网络爬虫(使用代码获取HTML网页信息)
向网站发送访问请求的时候网站服务器会先判断访问是否合理,合理会返回状态码和返回信息,不合理就会返回异常状态码。params参数会以字典形式在url后自动添加信息,需要提前将params定义为字典,建立字典info,包含一个键值对,get函数获取网页,该使用形式便于灵活设定需要搜索的信息。此时我们会发现并没有输出我们需要的信息,我们这时候不是以一个用户的身份进行访问的,可以进行UA伪装,伪装成用户再
网络爬虫
一、网络爬虫库
使用代码将HTML网页的内容下载到本地的过程。爬取网页主要是为了获取网页中的关键信息。
会用到以下库:
urllib库:python自带的,其中包含大量爬虫功能
requests库:第三方库需自己下载。在urllib库的基础上建立的,包含urllib库的功能。
下载命令:pip install requests -i 镜像地址(搜索第三方库镜像地址可以找到)
scrapy库:第三方库,需自己下载。适用于专业应用程序开发的网络爬虫库,集合了爬虫的框架,通过框架可创建一个专业爬虫系统。
下载命令:pip install scrapy -i 镜像地址
selenium库:第三方库,需要下载。用于驱动计算机中的浏览器执行相关命令,无需用户手动操作。
下载命令:pip install selenium -i 镜像地址
二、robots.txt规则
并不是所有网站的所有信息都允许被爬取,大部分网站根目录中存在一个robot.txt文件,用于声明此网站禁止访问的url和可以访问的url。
用户只需要在网站域名后加上/robots.txt,可以读取此文件
我们使用爬虫工具的时候,每次访问之间需要延迟5秒,避免频繁访问导致服务器拥挤,使得用户无法正常使用浏览器,爬虫由代码实现访问速度会很快。
三、获取网页资源
1.get(url,params=none,**kwarge)
url:表示需要获取的HTML网址
params:表示可选参数,以字典的形式发送发送信息,当需要向网页中提交查询信息时使用
**kwarge:表示请求采用的可选参数
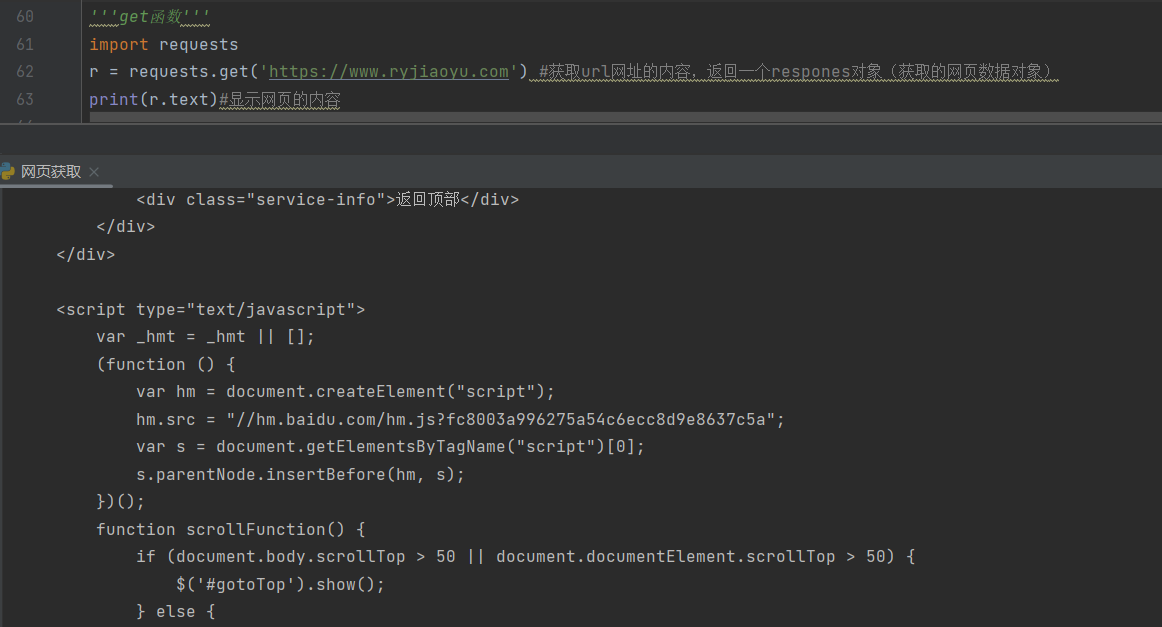
搜索信息
在该网页中搜索关键词为python的信息

添加信息
params参数会以字典形式在url后自动添加信息,需要提前将params定义为字典,建立字典info,包含一个键值对,get函数获取网页,该使用形式便于灵活设定需要搜索的信息。
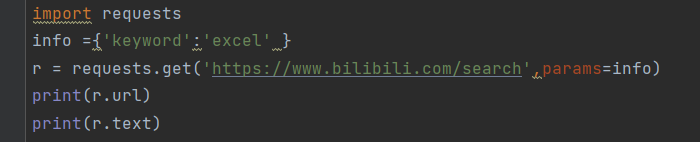
2.返回response对象
通过get函数获取HTML网页后,由于网页多样性,通常需要对网页返回response对象进行设置,以下为类response中的方法
response属性:
status_code(状态码):获取一个HTML时网页所在服务器会返回一个状态码,表明本次获取网页状态。向网站发送访问请求的时候网站服务器会先判断访问是否合理,合理会返回状态码和返回信息,不合理就会返回异常状态码。
headers(响应头):服务器返回的附加信息
url:相应的最终url位置
encoding:访问r.txt时使用的编码
cookies:服务器返回的文件
判断状态码是否为200,200获取网页内容,否则表示存在异常。
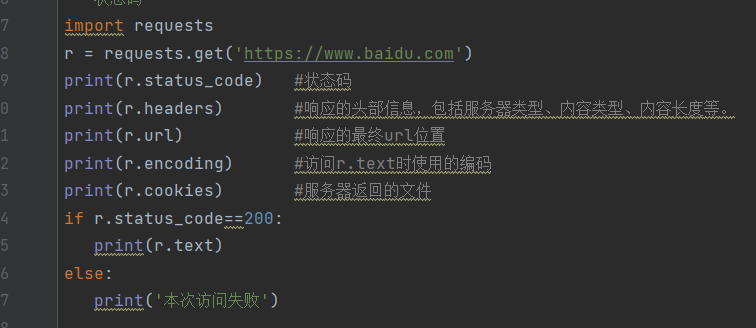
设置编码
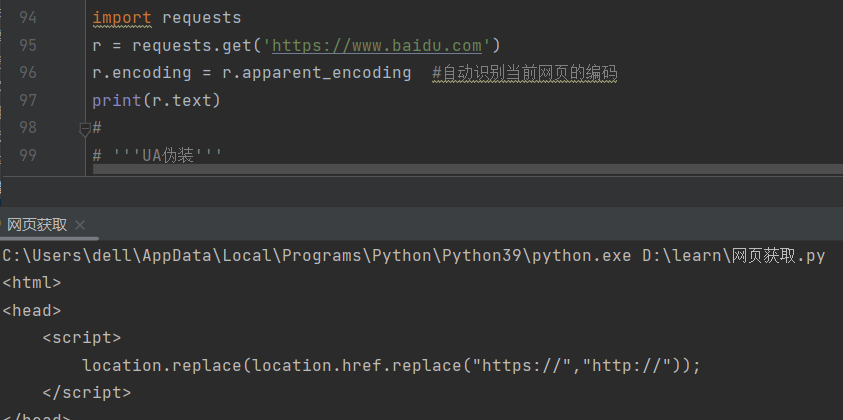
此时我们会发现并没有输出我们需要的信息,我们这时候不是以一个用户的身份进行访问的,可以进行UA伪装,伪装成用户再进行操作就会得到我们需要对信息
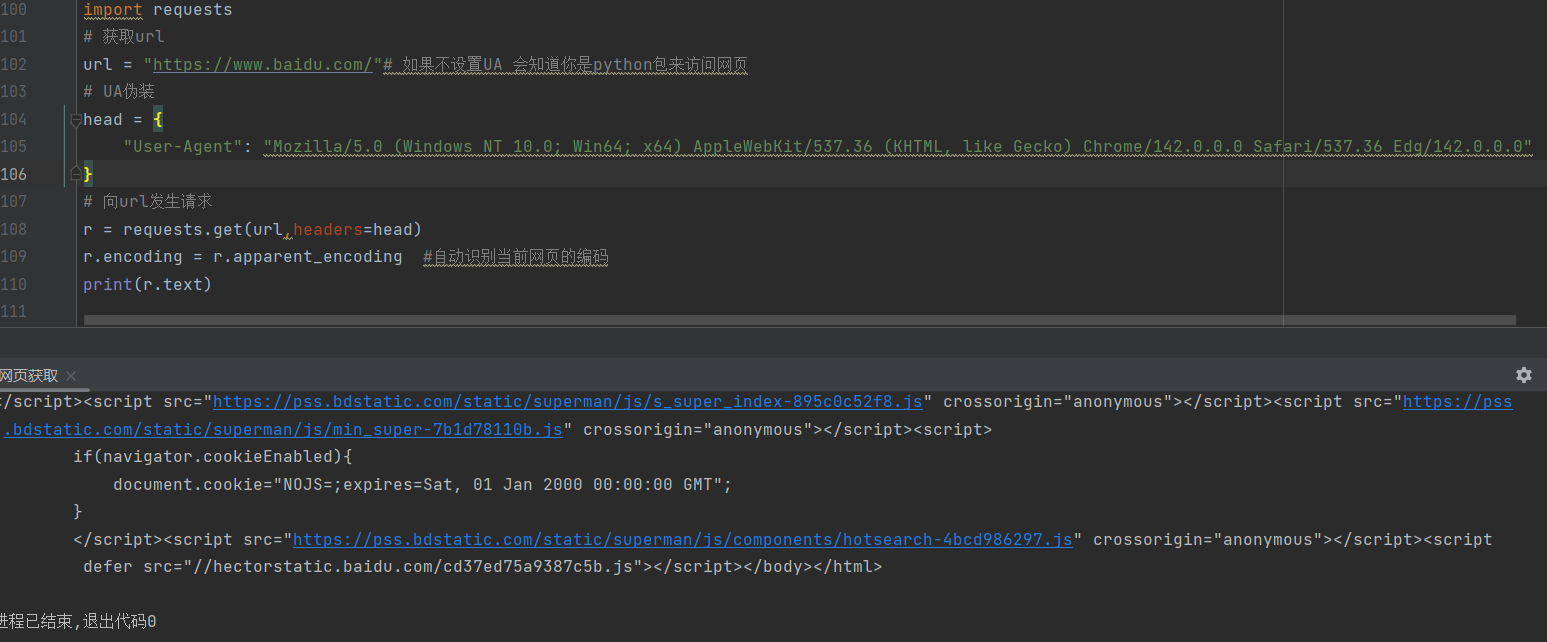
如何找到这里的head中需要填写的信息
先找到网络--刷新网页
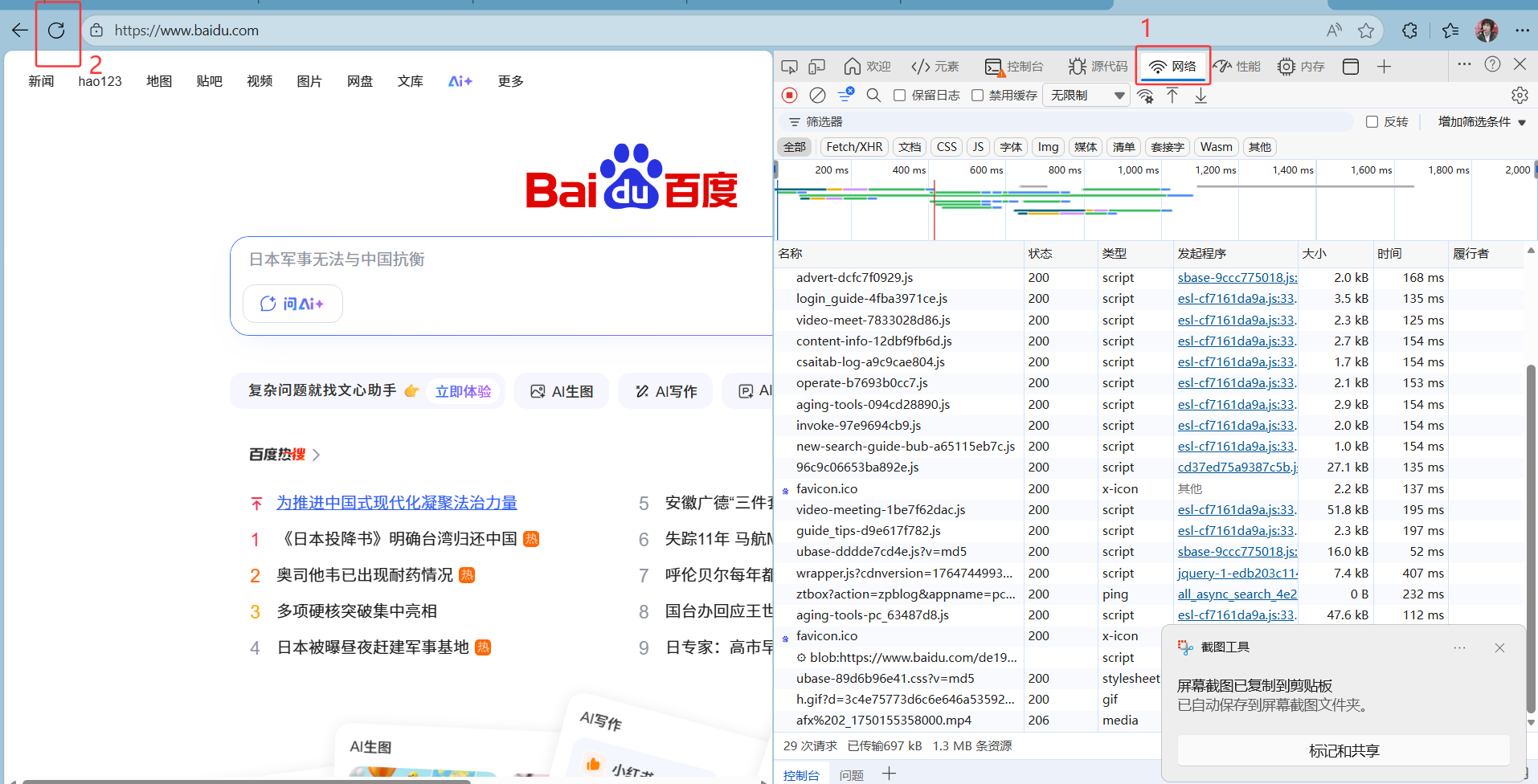
点击刷新出现的第一个----标头----下滑----user-agent
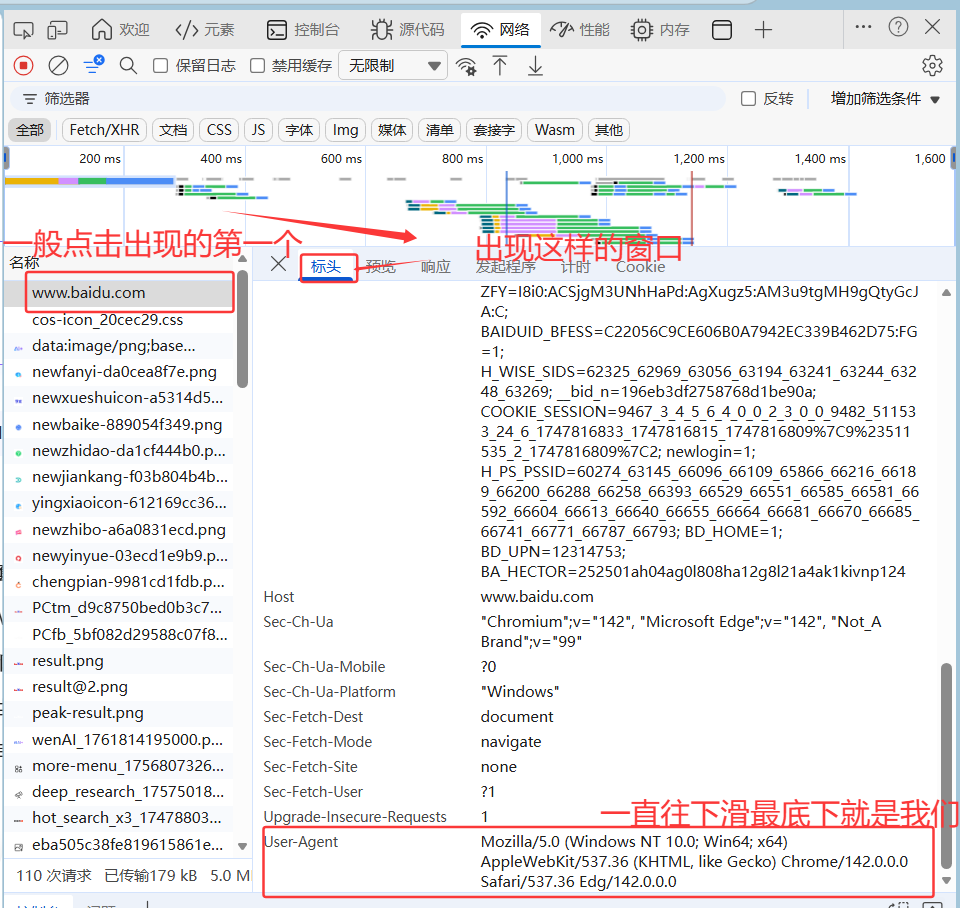
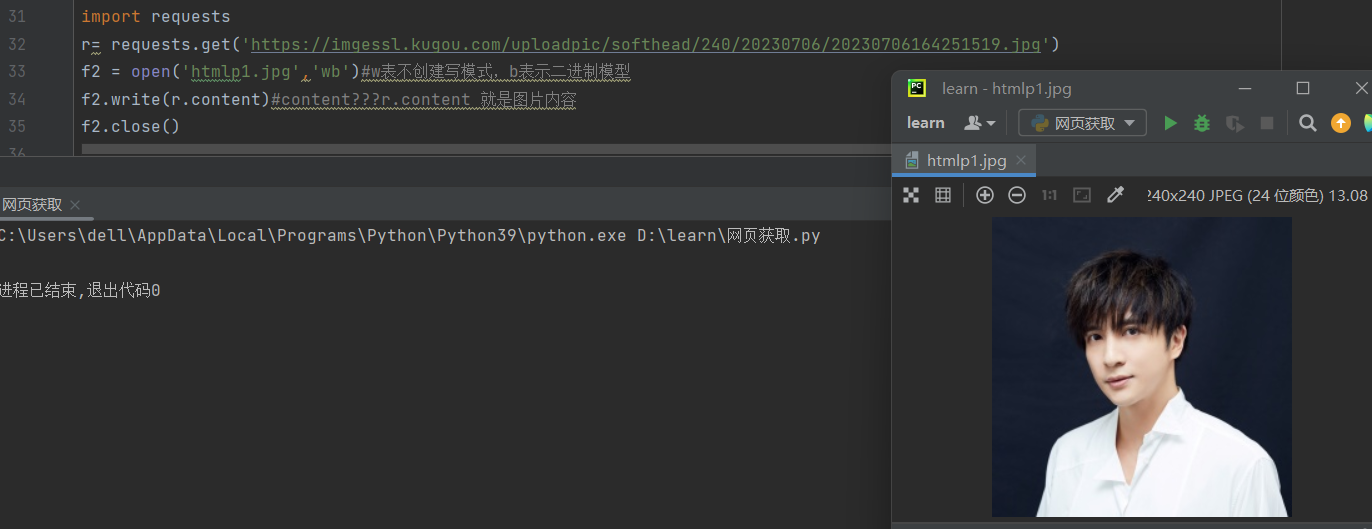
返回网页内容
3.xpath寻找元素
首先我们要下载lxml第三方库使用xpath前必须要对文件进行解析
这里时下面我需要用到的html文件
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>测试bs4</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
你好
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com/" title="赵匡胤" target="_self">
<span>this is span</span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
<img src="http://www.baidu.com/meinv.jpg" alt="" />
</div>
<div class="tang">
<ul>
清明时节雨纷纷,路上行人欲断魂
<li>
<a href="http://www.baidu.com" title="qing">
清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村
</a>
</li>
<li>
<a href="http://www.163.com" title="qin">
秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山
</a>
</li>
<li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>
<li><a href="http://www.sina.com" class="du">杜甫</a></li>
<li><a href="http://www.dudu.com" class="du">杜牧</a></li>
<li><b>杜小月</b></li>
<li><i>度蜜月</i></li>
<li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>
</ul>
</div>
</body>
</html>导入lxml库并对html进项解析
from lxml import etree
tree=etree.parse('E:/我的文件/人工智能/test.html')
# parse 提供解轿本地html文件的方法
#xpath获取返国的数据类型都是列表形式
#获取到title 对象
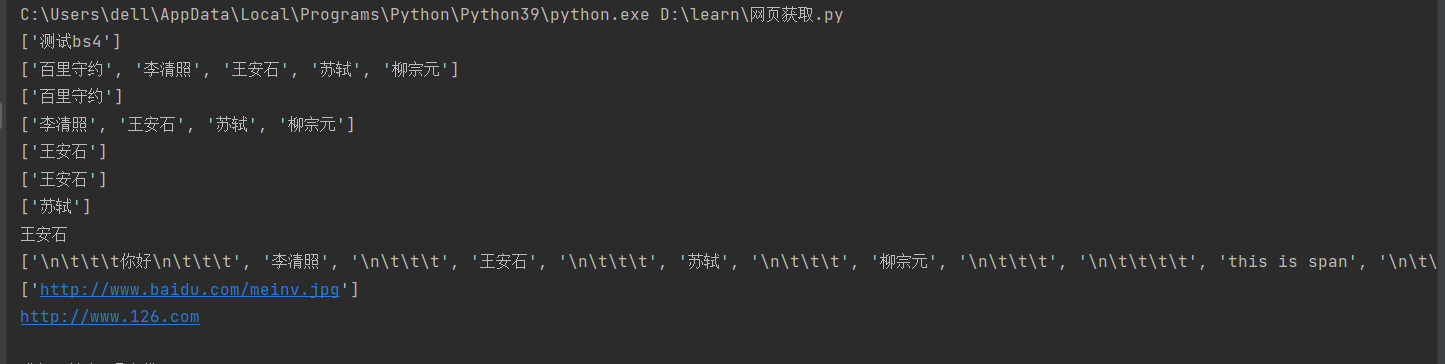
print(tree.xpath("/html/head/title/text()"))
print(tree.xpath("/html/body/div/p/text()"))
#索引定位,这里的索引从1开始
print(tree.xpath("/html/body/div[1]/p/text()"))
print(tree.xpath("/html/body/div[2]/p/text()"))
print(tree.xpath("/html/body/div[2]/p[2]/text()"))
# 属性定位 class,id
print(tree.xpath("/html/body/div[@class='song']/p[2]/text()"))
#/ 表示的是一个层做 //表示的是多个层级
print(tree.xpath("//div[@class='song']/p[3]/text()"))
# /text()取育系标签下的文本内容
# //text()该标答下的所台文本内容
print(tree.xpath("//div[@class='song']/p[2]/text()")[0])
print(tree.xpath("//div[@class='song']//text()"))
#取标签内的属性内容 @src、@nref、
print(tree.xpath("//div[@class='song']/img/@src"))
print(tree.xpath("//div[@class='tang']/ul/li[3]/a/@href")[0])运行结果:
4.爬取虎扑热榜,https://m.hupu.com/hot
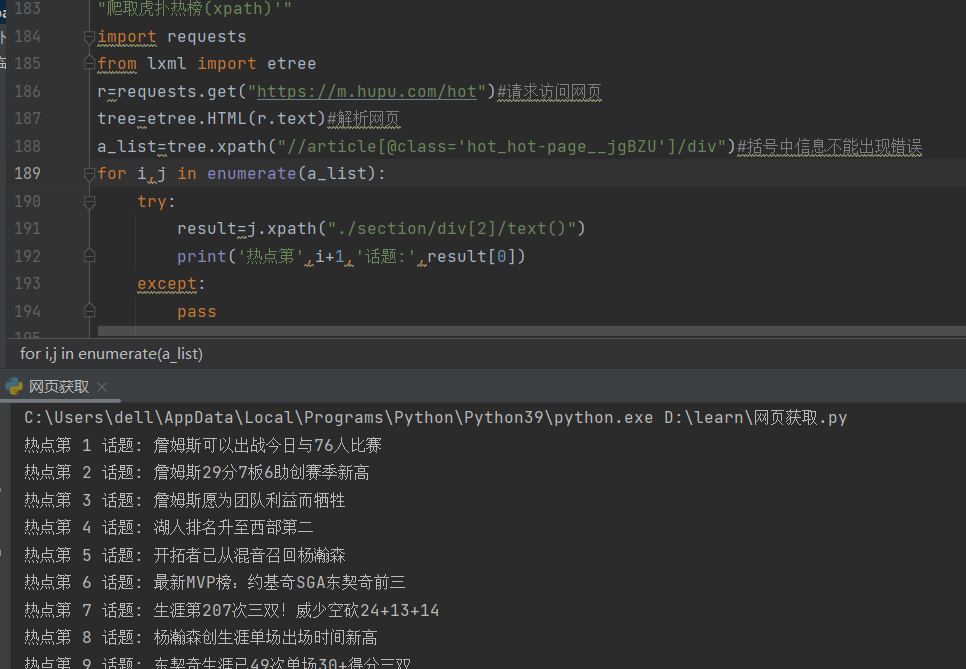
可以观察标签是否是独一的,越下级独一越简洁
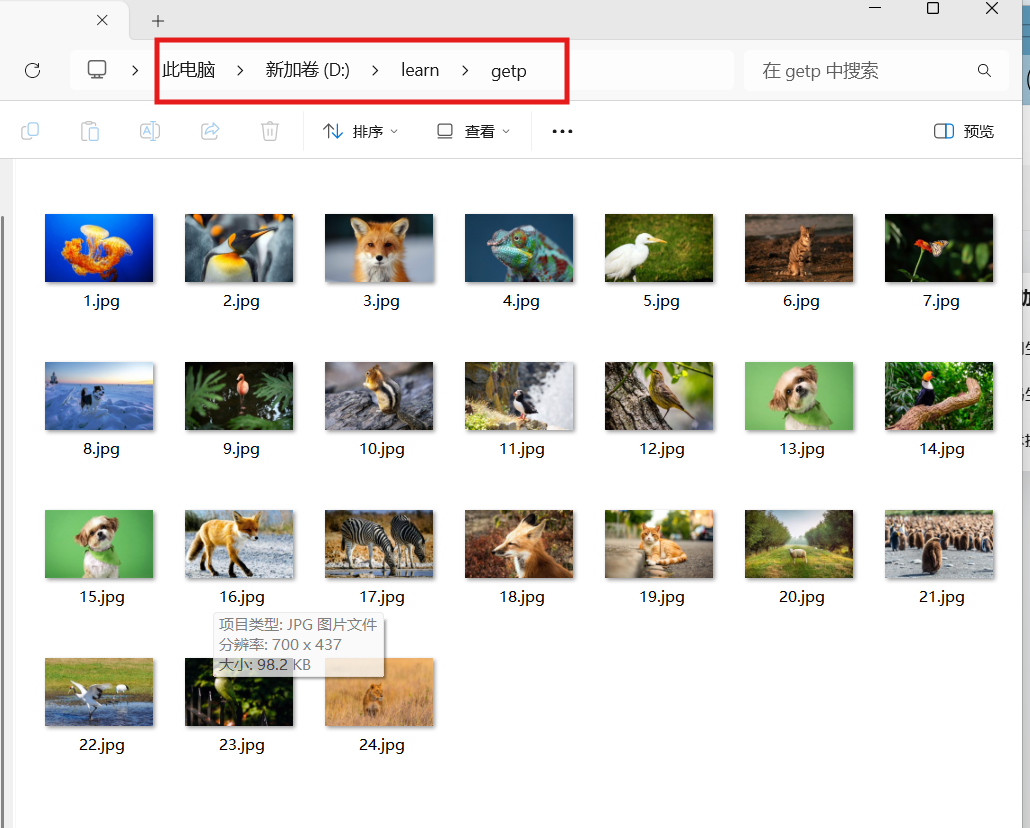
5.爬取图片
1)爬取wallpaper
目标网站:https://10wallpaper.com
这里需要下载第三方库fake_useragent,这个是用来ua伪装的
"爬取图片"
import fake_useragent
import requests
from lxml import etree
import os
n=0
def count():
global n
n+=1
return n
# 新建一个文件夹用于存储图片
if not os.path.exists("./getp"):
os.mkdir("./getp")
head ={
"User-Agent":fake_useragent.UserAgent().random
}
for i in range(2,4):
url = f'https://10wallpaper.com/Animal_wallpaper/page/{i}'# 发送请求
resp =requests.get(url,headers=head)
# 响应回去的返回数据
result =resp.text
tree = etree.HTML(result)
p_list = tree.xpath("//div[@id='pics-list']/p")
for p in p_list:
img_url = p.xpath("./a/img/@src")[0]
img_url2='https://10wallpaper.com'+img_url
print(img_url2)
img_name = count()
print(img_name)
img_resp =requests.get(img_url2, headers=head)
img_content = img_resp.content
with open(f"./getp/{img_name}.jpg","wb") as fp:
fp.write(img_resp.content)运行后可在文档中点开文件夹
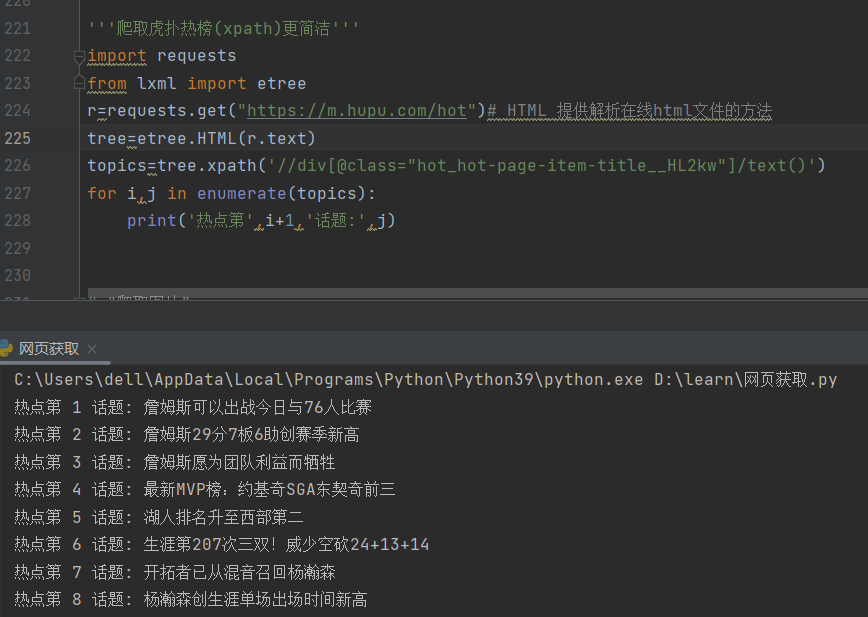
2)爬取gamewallpapers
目标网页:https://www.gamewallpapers.com
关于xpath,一个/表示只找下一级,//表示找下面的所有级
import fake_useragent
import requests
from lxml import etree
import os
n=0
def count():
global n
n+=1
return n
if not os.path.exists("./getp2"):# 新建一个文件夹用于存储图片
os.mkdir("./getp2")
head ={
"User-Agent":fake_useragent.UserAgent().random
}
for i in range(1,2):
url = f'https://www.gamewallpapers.com/index.php?start={(i-1)*36}&page='# 发送请求
#第一页:https://www.gamewallpapers.com/index.php?start=0&page=
#第二页:https://www.gamewallpapers.com/index.php?start=36&page=
#第三页:https://www.gamewallpapers.com/index.php?start=72&page=
#以此类推第四页应为108
resp =requests.get(url,headers=head)
# 响应回去的返回数据
result =resp.text
tree = etree.HTML(result)
p_list = tree.xpath('//div[@id="thumbnails-left-content"]')
print(p_list)
for p in p_list:
img_url = p.xpath(".//img/@src")[0]
img_url2='https://www.gamewallpapers.com'+img_url
print(img_url2)
img_name = count()
print(img_name)
img_resp =requests.get(img_url2, headers=head)
img_content = img_resp.content
with open(f"./getp2/{img_name}.jpg","wb") as fp:
fp.write(img_resp.content)四、提交信息到网页
需要向网页中提交信息时,可以使用requests库中的post()函数实现,提交内容包含表单图片文件等类型数据
post()函数用于向网站发送数据请求
post(url,data=none,json=none,**kwarge)
url:表示网站地址
data:表示需要发送的数据对象(字典,元组,列表,字节数据或文件)
json:表示需要发送的数据对象(该对象为json数据)
**kwargs:表示请求采用的可选对象
五、selenium库驱动浏览器
1.下载selenium库
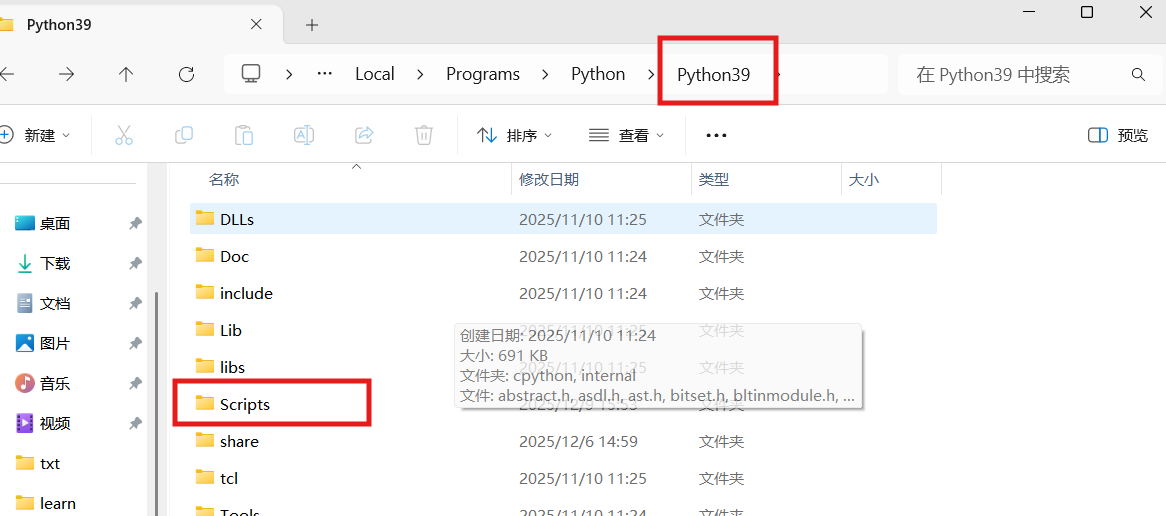
2.找到当前所用python的地址
可以在命令行中输入where python,复制路径

注意在文件管理器中查找的时候要把python.exe去掉,回车,在这里会有一个scripts文件夹,点开该文件夹
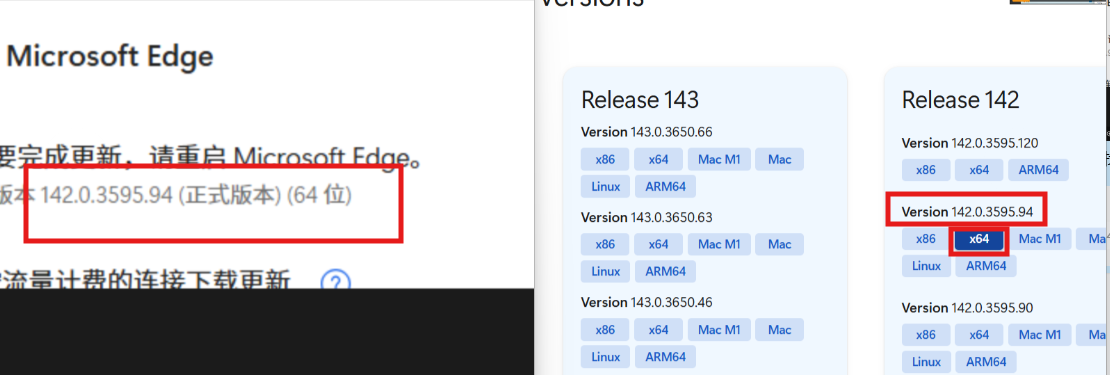
3.打开你的浏览器,这里我用的是edge,在设置里面找到浏览器的版本,这里是为了下载正确版本的驱动器

如果是其他浏览器,火狐可选firefox,谷歌,360……可选chrome
edge驱动下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?ch=1&form=MA13LH
chrome驱动下载地址:https://chromedriver.storage.googleapis.com/index.html
firefox驱动下载地址:https://github.com/mozilla/geckodriver/releases
下载对应版本
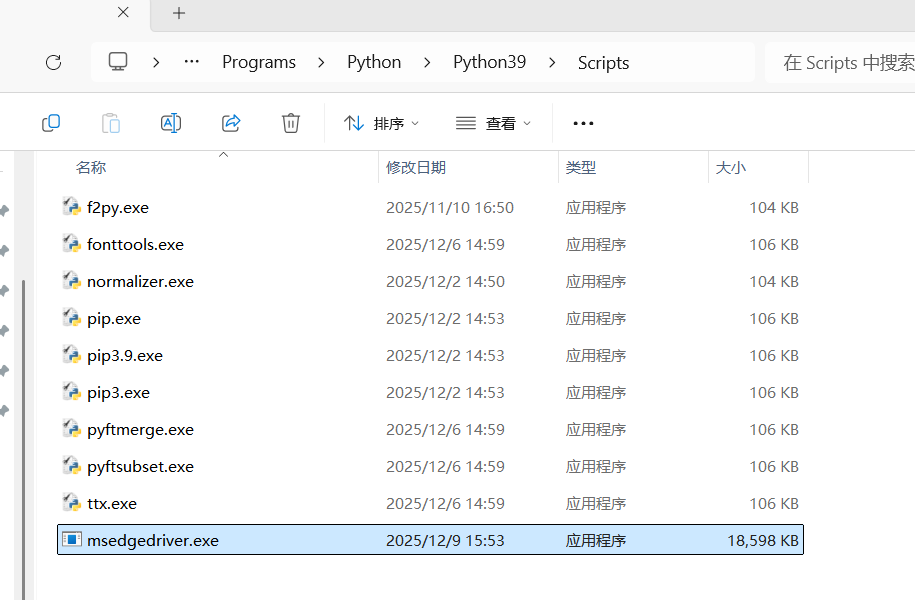
4.下载好后先进行解压,只需要解压红框中该项即可,解压位置自己选择

5.解压好之后把该程序剪切到上面我们打开的scripts,即可
6.selenium库驱动浏览器
这里的路径是浏览器的路径,可以右击桌面上浏览器选择打开文件地址,在右击msedge.exe,然后如下
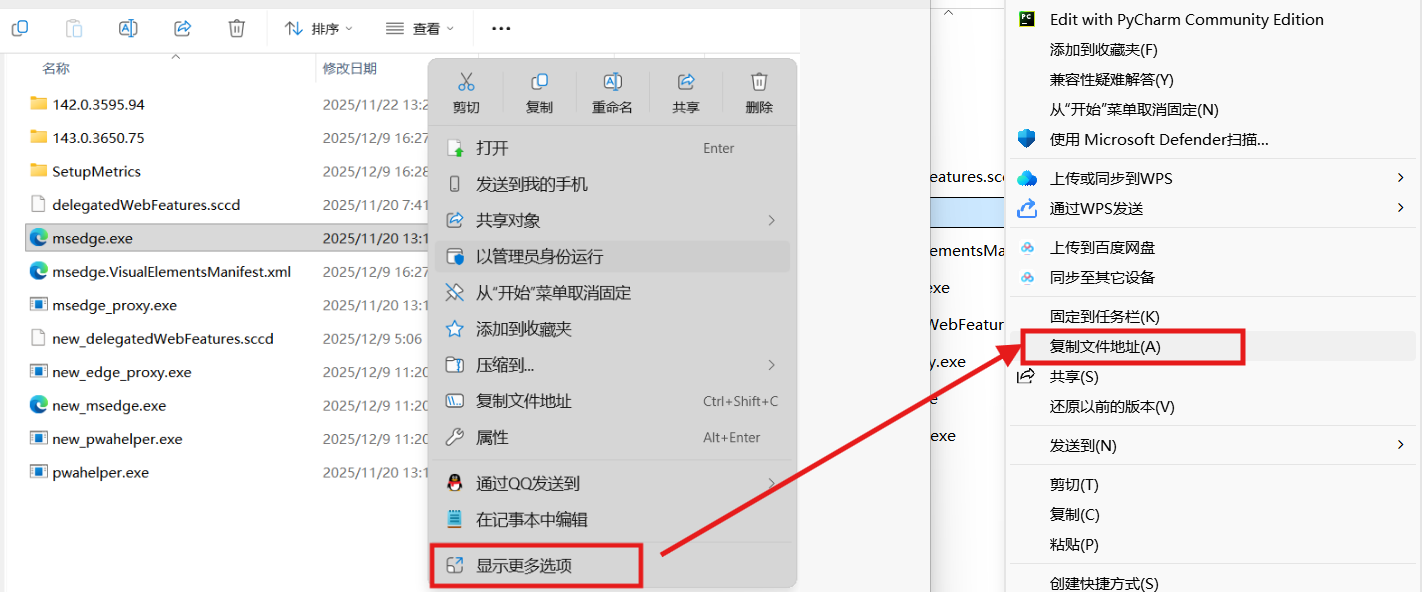
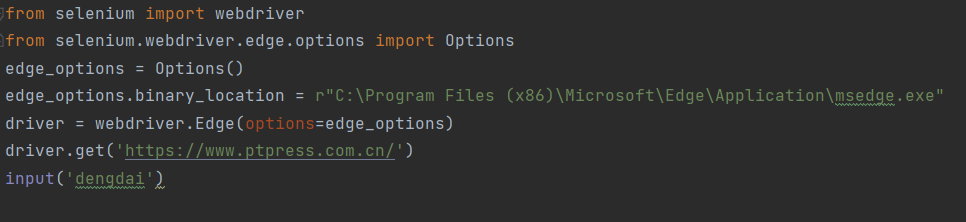
运行程序就会打开网站
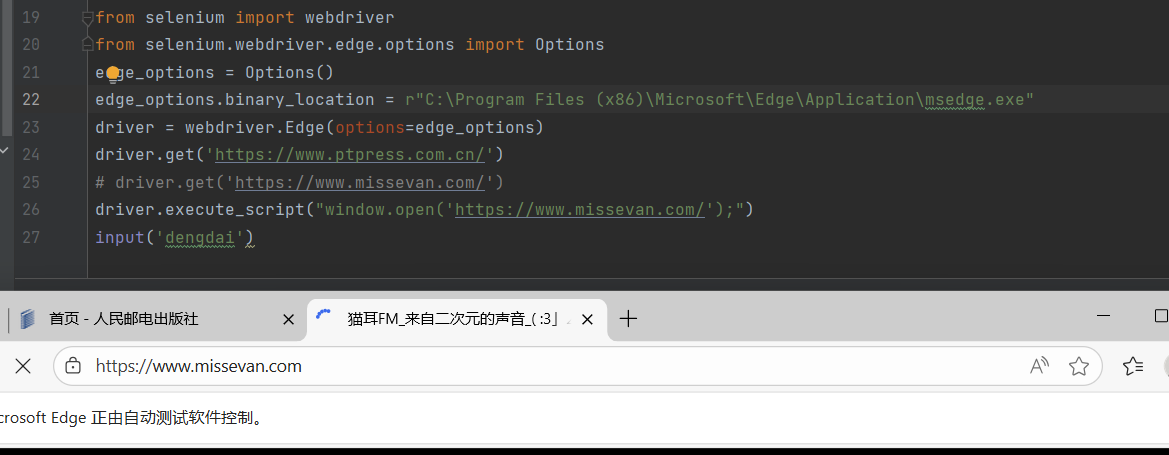
如果我们在上面写俩网站
后面就会覆盖前面的,因为只打开一个标签页,如果想打开多个标签页就可以按照下面语句,前面配置都是一样的

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)