两周,我搞懂了AI如何“计算”新材料:从金属合金到MOFs的科研实战体验
摘要:本文介绍了两大前沿专题,探讨计算化学与AI技术在材料研究中的应用。专题一聚焦MOFs材料,系统讲解从量子化学计算到图神经网络的全链条研究方法,涵盖CP2K结构优化、RASPA2吸附模拟及CGCNN性能预测等实战案例。专题二围绕金属材料智能设计,详细解析数据驱动的研发范式,包括Matminer描述符生成、主动学习工艺优化及SHAP可解释分析等技术。两个专题均采用真实材料体系案例,提供可复现的代
作为一名材料/化学方向的硕士生,我经常在实验室和文献之间反复横跳:合成、表征、测试,再分析数据,一个完整的研究周期往往以“月”甚至“年”为单位。尤其是在做MOFs或金属材料这类结构复杂、性能影响因素多的体系时,传统“试错法”的局限性越来越明显——数据量大、变量多、机理不清晰,让人头疼。
最近留意到两个线上专题,主题分别是 “计算化学+AI驱动的MOFs性能预测” 和 “数据驱动的金属材料智能设计”,看完内容大纲后,我感觉它们几乎是为我们这些想走“理论+数据”路线的研究生量身打造的。
🔬 专题一:当MOFs研究遇上AI与计算化学
如果你在做MOFs、COFs等多孔材料,应该深有体会:结构千变万化,性能与结构之间的关系复杂。这个专题从量子化学计算、分子模拟切入,再融合机器学习、图神经网络,覆盖了从结构处理、特征提取到建模预测的全链条。
我印象比较深的几个实战点:
-
用 CP2K、RASPA2 做结构优化与吸附模拟
-
从 CoRE-MOF、QMOF 等数据库中清洗与提取特征
-
用 XGBoost、SHAP、SISSO 做吸附性能预测与机制解读
-
甚至上手 图神经网络(CGCNN/MEGNet),把晶体结构当图数据建模
如果你之前只用过Materials Studio或VASP做计算,这套“计算+数据+AI”的串联思路可能会给你新的启发。
⚙️ 专题二:数据驱动,重新定义金属材料设计
金属材料的设计以往依赖经验与实验,但这个专题完全转向数据与算法。内容从Python数据处理、描述符工程,到经典机器学习、集成学习,再到主动学习、灰箱模型与可解释AI,一步步教你如何用数据“倒推”材料配方与工艺。
比较吸引我的是:
-
用 Matminer 批量生成材料描述符
-
在钛合金、高温合金等真实体系上做性能预测与工艺优化
-
实战主动学习循环,优化增材制造参数
-
用符号回归+SHAP发现材料规律,输出可解释的设计指南
对于做合金设计、工艺优化、性能预测的同学来说,这种“用数据说话”的研究范式可能会大幅提升你的工作效率与创新空间。
🧠 为什么我觉得值得关注?
-
内容不悬浮:两个专题都以真实材料体系为载体,提供可复现的代码与案例,不是纯讲理论。
-
技术栈很新:覆盖了从传统模拟到可解释AI、图神经网络的多个前沿方法,适合想拓展技术视野的同学。
-
适合学生入门:如果你对“计算+数据”交叉方向感兴趣,但不知道从哪入手,这类系统化的内容框架可以帮你快速构建知识体系。
-
纯线上进行:时间安排在2026年1月,均为直播+录播,支持回放,适合在校学生安排时间。
📌 小结
无论你是做MOFs吸附、催化,还是金属材料设计、工艺优化,“计算+数据+AI” 正在成为新一代材料研究的核心能力。这两个专题虽然不是“课程”,但内容密度高、实战性强,很适合想在科研中引入数据驱动方法的同学。
如果你也在寻找更智能、更高效的材料研究路径,或许可以关注一下这类内容。毕竟,在科研里,有时候“思路打开”比“埋头苦干”更重要。
注:内容源自公开资料整理,仅供学术交流参考。
有兴趣可自行搜索“研而有信er”或访问官网查看详情。
计算化学与人工智能驱动的MOFs性能预测与筛选技术大纲内容
|
目录 |
主要内容 |
|
|
第一部分 AI与MOF计算基础及环境搭建 |
1. 关键理论: 1.1. AI 在计算化学中的范式革新:从计算化学到深度学习 1.2. MOF结构-功能关系解析:从金属节点、有机配体的化学特性到宏观吸附、分离性能 1.3. 科学计算与AI工作流整合:数据获取(DB)→结构清洗(Code)→特征计算(Tool)→模型训练(AI)的标准流程 1.4. 量子化学基础:DFT在MOF结构优化、电子结构与吸附位点分析中的应用 案例实践1: ◇ Case 1:使用MOSAEC算法处理CoRE-MOF、QMOF数据库,进行结构合理性校验与数据清洗,确保所有结构满足化学合理性 ◇ Case 2:使用Zeo++计算 MOF 孔结构特征(比表面积、孔隙率等) ◇ Case 3:拓扑分析与化学描述符(开放金属位点、有机配体结构式)批量提取 ◇ Case 4:使用CP2K完成MOF的晶体结构优化,并计算CH4的结合能,为机器学习筛选出来的潜在候选物进行机理解释。 |
|
|
第二部分 分子模拟和高通量计算在MOFs中的应用 |
1. 关键理论: 1.1. 分子模拟核心:力场与电荷分配的物理意义与选择策略 1.2. 分子模拟在揭示MOF吸附与分离机制(吸附位点、扩散路径)中的作用 1.3. 高通量计算:作为AI模型“数据工厂” 的搭建流程与MOF 设计中的应用 案例实践2: ◇ Case 1:使用 RASPA2 计算气体吸附/分离性质 ◇ Case 2:使用 RASPA2计算等温吸附曲线和气体吸附概率密度图 ◇ Case 3: 使用GPU加速的gRASPA实现高通量GCMC模拟,体验“计算产生数据”的规模与效率,并构建后续所需数据集 ◇ Case4:高通量GCMC计算结果的分析与可视化,提取结构-性能对应关系。 文献复现:复现经典文献的高通量筛选流程,讨论如何将结果作为AI模型的输入Large-scale screening of hypothetical metal–organic frameworks. Nature Chem 2012, 4, 83–89 DOI: 10.1038/nchem.1192 |
|
|
第三部分 传统机器学习与可解释AI在MOF中的应用 |
1. 理论部分 1.1. 机器学习在MOF中的QSAR/QSPR模型:结构-性质定量关系 1.2. 特征工程核心:化学描述符(比表面积、孔径等)的物理意义 1.3. 算法深度解析:随机森林(RF)、XGBoost、SVM在吸附预测中的优劣 1.4. 可解释AI前沿:SHAP、SISSO 在挖掘物理机制与发现设计规则中的应用 案例实践3: ◇ Case 1:Python实现XGBoost、SVM、RF模型预测MOF气体吸附分离性质 ◇ Case 2:使用贝叶斯优化算法进行参数调优与特征选择 ◇ Case 3:基于独立筛选和稀疏算子 (SISSO) 算法从高维特征空间中学习简洁且可解释的物理公式 ◇ Case 4:可视化结果:AUC曲线、误差散点图、蜜蜂群图 ◇ Case 5:预测未知MOF的吸附性质,验证模型泛化能力 文献复现:Robust Machine Learning Models for Predicting High CO2 Working Capacity and CO2/H2 Selectivity of Gas Adsorption in Metal Organic Frameworks for Precombustion Carbon Capture J. Phys. Chem. C 2019, 123, 7, 4133–4139 DOI: 10.1021/acs.jpcc.8b10644 |
|
|
第四部分 图神经网络(GNN)与MOF结构-性能建模 |
1. 理论部分 1.1. GNN基础:如何将晶体结构表示为图—节点、边与全局状态的化学信息编码 1.2. 主流GNN模型:CGCNN、MEGNet消息传递机制及在MOF建模中的优势 1.3. 节点/边特征构建:化学键、配位环境、拓扑连通性的编码策略 1.4. GNN的可解释性:如何理解GNN“看到”的化学信息 案例实践4: ◇ Case 1:使用Pymatgen将MOF晶体结构转换为图神经网络所需的张量数据 ◇ Case 2:训练CGCNN或MEGNet模型,预测MOF的吸附性能,并与传统ML对比 ◇ Case 3:GNN可视化:使用t-SNE或主成分分析模型学习到的结构表征 ◇ Case 4:利用训练好的GNN模型,对虚拟MOF数据库(如hMOF)进行快速性能筛选与候选材料推荐 文献复现:Hydrogen storage metal-organic framework classification models based on crystal graph convolutional neural networks, Chemical Engineering Science 2022, 259, 117813. DOI: 10.1016/j.ces.2022.117813 |
|
6.
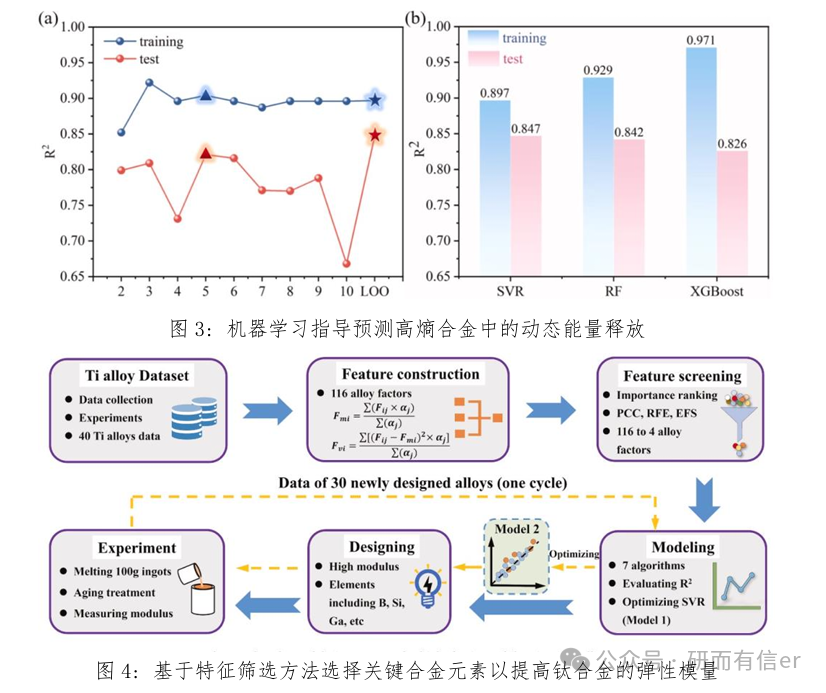
部分案例图展示
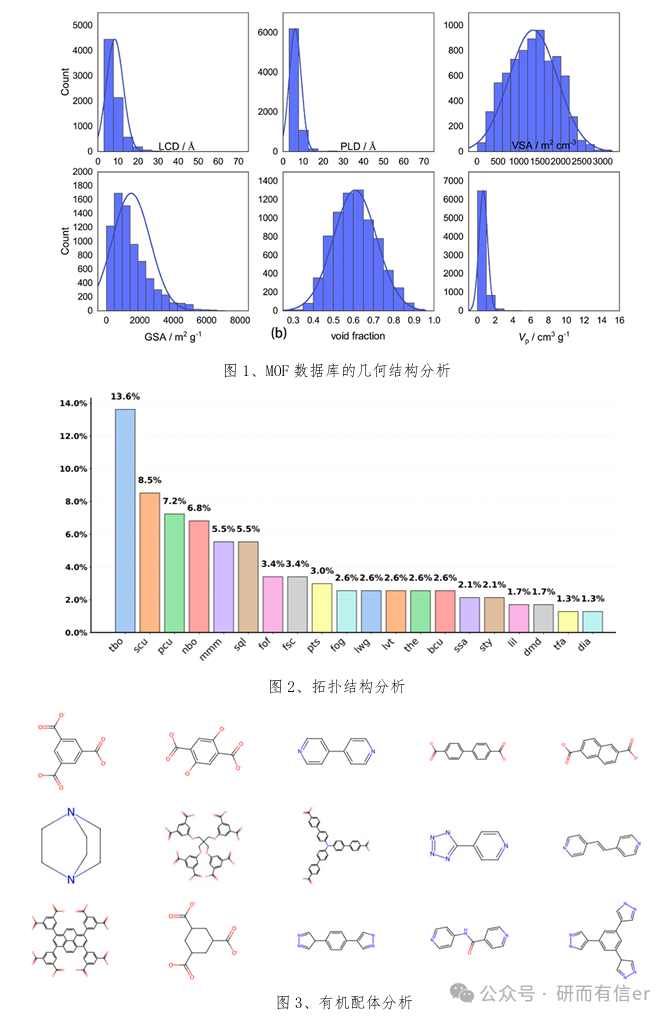
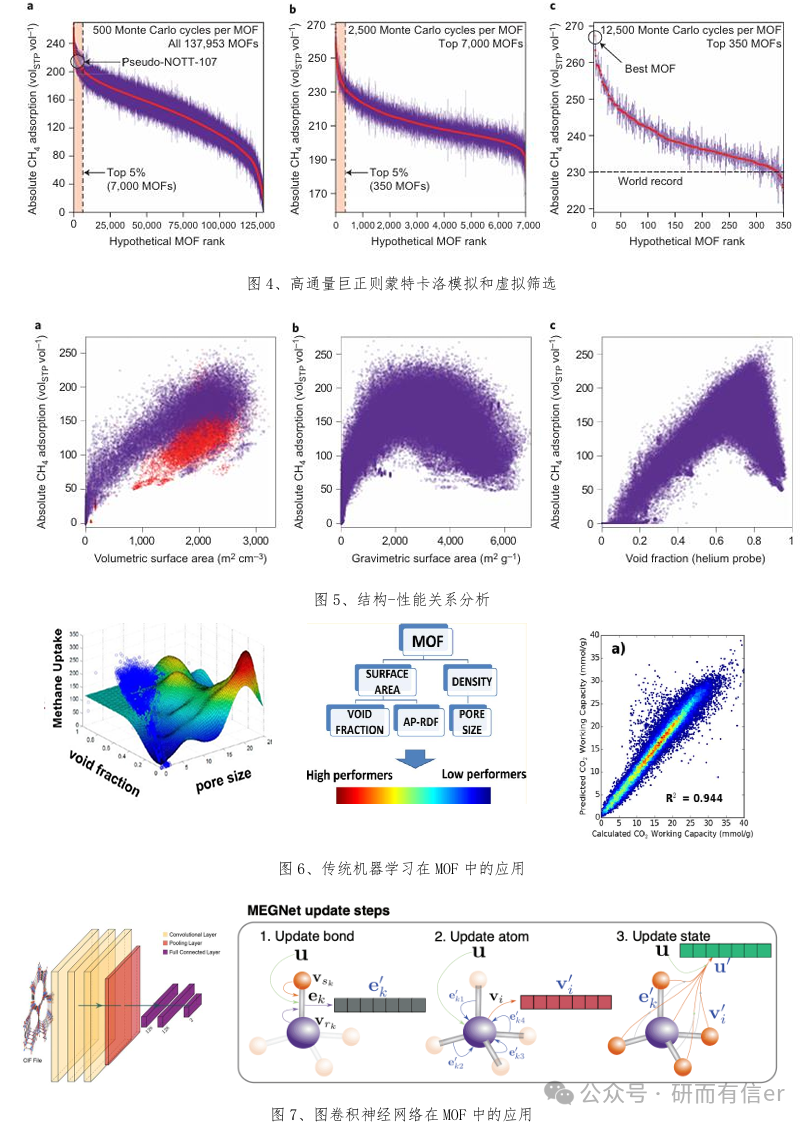
人工智能与数据驱动方法加速金属材料设计与应用大纲内容
|
目录 |
主要内容 |
|
|
第一部分 Python与材料科学数据分析基础 |
1. 理论内容: 1.1. 数据驱动材料设计的范式革命与核心流程 1.2. Python材料数据科学生态系统 1.3. 材料数据库与数据标准化概述 2. 实践内容:从环境搭建到数据分析 ◇ Case 1:Python科学计算环境搭建与核心库(NumPy, Pandas等) ◇ Case 2:准备或数据库下载特定材料数据 □ 高温合金体系,获取其原子结构、成分、相溶解温度等基本信息 □ 钛合金体系,重点关注蠕变性能和拉伸力学性能 □ 下载/准备钛合金或高温合金的数据,并将结果保存为DataFrame ◇ Case 3:数据清洗、探索与可视化分析 |
|
|
第二部分 描述符工程与特征优化 |
1. 理论内容: 1.1. 材料描述符的核心概念:如何数字化表征材料 1.2. 成分描述符、工艺描述符、晶体结构描述符与电子结构描述符详解 1.3. 特征选择、降维与特征重要性分析方法及原理 2. 实践内容:从生成描述符到优化特征空间 ◇ Case 1:使用Matminer批量生成多元化描述符 □ 为钛合金体系生成描述符 □ 为高温合金体系生成描述符 □ 获得包含原始材料信息和数十至上百个描述符列的DataFrame ◇ Case 2:无监督学习与数据可视化 □ 数据预处理: 对生成的大量描述符进行标准化,确保处于同一量纲 □ 主成分分析:对钛合金/高温合金体系描述符数据进行PCA分析 □ t-SNE可视化:使用t-SNE对钛合金体系/高温合金体系进行可视化 ◇ Case 3:特征选择与优化 □ 过滤法:计算描述符与目标性能的相关系数 □ 随机森林或其他回归模型进行训练。 以“预测钛合金的蠕变断裂寿命或其他性能”为例,分析模型哪些描述符最为重要。 □ 递归特征消除:使用RFECV工具,自动确定最佳特征数量。 |
|
|
第三部分 经典与集成机器学习算法 |
1. 理论内容: 1.1. 监督学习的基本框架与材料数据的建模流程 1.2. 经典机器学习算法的核心思想与比较 1.3. 集成学习方法及其在复杂材料体系中的优势 1.4. 模型评估、误差分析与模型选择策略 2. 实践内容——从基础建模到集成算法应用 ◇ Case 1:基于经典算法的材料性能预测入门实践 □ 使用给定合金属性数据集(如晶体结构/力学性能 - 元素特征数据)建立初始化线性回归、支持向量机回归、决策树回归/分类器等模型 □ 完成训练–测试流程,可视化预测误差 ◇ Case 2:超参数调优实战:使用交叉验证和自动化搜索工具来寻找模型的最佳超参数组合 ◇ Case 3:集成模型在复杂材料任务中的应用与解释 □ 针对合金力学性能等,分别训练基于随机森林、GBDT等性能预测模型,调整主要超参数,比较不同集成模型的预测精度与训练效率 □ 模型解释性:使用SHAP库,对合金力学性能预测模型进行分析 |
|
|
第四部分 主动学习与多目标优化 |
1. 理论内容: 1.1. 材料研发的瓶颈与主动学习的核心 1.2. 主动学习优化框架:建模与决策 1.3. 单目标优化与多目标优化介绍 2. 实践内容: ◇ Case 1:在一个简单一维函数上实现主动学习循环,理解其工作原理 ◇ Case 2:综合案例—钛合金增材制造工艺参数优化 □ 问题定义 □ 构建初始代理模型 □ 设计主动学习循环 □ 执行循环,绘制每一轮中发现的最佳性能的进化图 □ 循环结束后,分析最终推荐出的增材制造工艺参数 论文实例复现与解读: 1.Active learning framework to optimize process parameters for additive-manufactured Ti-6Al-4V with high strength and ductility. Nature Communication, 2025: 16: 931. |
|
|
第五部分 “灰箱”模型与可解释AI |
1. 理论内容: 1.1. “灰箱”模型的核心思想与优势 1.2. 物理信息神经网络核心原理与应用 1.3. 符号回归 1.4. 模型可解释性技术(全局与局部解释、SHAP 理论) 2. 实践内容——构建与解读下一代AI模型(结合相关论文) ◇ Case 1:物理约束神经网络实战 ◇ Case 2:符号回归发现新材料规律 □ 输入系统或材料相关的多维数据,运行符号回归寻找关键描述符 □ 对发现的公式进行合理性评估,判断其是否具有实际解释意义 □ 运用SHAP工具解读一个高性能集成学习模型,获得材料设计指南 □ 全局解释:计算并绘制SHAP特征重要性条形图,识别出影响合金性能的最关键描述符,绘制SHAP摘要图,观察每个描述符与目标性能的单调性或非线性关系 □ 局部解释:选择一个模型预测为超高力学性能的特定合金成分,生成该样本的SHAP力力图,直观展示描述符(特征) |
|
6.
部分案例图展示
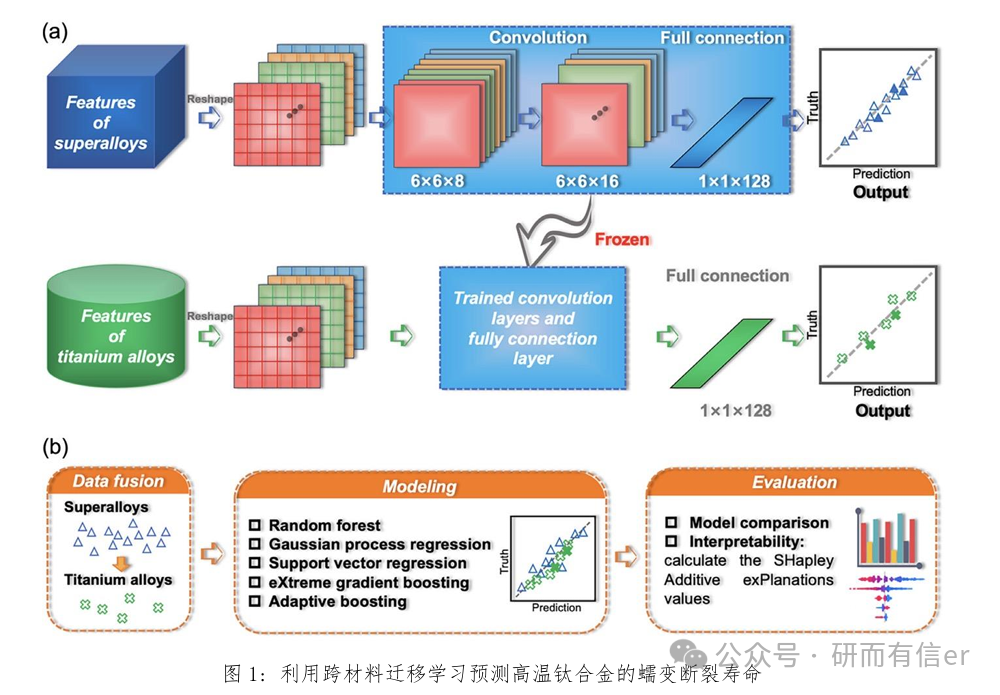
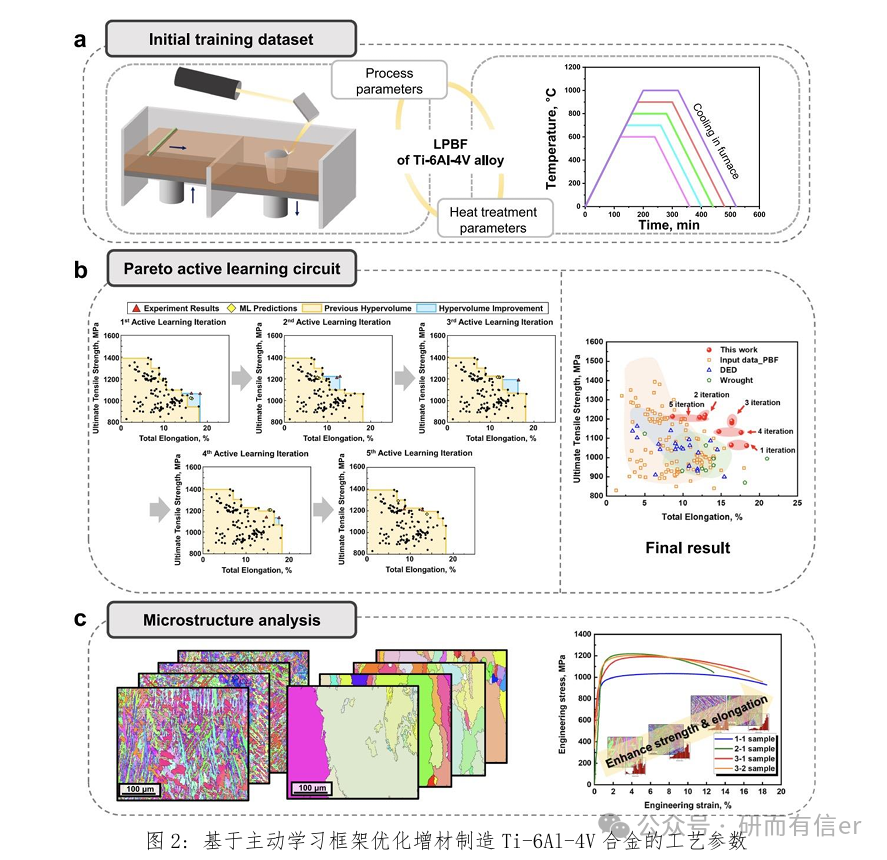

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)