大模型 MoE,你明白了么?
本文介绍了混合专家模型(MoE)的核心概念和架构优势。MoE通过多个专家网络协同工作,每次推理仅激活少量相关专家,实现大模型能力与小模型成本的结合。文章对比了传统稠密模型(Dense)和MoE模型的差异:MoE总参数量大但激活参数少,显存占用仅为Dense模型的1/10-1/20,使大模型能在消费级显卡运行。关键要素包括路由器(Router)选择专家、专家分工机制和Top-K激活策略。MoE架构既
大模型 MoE,你明白了么?
最近被T4卡搞得有点抽风就多些一点关于大模型的讲解的。由浅至深的讲个透,愿天下用老旧显卡的人儿都可以远离傻*问题。

作者:吴佳浩
最后更新:2025-12-11
适用人群:大模型上下游相关从业者
——以 Qwen2/Qwen3 为例,从入门到回家
1. 什么是 MoE(Mixture of Experts)
核心概念
MoE = 混合专家模型,它让模型由多个"专家网络"组成,每次推理只激活少量专家,从而实现:
- ✅ 保留大模型能力 - 总参数量大,能力强
- ✅ 降低推理成本 - 只激活部分参数,计算量小
- ✅ 提升领域能力 - 专家各司其职,术业有专攻
核心理念
💡 不需要每个 token 都用 300 亿参数计算,而是只调用其中最适合解决该问题的专家。
这就像一个医院:
- 你头疼不需要召集所有科室医生
- 只需要神经科专家诊断
- 但医院仍然拥有全科能力
为什么需要 MoE?
Dense 模型的问题:
| 参数量 | 推理需要激活 | 显存需求 |
|---|---|---|
| 70B | 全 70B | 极高(>140GB FP16) |
MoE 的改进:
| 总参数量 | 每次激活 | 实际推理成本 |
|---|---|---|
| 70B(含16个专家) | Top-1=3B | 像跑 3B 模型一样 cheap |
核心思想:选对专家,而不是计算全部专家。
2. MoE 架构全景
2.1 基础架构流程
关键要素解释:
- Router(路由器) - 根据输入内容选择最适合的专家(Top-1 / Top-2)
- Experts(专家) - 每个都是独立的 FFN 网络,拥有专属参数
- 选择性激活 - 只激活部分专家,其余专家在当前 token 不参与运算
- 加权合并 - 将激活专家的输出按权重求和
2.2 完整 Transformer 层结构
对比要点:
- 传统模型:FFN 层所有参数都参与计算
- MoE 模型:用多专家 + 路由器替代 Dense FFN
3. Dense 模型 vs MoE 模型:显存与计算对比
3.1 什么是 Dense(稠密模型)
Dense = 所有参数全部参与推理
示例:
- Qwen2.5-32B Dense
- 推理时 32B 全激活
- 显存占用 60+ GB(FP16)
- 性能强但成本高
显存对比表:
| 模型 | FP16 | FP8 | INT8 | INT4 |
|---|---|---|---|---|
| Qwen3 Dense 32B(全激活) | 60+ GB | 30 GB | 28 GB | 15 GB |
| Qwen3 MoE 30B(激活 ~3B) | 6 GB | 3 GB | 3 GB | 1.5 GB |
👉 MoE 推理显存 ≈ Dense 的 1/10~1/20
3.2 什么是 MoE(混合专家模型)
MoE = 总参数大,但每次只激活少量专家
示例:
- Qwen1.5-MoE-33B
- 总参数:33B
- 激活专家:Top-1(约 3B)
- 显存占用:~6GB(FP16)
- 推理成本 ≈ 3B Dense 模型
3.3 显存占用对比表(重要!)
以 Qwen3 32B Dense & Qwen3 30B MoE 为例:
| 模型配置 | FP16(全精度) | FP8 | INT8 | INT4 |
|---|---|---|---|---|
| Qwen3 Dense 32B (全参数激活) |
60+ GB | ~30 GB | ~28 GB | ~15 GB |
| Qwen3 MoE 30B (激活 3B) |
~6 GB | ~3 GB | ~3 GB | ~1.5 GB |
结论:
⚡ MoE 推理显存消耗 ≈ Dense 的 1/10
原因:
- Dense:所有层、所有参数都要参与计算
- MoE:每层只用少数专家(如激活 3B)
这就是为什么 30B MoE 可以在消费级显卡运行。
4. MoE 的关键概念
4.1 专家数量(Experts)
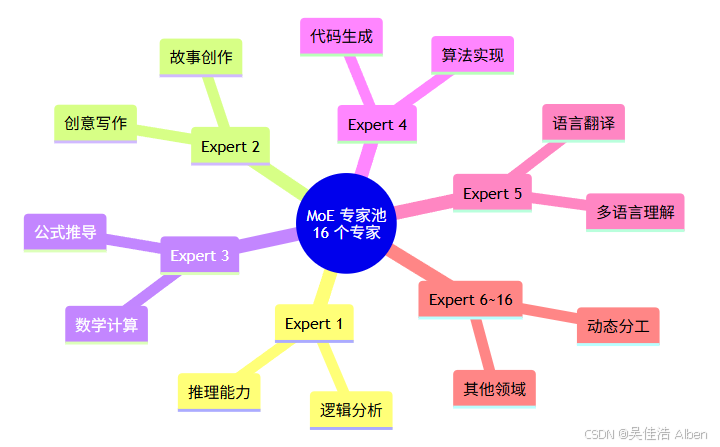
专家分工示例:
- Expert 1:推理、逻辑分析
- Expert 3:数学、计算
- Expert 5:代码生成
- Expert 7:语言翻译
- Expert 10:创意写作
- …
4.2 Top-K(激活专家数量)
常见配置:
- Top-1:每次激活 1 个专家(速度快)
- Top-2:每次激活 2 个专家(性能好)
4.3 参数关系图
关键公式:
总参数 = 专家数量 × 单专家参数 + 共享参数
激活参数 = Top-K × 单专家参数 + 共享参数
推理成本 ∝ 激活参数(而非总参数)
5. 常见疑问:没激活的专家是不是浪费?
❌ 错误理解
✅ 正确理解
真相:
- 训练时 - 所有专家都会被激活并学习
- 推理时 - 根据任务动态选择最合适的专家
- 长期使用 - 每个专家都会在各自擅长的领域发光
类比:
🏥 医院有 16 个科室,你看病只挂 1 个科室,但其他科室不是浪费,而是在服务其他患者。
6. Qwen3(Dense / MoE)部署推荐方案
场景分析
方案 1:注重性能(推荐)
Qwen3-14B Dense(INT4 或 FP8)
| 精度 | 显存占用 | 推荐指数 | 说明 |
|---|---|---|---|
| FP16 | ~28GB | ❌ | 超出 24GB 显存 |
| FP8 | ~14GB | ⭐⭐⭐⭐⭐ | 强烈推荐 |
| INT4 | ~7GB | ⭐⭐⭐⭐ | 轻量级最佳 |
优势:
- 性能显著强于 7B
- 性价比 > 70%
- 适合日常对话、代码生成
方案 2:大模型能力 + 小显存
Qwen1.5-MoE-33B(INT4)
| 指标 | 数值 |
|---|---|
| 总参数 | 33B |
| 激活参数 | ~3B |
| 显存占用 | ~1.5GB (INT4) |
优势:
- ✅ 显存占用极低(4GB 显卡可跑)
- ✅ 推理速度快
- ✅ 性能接近 30B Dense(尤其中文、推理)
劣势:
- ⚠️ 特定任务效果可能不如 Dense 精细
方案 3:企业级旗舰
Qwen3-72B Dense(FP8)
硬件要求:
- A100 80GB / H100
- 或多卡 80GB GPU
性能:
- Top 级别
- 适合企业级应用
7. MoE 的训练机制(进阶)
7.1 训练流程图
7.2 路由器训练机制
训练优化:
- 使用 Softmax + Top-K
- 加入 负载均衡(Load Balancing)损失项
- 确保专家不会"偏向性过强"
7.3 专家特化过程
关键训练技术:
- OBST(One-Batch Selective Training)
- GShard(Google)
- Switch Transformer(Google)
- DeepSpeed-MoE(微软)
7.4 防止专家闲置的机制
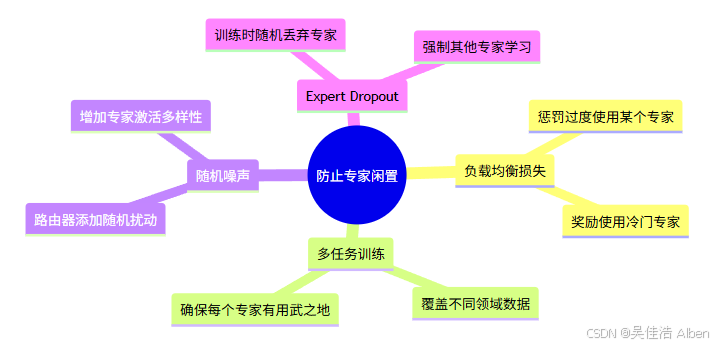
结果: 所有专家都有机会参与训练,不会出现"活跃专家"和"僵尸专家"。
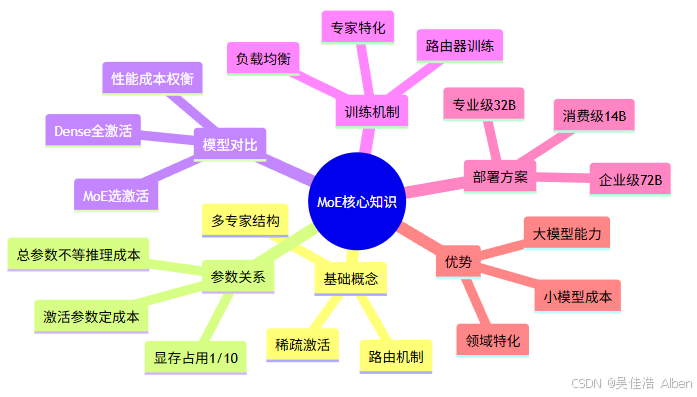
8. 完整知识体系总结
9. 十句话掌握 MoE
- MoE = 多专家结构,每次只激活少数专家
- 总参数(如 30B)≠ 推理成本
- 推理成本 ≈ 激活参数(如 3B)
- Dense = 全部激活,性能强但成本高
- MoE = “大模型能力 + 小模型成本”
- INT4/FP8 是量化技术,与 MoE 架构无关
- INT4 省显存但会略降性能
- MoE 不会浪费参数,未激活专家会在其他任务中使用
- Qwen3-14B Dense FP8 是最稳健的部署方案
- Qwen-MoE 系列适合显存 4GB~24GB 的场景
10. 个人快速决策指南
附录:参考资源
官方文档:
部署工具:
- vLLM
- Ollama
- llama.cpp

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)