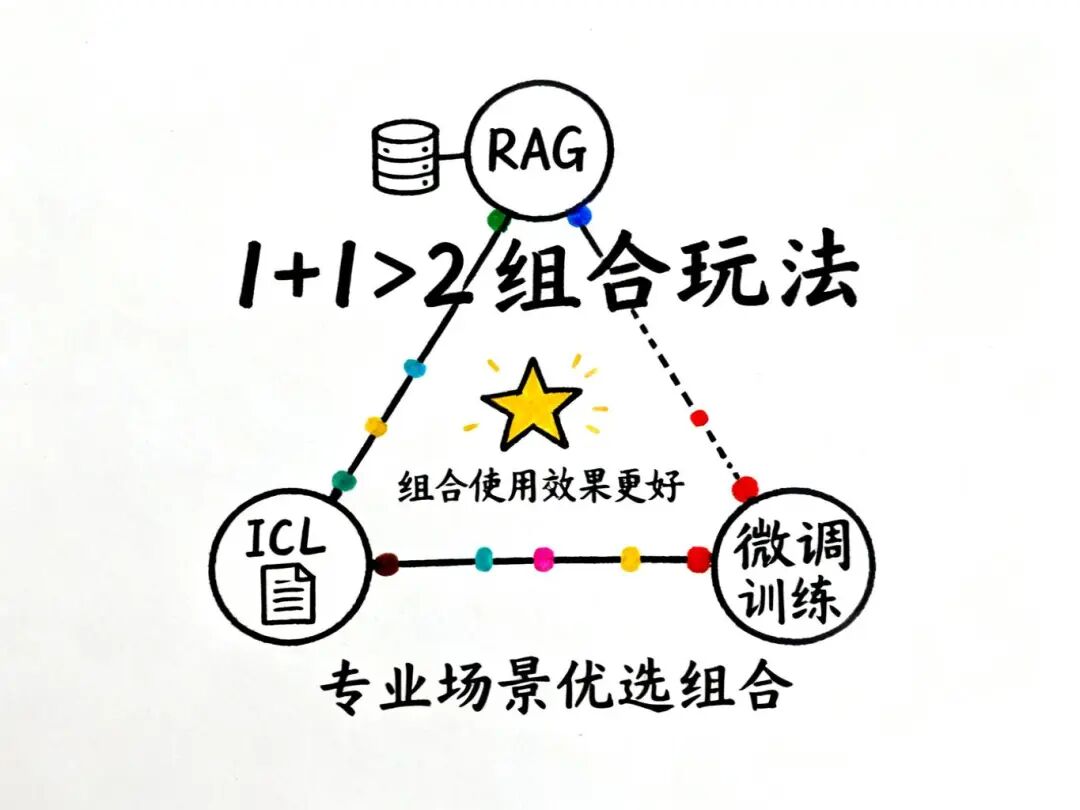
实际项目中,三种技术并非互斥,巧妙组合往往能发挥出1+1>2的效果!
策略1:RAG + Fine-tuning
**场景:**专业领域问答系统(如法律、医疗)
做法:
- Fine-tuning增强模型对领域术语的理解能力
- RAG检索具体案例和最新法规
- 模型结合自身领域知识和检索内容生成回答
**效果:**某法律咨询平台采用此方案,准确率从79%提升到93%,比单用RAG高8个百分点。
策略2:RAG + In-Context Learning
**场景:**多风格内容生成(营销文案、技术文档等)
做法:
- RAG检索相似的高质量内容作为参考
- 在Prompt中作为示例展示给模型
- 动态调整示例库,形成"自进化"系统
**优势:**无需Fine-tuning,快速适应新风格。
策略3:三者结合的最佳实践
某电商平台的智能客服架构:
用户问题
↓
[意图识别] ← Fine-tuned小模型(速度快)
↓
[知识检索] ← RAG(业务数据)
↓
[回答生成] ← Base模型 + ICL(少量示例调整风格)
成果:
- 响应速度:平均600ms
- 准确率:96%
- 月成本:$12000(纯RAG方案需$20000)
**核心思想:**对的任务用对的技术,分层架构,各司其职。
🔮 2025年的趋势预判
技术边界正在模糊,新的范式正在形成:
趋势1:RAG向Agent方向演进
传统RAG是"检索→生成",新一代是"规划→检索→推理→行动"。
**实例:**某研究助手系统能够:
- 分解复杂问题
- 多轮检索不同知识源
- 自我纠错和验证
- 整合跨领域信息
这已经不是简单的检索,而是智能体的认知过程。
趋势2:ICL的token效率优化
Long Prompt的成本问题催生了新技术:
- **示例压缩:**将20个示例压缩到5个的token量
- **动态示例选择:**根据query智能选择最相关的3-5个示例
- **提示词蒸馏:**将大量示例知识蒸馏进小模型
**数据:**某压缩技术可将ICL的token成本降低60%,同时保持95%的效果。
趋势3:Fine-tuning的低成本革命
- **参数高效微调(PEFT)😗*只训练1%的参数,成本降低90%
- **合成数据生成:**用大模型生成训练数据,标注成本降低80%
- **持续学习:**模型可以增量更新,不需要每次从头训练
LoRA、QLoRA等技术让个人开发者也能负担Fine-tuning成本。
趋势4:检索增强微调(RAFT)
新范式正在打破RAG和Fine-tuning的边界:
- 在微调时就注入"如何使用检索信息"的能力
- 模型学会判断检索内容的可信度
- 自动过滤干扰信息,提取关键知识
某医疗问答系统采用RAFT,在噪声知识干扰下,准确率比传统RAG高12个百分点。
**核心洞察:**未来不是选A还是选B,而是如何让ABC深度融合,形成更强大的系统。
🎓 总结:理解本质,才能做对选择
三种技术的核心差异:
| 技术 | 解决什么问题 | 知识/能力在哪 | 是否改动模型 |
|---|---|---|---|
| RAG | 缺背景知识 | 外部知识库 | ❌ 否 |
| In-Context Learning | 能力不足 | Prompt中的示例 | ❌ 否 |
| Fine-tuning | 能力不足 | 模型内部 | ✅ 是 |
记住这个决策核心:
- 先判断是能力问题还是知识问题
- 如果是能力问题,判断示例能否激发
- 考虑效率和成本因素
只有深入理解这三种技术的本质,才能在实际项目中选择最适合的方案,避免走弯路,节省宝贵的时间和资源!
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献187条内容
已为社区贡献187条内容

所有评论(0)