语言大模型的实现逻辑
大模型实现与差异解析 大模型实现分为6步:数据准备(海量高质量文本)、分词(文字转数字)、架构设计(Transformer自注意力机制)、预训练(自回归/掩码预测)、微调对齐(指令遵循与强化学习)、推理部署(工程优化)。核心难点包括数据质量、算力需求、长文本处理及对齐平衡。 模型效果差异源于5大因素:架构类型(GPT/BERT等)、参数规模、训练数据质量、训练策略(稳定性与推理能力)及微调对齐(安
你可以把它理解成:
“一个小孩如何成长为一个超级学霸”的全过程 + 学霸之间为什么水平不同的原因。
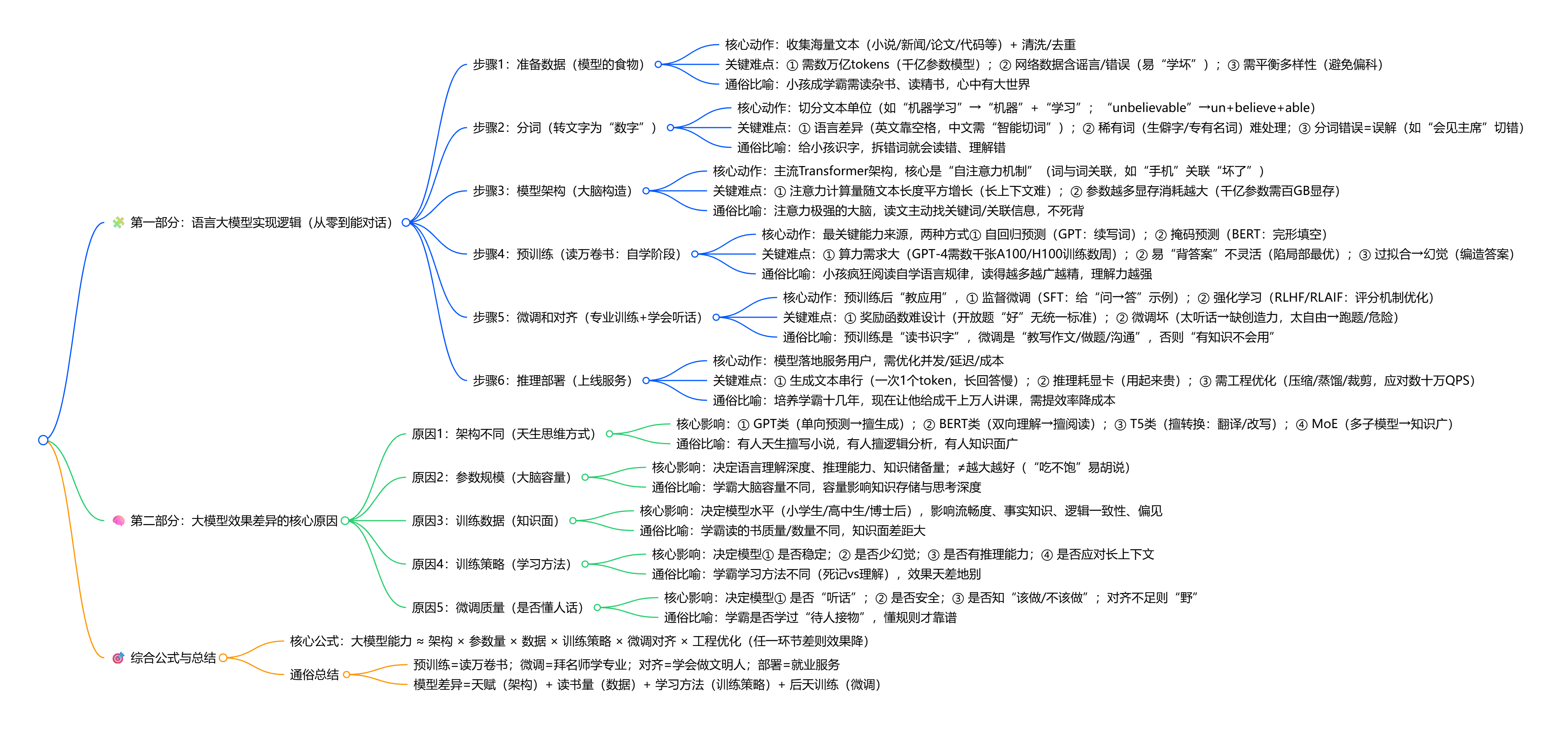
🧩 第一部分:语言大模型的实现逻辑(从零到能对话)
可以分成 6 个大步骤,每一步都有非常现实的难点,就像一个人从出生→上学→专业训练→就业。
步骤 1:准备数据(模型的食物)
👉 在做什么?
收集海量文本,比如:
- 小说、新闻、论文
- 维基百科
- 程序代码
- 网站对话
- 专业资料
然后对这些数据进行清洗、整理、去重。
❗ 难点
-
数据量巨大
- 一个千亿参数模型需要 数万亿 tokens,相当于把几十万本书合在一起读。
-
质量极难把控
- 网络数据里谣言、脏话、错误信息、重复数据很多
- 不清洗会让模型“学坏”
-
多样性要平衡
- 书读得太偏科(只读技术书或只看小说)都会导致模型能力不均衡
🧠 通俗比喻
“想让小孩成学霸,必须让 TA 既读文学又读科学,还要读历史、数学、艺术……读得杂、读得精,心中自然有大世界。”
步骤 2:分词(把文字拆成模型能读的“数字”)
👉 在做什么?
大模型不会直接读文字,它要把文字切成更小的单位再转成数字。
例子:
- “机器学习” → “机器” + “学习” (或更细:机/器/学/习)
- “unbelievable” → un + believe + able
❗ 难点
-
不同语言分词方式完全不同
- 英文靠空格
- 中文没有空格,需要“聪明地切词”
-
稀有词处理困难
- 生僻字、专有名词,需要再拆小
-
分词错误 = 直接影响理解
- “会见主席”如果被切成“会/见主/席”,模型会彻底误解意思
🧠 比喻
“分词就像给小孩识字,把文章拆成一个个字、词;拆错了,他就会读错、理解错。”
步骤 3:模型架构(大脑构造)
目前主流是 Transformer 架构,它解决了“语言需要考虑上下文”的难题。
核心机制:自注意力(Self-Attention)
让每个词都能意识到:
- “我应该关注句子中的哪些词?”
- “哪些词和我有关?”
例子:
“我昨天买的手机坏了”
模型会自动知道“手机”与“坏了”关联特别大。
❗ 难点
-
Attention 计算量随文本长度呈平方增长
- 文本越长,算力成倍暴涨
- 这是长上下文模型最困难的点
-
参数越多,大脑越大,但显存消耗也越可怕
- 千亿参数模型需要上百 GB 显存
- 单张显卡根本跑不动
🧠 通俗比喻
Transformer 就像是一个“注意力极强的大脑”,读文章时会主动寻找关键词、关联信息,而不是一个字一个字死背。
步骤 4:预训练(读万卷书:自学阶段)
这是模型能力的 最关键来源。
👉 常见两种方式
-
自回归预测(GPT 的方式)
- 给你前文,让你猜下一个词
- 像写作文时“续写一句话”
-
掩码预测(BERT 的方式)
- 挖掉几个词,让模型补全
- 像完形填空
❗ 难点
-
算力需求巨大
- GPT-4 级别模型,可能需要数千张 A100 或 H100,持续训练几周甚至几个月
-
优化难
- 模型容易“背答案”,但不会灵活运用
- 容易陷入局部最优(只会简单套路)
-
过拟合风险
- 背得太死 → 幻觉增多 → 编造答案
🧠 比喻
预训练就是小孩靠“疯狂阅读”自学语言规律。读得越多、越广、质量越高,理解力越强。
步骤 5:微调和对齐(专业训练 + 学会听话)
预训练后模型只是“知识丰富的中学生”,但不一定:
- 会聊天
- 会遵守规则
- 会按照指令办事
👉 需要两类训练
-
监督微调(SFT)
- 给它大量“问 → 答示例”
- 让模型学会按照人类意图回答
-
强化学习(RLHF / RLAIF)
- 用回合制评分机制,让模型逐渐学会“更好、更安全、更有逻辑地回答”
❗ 难点
-
奖励函数难设计
- 对开放回答题,什么叫“好”?
- 人类都难达成一致
-
容易微调坏(Alignment Tax)
- 太听话 → 创造力降低
- 太自由 → 容易跑题、输出危险内容
🧠 比喻
把预训练当成“读书识字”,微调就是“教你写作文、教你做题、教你如何与人沟通”,否则只是“知识很多但不会用”。
步骤 6:推理部署(真正上线使用)
模型训练完,要在真实场景中服务用户。
👉 难点
-
生成文本是串行的
- 一次只生成一个 token
- 长回答就慢
-
推理也很耗显卡
- 不只是训练难
- 用起来也贵
-
并发、延迟、成本都要优化
- 企业应用需要数十万 QPS
- 必须做模型压缩、蒸馏、裁剪等工程优化
🧠 比喻
这就像“你培养一个学霸花了十几年,现在要让他每天给成千上万人讲课”,成本非常高,需要想办法提高效率。
🧠 第二部分:为什么不同大模型效果差异这么大?(根本原因)
效果差异来自 5 个核心维度:
原因 1:架构不同(天生的思维方式不同)
- GPT 类:单向预测 → 更擅长生成
- BERT 类:双向理解 → 更擅长阅读理解
- T5 类:专长在“转换”任务(翻译、改写、摘要)
- MoE(专家混合):多个子模型合作 → 涵盖更广的知识
比喻
就像有人天生擅长写小说,有人擅长逻辑分析,有人知识面特别广。
原因 2:参数规模(大脑容量)
大小决定:
- 语言理解深度
- 推理能力
- 知识储备量
但不是越大越好,吃不饱的大脑只会“胡说八道”。
原因 3:训练数据(知识面)
决定模型像“小学生”“高中生”还是“博士后”。
影响:
- 语言流畅度
- 事实知识
- 逻辑一致性
- 是否容易产生偏见
原因 4:训练策略(学习方法)
不同方法会导致:
- 是否稳定
- 是否容易出现幻觉
- 是否能学到推理能力
- 是否能应对长上下文
原因 5:微调质量(是否听得懂人话)
决定:
- 是否“听话”
- 是否安全
- 是否知道“什么该做”“什么不该做”
很多模型数据量大,但对齐不足,就显得很“野”。
🎯 综合公式(非常准确)
大模型能力 ≈ 架构 × 参数量 × 数据 × 训练策略 × 微调对齐 × 工程优化
任何一个环节差一些,最终效果都会明显下降。
🎉 结尾总结(更通俗)
- 预训练是“读万卷书”
- 微调是“拜名师学专业”
- 对齐是“学会做文明人”
- 部署是“就业并提供服务”
- 各模型差异来自“天赋 + 读书量 + 学习方法 + 后天训练”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)