GLM-4.6V开源:从看懂到完成
智谱AI开源GLM-4.6V多模态大模型,实现从"理解图片"到"完成任务"的突破。该系列包含高性能云端版(106B-A12B)和轻量本地版(9B),具备128k超长上下文处理能力和SOTA视觉精度。其核心创新在于原生多模态工具调用和视觉-行动闭环,支持直接处理图像并生成可执行行动,适用于图文创作、电商导购、前端开发等场景。模型已全面开源,提供本地部署、云端A
在AI多模态领域,模型从"看懂图片"到"自动完成任务"的跨越,一直是技术发展的关键瓶颈。
近日,智谱AI正式开源GLM-4.6V系列多模态大模型,标志着国产多模态技术迈入新纪元。本文将带您深入了解这一突破性模型的三大核心亮点。
一、技术参数
GLM-4.6V系列包含两款模型:
面向云端高性能场景的GLM-4.6V(106B-A12B)和面向本地部署的轻量版GLM-4.6V-Flash(9B)。
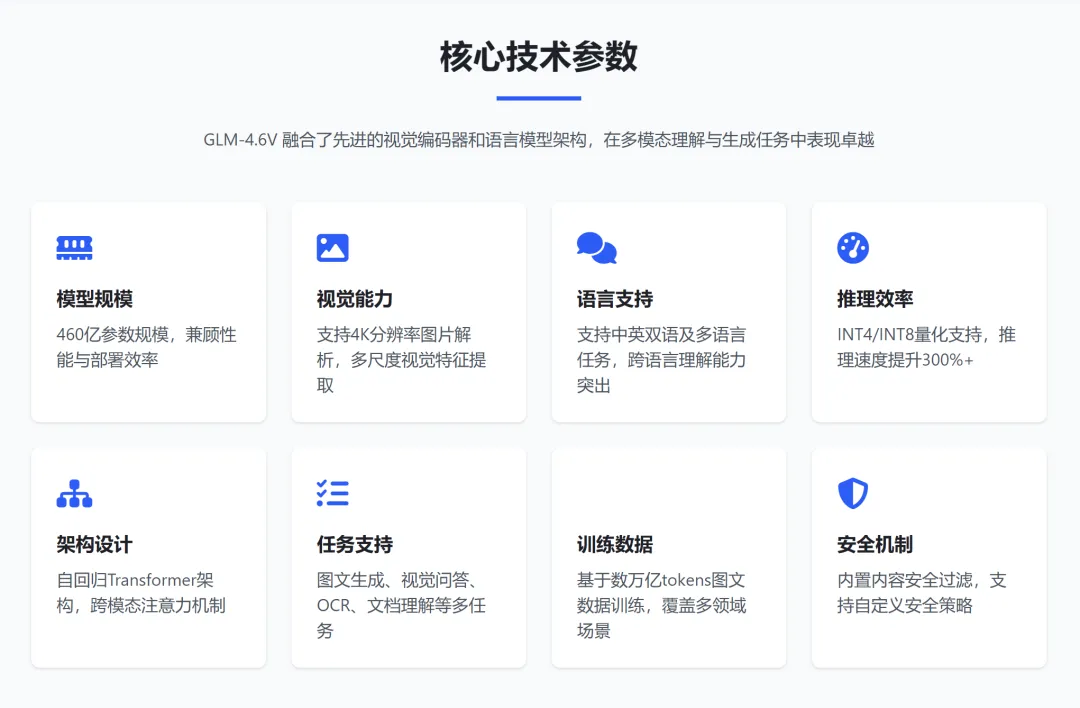
其技术亮点包括:
超长上下文处理:训练时上下文窗口提升至128k tokens,显著提升长文档和视频理解能力
视觉精度突破:在同参数规模下达到SOTA(State-of-the-Art)视觉理解精度
性能对比:9B版本的GLM-4.6V-Flash在34项测试中22项超越Qwen3-VL-8B;106B参数12B激活的GLM-4.6V表现接近Qwen3-VL-235B(参数量为2倍)
价格优势:API调用价格低至输入1元/百万tokens,输出3元/百万tokens,GLM-4.6V-Flash全面免费
二、区别与突破
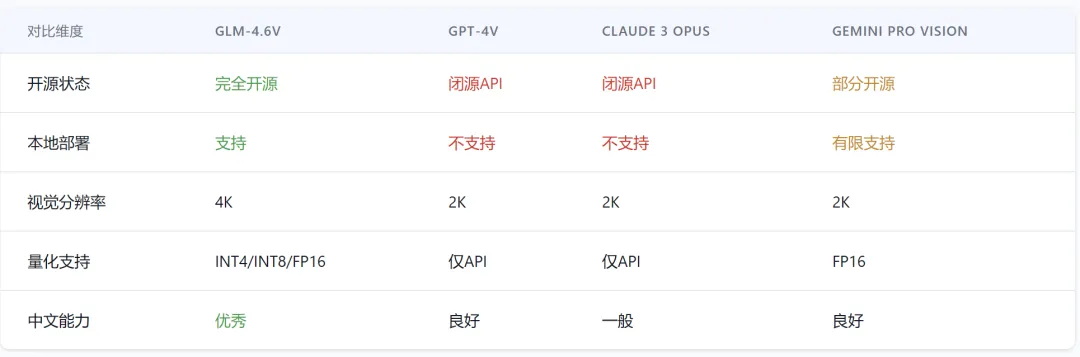
传统多模态模型在处理视觉任务时,往往需要将图像先转为文字描述,再进行后续处理,造成信息损失和工程复杂度。
GLM-4.6V的突破在于:
1、原生多模态工具调用:
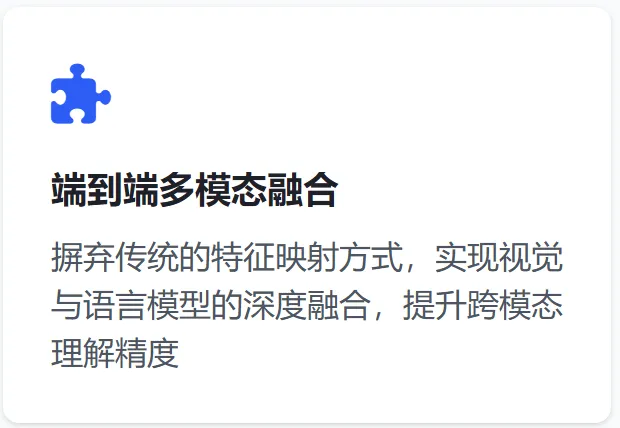
输入多模态(图像、截图、文档页面)可直接作为工具参数,无需文字转换
2、视觉-行动闭环
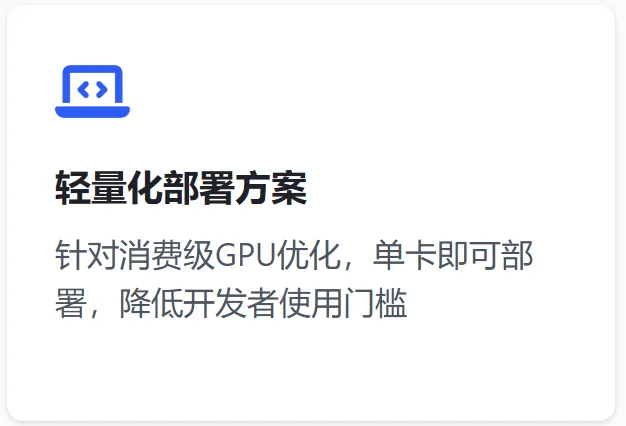
打通从"视觉感知"到"可执行行动"的链路,实现真正"看图即行动"
多模态输出能力:对工具返回的图表、截图等结果,模型能再次进行视觉理解
3、典型场景实践:
智能图文混排:输入主题,自动生成结构清晰的图文内容,无需额外处理图片
视觉驱动购物:上传商品图片,自动搜索同款并生成比价导购清单
前端复刻开发:上传网页截图,精准生成HTML/CSS/JS代码,支持多轮视觉交互修改
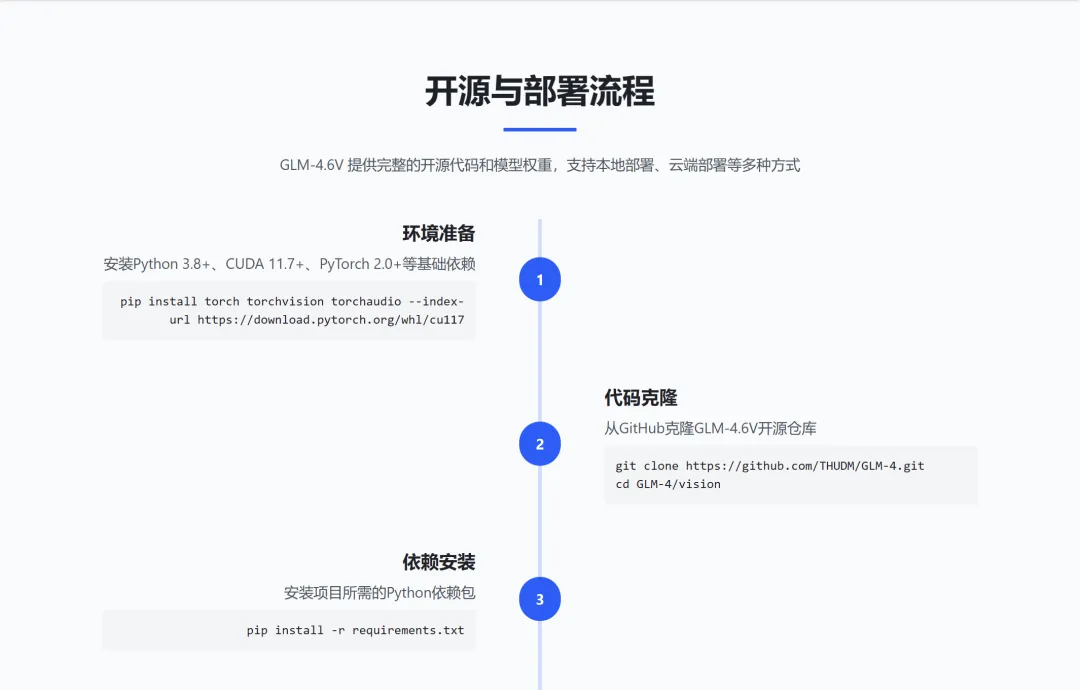
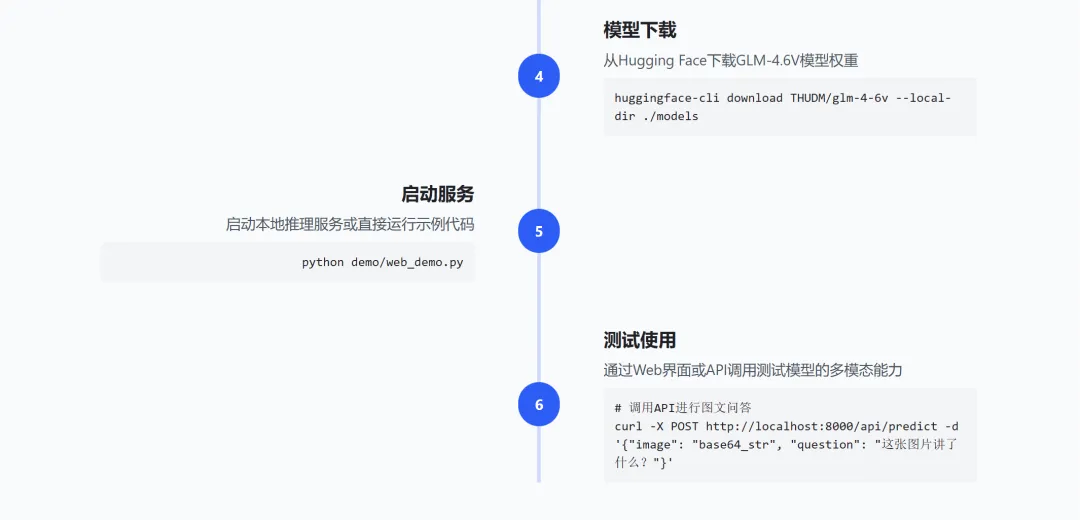
三、开源与部署
GLM-4.6V已全面开源,提供多种便捷部署方式:
GitHub开源:
https://github.com/zai-org/GLM-V
Hugging Face模型库:
https://huggingface.co/collections/zai-org/glm-46v
魔搭社区:
https://modelscope.cn/collections/GLM-46V-37fabc27818446
部署方式:
本地部署:下载代码和模型权重,在本地服务器运行
云端调用:通过智谱开放平台获取API密钥,调用云端模型
在线体验:访问z.ai或智谱清言APP/网页版,直接体验模型能力
应用集成:通过API或本地部署方式,将模型接入自有系统
GLM-4.6V的开源
不仅降低了多模态技术应用门槛,
更通过原生"行动多模态"能力,
让AI真正从"理解图片"走向"完成任务",
为内容创作、电商导购、前端开发等场景
带来革命性体验。
随着模型在更多国产芯片上的适配,
GLM-4.6V正推动国产AI生态迈向新高度。
即刻体验:https://chat.z.ai/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)