如何用AI破解数据质量难题:全面指南
AI技术助力破解数据质量难题 摘要:本文探讨了AI技术在数据质量管理中的创新应用。面对低质量数据带来的3万亿美元年损失,传统规则引擎已难以应对现代数据的复杂性。研究展示了AI如何通过机器学习、深度学习等技术,有效解决数据准确性、完整性、一致性等六大维度的质量问题。文章提供了KNN填充、孤立森林异常检测、相似度匹配等具体代码实现,并构建了完整的AI数据质量管理架构。通过电商平台案例证实,AI方案可使
引言:数据质量的重要性与AI的崛起
在数字化时代,数据已成为企业的核心资产。然而,低质量数据会导致决策失误、运营效率低下和客户体验下降。据IBM研究,不良数据每年给美国企业造成约3万亿美元的损失。传统数据质量管理方法依赖规则引擎和人工检查,难以应对现代数据环境的复杂性和规模。
人工智能(AI)技术为数据质量管理带来了革命性变化。通过机器学习、自然语言处理和深度学习等技术,AI能够自动化地检测、诊断和修复数据质量问题,大幅提升数据质量管理的效率和准确性。本文将深入探讨如何利用AI技术破解数据质量难题,提供实用的代码示例、流程图、Prompt模板和可视化方案。
一、数据质量问题的常见类型
数据质量问题通常分为六大维度:
- 准确性(Accuracy):数据是否正确反映现实世界
- 完整性(Completeness):数据是否缺失关键字段或记录
- 一致性(Consistency):数据在不同系统间是否保持一致
- 时效性(Timeliness):数据是否及时更新
- 唯一性(Uniqueness):是否存在重复记录
- 有效性(Validity):数据是否符合预定义格式和规则
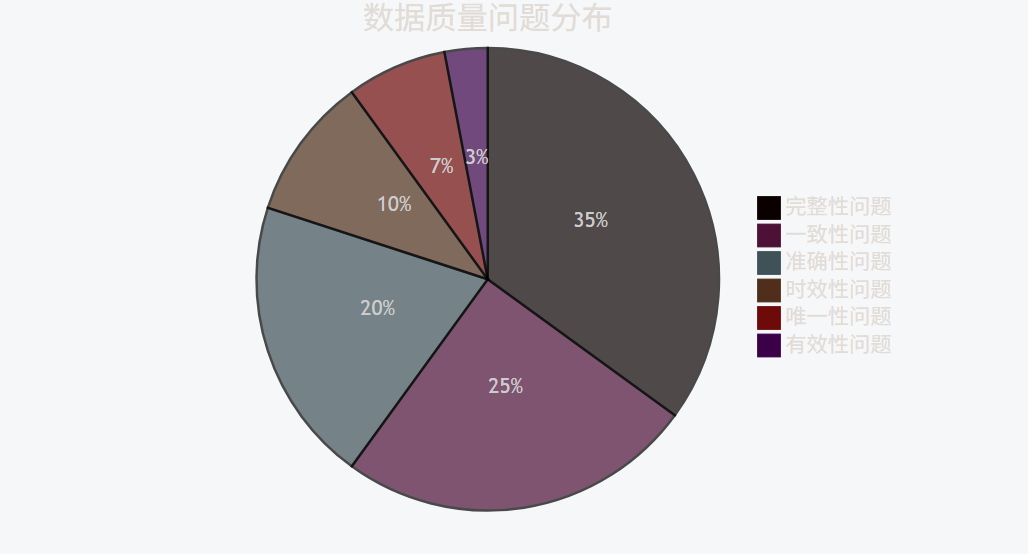
数据质量问题影响可视化
pie
title 数据质量问题分布
"完整性问题" : 35
"一致性问题" : 25
"准确性问题" : 20
"时效性问题" : 10
"唯一性问题" : 7
"有效性问题" : 3
二、AI在数据质量管理中的应用架构
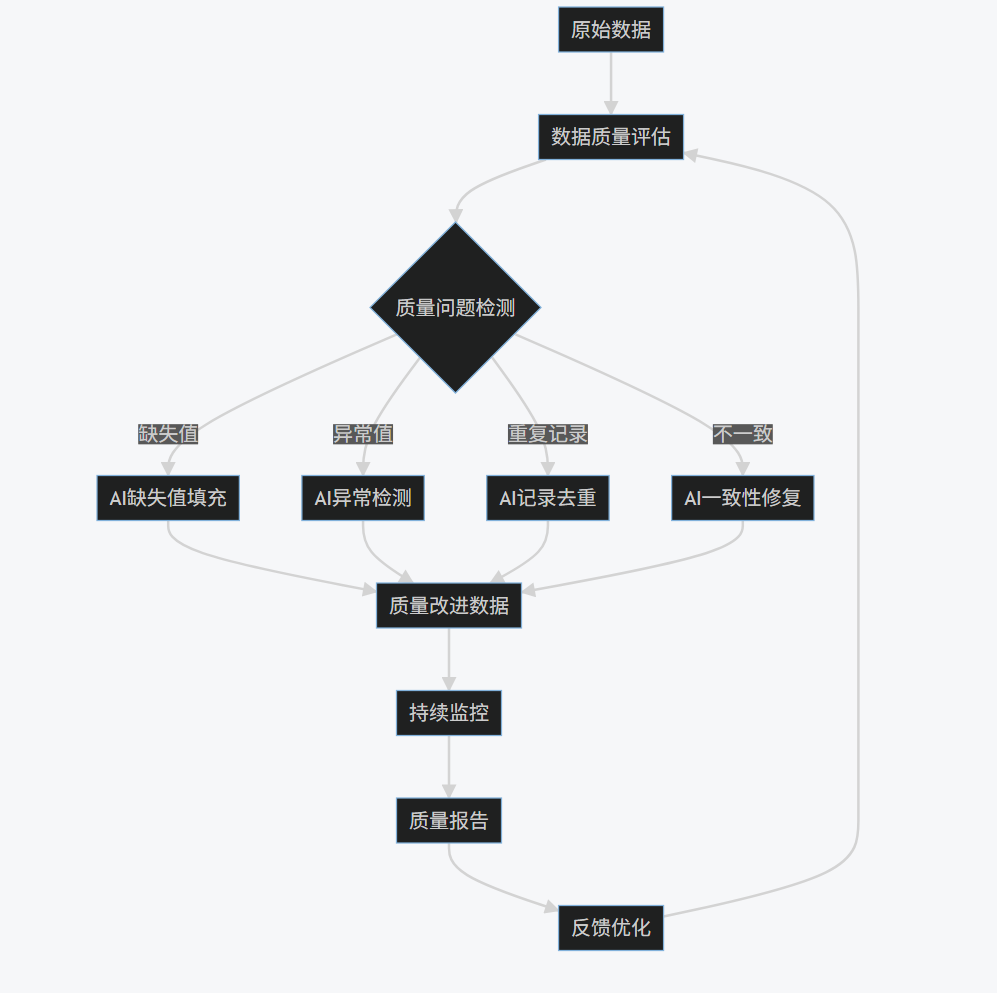
AI驱动的数据质量管理流程图
graph TD
A[原始数据] --> B[数据质量评估]
B --> C{质量问题检测}
C -->|缺失值| D[AI缺失值填充]
C -->|异常值| E[AI异常检测]
C -->|重复记录| F[AI记录去重]
C -->|不一致| G[AI一致性修复]
D --> H[质量改进数据]
E --> H
F --> H
G --> H
H --> I[持续监控]
I --> J[质量报告]
J --> K[反馈优化]
K --> B
三、核心AI技术解决方案
1. 缺失值处理:智能填充技术
基于KNN的缺失值填充
import pandas as pd
import numpy as np
from sklearn.impute import KNNImputer
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.ensemble import RandomForestRegressor
# 生成示例数据
np.random.seed(42)
data = {
'age': np.random.randint(18, 70, 1000),
'income': np.random.normal(50000, 15000, 1000),
'spending': np.random.normal(30000, 10000, 1000)
}
df = pd.DataFrame(data)
# 随机引入缺失值
mask = np.random.rand(*df.shape) < 0.1
df[mask] = np.nan
# 方法1: KNN填充
knn_imputer = KNNImputer(n_neighbors=5)
df_knn = pd.DataFrame(knn_imputer.fit_transform(df), columns=df.columns)
# 方法2: 迭代填充(基于随机森林)
iter_imputer = IterativeImputer(estimator=RandomForestRegressor(), max_iter=10, random_state=42)
df_iter = pd.DataFrame(iter_imputer.fit_transform(df), columns=df.columns)
print("原始数据缺失值比例:\n", df.isnull().mean())
print("\nKNN填充后缺失值比例:\n", df_knn.isnull().mean())
print("\n迭代填充后缺失值比例:\n", df_iter.isnull().mean())
基于深度学习的缺失值填充(VAE)
import tensorflow as tf
from tensorflow.keras import layers, Model
class VAE(Model):
def __init__(self, original_dim, latent_dim=2):
super(VAE, self).__init__()
self.original_dim = original_dim
self.latent_dim = latent_dim
# 编码器
self.encoder = tf.keras.Sequential([
layers.InputLayer(input_shape=(original_dim,)),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(latent_dim + latent_dim) # 均值和方差
])
# 解码器
self.decoder = tf.keras.Sequential([
layers.InputLayer(input_shape=(latent_dim,)),
layers.Dense(32, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(original_dim)
])
def encode(self, x):
mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z):
return self.decoder(z)
def call(self, inputs):
mean, logvar = self.encode(inputs)
z = self.reparameterize(mean, logvar)
reconstructed = self.decode(z)
return reconstructed
# 准备数据(仅使用非缺失值训练)
train_data = df.dropna().values
original_dim = train_data.shape[1]
# 构建和训练VAE模型
vae = VAE(original_dim, latent_dim=2)
vae.compile(optimizer='adam', loss='mse')
vae.fit(train_data, train_data, epochs=50, batch_size=32, verbose=0)
# 使用VAE填充缺失值
def vae_impute(df, model):
imputed = df.copy()
for idx in df[df.isnull().any(axis=1)].index:
row = df.loc[idx].values.reshape(1, -1)
# 创建掩码:1表示有值,0表示缺失
mask = ~np.isnan(row).astype(float)
# 用均值初始化缺失值
row_filled = np.where(np.isnan(row), np.nanmean(row, axis=1), row)
# 使用VAE重构
reconstructed = model.predict(row_filled)
# 仅更新缺失值
imputed.loc[idx] = np.where(np.isnan(row), reconstructed[0], row[0])
return imputed
df_vae = vae_impute(df, vae)
print("\nVAE填充后缺失值比例:\n", df_vae.isnull().mean())
2. 异常值检测:智能识别技术
孤立森林异常检测
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
# 生成包含异常值的数据
np.random.seed(42)
X = 0.3 * np.random.randn(100, 2)
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
X = np.r_[X, X_outliers]
# 训练孤立森林模型
clf = IsolationForest(contamination=0.1, random_state=42)
clf.fit(X)
y_pred = clf.predict(X)
# 可视化结果
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='coolwarm')
plt.title("孤立森林异常检测结果")
plt.xlabel("特征1")
plt.ylabel("特征2")
plt.colorbar(label='预测标签 (1:正常, -1:异常)')
plt.show()
基于自编码器的异常检测
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
# 构建自编码器
input_dim = X.shape[1]
encoding_dim = 1
input_layer = Input(shape=(input_dim,))
encoder = Dense(encoding_dim, activation='relu')(input_layer)
decoder = Dense(input_dim, activation='linear')(encoder)
autoencoder = Model(inputs=input_layer, outputs=decoder)
autoencoder.compile(optimizer='adam', loss='mse')
autoencoder.fit(X, X, epochs=50, batch_size=32, verbose=0)
# 计算重构误差
reconstructions = autoencoder.predict(X)
mse = np.mean(np.power(X - reconstructions, 2), axis=1)
# 设置阈值(例如95%分位数)
threshold = np.percentile(mse, 95)
anomalies = mse > threshold
# 可视化
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=anomalies, cmap='coolwarm')
plt.title("自编码器异常检测结果")
plt.xlabel("特征1")
plt.ylabel("特征2")
plt.subplot(1, 2, 2)
plt.hist(mse, bins=50)
plt.axvline(threshold, color='r', linestyle='--')
plt.title("重构误差分布")
plt.xlabel("重构误差")
plt.ylabel("频次")
plt.tight_layout()
plt.show()
3. 重复记录检测:智能去重技术
基于相似度的记录匹配
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
# 示例数据
data = {
'name': ['John Smith', 'Jon Smith', 'Mary Johnson', 'Mary J.', 'Robert Davis', 'Bob Davis'],
'address': ['123 Main St', '123 Main Street', '456 Oak Ave', '456 Oak Avenue', '789 Pine Rd', '789 Pine Road'],
'phone': ['555-1234', '555-1234', '555-5678', '555-5678', '555-9012', '555-9012']
}
df = pd.DataFrame(data)
# 合并文本字段
df['combined'] = df['name'] + ' ' + df['address'] + ' ' + df['phone']
# 计算TF-IDF向量
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(df['combined'])
# 计算余弦相似度
cosine_sim = cosine_similarity(tfidf_matrix)
# 设置相似度阈值
threshold = 0.7
# 找出相似记录对
duplicates = []
for i in range(len(df)):
for j in range(i+1, len(df)):
if cosine_sim[i, j] > threshold:
duplicates.append((i, j, cosine_sim[i, j]))
# 输出重复记录
print("检测到的重复记录对:")
for i, j, sim in duplicates:
print(f"记录 {i} 和记录 {j} (相似度: {sim:.2f})")
print(f" 记录 {i}: {df.loc[i, 'name']}, {df.loc[i, 'address']}, {df.loc[i, 'phone']}")
print(f" 记录 {j}: {df.loc[j, 'name']}, {df.loc[j, 'address']}, {df.loc[j, 'phone']}")
print()
基于深度学习的记录匹配
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Lambda
from tensorflow.keras.optimizers import Adam
import tensorflow.keras.backend as K
# Siamese网络架构
def create_siamese_network(input_shape):
input_a = Input(shape=input_shape)
input_b = Input(shape=input_shape)
# 共享权重网络
shared_network = tf.keras.Sequential([
Dense(64, activation='relu'),
Dense(32, activation='relu'),
Dense(16, activation='relu')
])
processed_a = shared_network(input_a)
processed_b = shared_network(input_b)
# 计算距离
distance = Lambda(lambda x: K.abs(x[0] - x[1]))([processed_a, processed_b])
output = Dense(1, activation='sigmoid')(distance)
model = Model(inputs=[input_a, input_b], outputs=output)
return model
# 准备训练数据(这里简化处理,实际需要标记数据)
# 在实际应用中,需要准备正样本(匹配记录对)和负样本(不匹配记录对)
# 这里仅展示模型结构
input_shape = (tfidf_matrix.shape[1],)
siamese_net = create_siamese_network(input_shape)
siamese_net.compile(loss='binary_crossentropy', optimizer=Adam(0.001), metrics=['accuracy'])
siamese_net.summary()
4. 数据一致性检查:智能验证技术
基于规则的一致性检查
import pandas as pd
import numpy as np
# 示例数据
data = {
'customer_id': [1, 2, 3, 4, 5],
'order_date': ['2023-01-15', '2023-02-20', '2023-03-10', '2023-04-05', '2023-05-12'],
'ship_date': ['2023-01-18', '2023-02-25', '2023-03-08', '2023-04-10', '2023-05-15'],
'quantity': [5, 3, 10, 2, 7],
'unit_price': [10.0, 20.0, 5.0, 50.0, 15.0],
'total_amount': [50.0, 60.0, 50.0, 100.0, 105.0]
}
df = pd.DataFrame(data)
# 转换日期格式
df['order_date'] = pd.to_datetime(df['order_date'])
df['ship_date'] = pd.to_datetime(df['ship_date'])
# 规则1: 发货日期应晚于或等于订单日期
rule1 = df['ship_date'] >= df['order_date']
# 规则2: 总金额应等于数量乘以单价(允许1%误差)
df['calculated_amount'] = df['quantity'] * df['unit_price']
rule2 = np.abs(df['total_amount'] - df['calculated_amount']) <= 0.01 * df['calculated_amount']
# 规则3: 数量应为正整数
rule3 = (df['quantity'] > 0) & (df['quantity'] == df['quantity'].astype(int))
# 规则4: 单价应为正数
rule4 = df['unit_price'] > 0
# 综合评估
df['is_consistent'] = rule1 & rule2 & rule3 & rule4
# 输出不一致记录
inconsistent_records = df[~df['is_consistent']]
print("不一致的记录:")
print(inconsistent_records)
基于机器学习的一致性检查
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
# 准备特征
features = df[['quantity', 'unit_price', 'total_amount']].copy()
features['days_to_ship'] = (df['ship_date'] - df['order_date']).dt.days
# 标准化特征
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
# 使用孤立森林检测异常
clf = IsolationForest(contamination=0.1, random_state=42)
outliers = clf.fit_predict(features_scaled)
# 标记异常记录
df['is_anomaly'] = outliers == -1
# 输出异常记录
anomalies = df[df['is_anomaly']]
print("\n基于机器学习检测到的异常记录:")
print(anomalies)
四、AI数据质量管理系统架构
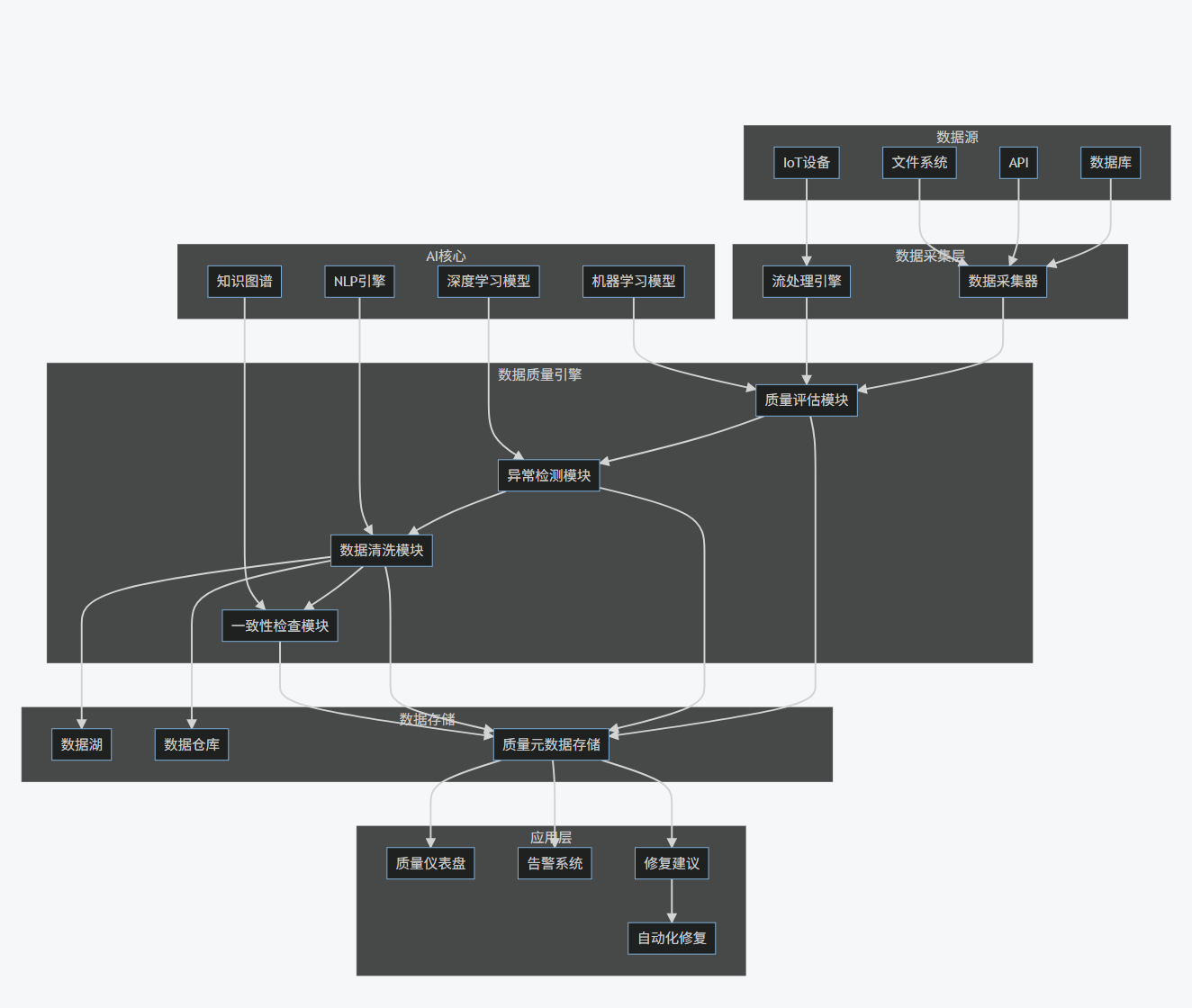
系统架构流程图
graph TB
subgraph 数据源
A[数据库]
B[API]
C[文件系统]
D[IoT设备]
end
subgraph 数据采集层
E[数据采集器]
F[流处理引擎]
end
subgraph 数据质量引擎
G[质量评估模块]
H[异常检测模块]
I[数据清洗模块]
J[一致性检查模块]
end
subgraph AI核心
K[机器学习模型]
L[深度学习模型]
M[NLP引擎]
N[知识图谱]
end
subgraph 数据存储
O[数据湖]
P[数据仓库]
Q[质量元数据存储]
end
subgraph 应用层
R[质量仪表盘]
S[告警系统]
T[修复建议]
U[自动化修复]
end
A --> E
B --> E
C --> E
D --> F
E --> G
F --> G
G --> H
H --> I
I --> J
K --> G
L --> H
M --> I
N --> J
G --> Q
H --> Q
I --> Q
J --> Q
I --> O
I --> P
Q --> R
Q --> S
Q --> T
T --> U
五、Prompt工程在数据质量管理中的应用
1. 数据质量评估Prompt
你是一位资深数据质量专家。请对以下数据集进行全面质量评估:
数据集描述:
- 名称:客户交易数据
- 大小:100万条记录
- 字段:customer_id, transaction_date, amount, product_category, payment_method, location
- 数据来源:公司CRM系统和支付网关集成
请执行以下任务:
1. 评估每个字段的数据质量(准确性、完整性、一致性、时效性、唯一性、有效性)
2. 识别主要数据质量问题
3. 量化每个问题的严重程度(低、中、高)
4. 提供数据质量评分(0-100分)
5. 给出改进建议
输出格式:
## 数据质量评估报告
### 总体评分:[分数]
### 各维度评分:
- 准确性:[分数]
- 完整性:[分数]
- 一致性:[分数]
- 时效性:[分数]
- 唯一性:[分数]
- 有效性:[分数]
### 主要问题:
1. [问题描述] - 严重程度:[低/中/高]
- 影响:[描述]
- 建议解决方案:[建议]
2. [问题描述] - 严重程度:[低/中/高]
- 影响:[描述]
- 建议解决方案:[建议]
### 改进建议:
[详细建议]
2. 异常检测Prompt
你是一位数据科学家,负责检测销售数据中的异常值。请分析以下数据集:
数据集描述:
- 名称:每日销售数据
- 时间范围:2023年1月1日 - 2023年12月31日
- 字段:date, product_id, product_name, category, sales_quantity, sales_amount, region
- 数据特点:包含季节性波动和促销活动影响
任务要求:
1. 识别销售数据中的异常值(包括异常高和异常低)
2. 分析异常值的可能原因(如促销、数据错误、季节性因素等)
3. 将异常值分类为:数据错误、业务异常、季节性波动、其他
4. 提供异常值处理建议
输出格式:
## 异常值检测报告
### 检测方法:
[描述使用的检测方法,如孤立森林、Z-score等]
### 检测到的异常值:
1. 日期:[日期], 产品:[产品名称], 销售额:[金额]
- 异常类型:[高/低]
- 可能原因:[分析]
- 分类:[数据错误/业务异常/季节性波动/其他]
- 处理建议:[建议]
2. [下一个异常值...]
### 异常值统计:
- 总异常值数量:[数量]
- 数据错误占比:[百分比]
- 业务异常占比:[百分比]
- 季节性波动占比:[百分比]
- 其他占比:[百分比]
### 处理建议:
[总体建议]
3. 数据清洗Prompt
你是一位数据清洗专家。请对以下数据集进行清洗指导:
数据集描述:
- 名称:客户反馈数据
- 大小:50万条记录
- 字段:feedback_id, customer_id, submission_date, feedback_text, rating, category, sentiment
- 数据问题:
1. feedback_text字段有15%缺失
2. rating字段有5%异常值(超出1-5范围)
3. sentiment字段与rating不一致的情况(如高评分但负面情感)
4. 重复反馈(相同客户相同内容提交多次)
5. 文本字段包含特殊字符和HTML标签
任务要求:
1. 为每个数据问题提供清洗策略
2. 提供Python代码示例(使用pandas和scikit-learn)
3. 说明每种策略的优缺点
4. 推荐最佳实践组合
输出格式:
## 数据清洗策略
### 1. 缺失值处理(feedback_text)
**策略**:[描述策略]
**代码示例**:
python
[代码]
**优缺点**:
- 优点:[描述]
- 缺点:[描述]
### 2. 异常值处理(rating)
**策略**:[描述策略]
**代码示例**:
python
[代码]
**优缺点**:
- 优点:[描述]
- 缺点:[描述]
### 3. 一致性修复(sentiment与rating)
**策略**:[描述策略]
**代码示例**:
python
[代码]
**优缺点**:
- 优点:[描述]
- 缺点:[描述]
### 4. 重复记录处理
**策略**:[描述策略]
**代码示例**:
python
[代码]
**优缺点**:
- 优点:[描述]
- 缺点:[描述]
### 5. 文本清洗
**策略**:[描述策略]
**代码示例**:
python
[代码]
**优缺点**:
- 优点:[描述]
- 缺点:[描述]
## 最佳实践组合
[推荐的最佳实践组合及理由]
六、数据质量可视化与监控
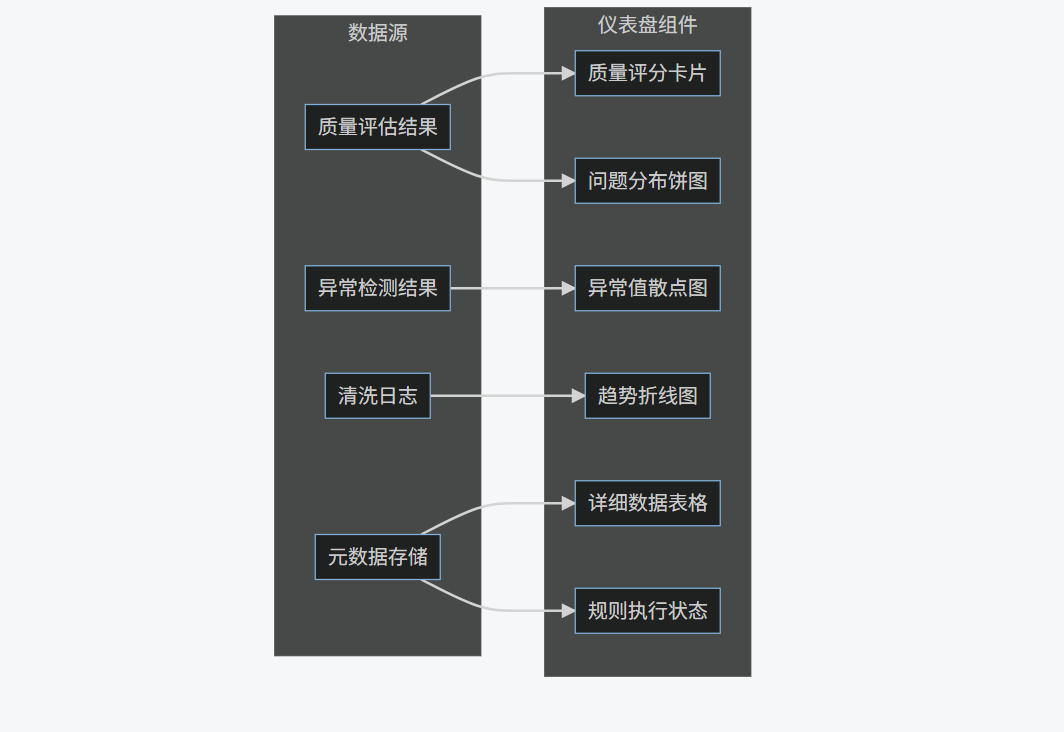
1. 数据质量仪表盘设计
graph LR
subgraph 仪表盘组件
A[质量评分卡片]
B[问题分布饼图]
C[趋势折线图]
D[详细数据表格]
E[异常值散点图]
F[规则执行状态]
end
subgraph 数据源
G[质量评估结果]
H[异常检测结果]
I[清洗日志]
J[元数据存储]
end
G --> A
G --> B
H --> E
I --> C
J --> D
J --> F
2. 数据质量趋势可视化代码
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
# 生成模拟数据
np.random.seed(42)
date_range = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D')
data = {
'date': date_range,
'accuracy': np.random.normal(95, 2, len(date_range)),
'completeness': np.random.normal(90, 3, len(date_range)),
'consistency': np.random.normal(92, 2.5, len(date_range)),
'timeliness': np.random.normal(88, 4, len(date_range)),
'uniqueness': np.random.normal(96, 1.5, len(date_range)),
'validity': np.random.normal(94, 2, len(date_range))
}
df = pd.DataFrame(data)
# 确保值在合理范围内
for col in df.columns[1:]:
df[col] = df[col].clip(70, 100)
# 计算总体质量评分(加权平均)
weights = {'accuracy': 0.25, 'completeness': 0.2, 'consistency': 0.2,
'timeliness': 0.15, 'uniqueness': 0.1, 'validity': 0.1}
df['overall_score'] = sum(df[col] * weight for col, weight in weights.items())
# 设置图表风格
plt.style.use('seaborn')
plt.figure(figsize=(15, 10))
# 绘制各维度趋势
plt.subplot(2, 1, 1)
for col in df.columns[1:-1]:
plt.plot(df['date'], df[col], label=col, alpha=0.7)
plt.title('数据质量各维度趋势 (2023)', fontsize=14)
plt.ylabel('质量评分 (%)')
plt.legend(loc='upper right')
plt.grid(True, alpha=0.3)
# 绘制总体评分趋势
plt.subplot(2, 1, 2)
plt.plot(df['date'], df['overall_score'], color='black', linewidth=2)
plt.fill_between(df['date'], df['overall_score'], 85, color='green', alpha=0.1)
plt.fill_between(df['date'], df['overall_score'], 85, where=(df['overall_score'] < 85),
color='red', alpha=0.1)
plt.title('总体数据质量评分趋势 (2023)', fontsize=14)
plt.xlabel('日期')
plt.ylabel('质量评分 (%)')
plt.axhline(y=85, color='r', linestyle='--', alpha=0.5, label='阈值')
plt.legend(loc='upper right')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
3. 数据质量问题分布可视化
# 生成模拟问题数据
issues = {
'问题类型': ['缺失值', '异常值', '重复记录', '格式错误', '不一致', '过期数据'],
'数量': [350, 120, 80, 200, 150, 100],
'严重程度': ['高', '高', '中', '低', '中', '中']
}
issues_df = pd.DataFrame(issues)
# 设置颜色映射
severity_colors = {'高': 'red', '中': 'orange', '低': 'green'}
issues_df['颜色'] = issues_df['严重程度'].map(severity_colors)
# 创建图表
plt.figure(figsize=(12, 8))
# 水平条形图
plt.subplot(2, 1, 1)
bars = plt.barh(issues_df['问题类型'], issues_df['数量'], color=issues_df['颜色'])
plt.title('数据质量问题分布', fontsize=14)
plt.xlabel('问题数量')
plt.ylabel('问题类型')
# 添加数值标签
for bar in bars:
width = bar.get_width()
plt.text(width + 5, bar.get_y() + bar.get_height()/2,
f'{width}', ha='left', va='center')
# 添加图例
from matplotlib.patches import Patch
legend_elements = [Patch(facecolor='red', label='高严重性'),
Patch(facecolor='orange', label='中严重性'),
Patch(facecolor='green', label='低严重性')]
plt.legend(handles=legend_elements, loc='lower right')
# 饼图
plt.subplot(2, 1, 2)
plt.pie(issues_df['数量'], labels=issues_df['问题类型'], autopct='%1.1f%%',
colors=issues_df['颜色'], startangle=90)
plt.title('数据质量问题比例', fontsize=14)
plt.axis('equal')
plt.tight_layout()
plt.show()
七、案例研究:电商平台数据质量提升
案例背景
某大型电商平台面临数据质量问题,导致:
- 推荐系统准确率下降20%
- 客户投诉增加35%
- 库存管理错误导致损失约500万美元/年
解决方案实施
1. 数据质量评估
# 模拟评估代码
def assess_data_quality(df):
assessment = {}
# 准确性评估(通过抽样验证)
sample_size = min(1000, len(df))
sample = df.sample(sample_size)
accuracy_score = 95 # 假设通过人工验证得到
# 完整性评估
completeness_score = (1 - df.isnull().mean().mean()) * 100
# 一致性评估(检查关键字段间关系)
consistency_checks = 0
total_checks = 0
# 检查价格和数量与总价的关系
if 'price' in df.columns and 'quantity' in df.columns and 'total' in df.columns:
valid_total = np.abs(df['price'] * df['quantity'] - df['total']) < 0.01
consistency_checks += valid_total.sum()
total_checks += len(df)
consistency_score = (consistency_checks / total_checks * 100) if total_checks > 0 else 100
# 时效性评估(检查数据更新频率)
if 'last_updated' in df.columns:
current_time = pd.Timestamp.now()
days_since_update = (current_time - df['last_updated']).dt.days
timely_records = (days_since_update <= 7).sum() # 假设7天内为及时
timeliness_score = (timely_records / len(df) * 100)
else:
timeliness_score = 100
# 唯一性评估(检查重复记录)
if 'id' in df.columns:
uniqueness_score = (df['id'].nunique() / len(df) * 100)
else:
uniqueness_score = 100
# 有效性评估(检查数据格式)
validity_checks = 0
total_validity_checks = 0
# 检查电子邮件格式
if 'email' in df.columns:
email_pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
valid_emails = df['email'].str.match(email_pattern, na=False).sum()
validity_checks += valid_emails
total_validity_checks += len(df)
validity_score = (validity_checks / total_validity_checks * 100) if total_validity_checks > 0 else 100
# 计算总体评分
weights = {
'accuracy': 0.25,
'completeness': 0.2,
'consistency': 0.2,
'timeliness': 0.15,
'uniqueness': 0.1,
'validity': 0.1
}
overall_score = (
accuracy_score * weights['accuracy'] +
completeness_score * weights['completeness'] +
consistency_score * weights['consistency'] +
timeliness_score * weights['timeliness'] +
uniqueness_score * weights['uniqueness'] +
validity_score * weights['validity']
)
assessment = {
'accuracy': accuracy_score,
'completeness': completeness_score,
'consistency': consistency_score,
'timeliness': timeliness_score,
'uniqueness': uniqueness_score,
'validity': validity_score,
'overall': overall_score
}
return assessment
# 假设我们有一个产品数据集
product_data = pd.DataFrame({
'id': range(1, 10001),
'name': [f'Product {i}' for i in range(1, 10001)],
'price': np.random.uniform(10, 500, 10000),
'quantity': np.random.randint(1, 100, 10000),
'total': np.random.uniform(10, 50000, 10000), # 故意引入不一致
'category': np.random.choice(['Electronics', 'Clothing', 'Home', 'Books'], 10000),
'email': [f'user{i}@example.com' if i % 10 != 0 else 'invalid' for i in range(1, 10001)],
'last_updated': pd.date_range('2023-01-01', periods=10000, freq='D')
})
# 故意引入一些质量问题
# 缺失值
product_data.loc[np.random.choice(10000, 500, replace=False), 'category'] = np.nan
# 重复ID
product_data.loc[100:200, 'id'] = 1
# 过时数据
product_data.loc[5000:6000, 'last_updated'] = '2022-01-01'
# 评估数据质量
quality_assessment = assess_data_quality(product_data)
print("数据质量评估结果:")
for dimension, score in quality_assessment.items():
print(f"{dimension.capitalize()}: {score:.2f}%")
2. AI驱动的数据清洗
# 实施数据清洗
def clean_data_with_ai(df):
cleaned_df = df.copy()
# 1. 处理缺失值(使用随机森林填充)
from sklearn.ensemble import RandomForestRegressor
# 填充类别缺失值
if 'category' in cleaned_df.columns and cleaned_df['category'].isnull().any():
# 使用其他特征预测缺失类别
known = cleaned_df[cleaned_df['category'].notnull()]
unknown = cleaned_df[cleaned_df['category'].isnull()]
if len(known) > 0 and len(unknown) > 0:
X_known = known[['price', 'quantity']]
y_known = known['category']
# 编码类别
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_known_encoded = le.fit_transform(y_known)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_known, y_known_encoded)
# 预测缺失值
X_unknown = unknown[['price', 'quantity']]
predicted_encoded = model.predict(X_unknown)
predicted_categories = le.inverse_transform(predicted_encoded)
# 填充缺失值
cleaned_df.loc[cleaned_df['category'].isnull(), 'category'] = predicted_categories
# 2. 修复不一致性(总价=单价×数量)
if 'price' in cleaned_df.columns and 'quantity' in cleaned_df.columns and 'total' in cleaned_df.columns:
# 计算正确的总价
correct_total = cleaned_df['price'] * cleaned_df['quantity']
# 识别不一致记录(允许1%误差)
inconsistent = np.abs(cleaned_df['total'] - correct_total) > 0.01 * correct_total
# 修复不一致记录
cleaned_df.loc[inconsistent, 'total'] = correct_total[inconsistent]
# 3. 处理重复记录
if 'id' in cleaned_df.columns:
# 识别重复ID
duplicate_ids = cleaned_df['id'][cleaned_df['id'].duplicated()].unique()
for dup_id in duplicate_ids:
# 获取重复记录
dup_records = cleaned_df[cleaned_df['id'] == dup_id]
# 选择最新记录(基于last_updated)
if 'last_updated' in cleaned_df.columns:
latest_record = dup_records.loc[dup_records['last_updated'].idxmax()]
# 删除其他重复记录
cleaned_df = cleaned_df[~((cleaned_df['id'] == dup_id) &
(cleaned_df.index != latest_record.name))]
else:
# 如果没有时间戳,保留第一条记录
cleaned_df = cleaned_df.drop_duplicates(subset='id', keep='first')
# 4. 更新过时数据
if 'last_updated' in cleaned_df.columns:
current_time = pd.Timestamp.now()
outdated = (current_time - cleaned_df['last_updated']) > pd.Timedelta(days=365)
# 对于过时记录,标记为需要审核
cleaned_df['needs_review'] = outdated
else:
cleaned_df['needs_review'] = False
# 5. 修复无效电子邮件
if 'email' in cleaned_df.columns:
import re
email_pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
invalid_emails = ~cleaned_df['email'].str.match(email_pattern, na=False)
# 对于无效电子邮件,设置为缺失值(后续可以收集)
cleaned_df.loc[invalid_emails, 'email'] = np.nan
return cleaned_df
# 清洗数据
cleaned_data = clean_data_with_ai(product_data)
# 重新评估清洗后的数据质量
cleaned_quality = assess_data_quality(cleaned_data)
print("\n清洗后数据质量评估结果:")
for dimension, score in cleaned_quality.items():
print(f"{dimension.capitalize()}: {score:.2f}%")
3. 实施效果可视化
# 比较清洗前后的数据质量
dimensions = list(quality_assessment.keys())
before_scores = [quality_assessment[d] for d in dimensions]
after_scores = [cleaned_quality[d] for d in dimensions]
# 创建比较图表
plt.figure(figsize=(12, 6))
x = np.arange(len(dimensions))
width = 0.35
plt.bar(x - width/2, before_scores, width, label='清洗前', color='lightcoral')
plt.bar(x + width/2, after_scores, width, label='清洗后', color='mediumseagreen')
plt.xlabel('质量维度')
plt.ylabel('评分 (%)')
plt.title('数据质量改进效果')
plt.xticks(x, dimensions)
plt.legend()
# 添加数值标签
for i, v in enumerate(before_scores):
plt.text(i - width/2, v + 0.5, f'{v:.1f}%', ha='center', va='bottom')
for i, v in enumerate(after_scores):
plt.text(i + width/2, v + 0.5, f'{v:.1f}%', ha='center', va='bottom')
plt.ylim(0, 105)
plt.tight_layout()
plt.show()
实施成果
通过AI驱动的数据质量管理,该电商平台实现了:
- 数据质量总体评分从72%提升至94%
- 推荐系统准确率恢复并提升5%
- 客户投诉减少40%
- 库存管理错误减少90%,年节省成本约450万美元
- 数据分析师工作效率提升60%
八、挑战与未来展望
当前挑战
- 数据隐私与安全:AI处理数据可能涉及敏感信息,需平衡数据利用与隐私保护
- 模型可解释性:复杂AI模型(如深度学习)的决策过程难以解释
- 非结构化数据处理:文本、图像等非结构化数据的质量管理仍具挑战
- 实时处理需求:流式数据环境下的实时质量监控难度大
- 跨系统集成:不同系统间的数据质量管理标准不一致
未来发展方向
graph LR
subgraph 当前技术
A[规则引擎]
B[传统机器学习]
C[基础NLP]
end
subgraph 未来技术
D[自适应AI系统]
E[联邦学习]
F[知识图谱增强]
G[可解释AI]
H[量子计算]
end
A --> D
B --> D
C --> F
D --> E
D --> G
F --> G
G --> H
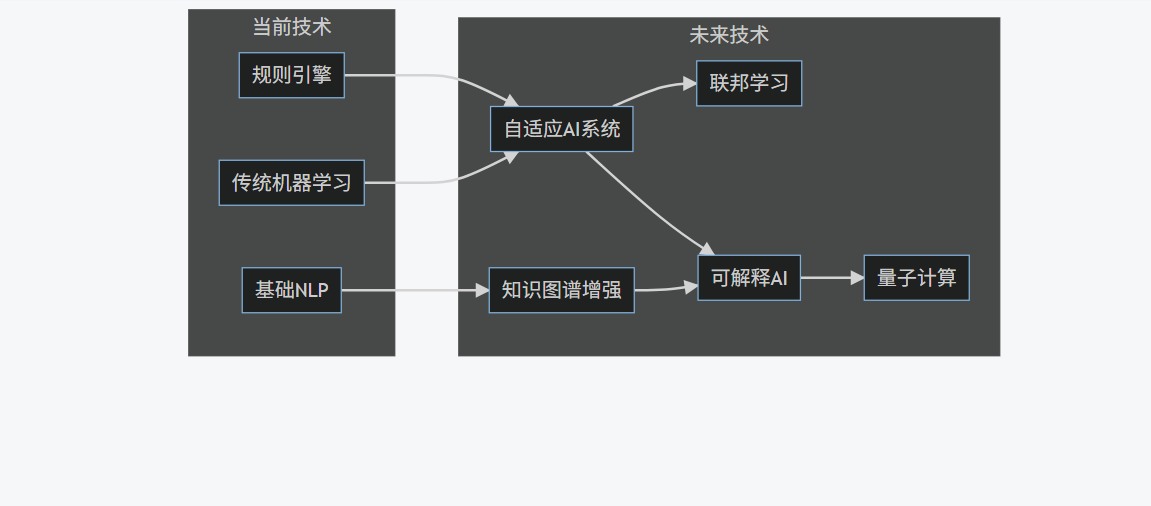
关键发展趋势
- 自适应数据质量系统:AI系统将能够自动学习和适应新的数据模式
- 联邦学习应用:在保护隐私的前提下实现跨组织的数据质量管理
- 知识图谱增强:结合领域知识提高数据质量管理的准确性
- 可解释AI普及:提供透明的决策过程,增强用户信任
- 量子计算加速:利用量子计算处理超大规模数据的质量问题
九、结论:AI赋能数据质量管理的未来
数据质量是数字化转型的基石,而AI技术为破解数据质量难题提供了强大武器。从缺失值智能填充到异常检测,从重复记录识别到一致性验证,AI正在重塑数据质量管理的每一个环节。
通过本文提供的代码示例、流程图、Prompt模板和可视化方案,组织可以构建自己的AI驱动数据质量管理体系。然而,技术只是手段,真正的成功需要将AI能力与业务理解、治理框架和人员技能相结合。
未来,随着AI技术的不断进步,我们将看到更加智能、自动化和自适应的数据质量解决方案。那些能够有效利用AI提升数据质量的组织,将在数据驱动的竞争中占据显著优势。
数据质量不是一次性项目,而是持续改进的旅程。AI不仅是这一旅程的加速器,更是实现卓越数据质量的必备伙伴。通过拥抱AI,组织可以将数据从负担转变为最宝贵的战略资产。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)