以科技创新推动产业创新专题 | HiMo-CLIP入选AAAI 2026 Oral,联通元景突破跨模态对齐瓶颈
然而,作为连接图像与文本的“桥梁”,传统的CLIP(Contrastive Language-Image Pre-training)模型在面对复杂、多细节的长文本描述时,却常出现一个怪象:描述越丰富,图文匹配反而越差。将持续深化多模态对齐技术的创新与应用,攻克多模态理解中复杂语义结构建模的"关键一环",让具备认知一致性的AI模型在智能客服、医疗影像分析、教育内容生成、电子商务和工业质检等更多场景中
近日,来自Google的Gemini 3掀起了新一轮的多模态技术浪潮,“读图”与“长文本理解”已成为衡量AI智商的核心标准。然而,作为连接图像与文本的“桥梁”,传统的CLIP(Contrastive Language-Image Pre-training)模型在面对复杂、多细节的长文本描述时,却常出现一个怪象:描述越丰富,图文匹配反而越差。
与此同时,中国联通数据科学与人工智能研究院在这一领域取得重要进展,提出全新视觉语言对齐框架HiMo-CLIP,通过创新性建模语义层级与单调性,在不修改编码器架构的前提下,实现了长文本、短文本场景的全维度性能突破。相关论文已入选国际人工智能顶会AAAI 2026 Oral(总投稿量23680篇,录用率为17.6%,其中Oral录用率仅约3.5%)。目前,量子位、CVer、AI思想会、我爱计算机视觉等媒体均对该成果进行了报道。
关于 AAAI
AAAI人工智能会议(AAAI Conference on Artificial Intelligence)是人工智能领域历史最悠久、覆盖范围最广的国际顶级学术盛会之一。其学术权威性备受认可,被中国计算机学会(CCF)、中国自动化学会(CAA)及中国人工智能学会(CAAI)共同评定为A类会议。

论文入选
问题溯源:CLIP的“扁平化”瓶颈
传统CLIP模型在处理文本时,往往把句子当作“一锅粥”,不能在复杂的上下文中捕捉到最具区分度的特征。这将导致两个典型问题:语义层级和语义单调性的缺失。
例如,一张“白色福特F250”的图片,若描述从“一辆白色卡车”逐步扩展为“带有超大轮胎、可见车轴、染色车窗的白色福特F250”,理想情况下模型应该越来越确信这是一张匹配的图片。但现有模型往往做不到这一点。
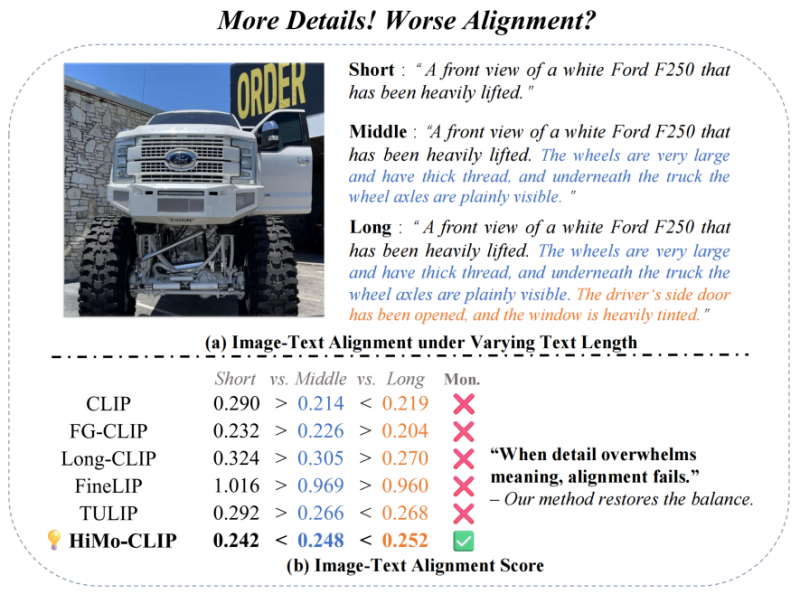
随着描述变长,现有模型分数下降,而HiMo-CLIP(绿勾)稳步提升
HiMo-CLIP:两大创新,让AI“越看越懂”
HiMo-CLIP提出了两个核心组件,由此让模型具备了“分层理解”和“越详细越匹配”的能力:
层次化解构(HiDe):使用批次内主成分分析(PCA),动态提取文本中的关键语义成分,让模型能根据上下文自适应聚焦不同层次的语义信息。比如在同一批数据中,有时“福特F250”是关键,有时“染色车窗”更关键。
单调性感知对比损失(MoLo):设计双分支对齐目标,一个分支保持全局图文对齐,另一个分支将图像与HiDe提取出的关键语义成分对齐。通过联合优化,模型自然而然地学会“文本越完整,对齐分数越高”的单调性规律。
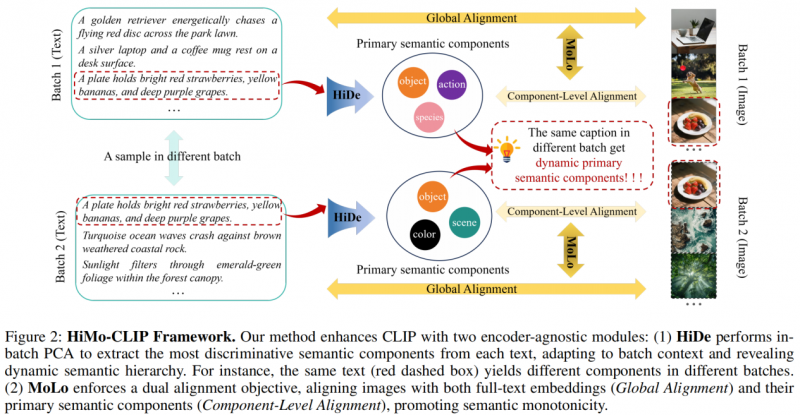
HiMo-CLIP框架概览
实验结果:全场景性能碾压主流基线
HiMo-CLIP在多个经典的长文本、短文本检索基准,以及自行构造的深度层级数据集HiMo-Docci上进行了广泛实验。
在长文本(表1)和短文本(表2)检索任务上,HiMo-CLIP展现出了显著的优势。值得注意的是,HiMo-CLIP仅使用了1M(一百万)的训练数据,就击败了使用100M甚至10B数据的现有方法(如LoTLIP,SigLIP等),并在多个数据集上刷新SOTA。
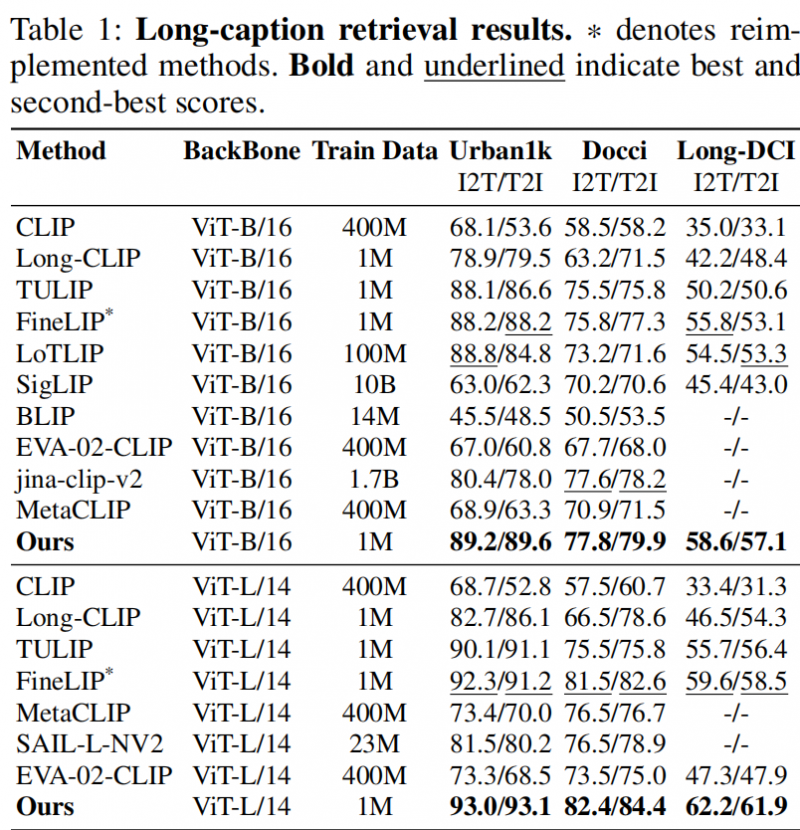
表1 长文本检索结果
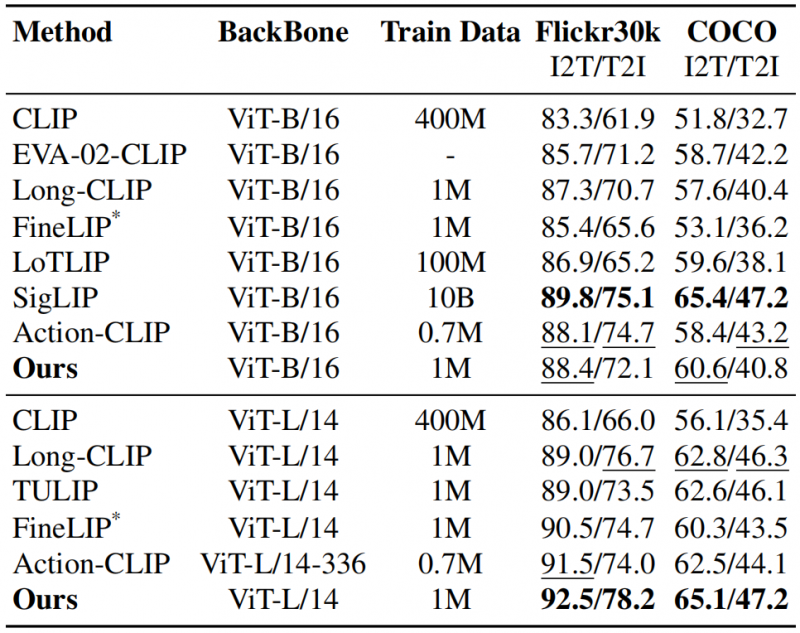
表2 短文本检索结果
为系统评估语义单调性,中国联通数据科学与人工智能研究院提出了HiMo@K指标,用于衡量模型在文本逐步完整时对齐分数是否单调递增。还通过可视化方式,展示了不同方法的语义单调性表现。现有方法经常出现“细节增加但匹配度下降”的反直觉现象,而HiMo-CLIP则始终维持稳定递增的匹配趋势,完美符合人类认知。
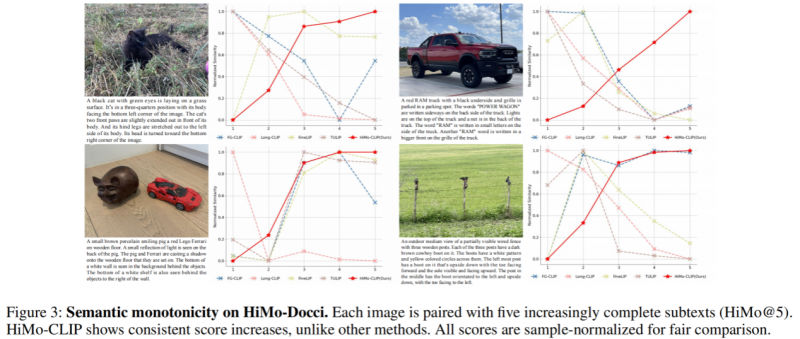
HiMo-Docci上的单调性可视化
HiMo-CLIP的提出标志着多模态学习从“扁平化”向“结构化”的重要转变。正如论文中所强调:“对齐跨模态表示的多个语义抽象层次,对鲁棒且符合认知的视觉-语言理解至关重要。”这一突破不仅提升了长文本检索性能,更为AI系统理解人类语言的丰富层次结构铺平了道路,让机器真正“看懂”我们描述的世界。
未来,中国联通数据科学与人工智能研究院将持续深化多模态对齐技术的创新与应用,攻克多模态理解中复杂语义结构建模的"关键一环",让具备认知一致性的AI模型在智能客服、医疗影像分析、教育内容生成、电子商务和工业质检等更多场景中发挥核心价值,推动多模态智能技术向更智能、更可靠、更贴近人类认知的方向发展。
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献425条内容
已为社区贡献425条内容

所有评论(0)