基于 LangChain 与 DeepSeek-R1 的本地知识库问答系统
本文介绍了一个基于DeepSeek-R1模型和LangChain框架的本地知识库问答系统实现方案。该系统通过Ollama框架管理本地大语言模型,利用Chroma向量数据库存储PDF文档的向量化表示,构建了完整的检索增强生成(RAG)流程。项目实现了从环境配置、模型加载、文档处理到问答交互的全过程,特别强调了本地化部署在数据安全和成本控制方面的优势。通过Gradio提供的Web界面,用户可直接与本地
·
一、项目背景
随着大模型在自然语言处理领域的广泛应用,企业和个人对本地化、私有化的知识问答需求越来越强烈。相比依赖在线大模型,本地知识库问答系统具有以下优势:
- 数据安全:文档保存在本地,避免敏感信息上传至第三方。
- 成本可控:无需持续调用云端 API。
- 可扩展性强:可以自由替换模型和知识库。
本项目的目标是:
利用 DeepSeek-R1 模型和 LangChain 框架,结合 Chroma 向量数据库,实现一个基于 PDF 文档的本地知识库问答系统,并通过 Gradio 提供简洁的交互界面。
二、环境准备与模型安装
1.创建开发环境
选择单卡4090套餐并自定义容器端口。

2. 安装 Ollama
Ollama 是一个轻量级框架,用于在本地管理和运行大语言模型(如 LLaMA、DeepSeek-R1 等)。这里我们先通过脚本安装 Ollama。
curl -fsSL https://ollama.com/install.sh | sh3. 启动 Ollama 服务
该命令会在本地启动 Ollama 的服务进程,后续我们才能调用模型。
ollama serve4.下载 DeepSeek-R1 模型
这里选择了 deepseek-r1:7b 作为推理模型。你也可以替换成更大或更小的版本。
ollama pull deepseek-r1:7b5. 安装依赖库
- langchain:核心框架,用于构建检索增强生成(RAG)流程
- chromadb:轻量化向量数据库
- gradio:提供可视化 Web 界面
- pypdf:PDF 文件解析工具
- langchain-ollama:LangChain 与 Ollama 的对接组件
pip install langchain chromadb gradio pypdf ollama -U langchain-community langchain-ollama pypdf三、知识库构建
6. 加载与切分文档
这里加载了 智算业务介绍.pdf 文档,并将其切分成小片段,保证后续向量化和检索的效果。
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载 PDF
loader = PyPDFLoader("/workspace/智算业务介绍.pdf")
docs = loader.load()
# 切分
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = splitter.split_documents(docs)7. 构建向量数据库
- 使用 OllamaEmbeddings 将文本转为向量表示。
- Chroma 作为向量数据库存储切分后的文档片段。
- 数据会持久化到 ./chroma_db 目录中。
from langchain_ollama import OllamaEmbeddings
from langchain.vectorstores import Chroma
embeddings = OllamaEmbeddings(model="deepseek-r1:7b")
db = Chroma.from_documents(documents, embeddings, persist_directory="./chroma_db")8. 构建检索问答链
- 定义了 LLM(使用 DeepSeek-R1 模型)。
- 设置检索器,每次返回最相关的 3 个文档。
- 构建 RetrievalQA,实现基于检索的问答(RAG)。
from langchain.chains import RetrievalQA
from langchain_ollama import OllamaLLM
llm = Ollama(model="deepseek-r1:7b")
retriever = db.as_retriever(search_kwargs={"k": 3})
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type="stuff"
)四、问答示例
9. 输入问题并得到回答
query = "请介绍一下我国算力未来发展"
result = qa_chain.invoke(query)
print(result){'query': '请介绍一下我国算力未来发展', 'result': "<think>\n嗯,我需要回答关于我国算力未来发展的介绍。首先,我要理解“算力”是什么。算力应该是指计算能力,特别是在人工智能和大数据处理方面的重要性。然后,我可以参考提供的上下文。\n\n上下文中提到“智算平台建设”,这可能涉及到国家对算力发展的规划。接着,我看到 mentions the National Development and Reform Commission (NCDR) in 2017 rising it to a national strategy, indicating a strategic shift towards using computation as part of the nation's development plans.\n\n还有提到安徽省智能算力规模的目标:2023年达到5000P,2024年达到12000P。这里的“P”应该代表 Pete,即千万亿次运算,所以数字很大,说明目标很明确且有时间表。\n\n此外,内容从技术到产业再到基础设施的演进逻辑,这可能意味着国家不仅关注技术创新,还注重整个产业链的发展和基础设施的支持,比如硬件、网络等。\n\n我还需要考虑算力在各个领域中的应用,如人工智能、大数据分析、5G通信等领域,这些都需要强大的计算能力来支持。因此,算力发展将推动这些领域的技术进步和发展。\n\n另外,可能还需要提到算力对经济增长和社会发展的促进作用,比如提高生产效率、优化资源配置等,从而实现经济和科技的可持续发展。\n\n综上所述,我需要整合以上信息,清晰地介绍我国算力未来发展的重要性和具体规划。\n</think>\n\n我国算力未来发展的规划和目标可以从以下几个方面进行介绍:\n\n1. **战略提升**:从2017年开始,国家将计算能力提升至国家战略层面,体现了其在技术创新中的重要性。这一决策不仅指导了技术研究,还推动了整个产业的发展。\n\n2. **目标明确**:安徽省设定的目标显示了算力发展的具体方向和时间节点。到2023年达到5000P,2024年提升至12000P,表明了我国在算力领域的 ambitious 长期发展目标。\n\n3. **技术演进与产业沉淀**:算力的发展不仅是技术创新的推动,更是对整个产业链的支持。从技术层面到产业应用,再到基础设施的完善,显示出系统性规划和长远发展的思路。\n\n4. **多领域驱动**:算力在人工智能、大数据、5G通信等多个领域的应用需求,将 drives 各个行业的技术升级和创新,促进经济和社会的整体发展。\n\n综上所述,我国算力未来的演进和发展将为科技与产业带来深远影响,推动经济和科技进步,实现可持续发展。"}
五、扩展:搭建交互界面
可以加入 Gradio 界面,方便用户通过浏览器交互使用问答系统,例如:
import gradio as gr
def chat(query):
return qa_chain.run(query)
iface = gr.Interface(
fn=chat,
inputs=gr.Textbox(label="输入问题", lines=2),
outputs=gr.Textbox(label="回答", lines=8, max_lines=20, scale=2), # 调整高度和宽度比例
title="企业知识库问答",
theme=gr.themes.Soft() # 可选:使用内置主题
)
iface.launch(server_name="0.0.0.0", server_port=7860)/opt/conda/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm * Running on local URL: http://0.0.0.0:7860 * To create a public link, set `share=True` in `launch()`.
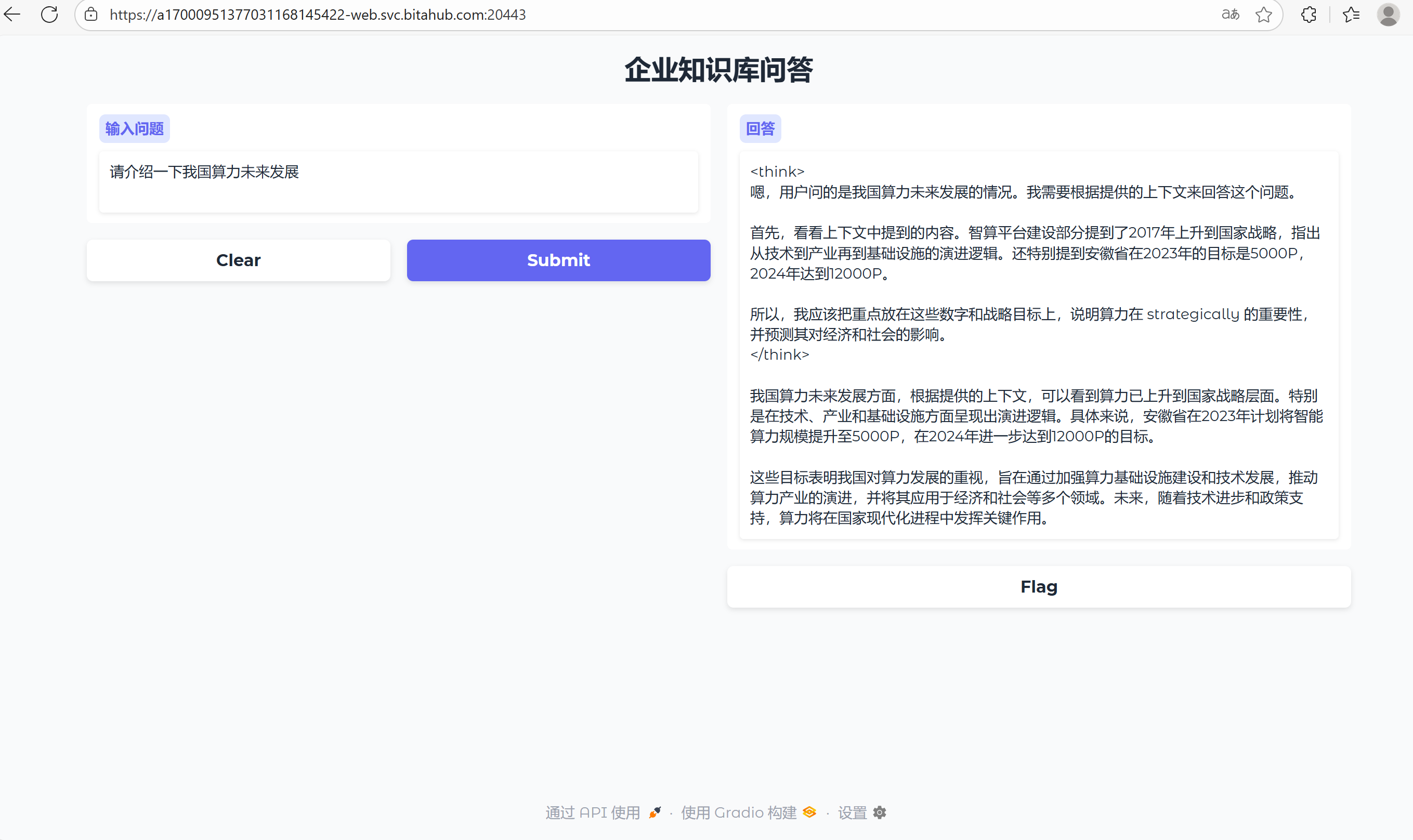
这样用户就可以在网页中输入问题,直接获取答案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)