英伟达的“AI算力霸权”背后:谁来守护被牺牲的FP64与科学计算的未来?
英伟达近期在超级计算领域遭遇持续争议。部分 HPC 领域专家批评其在新架构中优先强化 AI 所需的低精度算力,而对传统建模与仿真高度依赖的 64 位(FP64)性能投入不足。
英伟达近期在超级计算领域遭遇持续争议。部分 HPC 领域专家批评其在新架构中优先强化 AI 所需的低精度算力,而对传统建模与仿真高度依赖的 64 位(FP64)性能投入不足。不过英伟达相关高管对外表示,公司并未放弃 FP64 计算,并提到包括 cuBLAS 在内的最新模拟库正在持续加强,同时也承诺下一代 GPU 将提升 FP64 能力。
在 SC25 公布最新 TOP500 榜单期间,HPC 领域权威、田纳西大学教授 Jack Dongarra 明确指出,从 Hopper 架构过渡到 Blackwell 架构后,英伟达的 FP64 性能“没有实质性的提升”,甚至出现倒退。他直言:“平台的浮点能力相比前代没有改进——64 位性能没有提升。我们看到的是带宽更高,但 FP64 却停滞的处理器。”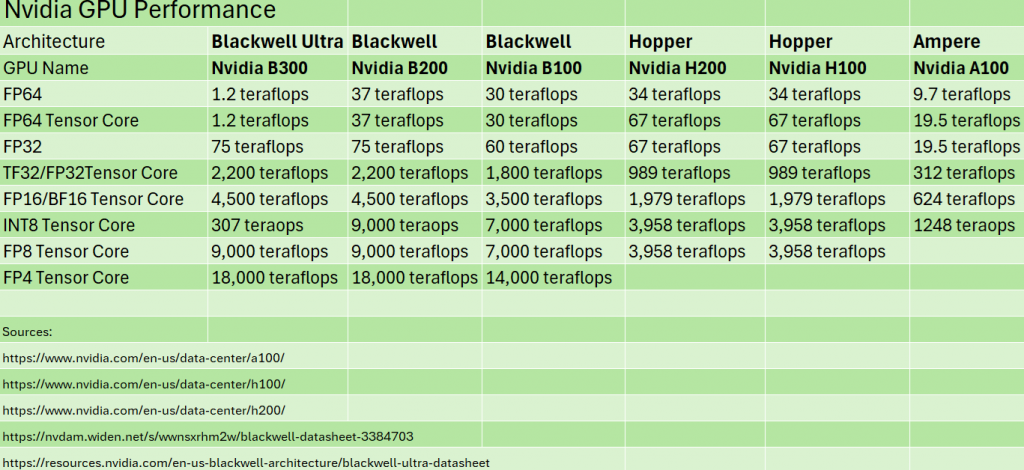
从数据上看,Hopper 架构(H100/H200)在 FP64 上仍保持强势:34 TFLOPS 的 FP64 与 67 TFLOPS 的 FP64 Tensor 性能,较 2020 年的 A100 有明显跃升。然而到了 Blackwell 架构,B100 的 FP64 性能下降至 30 TFLOPS,虽 B200 与 GB200 略有回升,整体仍未达到 H200 的水平;而最新 B300 Ultra Blackwell 的 FP64 甚至低至约 1 TFLOPS,与 Hopper 相差一个数量级,形成鲜明反差的则是其高达 14 PFLOPS 的 FP4 性能——完全针对 AI 工作负载而来。
一、精度之战:为什么 FP64 在科学计算中无法妥协?
低精度革命在 AI 时代取得巨大成功,FP16、FP8、FP4 通过混合精度训练,使神经网络在保持可接受误差的情况下实现数倍算力提升、显著降低训练成本。这直接推动了 GPT-4、Sora 等超大模型的诞生。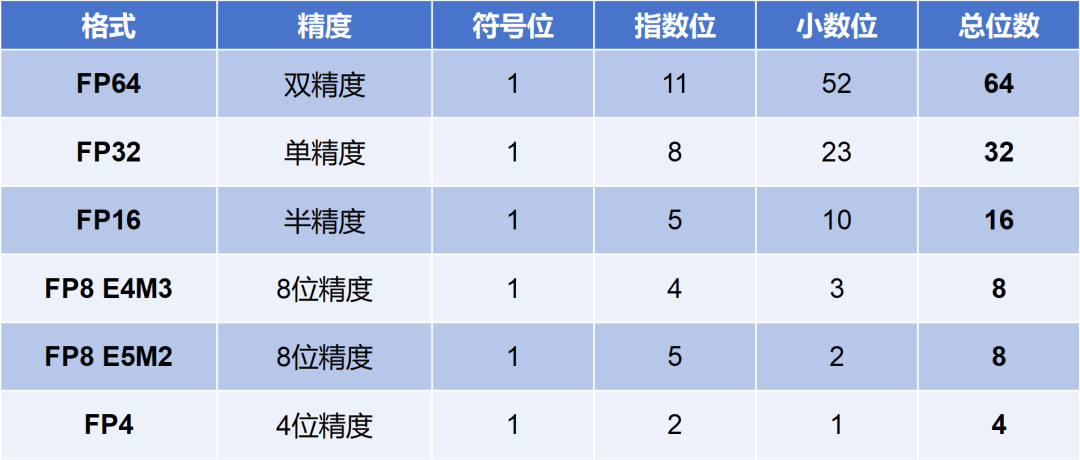
然而在科学计算、工程仿真、气候模拟、材料建模等 HPC 核心领域,FP64 是不可替代的基础支柱。高精度不仅是习惯,而是数值方法本身的数学要求——复杂 PDE 求解、迭代收敛、误差控制、矩阵稳定性等均依赖 FP64 的准确性。即便 HBM 带宽的堆叠对于 AI 十分关键,但这些提升并未解决 HPC 工作负载最核心的“精度稳定性”需求。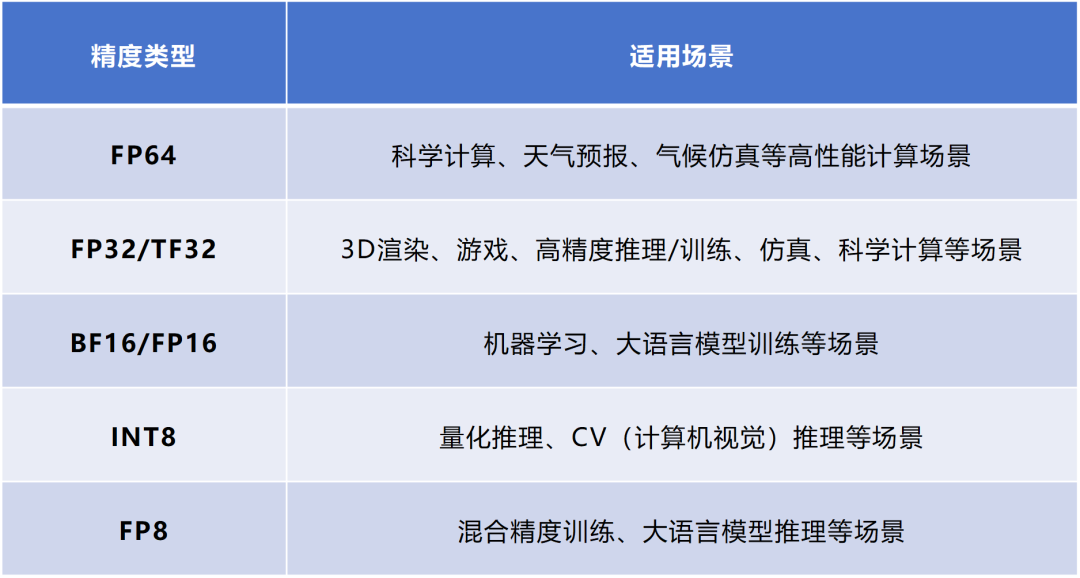
换句话说,英伟达在 Blackwell 中优先低精度,是顺应 AI 市场的现实策略;但从科学计算角度看,其 GPU 在 FP64 性能上的停滞确实带来了潜在影响与担忧。
二、生态震荡:超算中心的集体焦虑正在快速累积
英伟达 FP64 战略调整对全球超算生态产生了连锁影响:
1. 国家级科学算力项目被迫调整路线图
如 DOE 的 Exascale Computing Project 中,Frontier(AMD)与 Aurora(Intel)因保持 FP64 均衡而相对平稳,而大量基于英伟达 GPU 的系统升级计划被迫重新评估。日本富岳后继机型、欧盟 EuroHPC 的多个项目也出现路线微调。
2. 二级市场出现反常:H100 在 Blackwell 发布后不降反升
原因很简单:对 FP64 有硬性需求的科研机构发现,新架构反而是“降级”,H100/H200 才是更适配 HPC 的选择。阿贡国家实验室科学家李伟表示:“我们正在延长 Hopper 集群的生命周期,同时评估 AMD MI300X 与 Intel Ponte Vecchio——这在过去难以想象。”
3. 新兴架构获得长期未有的窗口期
AMD MI300X 强调 1:2 FP64/矩阵核心比率,高调对标英伟达短板。Intel 在 Ponte Vecchio 中强调“原生 64 位支持”。中国昇腾也在最新白皮书中将“科学计算全栈优化”作为单独章节——差异化竞争机会正在形成。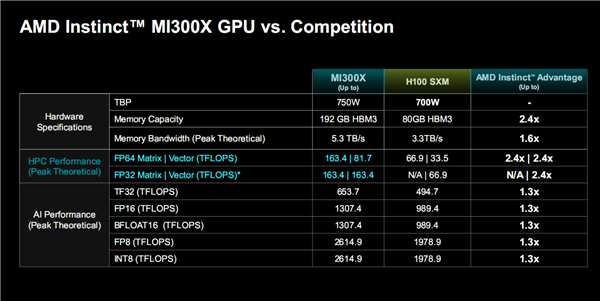
三、开发者站在十字路口:适应、妥协,还是重建?
随着硬件精度倾斜,软件与算法端正经历一次“静默但深刻”的重构。
1. 分层精度算法开始流行,但成本高昂
如 MIT 研发的“自适应精度分区算法”,将核心物理区域强制 FP64,而将非关键区域交给 FP16/FP8,平均减少 40% FP64 需求。但这种算法往往需要数月人工优化,并非万能解。
2. 异构计算让 HPC 工作流变得越来越复杂
橡树岭国家实验室表示:“我们现在常用的是 CPU + AMD GPU + Nvidia GPU 的三层异构体系,分别处理不同任务,调试复杂度是过去的两倍。”
3. 开源社区开始行动
GitHub 上出现 “OpenPrecision” 计划,旨在提供跨平台精度抽象层,让 CUDA 代码能在更广泛的 FP64 硬件上运行。创始人 Rajesh Kumar 指出:“硬件不应决定科学的上限。”
四、英伟达的两难:万亿市值背后的战略算式
从英伟达财报看,其选择几乎是“必然”:数据中心业务在 2025 财年占比已达 88%,其中 AI 训练与推理贡献超过 70% 的增长,传统 HPC 业务占比不足 8%。市场分析师指出:“为了一个不足 10% 的平缓市场,牺牲对 90% 高速增长市场的优化是不现实的。”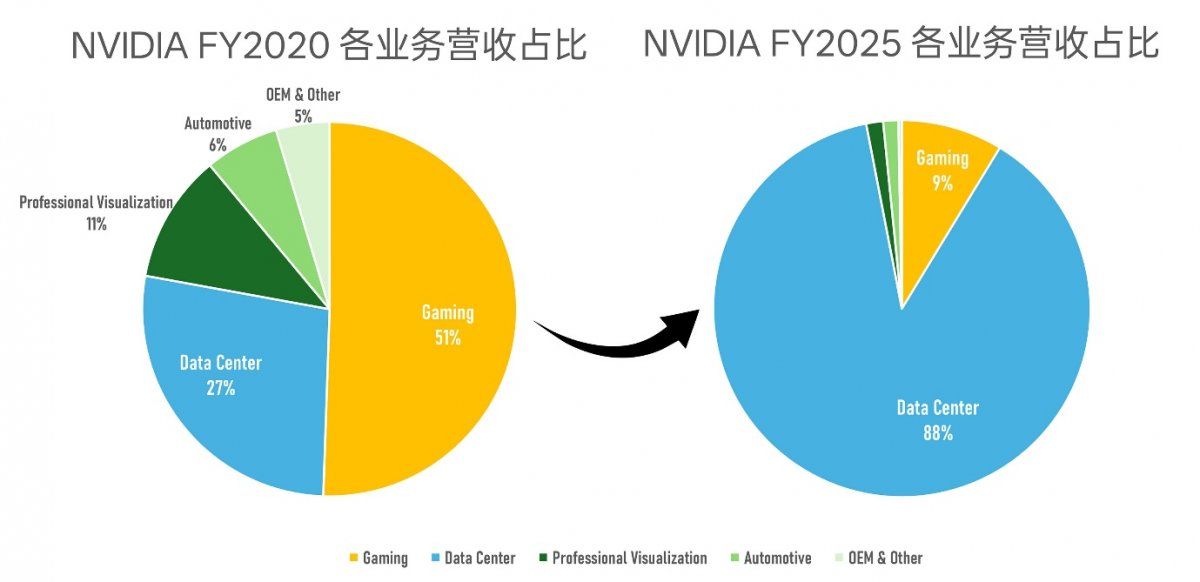
但这同样带来生态风险。CUDA 生态的稳固来自应用广度——涵盖游戏、AI、科学计算。一旦 HPC 生态在他家芯片上形成完整替代链条,AI 芯片领域的竞争壁垒也会下降。
英伟达高管暗示下一代将加强 FP64,这被业界解读为可能推出“面向 HPC 的特化版 GPU”。但 AI 和 HPC 共用同一底层技术栈,这种分化能否真正落地仍存不确定性。
五、多元算力的未来:超越单一架构的新时代
这场“精度之争”的深层启示是:未来计算不会、也不能依赖单一架构。
1. 专用加速器可能重新崛起
Groq的LPU(语言处理单元)、Cerebras的晶圆级引擎、Graphcore的IPU等架构,正从边缘突破,也可能催生面向气候科学、计算化学的专用处理器。
2. 云服务开始提供可调精度算力
AWS、Azure、Google Cloud 已推出可动态分配 FP64/低精度资源的实例,让更小的研究机构也能使用高精度算力。
3. 地缘政治影响加速自主科学算力建设
欧盟的European Processor Initiative(EPI)、日本的Post-K计算机项目,以及我国的“东数西算”工程,都包含了对自主可控科学算力的战略布局。英伟达的选择客观上为这些本土方案创造了生存空间。
六、智能与真理::双轨并行的计算未来
在AI加速重塑计算范式的同时,科学研究仍依赖高精度数值方法来确保模型可信性,因此未来的算力体系将从单一架构走向多层协同:AI 用于模式识别与加速模拟,传统 FP64 运算承担关键物理规律求解,而量子等新兴架构探索更深层的计算空间。
各国超算中心延长旧 GPU 服役、云厂商引入可配置精度实例、本土科学算力体系的推进,都反映出行业正从“单一性能指标”转向“多精度、多架构共存”的更稳健路径。真正重要的不是某款芯片的参数,而是系统在不同负载与精度需求之间的灵活切换能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)