AI的早期探索在哪里?
开源AI模型应用呈现显著趋势:角色扮演(52%)和编程辅助是两大主导领域,合计占大部分使用量。中国开源模型在编程支持方面表现突出,但国际开源模型份额正快速增长。数据显示,用户需求高度集中于特定任务,如角色扮演中的虚构对话和编程中的代码生成,而其他领域如科学、法律等使用较为分散。专有模型虽在商业任务占优,但开源模型在创意和技术领域已确立优势地位,反映出开发者更倾向选择当前性能最佳的开源方案。
原文 https://openrouter.ai/state-of-ai
总体而言,在整个开源生态系统中,关键用例包括:
- 角色扮演和创意对话:顶级类别,很可能是因为开放模型可以不受审查或更容易为虚构角色和故事任务进行定制。
- 编程辅助:第二大类别,并且不断增长,因为开放模型在编码方面变得更加强大。许多开发者在本地利用开源模型进行编码,以避免 API 成本。
- 翻译和多语言支持:一个稳定的用例,尤其是在有强大的双语模型可用时(中国开源模型在这方面具有优势)。
- 通用知识问答和教育:中等程度的使用;虽然开放模型可以回答问题,但用户可能更喜欢像 GPT-5 这样的闭源模型以获取最高的事实准确性。
如今,开源模型被用于极其广泛的任务范围,涵盖创意、技术和信息领域。虽然专有模型仍在结构化业务任务中占主导地位,但开源模型在两个特定领域确立了领导地位:创意角色扮演和编程辅助。这两个类别合计占据了开源 token 使用量的大部分。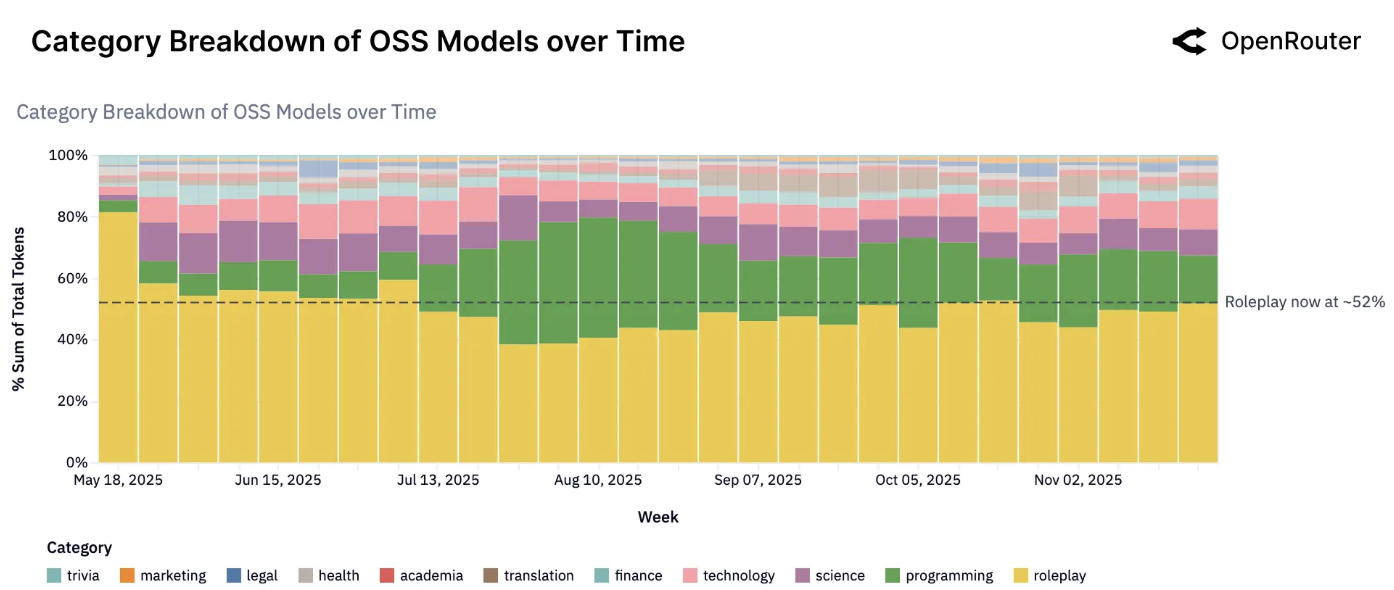
开源模型类别趋势。开源模型使用量在高级任务类别中的分布。角色扮演(约52%)和编程持续主导着开源工作负载组合,合计占开源 token 的大部分。较小的部分包括翻译、通用知识问答等。
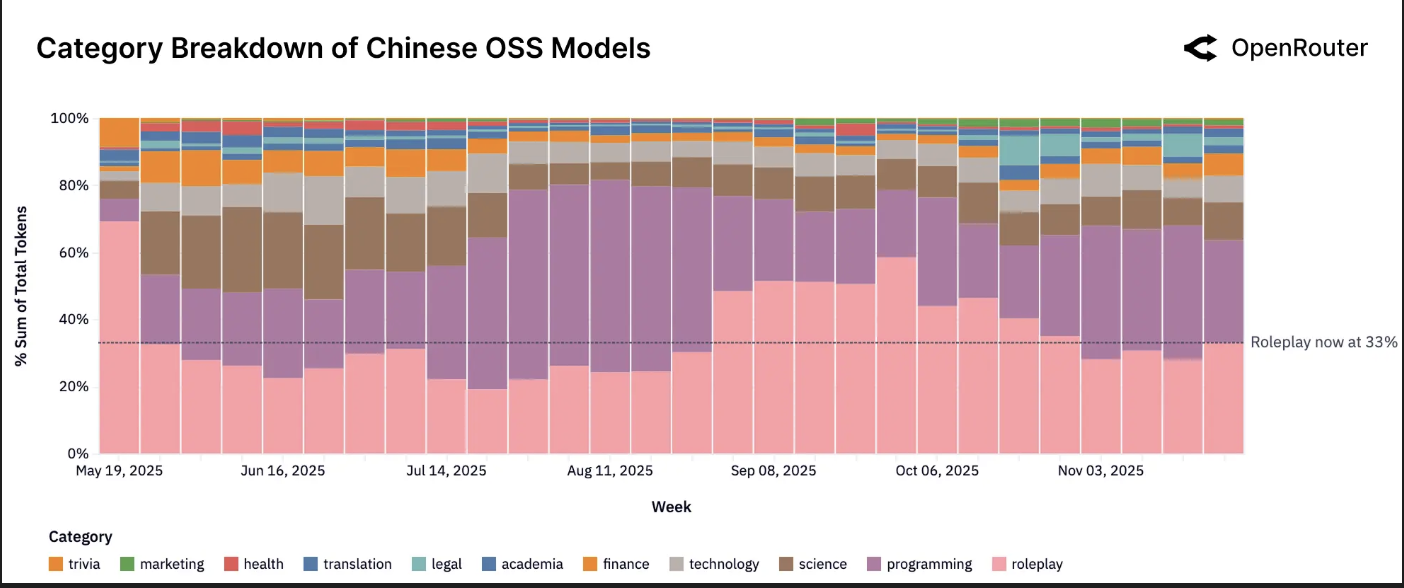
中国开源模型类别趋势。中国开发的开源模型使用类别构成。角色扮演仍然是最大的单一用例,尽管编程和技术类别在此处的合计占比高于整体开源模型组合(分别为33%和38%)。
主导类别
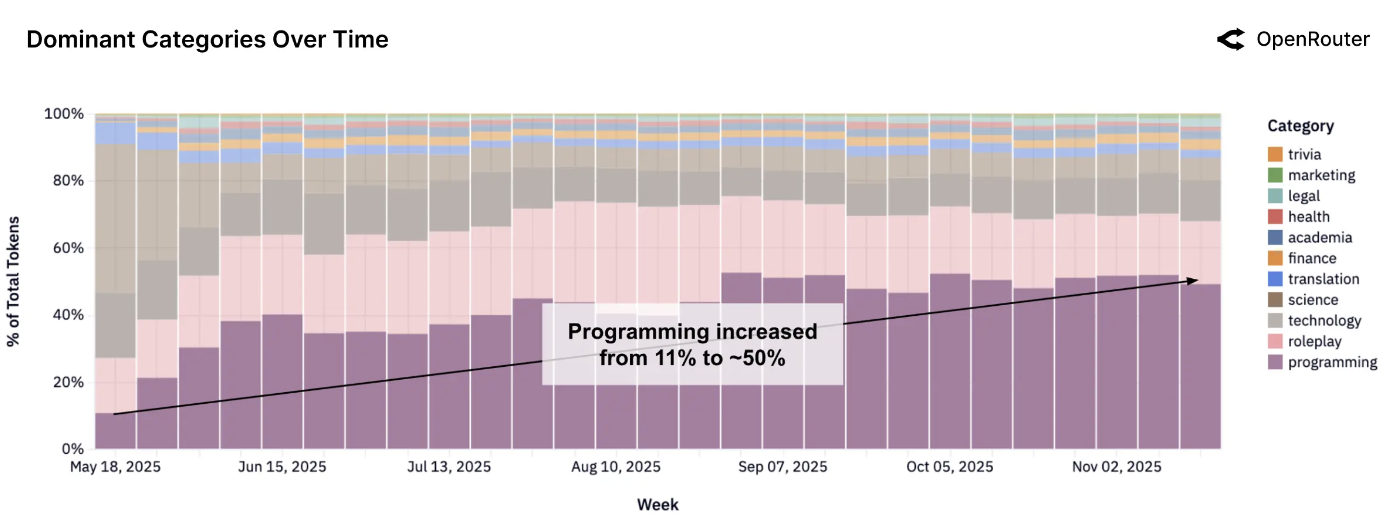
编程作为主导且不断增长的类别。归类为编程的所有大语言模型查询份额稳步增长,反映了人工智能辅助开发工作流的兴起。
对编程支持日益增长的需求正在重塑模型提供商之间的竞争格局。如下图所示,Anthropic 的 Claude 系列持续主导着该类别,在观测期的大部分时间里占据了编程相关支出的60%以上。然而,格局已经发生了有意义的变化。在11月17日当周,Anthropic 的份额首次跌破60%的门槛。自7月以来,OpenAI 的份额从约2%扩大到最近几周的约8%,这可能反映了其重新强调以开发者为中心的工作负载。同期,Google 的份额保持稳定在约15%。中端市场也在变动中。包括 Z.AI、Qwen 和 Mistral AI 在内的开源提供商正在稳步获得用户心智份额。尤其是 MiniMax,已成为快速崛起的进入者,在最近几周显示出显著增长。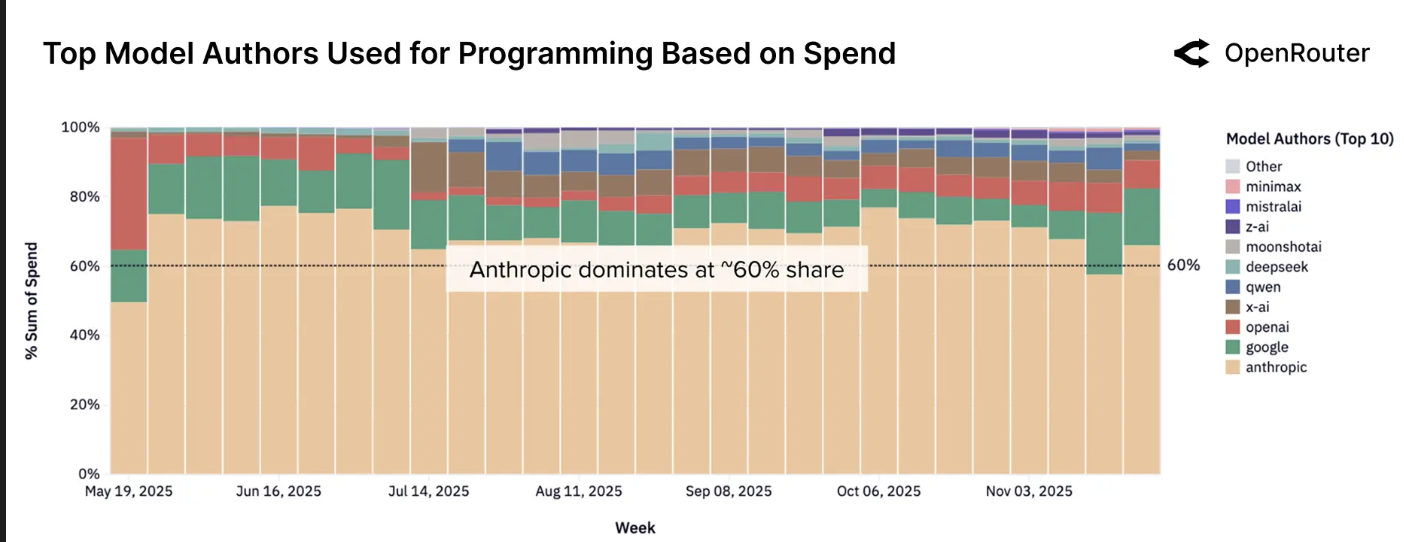
编程
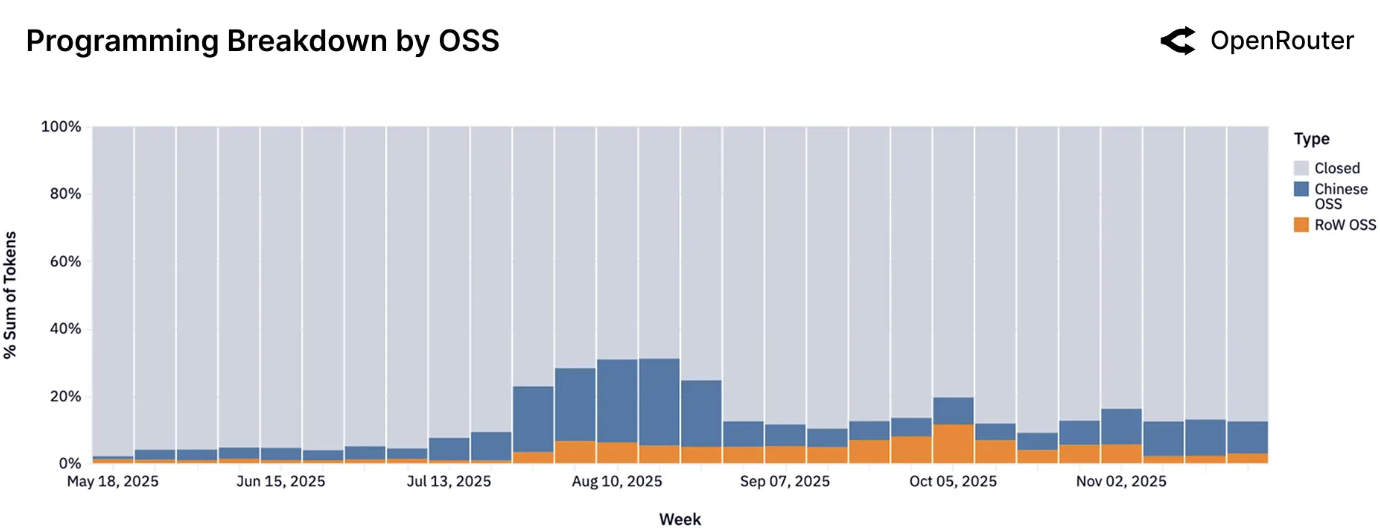
按模型来源划分的编程查询。由专有模型、中国开源模型与非中国(世界其他地区)开源模型处理的编程相关 token 量份额。在开源模型部分内部,平衡在2025年底明显向世界其他地区开源模型倾斜,其现在占所有开源编码 token 的一半以上(而在早期,中国开源模型曾主导开源编码使用量)。
实际的启示是,开源代码助手的使用是动态的,并且对新模型质量高度敏感:开发者乐于采用当前能提供最佳编码支持的任意开源模型。作为一个局限性,此图未显示绝对数量:开源编码使用量总体是增长的,因此蓝色部分的缩减并不意味着中国开源模型失去了用户,只是相对份额下降。
角色扮演
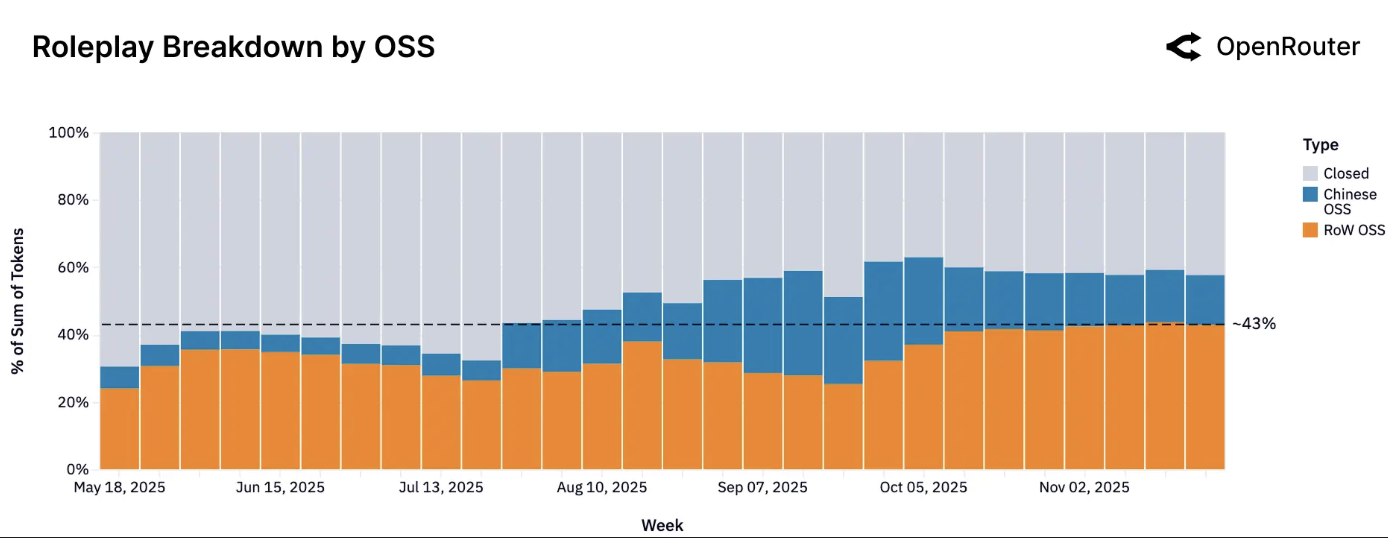
按模型来源划分的角色扮演查询。角色扮演用例的 token 量,按中国开源模型和世界其他地区开源模型划分。角色扮演对两个群体来说都是最大的类别;到2025年底,流量大致平均分配在中国和非中国开源模型之间。
由此产生的趋同表明了一种健康的竞争;用户在创意聊天和讲故事方面,从开源和专有产品中都有可行的选择。这反映出开发者认识到市场对角色扮演/聊天模型的需求,并为此调整了他们的发布策略(例如,对对话进行微调,增加对齐以确保角色一致性)。需要注意的是,"角色扮演"涵盖了一系列子类型(从休闲聊天到复杂的游戏场景)。然而,从宏观角度来看,开源模型在这个创意领域具有优势是显而易见的。
其他
之前有同学留言反映没理解在这个分类下role play有哪些内容,我们来看,游戏/角色扮演——最近coscon2025峰会上有很多学生把我的世界和大模型链接起来的尝试,另外一方面是读书和技术写作。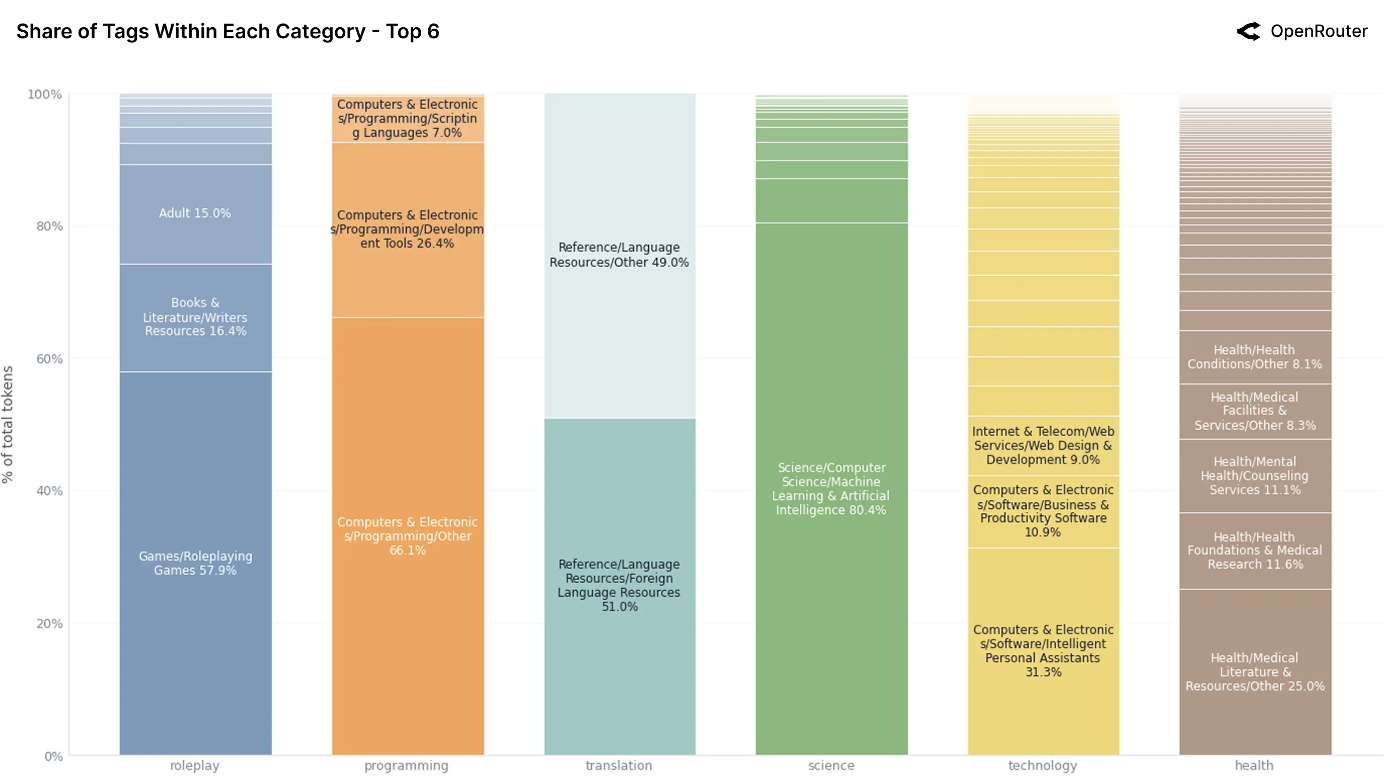
按token总份额排名前6的类别。每个条形图显示了该类别内主要子标签的细分。标签表示对该类别贡献至少7% token 的子标签。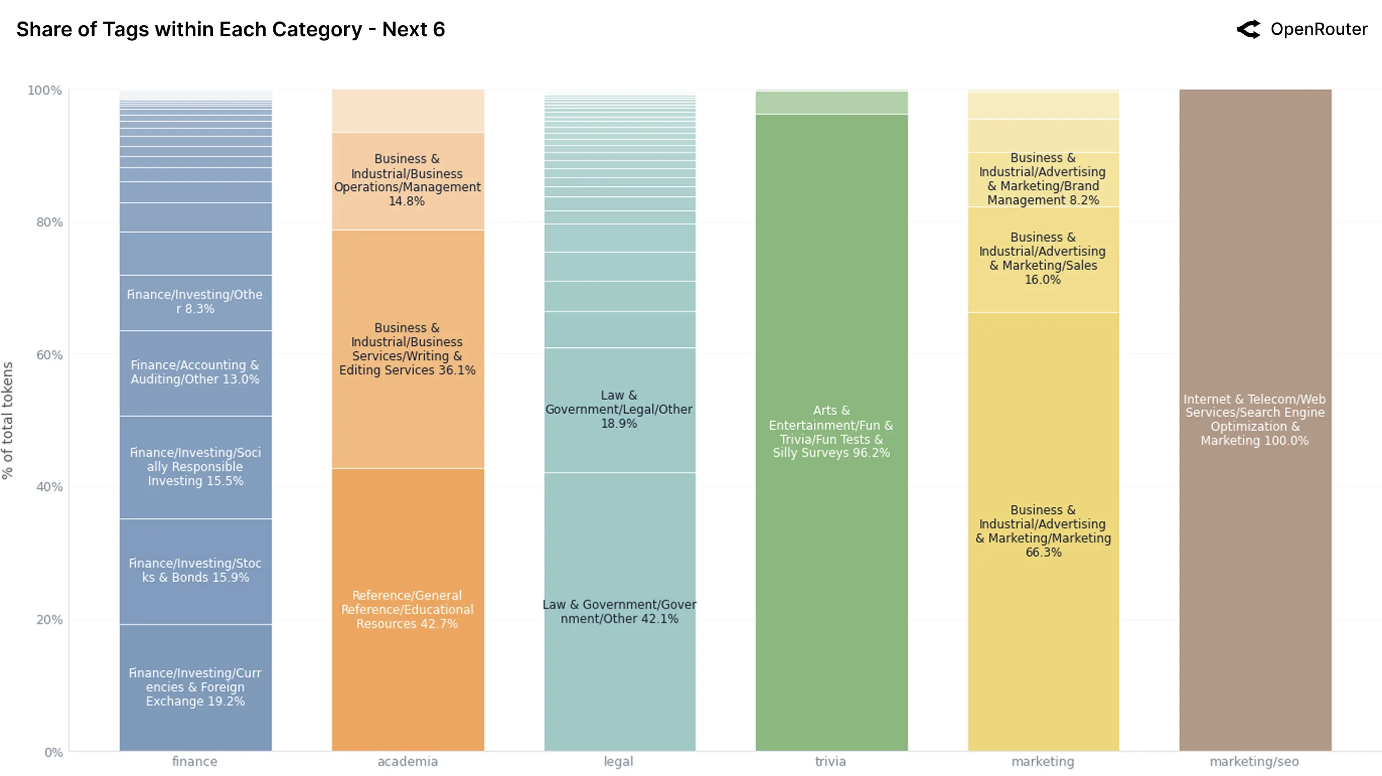
按token份额排名的接下来6个类别。对次要类别的类似细分,说明了每个领域中子主题的集中(或分散)情况。
上图分解了十二个最常见内容类别的大语言模型使用情况,揭示了每个类别内部的子主题结构。一个关键的结论是:大多数类别并非均匀分布,它们由一两种反复出现的使用模式主导,这通常反映了集中的用户意图或与大语言模型优势的契合。
数据表明,现实世界中的大语言模型使用并非均匀的探索:它紧密聚集在一小部分可重复、高流量的任务周围。角色扮演、编程和个人助理各自表现出清晰的结构和主导标签。相比之下,科学、健康和法律领域则更为分散,很可能尚未优化。这些内部分布可以指导模型设计、领域特定微调以及应用层界面,特别是在根据用户目标定制大语言模型方面。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)