SignRoundV2 深度解析:大模型极低比特量化的 “精度救星”,2 比特也能稳跑生产级任务
作为一名常年和大模型部署打交道的开发者,我深知 “模型大如天,部署难如登天” 的痛点 ——GPT-3、LLaMA 70B 这类模型动辄几十上百 GB,别说边缘设备,就算是消费级 GPU 也难以承载。而量化作为模型压缩的核心手段,在 “极低比特”(2-4 比特)场景下又容易出现精度 “断崖式下跌”,比如 MXFP4 量化后性能直接腰斩。
今天来解析 Intel 团队的 SignRoundV2 论文:它不用重新训练模型(后训练量化 PTQ),就能在 2 比特时保持强性能,4-5 比特接近全精度,还比传统方法快几十倍。今天就带大家精读这篇论文,把晦涩的技术点拆明白,看看它到底是怎么做到的~
一、先搞懂背景:为什么我们需要 SignRoundV2?
在聊技术前,先理清几个核心概念,避免后续看不懂~
1. 核心痛点:大模型部署的 “两难困境”
- 模型太大:LLaMA 70B 全精度(FP16)约 140GB,消费级显卡,如3090(24GB)根本装不下;
- 量化精度矛盾:比特数越低,模型越小(2 比特仅为 FP16 的 1/8),但精度掉得越狠(传统方法 2 比特精度仅 30%-40%,完全没法用)。
2. 量化领域的 “三大门派”
(1)后训练量化(PTQ):
- 定义:模型训练好后再压缩,不用重新训练,速度快、成本低(适合已有预训练模型的场景);
- 缺点:极低比特(≤4 比特)时精度损失严重,层敏感度难平衡(有的层禁不起压缩,有的层可以多压)。
(2)量化感知训练(QAT):PTQ 的 “强敌”
- 定义:训练时就加入量化模块,精度高,但需要重新训练(成本极高)、数据量要求大,还可能出现 “灾难性遗忘”(忘了原来的知识);
- 对比:QAT 像 “重新装修房子”,PTQ 像 “给房子做收纳压缩”,SignRoundV2 就是 “收纳界的顶级高手”,不用拆墙也能压得整齐。
(3)混合精度量化:聪明的 “资源分配”
- 定义:不给所有层用一样的比特数,敏感层(比如 down_proj 层)用高比特(4-8 比特),不敏感层用低比特(2 比特),兼顾压缩率和精度。
3. 现有 PTQ 的 “坑”:SignRoundV2 要解决的问题
- 敏感度指标不准:传统方法用 Hessian 矩阵(计算复杂,大模型扛不住)或输出失真(精度差),导致比特分配不合理;
- 量化参数初始化差:SignRoundV1 用固定值初始化,2 比特时训练不稳定,精度上不去;
- 成本高:部分方法需要大量校准样本或计算资源,不适合落地。
二、SignRoundV2 核心创新:两大 “法宝” 搞定极低比特量化
SignRoundV2 的本质的是 “更聪明的比特分配 + 更稳定的量化初始化”,核心就是两个创新点,咱们逐个拆透~
法宝 1:DeltaLoss 敏感度指标 —— 精准判断 “哪层不能压”
1. 核心思想:量化后性能下降多少,就有多敏感
敏感度指标的作用,相当于给模型每层做 “抗压测试”:量化后性能下降越多,说明这层越敏感,需要多分配比特。
传统方法要么算得慢(Hessian 矩阵),要么算得不准(仅看输出失真),而 DeltaLoss 的优势是 “又快又准”—— 用一阶泰勒展开直接估算量化导致的损失变化,不用复杂计算。
2. 公式拆解:
DeltaLoss 的核心公式:
咱们逐个拆解:
:量化后模型的 “性能下降幅度”(损失增加量),越大越敏感;
:损失对 “量化后激活值” 的梯度 —— 梯度越大,说明激活值稍微变一点,模型性能就掉很多(比如 “考试分数对选择题正确率的敏感度”,正确率降 10%,分数掉 20 分,梯度就大);
:全精度激活值和量化后激活值的 “差值”—— 差值越大,说明量化对激活值的破坏越严重;
- ∘:Hadamard 积(对应元素相乘)—— 不用管复杂定义,简单说就是 “梯度 × 差值”,得到 “激活值变化导致的性能下降”;
- ∣⋅∣:绝对值 —— 不管下降还是上升(实际都是下降),只看幅度。
3. 为什么 DeltaLoss 比传统方法好?
- 兼顾 “局部破坏” 和 “全局影响”:
是全局(这个变化对最终性能的影响),比只看局部的方法准;
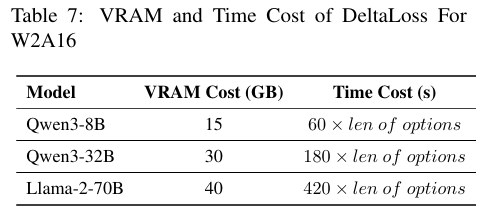
- 计算快:一阶泰勒展开比 Hessian 矩阵(二阶)简单,70B 模型算 DeltaLoss 仅需 40GB VRAM、7 分钟;
- 省资源:仅需 16 个校准样本(序列长度 256),不用大量数据。
法宝 2:量化参数预调优 —— 给量化 “一个好的起点”
1. 核心问题:SignRoundV1 的 “初始化坑”
SignRoundV1 对量化参数(比如尺度 s)用固定值初始化(s=1.0),就像跑步比赛从泥潭里起步,再怎么跑也难追上 ——2 比特时训练不稳定,精度上不去。
SignRoundV2 的思路:先找一个 “最优起点”,再开始量化调优,就像从平地上起跑,又快又稳。
2. 公式拆解:怎么找 “最优起点”?
首先是尺度 s 的候选集合生成:
:权重的最大绝对值(比如权重范围是 [-5,5],就是 5);
:对称量化的 “最大量化等级”(比如 2 比特,22−1=2,量化等级是 - 2,-1,1,2);
:微调参数,从 [-0.9, 0.9] 以 0.01 步长采样(共 180 个候选值)—— 相当于给 “量化等级” 做微调,找到最适合当前层的尺度;
然后用可学习参数 α 进一步优化:
:从候选集合中选的 “最优初始尺度”;
- α:可学习参数,限制在 [0.5,1.5],避免尺度偏差太大。
3. 效果:初始化后精度直接涨
实验显示,启用初始化后,Qwen3-8B 的 ARC-Challenge 任务精度从 34.90% 涨到 43.69%,Llama3.1-8B 的 LAMBADA 任务从 52.57% 涨到 60.41%—— 相当于 “起跑姿势对了,直接领先一大截”。
其他关键优化:让量化更稳、更快
1. 分层比特分配:用动态规划做 “最优预算分配”
把比特数当成 “预算”,用动态规划给每层分配比特:
- 目标:在平均比特预算(比如 2.5 比特)下,让所有层的总损失最小;
- 方法:给 DeltaLoss 高的层多分配比特(比如 4 比特),低的层少分配(比如 2 比特),比 “头部 / 尾部层固定 8 比特” 的 heuristic 方法准得多。
2. 损失计算技巧:排除 “异常值”
量化时会有个别样本的损失特别大(比如异常输入),SignRoundV2 会排除前 0.1% 的最大损失,避免训练被带偏 —— 就像考试算平均分,去掉最高分和最低分,结果更客观。
三、实验结果:用数据说话,SignRoundV2 到底有多强?
实验用了 LLaMA 2/3、Qwen 2.5/3 系列模型,覆盖 2-8 比特场景,重点看三个维度:精度、速度、成本。
1. 精度:2 比特也能打,4-5 比特接近全精度
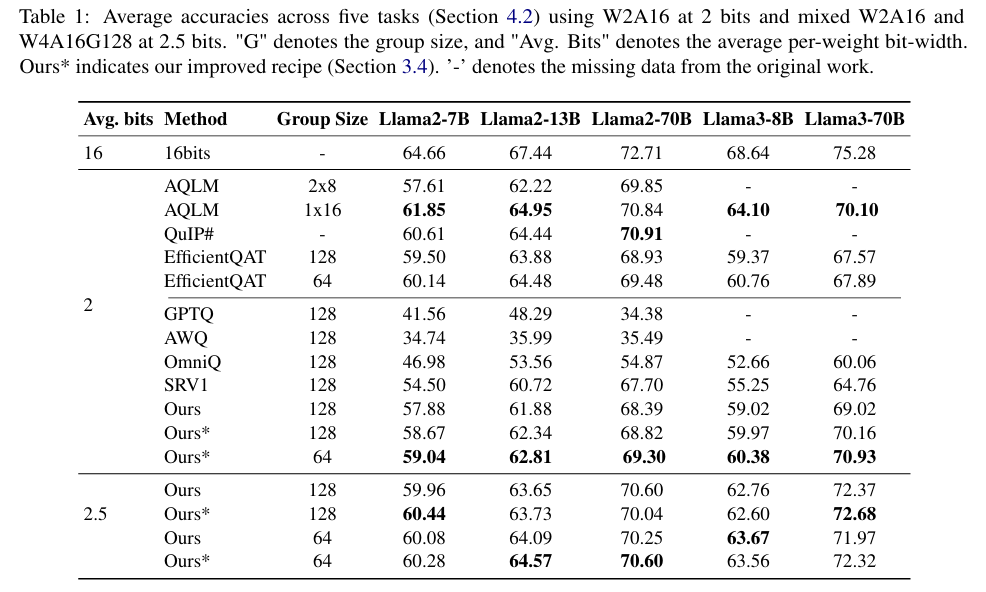
(1)W2A16 极低比特场景(2-2.5 比特)
表 1展示了 5 个核心任务的平均准确率,以 Llama2-70B 为例:
- 纯 2 比特场景:SignRoundV2(Ours*)平均精度达 69.30%,而 GPTQ 仅 34.38%、AWQ 仅 35.49%,差了一倍还多;
- 2.5 比特混合精度场景:Llama3-70B 的 Ours * 方案平均精度 72.32%,和全精度(75.28%)差距仅 3%;
- 对比高成本 QAT 方法(如 EfficientQAT):SignRoundV2 在大模型上精度相当(69.30% vs 69.48%),但成本仅为后者的 1/100。
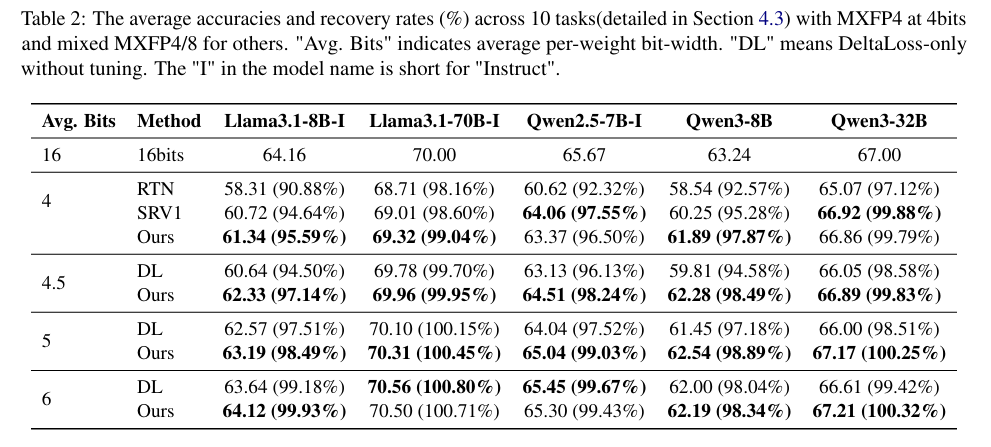
(2)MXFP4/8 混合精度场景(4-6 比特)
表 2呈现了 10 个任务的平均准确率和精度恢复率:
- 4 比特场景:Llama3.1-70B-Instruct 的 Ours 方案精度恢复率达 99.04%(69.32% vs 全精度 70.00%),较 SignRoundV1 提升约 1-3%;
- 5-6 比特场景:多数模型精度恢复率超 99%,Qwen3-32B 的 Ours 方案精度达 67.21%,几乎追平全精度(67.00%);
- DeltaLoss 仅方案(无调优)也表现亮眼:如 Llama3.1-8B-Instruct 在 5 比特时,DL 方案精度 62.57%,显著高于头部 8 比特(60.82%)、尾部 8 比特(60.12%)的 heuristic 方法(表 3)。
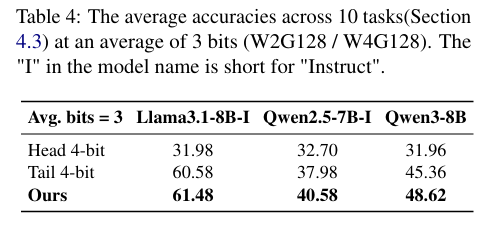
(3)低精度极限场景(平均 3 比特)
表 4显示,当平均比特仅为 3 时:
- 头部 / 尾部层固定 4 比特的 heuristic 方法精度断崖式下跌(Llama3.1-8B-Instruct 仅 31.98%);
- 而 SignRoundV2 的 Ours 方案仍保持 61.48% 的高准确率,差距超 29 个百分点,证明其在极低比特下的鲁棒性。
2. 速度:量化成本比 QAT 低两个数量级
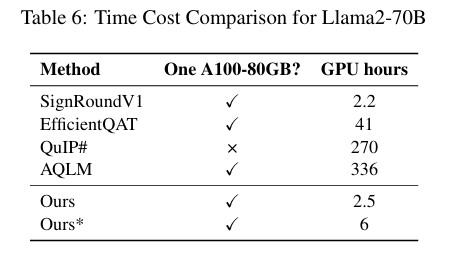
表 6直接对比了 Llama2-70B 的量化时间成本:
- SignRoundV2 仅需 2.5 小时,增强版 Ours * 也仅 6 小时;
- 而 QAT 方法(EfficientQAT)需 270 小时,向量量化方法(QuIP#)需 336 小时,差了 100 多倍;
- 补充:表 7显示,计算 DeltaLoss 的成本极低 ——70B 模型仅需 40GB VRAM、7 分钟(420 秒),完全不会成为性能瓶颈。
3. 对比优势:SignRoundV2 vs 其他方法
| 方法类型 | 代表方法 | 优势 | 劣势 | SignRoundV2 的改进 |
|---|---|---|---|---|
| QAT | EfficientQAT | 精度高 | 成本极高、易遗忘 | 精度相当,成本仅 1/100 |
| 传统 PTQ | GPTQ/AWQ | 速度快 | 极低比特精度差 | 速度相当,2 比特精度翻倍 |
| 混合精度 PTQ | llama.cpp | 简单 | 依赖 heuristic,精度一般 | 用 DeltaLoss,精度提升 5%-10% |
四、技术扩展:
1. Hadamard 积到底是什么?
简单说就是 “两个矩阵对应位置的元素相乘”,比如: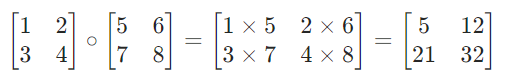
不用做复杂的矩阵乘法,计算速度快,适合大模型场景。
2. 动态规划在量化中的作用
动态规划的核心是 “把大问题拆成小问题,找最优解”。在这里:
- 大问题:给 n 层分配比特,总预算 T,让总损失最小;
- 小问题:第 i 层用 b 比特时的损失是多少,累计预算是多少;
- 结果:自动找到 “哪层用高比特、哪层用低比特” 的最优组合,比人工规则靠谱得多。
3. 对称量化 vs 非对称量化
- 对称量化:以 0 为中心,比如 2 比特量化等级是 [-2,-1,1,2],公式里的
就是对称量化的尺度;
- 非对称量化:不以 0 为中心,有零点(zero point),适合激活值分布不均的场景;
- SignRoundV2 用对称量化,原因是计算简单、硬件友好(大部分 GPU/CPU 支持对称量化加速)。
4. Heuristic 方法(启发式方法)
- 定义:基于经验、直觉或简单规则设计的方法,不依赖复杂数学建模或优化,核心是 “凭经验做事”;
- 论文中的应用:llama.cpp 采用的量化参数配置(手动给不同模型 / 量化方案设置混合精度)、“头部层(靠近 LM 头)或尾部层(靠近嵌入层)固定 8 比特” 的比特分配策略;
- 局限性:论文图 2 显示不同数据类型、不同层的敏感度差异极大,heuristic 方法无法精准适配所有场景(比如 down_proj 层敏感度高但未被特殊对待),导致精度损失;而 SignRoundV2 的 DeltaLoss 能动态捕捉层敏感度,比 heuristic 更灵活、精准。
5. Hessian 矩阵(二阶)
- 定义:多元函数的二阶偏导数矩阵,用来描述函数的曲率变化 —— 在量化中,它通过计算损失函数对模型参数的二阶偏导数,反映 “参数微小变化对损失的影响程度”,进而估计层敏感度;
- 论文中的对比:传统方法(如 HAWQ)用 Hessian 矩阵估计敏感度,假设梯度接近零,但极低比特量化时梯度变化大,该假设失效;且 Hessian 矩阵计算复杂度高(二阶偏导数运算),对 70B 等大模型来说,显存和时间成本极高(远超 DeltaLoss 的一阶计算);
- 优势与劣势:能捕捉参数变化的非线性影响,但计算成本 prohibitive,不适合高效 PTQ;而 SignRoundV2 的 DeltaLoss 用一阶泰勒展开,兼顾精度和效率,更适配大模型极低比特量化场景。
五、思考与展望:SignRoundV2 的价值与未来优化方向
1. 这篇论文的实际作用:推动大模型 “平民化部署”
- 降低硬件门槛:2 比特量化后,LLaMA 70B 从 140GB 压缩到 17.5GB,3090(24GB)就能跑;
- 平衡精度与成本:不用花几百万训练 QAT 模型,用 PTQ 就能达到生产级精度(4-5 比特误差≤1%);
- 适配多场景:消费级 GPU、CPU、边缘设备都能用上大模型,比如智能音箱、车载 AI。
2. 现有局限性
- 无混合精度时,小模型(比如 7B)2 比特精度仍有差距;
- 比特配置在调优前固定,没法根据调优过程动态调整;
- 依赖梯度计算,ONNX 等不支持梯度的框架用不了。
3. 未来优化方向(个人思考)
- 动态比特配置:调优过程中根据损失变化,实时调整每层比特数,进一步提升精度;
- 适配无梯度框架:把梯度计算改成无梯度的近似方法,支持 ONNX、TensorRT 等部署框架;
- 结合稀疏化:量化 + 稀疏(去掉无用权重),进一步压缩模型,比如 2 比特 + 50% 稀疏,压缩率达 16 倍;
- 多数据类型适配:支持 MXFP4、NVFP4 等新型低比特数据类型,充分利用硬件加速;
- 小模型优化:针对 7B 等小模型,优化 DeltaLoss 和初始化策略,缩小 2 比特与全精度的差距。
六、总结:SignRoundV2 的核心要点
SignRoundV2 的成功,本质是 “用更聪明的方法做资源分配”—— 通过 DeltaLoss 精准找到敏感层,用预调优初始化稳住极低比特训练,最终实现 “低比特、高精度、低成本” 的三者平衡。
对于开发者来说,这篇论文不仅提供了一个可直接使用的工具(代码已开源:https://github.com/intel/auto-round),更给出了量化优化的思路:量化不是 “暴力压缩”,而是 “精准适配”,未来的大模型部署,必然是 “量化 + 稀疏 + 混合精度” 的组合拳,而 SignRoundV2 已经走在了前面。
如果你正在做大模型部署,或者对量化技术感兴趣,强烈建议去读原文的代码和实验细节,相信会有更多收获~ 有任何疑问,欢迎在评论区交流!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)