Streams 处理:告别 Grok 的困扰 - 在 Streams 中解析你的日志
作者:来自 Elastic Luca Wintergerst

使用 Streams,Elastic 在 9.2 版本推出的新 AI 功能,让日志解析变得如此简单,不再让你烦恼。通常情况下,你的日志很混乱,字段繁多,有些已知,有些未知。你必须不断跟进语义并进行模式匹配才能正确解析。在某些情况下,即便是已知字段,也可能有不同的值或语义。例如,timestamp 是摄取时间,而非事件时间。或者你甚至无法按 log.level 或 user.id 过滤,因为它们埋在 message 字段里。结果,你的仪表板平淡无奇,无法发挥作用。
以前解决这个问题意味着离开 Kibana,学习 Grok 语法,手动编辑 ingest pipeline JSON 或复杂的 Logstash 配置,还得希望不破坏其他解析逻辑。
我们开发 Streams 就是为了解决这些问题,甚至更多。它是你处理数据的一站式工具,内置于 Kibana 中,让你在几秒钟内构建、测试和部署实时数据的解析逻辑。它将高风险的后端任务变为快速、可预测、交互式的 UI 工作流程。你可以使用 AI 从日志样本生成自动 Grok 规则,或者通过 UI 轻松构建。下面让我们来看一个示例。
更多阅读:
快速演示
现在让我们修复一个常见的 “非结构化” 日志。
1)从 Discover 开始。你发现一条日志未被结构化。@timestamp 错误,像 log.level 这样的字段没有被提取,因此你的直方图只是单色柱。
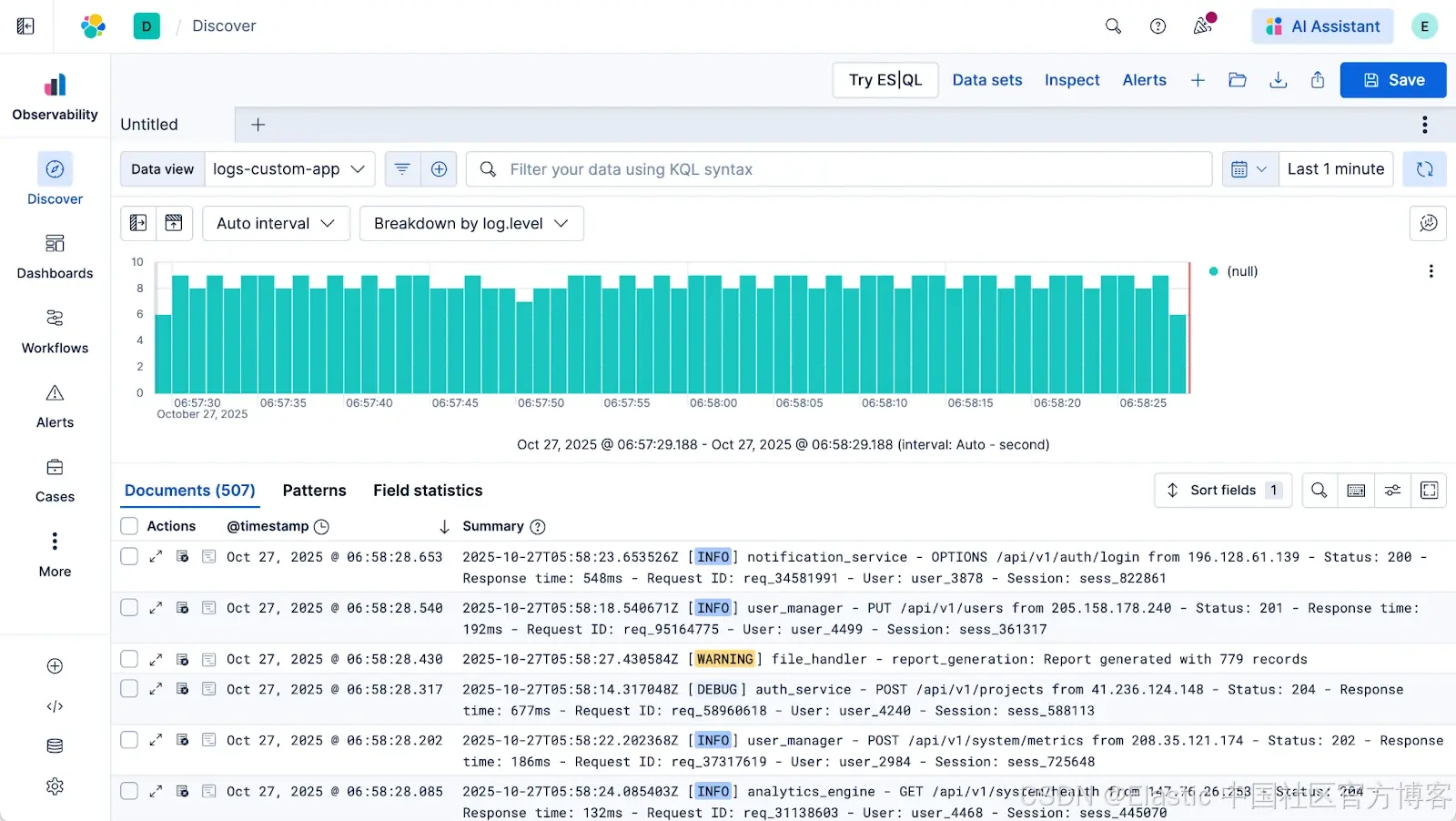
2)检查日志。打开文档弹出窗口(“检查单条日志事件”视图)。你会看到一个按钮:“Parse content in Streams - 在 Streams 中解析内容”(或“在 Streams 中编辑处理”)。点击它。
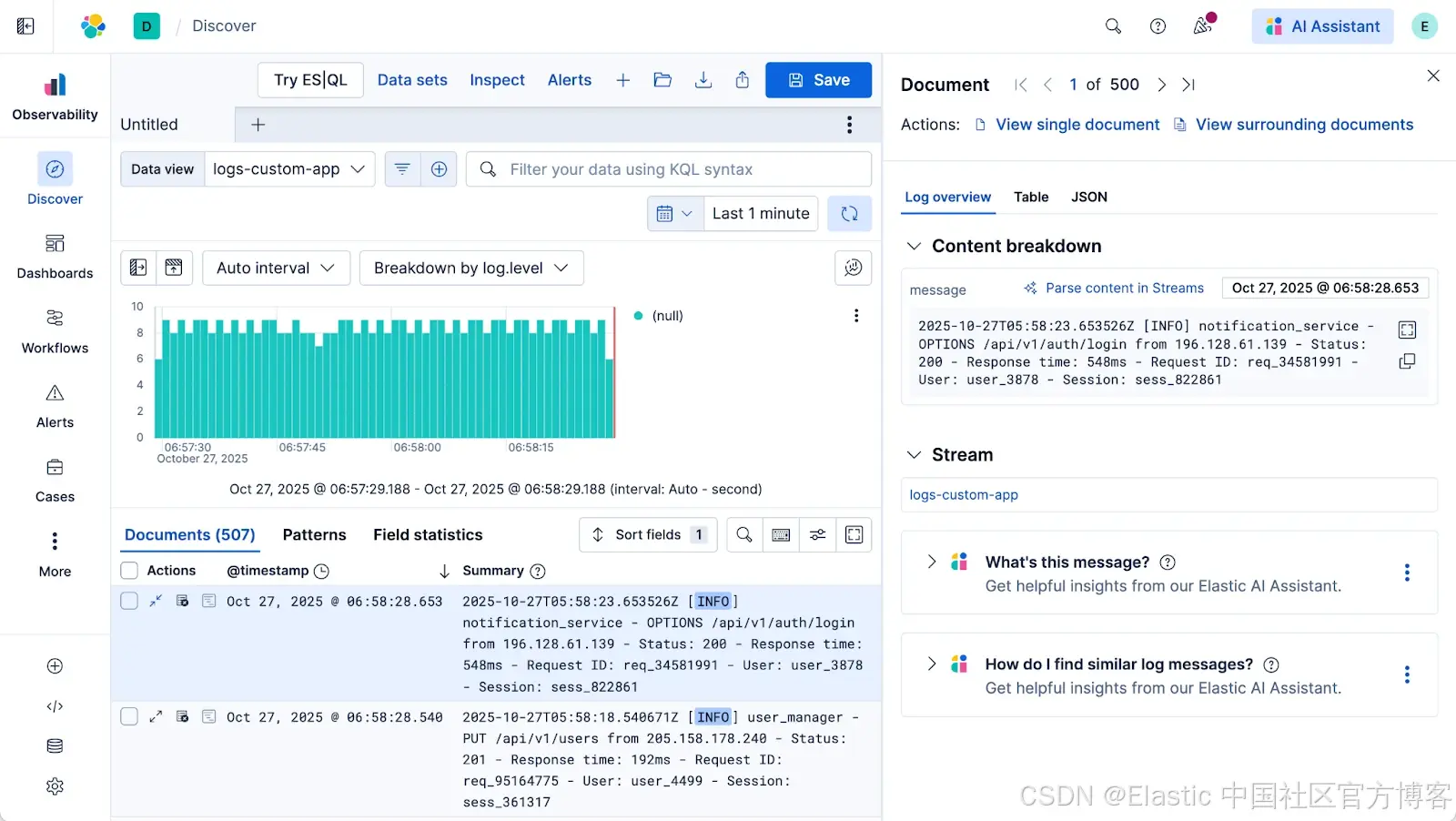
3)进入 Processing。这会直接带你到 Streams 的处理标签页,并预加载来自该数据流的示例文档。点击 “Create your first step - 创建你的第一步”。
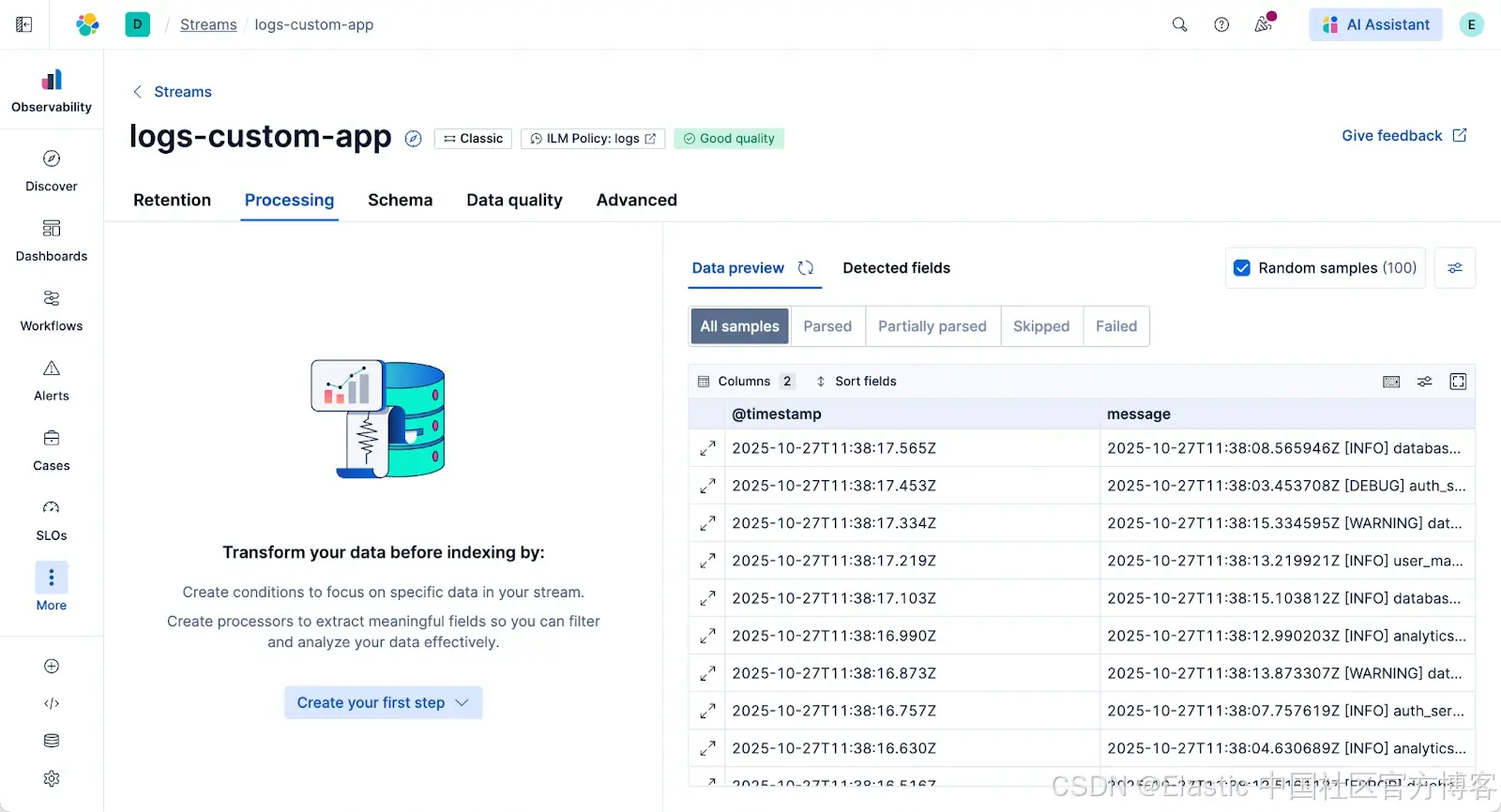
4)生成模式。处理器默认使用 Grok,你无需手动编写。只需点击 “Generate Pattern - 生成模式” 按钮。Streams 会分析数据流中的 100 个示例文档,并为你建议一个 Grok 模式。默认情况下,它使用 Elastic 管理的 LLM,但你也可以配置自己的模型。
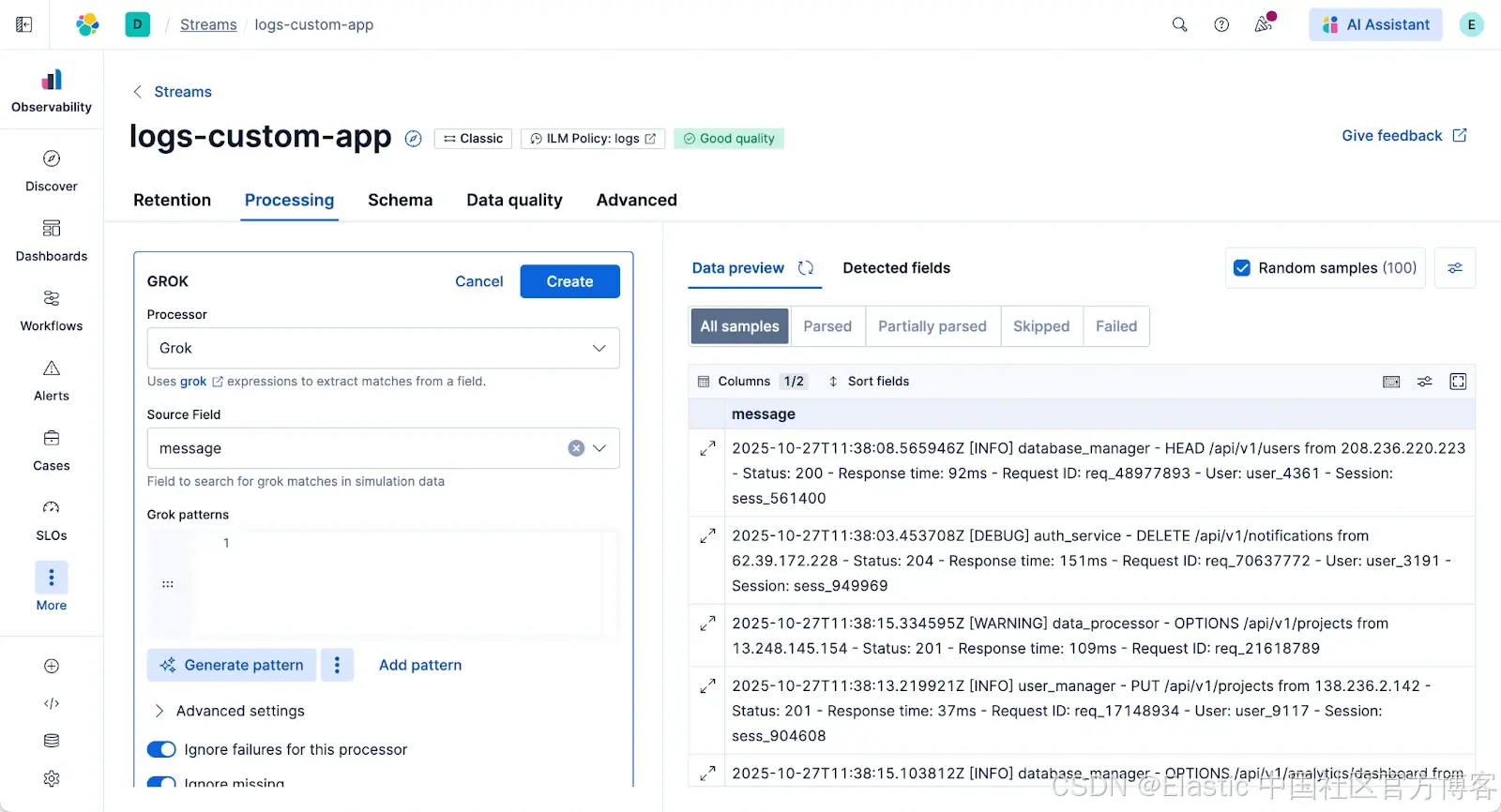
5)接受并模拟。点击“Accept - 接受”。界面会立即对所有 100 个示例文档运行模拟。你可以修改模式或调整字段名称,模拟会在每次输入时重新运行。
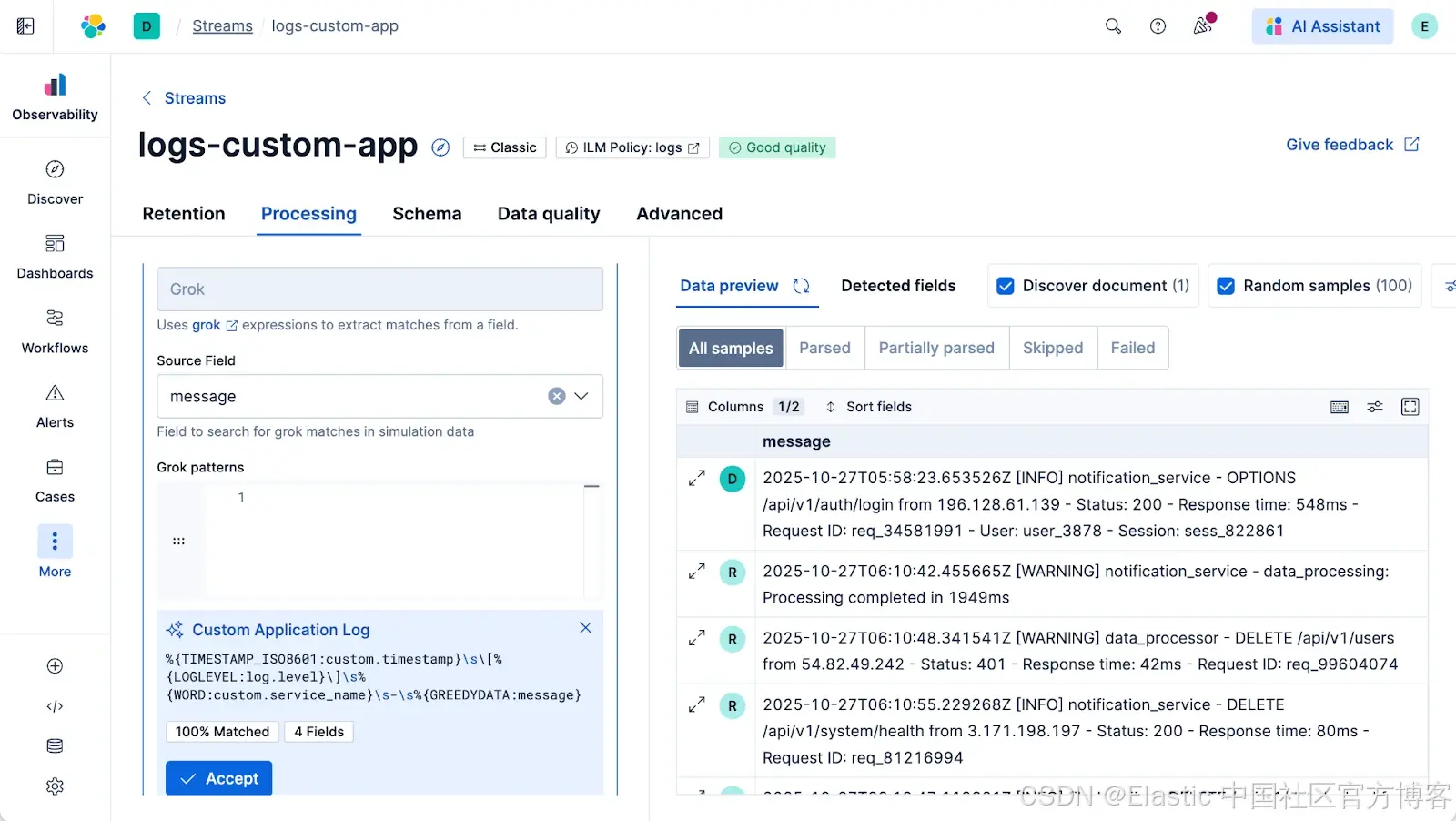
满意后,保存它。你新的日志现在将被正确解析。
处理混乱真实日志的强大功能
这只是一个简单示例。现实世界的数据很少如此干净。以下是为处理复杂情况而设计的功能。
交互式 Grok UI
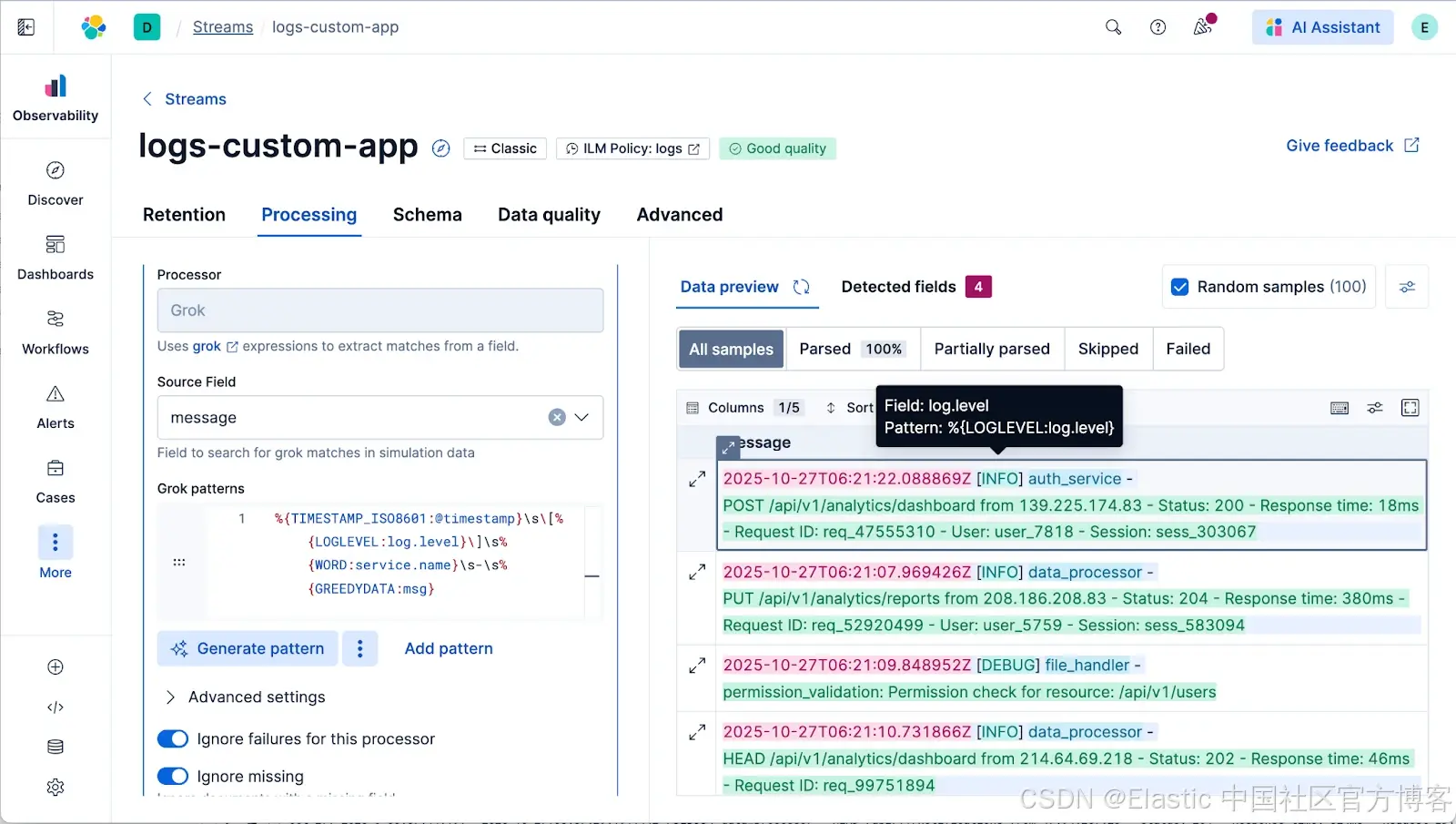
当你使用 Grok 处理器时,UI 会直观显示你的模式正在提取的内容。你可以看到 message 字段的哪些部分被映射到哪些新字段名称。即时反馈意味着你不再只是猜测。GROK 模式的自动补全和即时模式验证也包含在内。
Diff 查看器
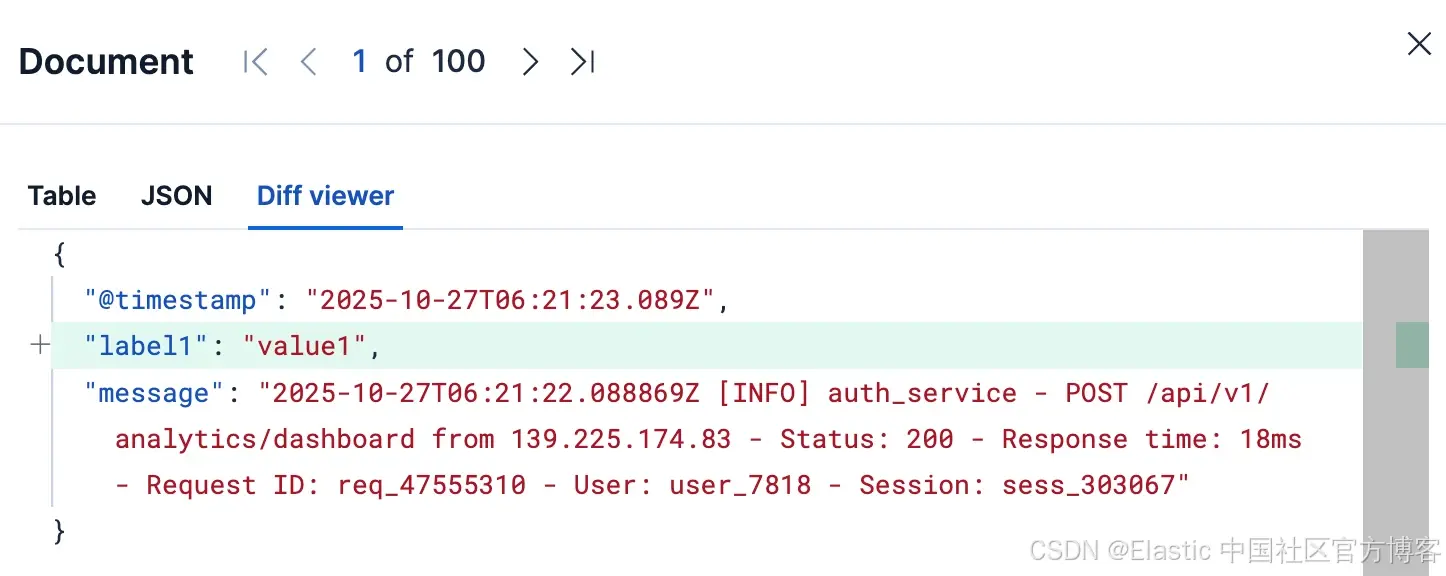
如何知道具体发生了什么变化?展开模拟表中的任意一行,你会看到一个 diff 视图,准确显示该文档中哪些字段被添加、删除或修改。不再需要猜测。
端到端模拟与故障检测
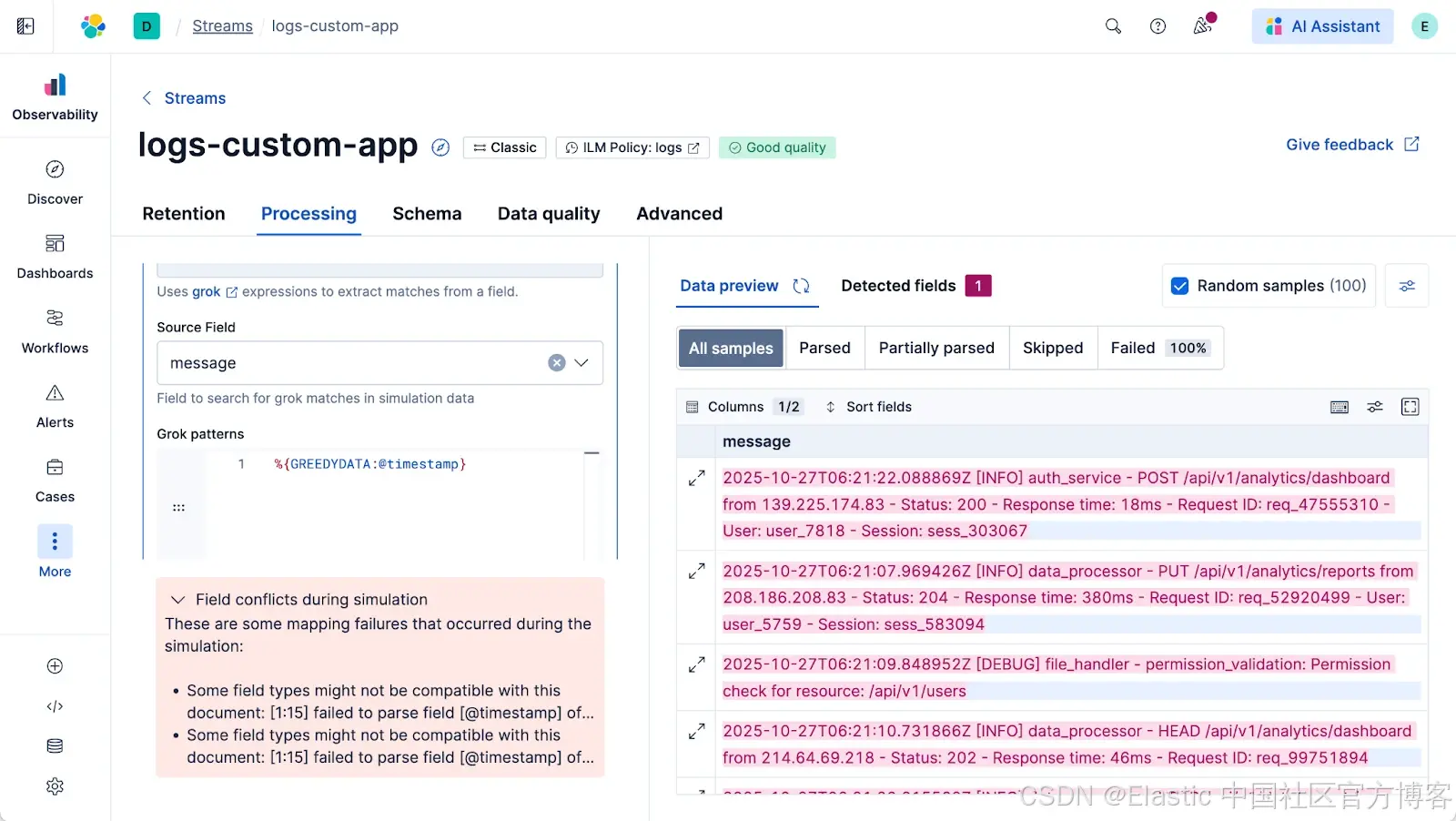
这是最关键的部分。Streams 不仅模拟处理器,还模拟整个索引过程。如果你尝试将非 timestamp 字符串(如 message 字段)直接映射到 @timestamp 字段,模拟会显示失败。它会在你保存之前、在集群中可能产生数据映射冲突之前检测到映射冲突。这个安全网让你可以快速操作。
条件处理
如果一个数据流包含大量不同类型的日志怎么办?你不能用一个 Grok 模式处理所有日志。
Streams 为此提供了条件处理。UI 允许你构建 “if-then” 逻辑。界面会准确显示有多少百分比的示例文档被你的条件跳过或处理。目前,UI 支持最多 3 级嵌套,我们计划未来增加 YAML 模式以处理更复杂的逻辑。
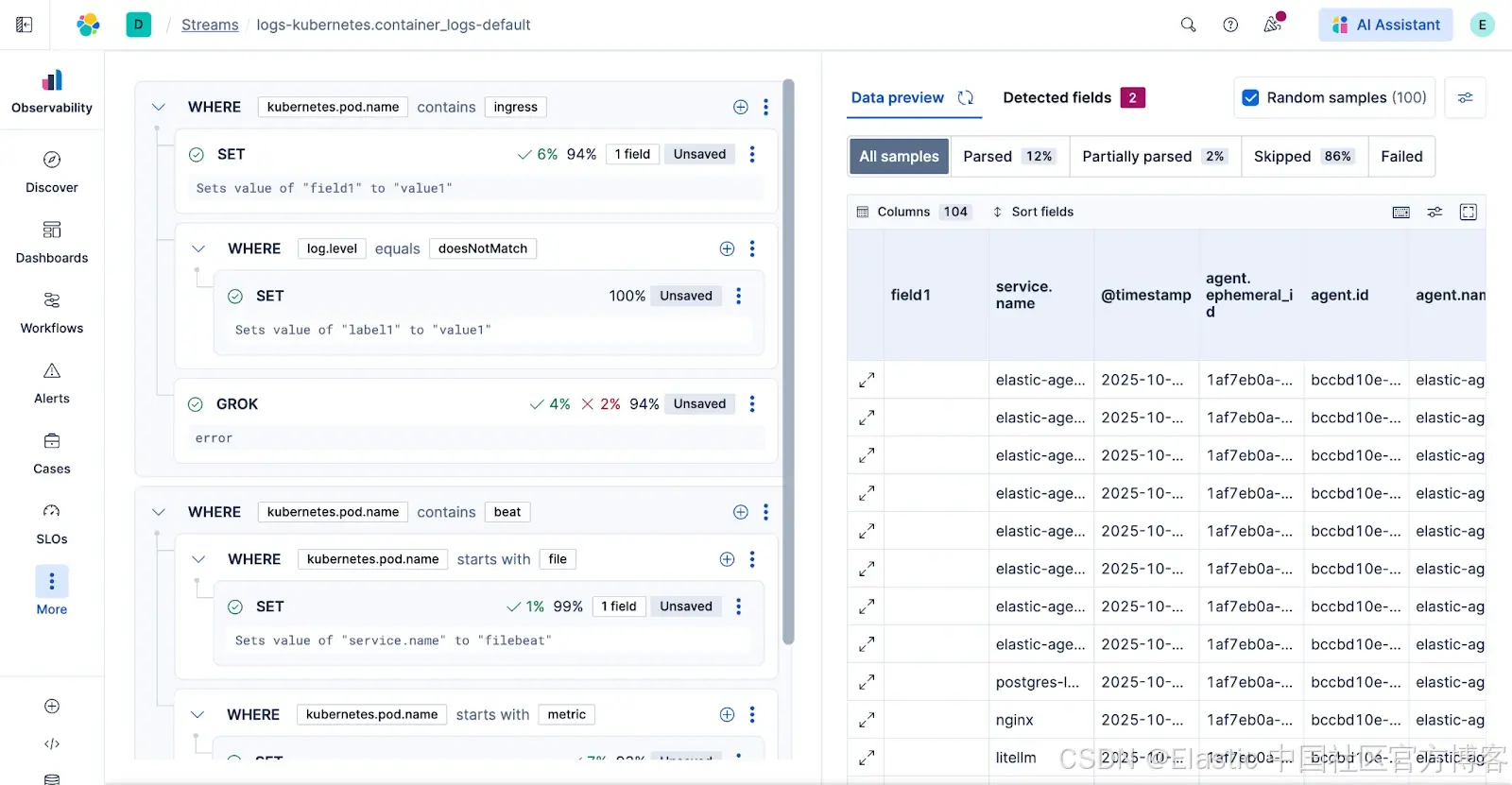
更改测试数据(文档样本)
随机的 100 条文档样本并不总是有用,尤其是在来自 Kubernetes 或中央消息代理的大型混合数据流中。
你可以更改文档样本,在更具体的日志集上测试更改。你可以手动提供文档(复制粘贴),或者更强大地,指定 KQL 查询来获取 100 条特定文档。例如:service.name : "data_processing",以获取 100 条额外样本文档用于模拟。现在你可以在你关心的精确日志上构建和测试处理器。
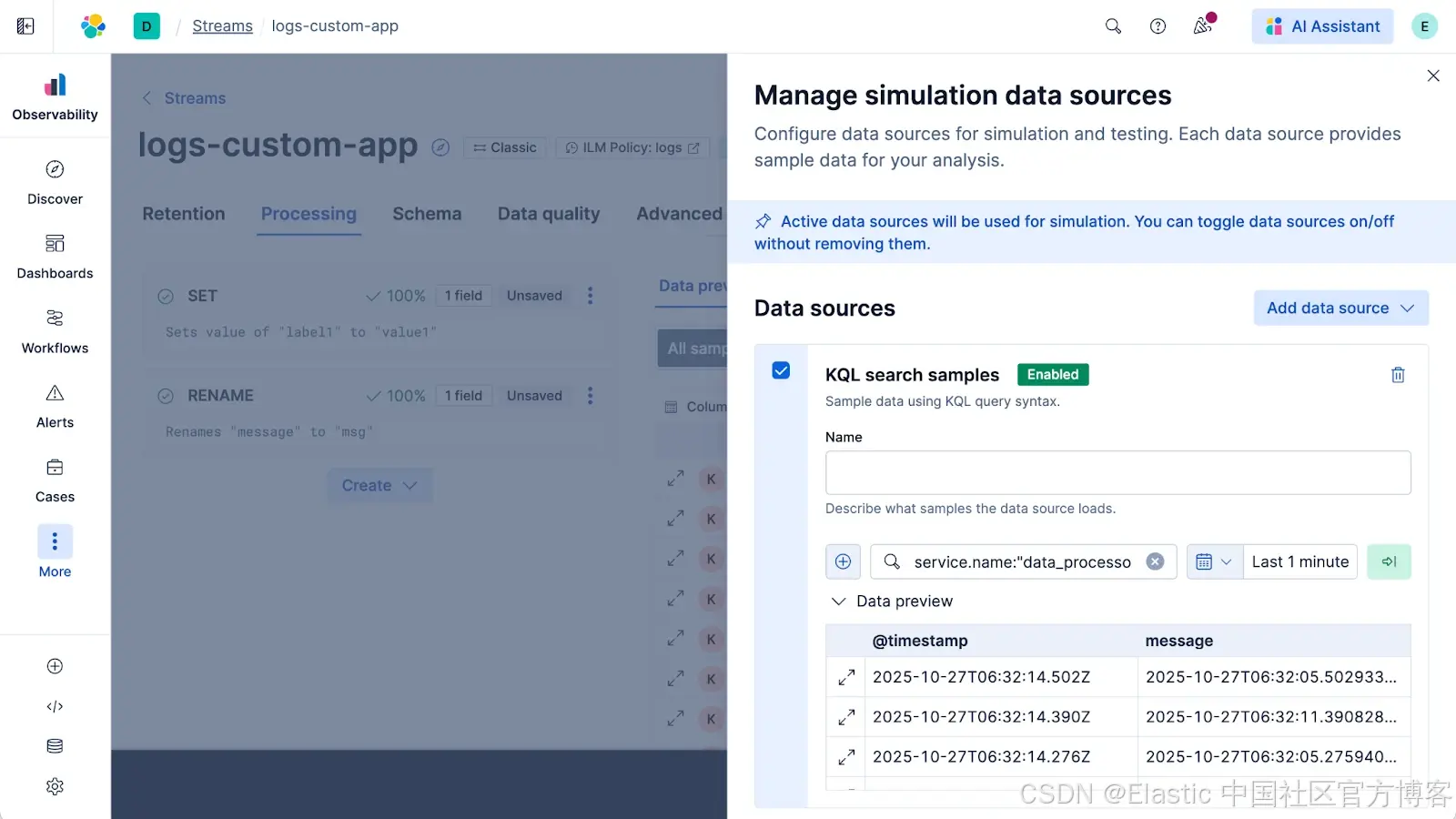
处理的底层原理
没有魔法。简单来说,它是一个让现有最佳实践更易访问的 UI。从 9.2 版本开始,Streams 完全运行在 Elasticsearch ingest pipeline 上。(我们计划提供更多功能,敬请期待)
当你保存更改时,Streams 会通过以下方式附加处理步骤:
- 定位数据流最具体的 @custom ingest pipeline。
- 向其添加单个 pipeline 处理器。
- 该处理器调用一个新的专用 pipeline,名为
<stream-name>@stream.processing,其中包含你在 UI 中构建的 Grok、条件及其他逻辑。
你甚至可以自己查看:进入 Stream 的 Advanced 标签页,点击 pipeline 名称即可。
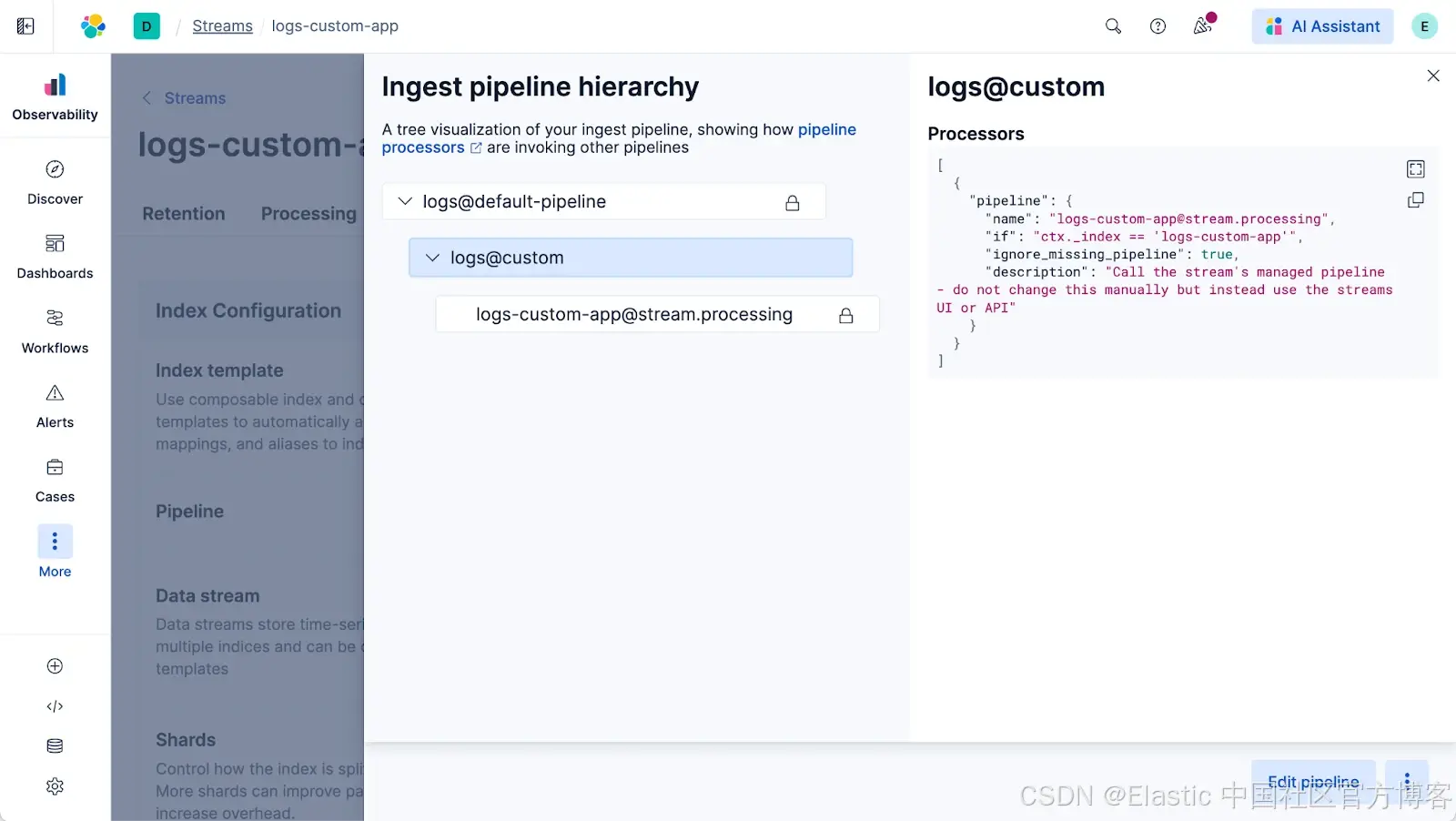
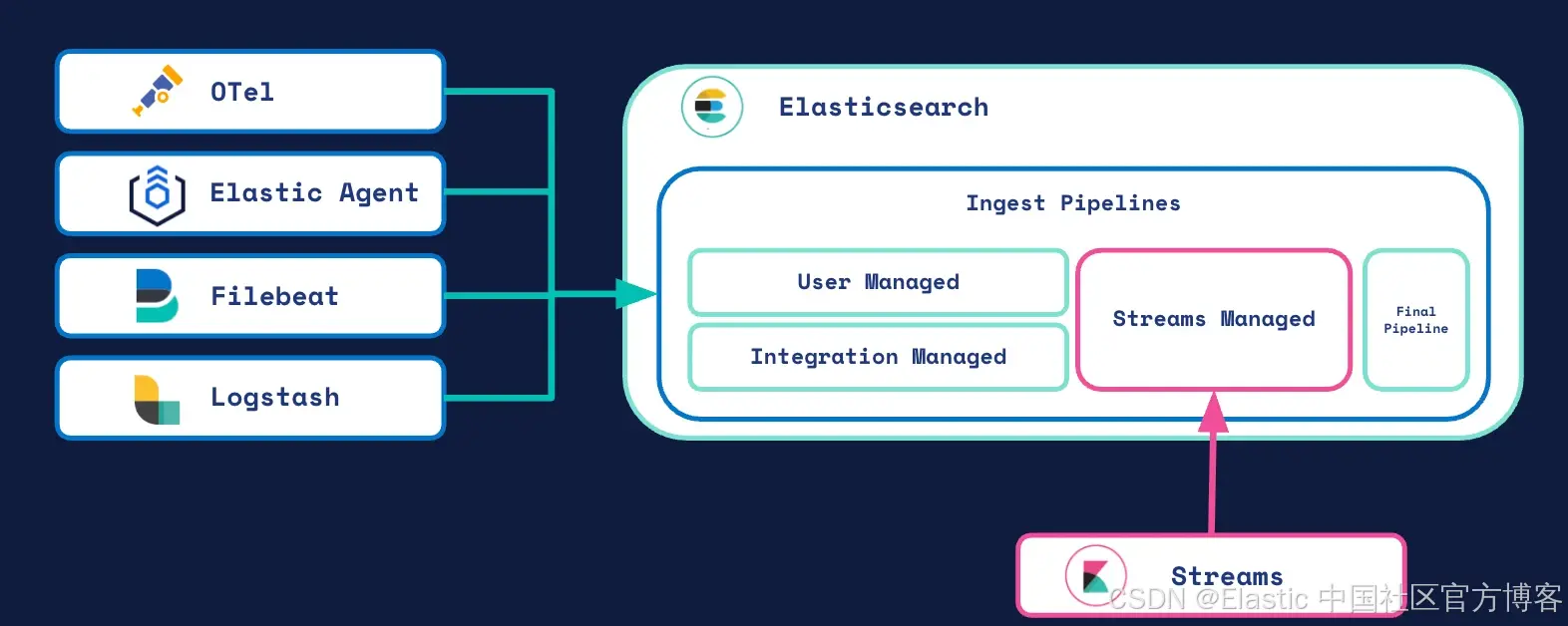
在 OTel、Elastic Agent、Logstash 还是 Streams 中处理?该用哪个?
这是一个合理的问题。你有很多方式来解析数据。
-
最佳:源头结构化日志。如果你能控制写日志的应用,让它以你选择的正确格式记录 JSON 日志。这始终是最好的日志方式,但并不总是可行。
-
不错,但不是每次都适用:Elastic Agent + Integrations。如果已有用于收集和解析数据的集成,Streams 并不会做得更好。就用它吧!
-
适合技术熟练用户:OTel 在边缘。使用 OTel(配合 OTTL)为未来做准备。
-
简单的全能方案:Streams。特别是当使用主要只将数据发送到 Elastic 的 Integration 时,Streams 可以增加很多价值。Kubernetes Logs Integration 就是一个好例子,虽然使用了 Integration,但大多数日志不会自动解析,因为它们来自各种 Pod。
把 Streams 当作你通用的“全能捕获器”,处理所有未结构化到达的数据。它非常适合你无法控制的数据源、遗留系统,或者当你只想立即修复解析错误而无需完整应用重新部署时。
关于模式的快速说明:Streams 可以处理 ECS(Elastic Common Schema)和 OTel(OpenTelemetry)数据。默认情况下,它假设目标模式为 ECS。不过,如果你的 Stream 名称包含 “otel”,或者你正在使用特殊的 Logs Stream(目前为技术预览),Streams 会自动检测并适配 OTel 模式。无论模式如何,你都会获得相同的可视化解析工作流程。
所有处理更改也可以通过 Kibana API 完成。注意,该 API 仍处于技术预览阶段,我们正在完善部分功能。
总结
日志解析不应是一个繁琐、高风险、仅在后端进行的任务。Streams 将整个工作流程从复杂且易出错的方法转移到你已熟悉的交互式 UI。你现在可以构建、测试并部署解析逻辑,并获得即时、安全的反馈。这意味着你可以停止与日志 “斗争”,真正开始使用它们。下次遇到混乱日志时,不要忽视它。点击“在 Streams 中解析”,60 秒内解决问题。
在 Elastic Observability Labs 查看更多日志分析文章。
试用 Elastic。注册 Elastic Cloud 试用。
原文:https://www.elastic.co/observability-labs/blog/elastic-streams-processing

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献101条内容
已为社区贡献101条内容

所有评论(0)