零成本部署一个简单AI海报生成工具
本项目是一个基于Qwen-plus和Qwen-image-plus模型的AI生图工具实验,用于课程报告研究模型协同中的伦理问题。开发重点在于快速构建免费可用的简易工具,代码主要依赖大模型生成。文章详细介绍了在HuggingFace Space上部署的完整流程,包括创建Space、文件配置、密钥设置等关键步骤。工具支持提示词迭代优化,但存在中文渲染错误、结果随机性不足等问题。项目提供三个分支版本:稳
介绍
该项目是本人为课程报告所做的一个简单实验,构建了一个使用qwen-plus+qwen-image-plus将用户输入的初始提示词转化为海报的简单工具,用于探索模型协同中的伦理问题。因为是一个简单的课程实验,本人开发时主要考虑免费和快捷,该教程面向同样有快速开发出一个可用的、功能明确的简单AI生图工具的学生和开发者。
本项目中的代码主要利用大模型生成,无重要参考价值。
本文会给出一个构建项目的完整流程,帮助想要实现相同或类似工具的开发者快速实现。工具所使用的模型,可以按需任意更改为其他你想使用的模型(但建议根据你使用生图模型设计提示词迭代优化过程)。
注意:使用前建议查看本文最后一章“实际效果”中的效果和现存问题部分,避免浪费你的免费token额度。
本项目代码仓库:https://github.com/defzi-l/SynthPoster
Live Demo:https://huggingface.co/spaces/Y-ris/SynthPoster(该工具应该可以正常使用到本人的免费token额度用完为止,当免费额度用尽后,线上Demo将因API调用失败而无法生成图片。因为千问image一共只提供100次免费额度,测试本工具功能时请不要多次生成)
本项目的一个初期参考:【Hugging Face实战】使用Gradio创建一个文生图应用 - misterz的文章 - 知乎https://zhuanlan.zhihu.com/p/1937805941891375894
创建Space
- 创建HuggingFace账号,在页面首页导航栏选择Space,点击右上角的New Space,或者点击用户头像点击下拉栏中的New Space。
- Space SDK选择Gradio。
- template可选可不选,可以选择text-to-image参考一下。
- hardware选择免费的CPU basic。
这里以选择了text-to-image template的情况为例。Space创建后会自行启动一次,缓慢的启动结束后能看到一个简单的图像生成页面,右下角会弹出git的使用指南。
右上角点击Files查看现有的文件:

可以看到模版初始有四个文件,比较容易踩坑的是Space项目的README.md文件要求在文件开头必须包含一些项目配置信息,配置信息的写法参考template和SynthPoster的README或官方文档即可。
requirements.txt文件是python项目的依赖管理文件,当初次加载或该文件发生变化时,Space会在Building阶段自动进行依赖下载或删除。
注意: 每一次上传或更改文件,Space都会完整进行一次Build到Start的过程,该过程比较缓慢,如果时间有限的情况下请尽量先确认依赖或执行代码的正确性再上传。
注:理论上该项目可以本地运行,不过本人没有尝试过。想要本地运行也可以参照项目仓库的README,不过不保证能运行成功就是了~
文件上传
Space可以与github仓库相关联,也支持直接上传文件(同名文件自动替换)或在线修改。SynthPoster开发过程中采用的是先在Space上测试通过后再将代码上传到Github,所以没有进行与Github的关联。可以依情况自行选择。
上传时直接点击Files界面右上角的Contribute、Upload files,传入需要上传的文件本身即可,不需要先将文件压缩为zip。
配置秘钥
在Space中点击右上角的Settings,进去下拉找到Variables and Secrets,按需配置即可。Settings中还可以更换所使用的Hardware,不过免费的只有CPU basic。
项目中需要配置的只有app.py中的3个环境变量:
# ==================== 1. 从环境变量加载设置 ====================
load_dotenv()
# 从环境变量读取,如果不存在则使用空字符串(防止报错)
LLM_API_KEY = os.getenv("LLM_API_KEY", "")
LLM_BASE_URL = os.getenv("LLM_BASE_URL", "")
LLM_MODEL_NAME = os.getenv("LLM_MODEL_NAME", "qwen-max") # 使用兼容的默认模型
# 检查关键密钥是否已设置
if not LLM_API_KEY:
raise ValueError("请在 .env 文件或环境变量中设置 'LLM_API_KEY'")
# 初始化LLM模型
llm = ChatOpenAI(
model=LLM_MODEL_NAME,
openai_api_key=LLM_API_KEY,
openai_api_base=LLM_BASE_URL if LLM_BASE_URL else None,
temperature=0.7,
)
dashscope.api_key = LLM_API_KEY请填入自己在所使用的模型官方获取的API key和Base_url,注意填入密钥时不要有多余的空格和换行符,否则会调用失败。如果API调用不成功,可以使用项目仓库中的with_network_and_api_test分支代码,进行网络连接和API连接测试。
注意: 在requirements.txt中加入python-dotenv。
查看调试信息
点击Space页面左上角的Logs可查看日志信息,建议把一些重要内容打印在这里方便调试代码。
创建本地项目
可以直接从Github拉取本项目代码,或自己新建。
对于希望快速搭建成功的开发者,直接使用main分支的代码即可,使用前建议阅读README.md。
实际效果
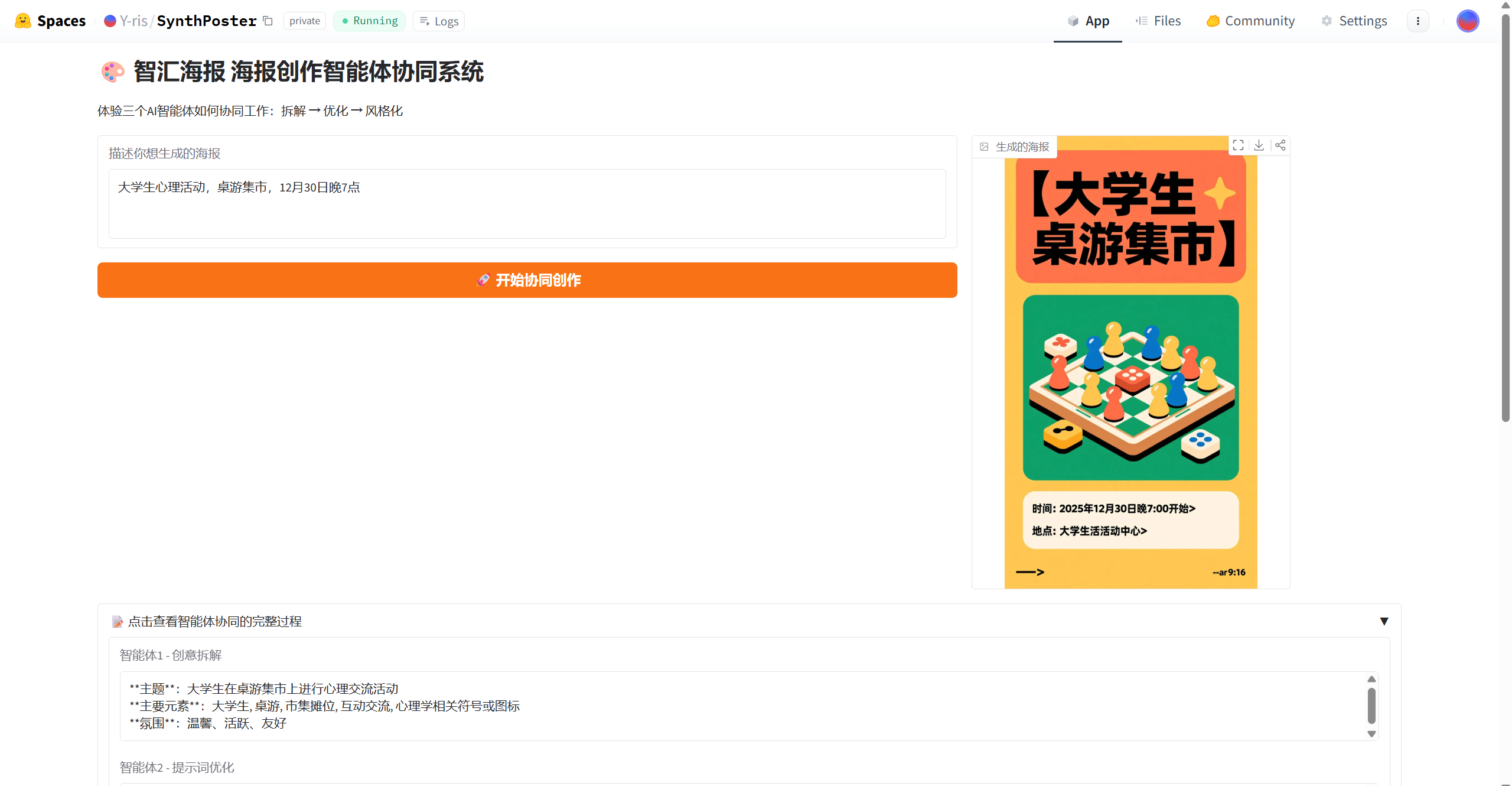
这里给出一个生成结果作为案例。
通过使用一些免费领取的token额度或一些免费公开的模型,该工具的构建可以做到完全免费(有时需要牺牲一些性能),对于需要进行类似实验的学生而言可以作为一个参考。
现存问题
- 虽然设置了3个提示词迭代步骤,但是第三个智能体并没有使用前2个智能体生成的结果,之后如果有机会会修复这个问题。
- 提示词迭代部分生成的结果随机性不足。
- 最终的图片结果常常存在中文汉字的输出错误(英文暂时未测试),在部分开源图像生成模型中,准确渲染中文仍是一个挑战。一个可能的修复方式是再接入第三个模型(例如千问的image-edit)对海报中的错误进行处理。
附
项目工具链
- 智能体框架:langchain
- 文本处理:qwen-plus
- 图像生成:qwen-image-plus
- 运行平台:HuggingFace Space
- 图形化界面:Gradio
一些版本介绍
项目代码仓库主要有以下3个分支版本:
| 分支名称 | 主要特点与目的 | 状态与备注 |
| main | 稳定可用版本。当前分支,集成了 qwen-max (LLM) 和 qwen-image-plus (生图) 的完整工作流。 | 生产环境推荐。功能完整,提示词经过优化,界面简洁。 |
| with_network_and_api_test | 开发调试版本。在main分支基础上,额外集成了网络诊断和API连通性测试功能。 | 供开发者使用。帮助快速验证API配置和网络环境,功能稳定,界面包含调试面板。 |
| feat/llm-qwen-sd-local | 实验与低成本版本。使用 qwen-max (LLM) + stabilityai/sd-turbo (生图) 的架构。 | 存档/实验分支。利用Hugging Face免费推理API节省资源,但生成效果和质量显著低于 qwen-image-plus。提示词未针对SD模型优化,且保留网络测试代码。 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)