收藏必看!大模型并行计算全攻略:DP/PP/TP/EP技术详解与实战指南
文章详解了大模型训练中的四大并行计算方式:数据并行(DP)、流水线并行(PP)、张量并行(TP)和专家并行(EP),阐述其工作原理、优缺点及适用场景,介绍了ZeRO优化器减少内存占用的方法,并指出实际应用中常采用混合并行策略(如3D并行),提及DeepSpeed、Megatron-LM等开源工具,帮助开发者理解算力集群架构对并行计算的重要性。
大家都知道,AI计算(尤其是模型训练和推理),主要以并行计算为主。
AI计算中涉及到的很多具体算法(例如矩阵相乘、卷积、循环层、梯度运算等),都需要基于成千上万的GPU,以并行任务的方式去完成。这样才能有效缩短计算时间。
搭建并行计算框架,一般会用到以下几种常见的并行方式:
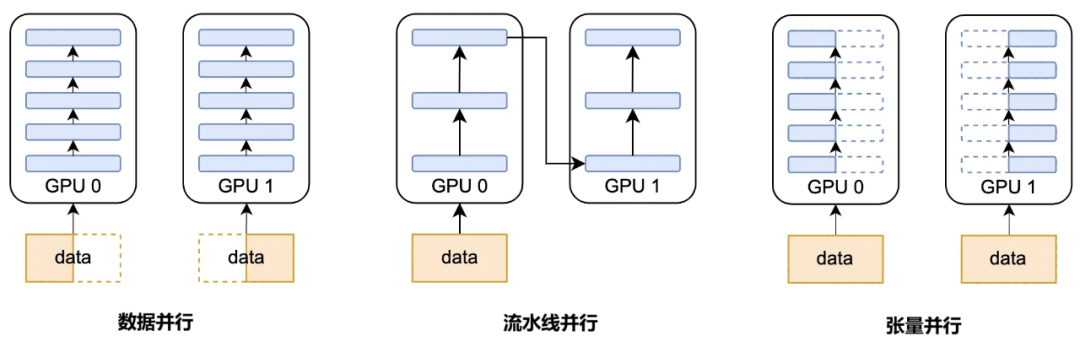
Data Parallelism,数据并行
Pipeline Parallelism,流水线并行
Tensor Parallelism,张量并行
Expert Parallelism, 专家并行
接下来,我们逐一看看,这些并行计算方式的工作原理。
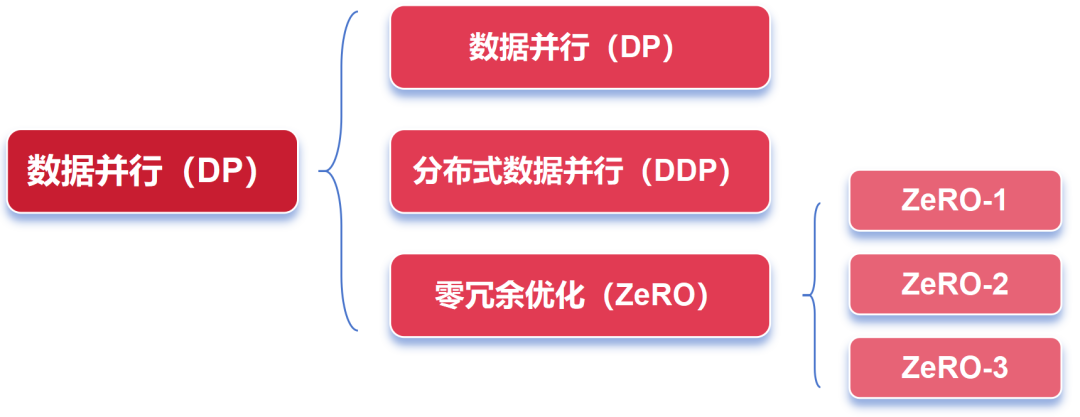
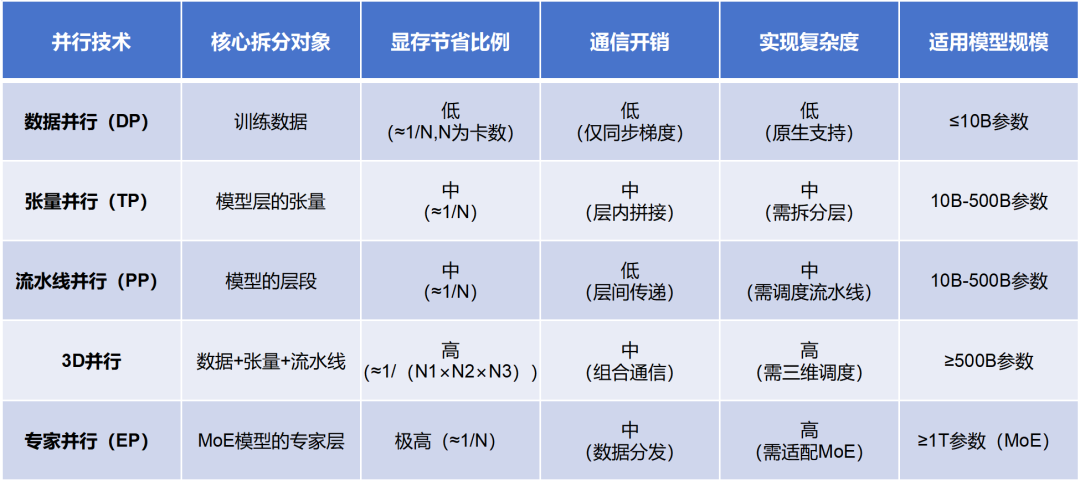
▉ DP(数据并行)
首先看看DP,数据并行(Data Parallelism)。
AI训练使用的并行,总的来说,分为数据并行和模型并行两类。刚才说的PP(流水线并行)、TP(张量并行)和EP(专家并行),都属于模型并行,待会再介绍。
这里,我们需要先大概了解一下神经网络的训练过程。简单来说,包括以下主要步骤:
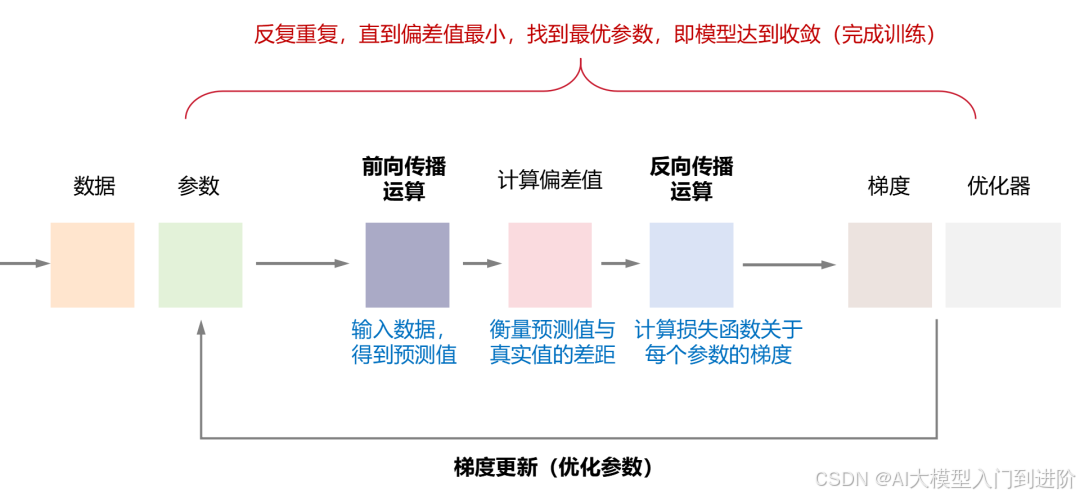
1、前向传播:输入一批训练数据,计算得到预测结果。
2、计算损失:通过损失函数比较预测结果与真实标签的差距。
3、反向传播:将损失值反向传播,计算网络中每个参数的梯度。
4、梯度更新:优化器使用这些梯度来更新所有的权重和偏置(更新参数)。
以上过程循环往复,直到模型的性能达到令人满意的水平。训练就完成了。
我们回到数据并行。
数据并行是大模型训练中最为常见的一种并行方式(当然,也适用于推理过程)。
它的核心思想很简单,就是每个GPU都拥有完整的模型副本,然后,将训练数据划分成多个小批次(mini-batch),每个批次分配给不同的GPU进行处理。
数据并行的情况下,大模型训练的过程是这样的:
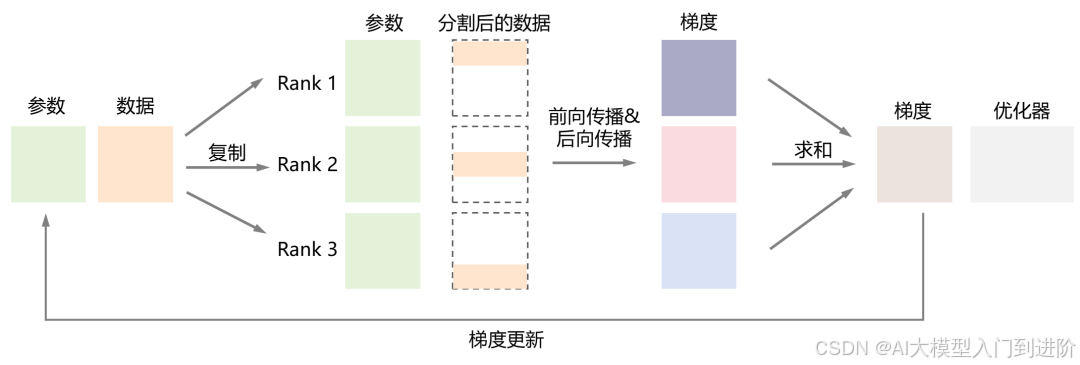
1、对数据进行均匀切割,发给不同的、并行工作的GPU(Worker);
2、各GPU都拥有一样的模型以及模型参数,它们各自独立进行前向传播、反向传播,计算得到各自的梯度;
3、各GPU通过卡间通信,以All-Reduce的通信方式,将梯度推给一个类似管理者的GPU(Server);
4、Server GPU对所有梯度进行求和或者平均,得到全局梯度;
5、Server GPU将全局梯度回传(broadcast广播)到每个Worker GPU,进行参数更新(更新本地模型权重)。更新后,所有worker GPU模型参数保持一致。
然后,再继续重复这样的过程,直至完成所有的训练。
再来一张图,帮助理解:
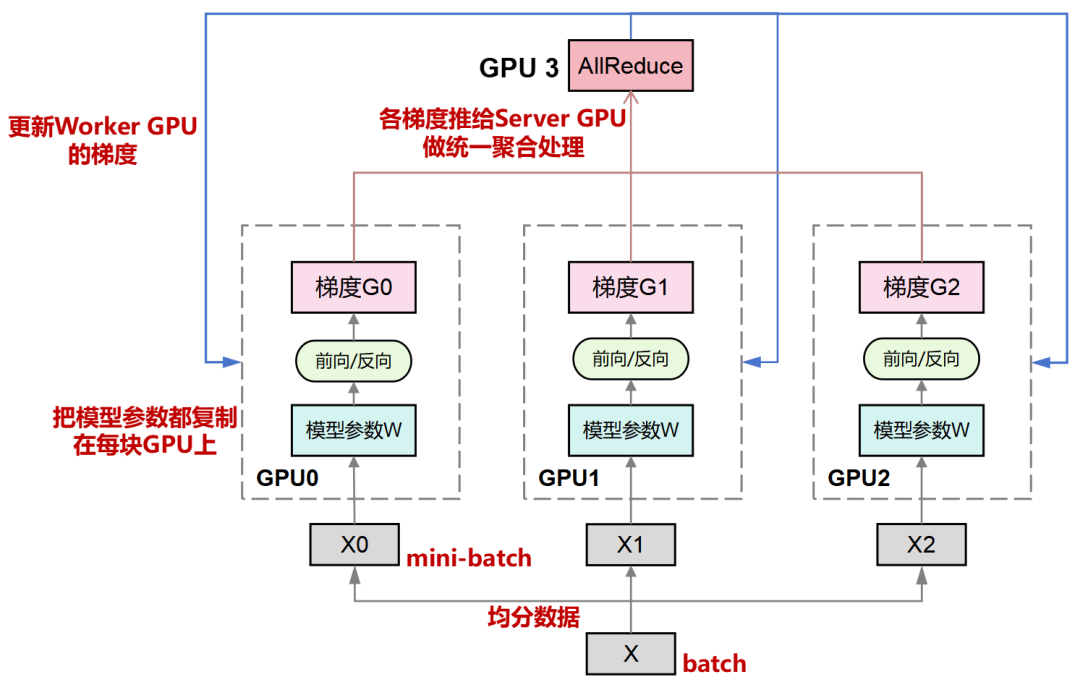
从下往上看
这里提到的All-Reduce,也是一个AI领域的常见概念,字面意思是“全(All)-规约(Reduce)”,即:对所有节点的数据进行聚合(如求和、求最大值),并将最终结果分发到所有节点。
数据并行的优点,在于实现过程比较简单,能够显著加速大规模数据的训练过程,尤其适用于数据量远大于模型参数的场景。
数据并行的缺点,在于显存的限制。因为每个GPU上都有完整的模型副本,而当模型的规模和参数越大,所需要的显存就越大,很可能超过单个GPU的显存大小。
数据并行的通信开销也比较大。不同GPU之间需要频繁通信,以同步模型参数或梯度。而且,模型参数规模越大,GPU数量越多,这个通信开销就越大。例如,对于千亿参数模型,单次梯度同步需传输约2TB数据(FP16精度下)。
▉ ZeRO
这里要插播介绍一个概念——ZeRO(Zero Redundancy Optimizer,零冗余优化器)。
在数据并行策略中,每个GPU的内存都保存一个完整的模型副本,很占内存空间。那么,能否每个GPU只存放模型副本的一部分呢?
没错,这就是ZeRo——通过对模型副本中的优化器状态、梯度和参数进行切分,来实现减少对内存的占用。
ZeRO有3个阶段,分别是:
ZeRO-1:对优化器状态进行划分。
ZeRO-2:对优化器状态和梯度进行划分
ZeRO-3:对优化器状态、梯度和参数进行划分。(最节省显存)
通过下面的图和表,可以看得更明白些:
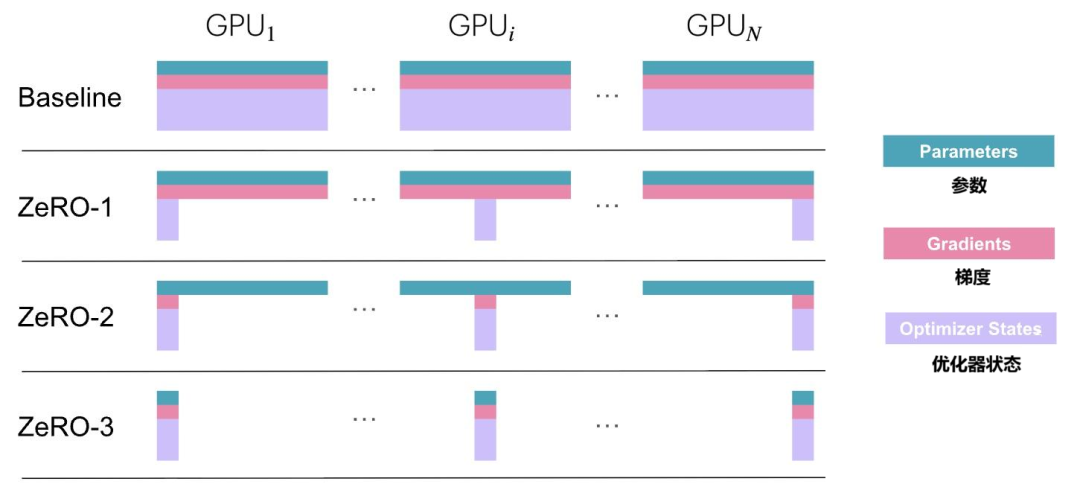
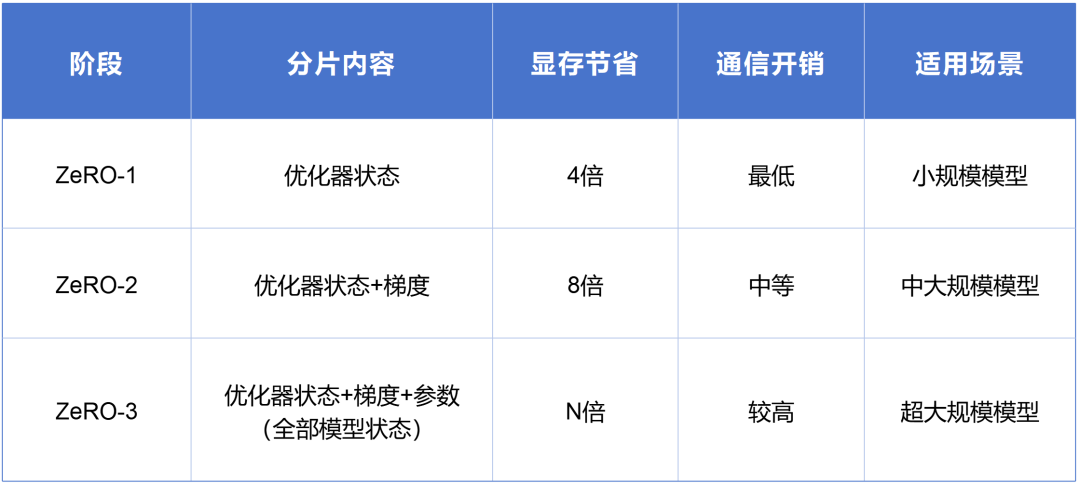
根据实测数据显示,ZeRO-3在1024块GPU上训练万亿参数模型时,显存占用从7.5TB降至7.3GB/卡。
值得一提的是,DP还有一个DDP(分布式数据并行)。传统DP一般用于单机多卡场景。而DDP能多机也能单机。这依赖于Ring-AllReduce,它由百度最先提出,可以有效解决数据并行中通信负载不均(Server存在瓶颈)的问题。
▉ PP(流水线并行)
再来看看模型并行。
刚才数据并行,是把数据分为好几个部分。模型并行,很显然,就是把模型分为好几个部分。不同的GPU,运行不同的部分。(注意:业界对模型并行的定义有点混乱。也有的资料会将张量并行等同于模型并行。)
流水线并行,是将模型的不同层(单层,或连续的多层)分配到不同的GPU上,按顺序处理数据,实现流水线式的并行计算。
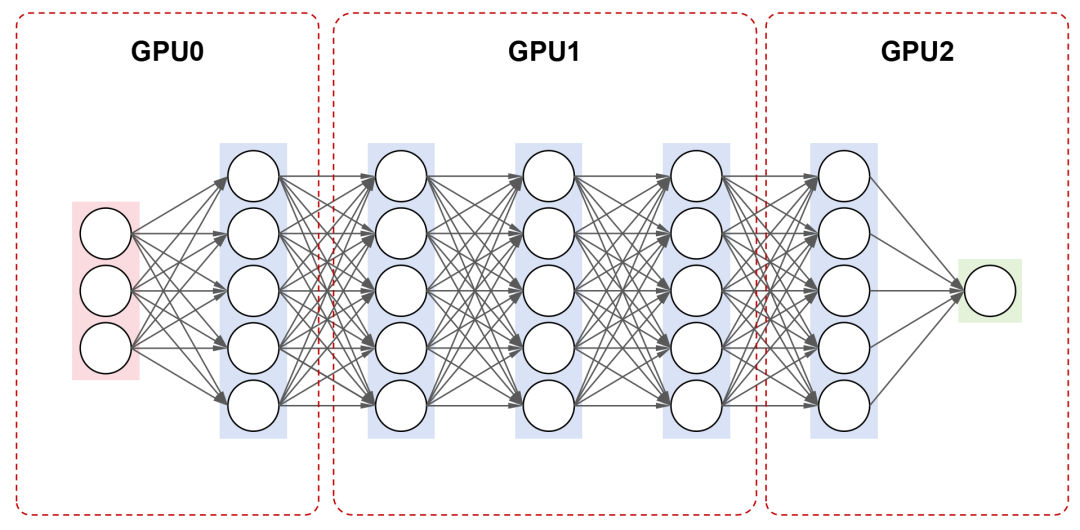
例如,对于一个包含7层的神经网络,将12层放在第一个GPU上,35层放在第二个GPU上,6~7层放在第三个GPU上。训练时,数据按照顺序,在不同的GPU上进行处理。
乍一看,流水并行有点像串行。每个GPU需要等待前一个GPU的计算结果,可能会导致大量的GPU资源浪费。
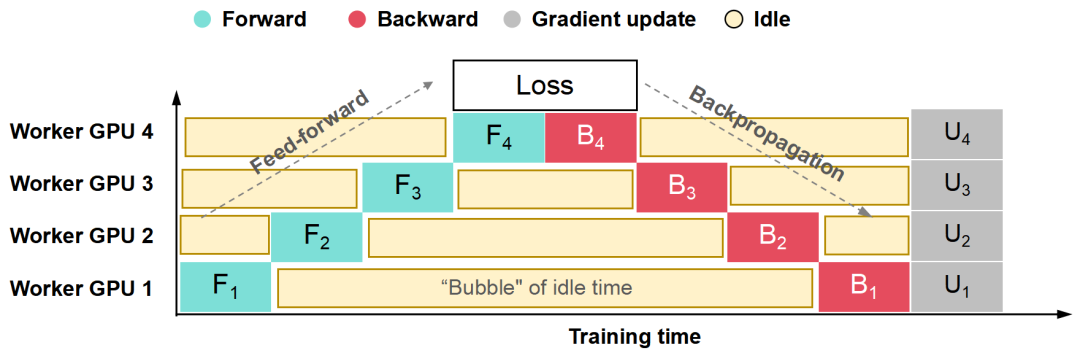
上面这个图中,黄色部分就是Bubble (气泡)时间。气泡越多,代表GPU处于等待状态(空闲状态)越长,资源浪费越严重。
为了解决上述问题,可以将mini-batch的数据进一步切分成micro-batch数据。当GPU 0处理完一个micro-batch数据后,紧接着开始处理下一个micro-batch数据,以此来减少GPU的空闲时间。如下图(b)所示:
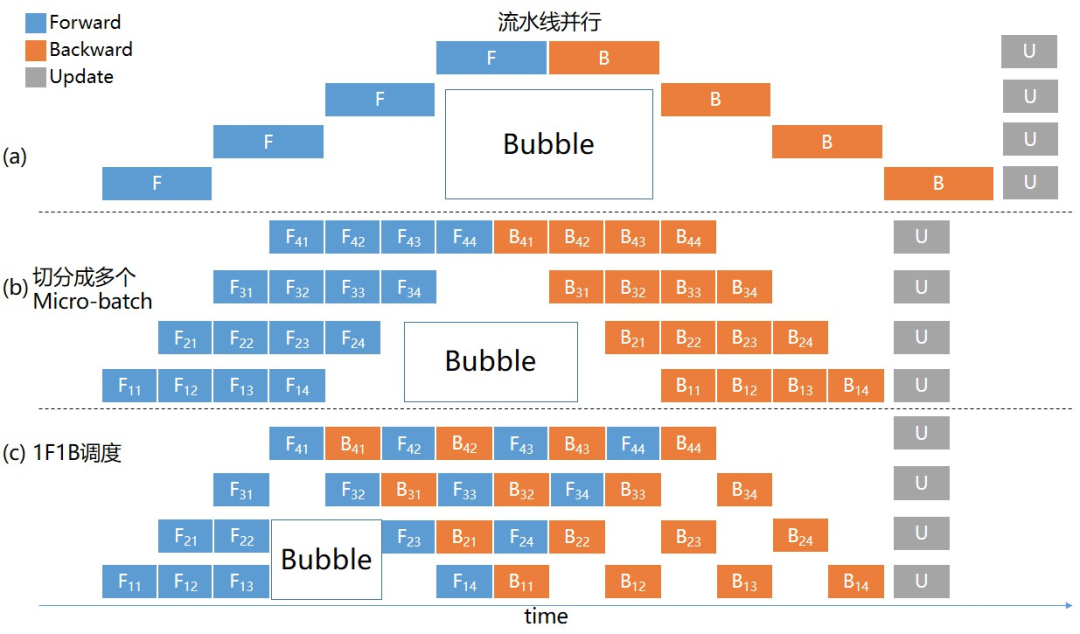
还有,在一个micro-batch完成前向计算后,提前调度,完成相应的反向计算,这样就能释放部分显存,用以接纳新的数据,提升整体训练性能。如上图(c)所示。
这些方法,都能够显著减少流水线并行的Bubble时间。
对于流水线并行,需要对任务调度和数据传输进行精确管理,否则可能导致流水线阻塞,以及产生更多的Bubble时间。
▉ TP(张量并行)
模型并行的另外一种,是张量并行。
如果说流水线并行是将一个模型按层「垂直」分割,那么,张量并行则是在一个层内「横向」分割某些操作。
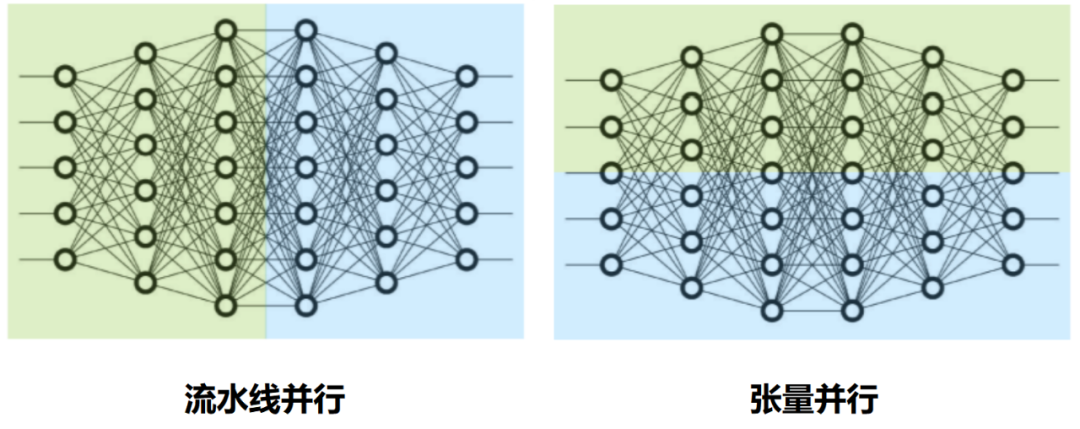
具体来说,张量并行是将模型的张量(如权重矩阵)按维度切分到不同的GPU上运行的并行方式。
张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)(权重矩阵按行分割)与列并行(Column Parallelism)(权重矩阵按列分割)。
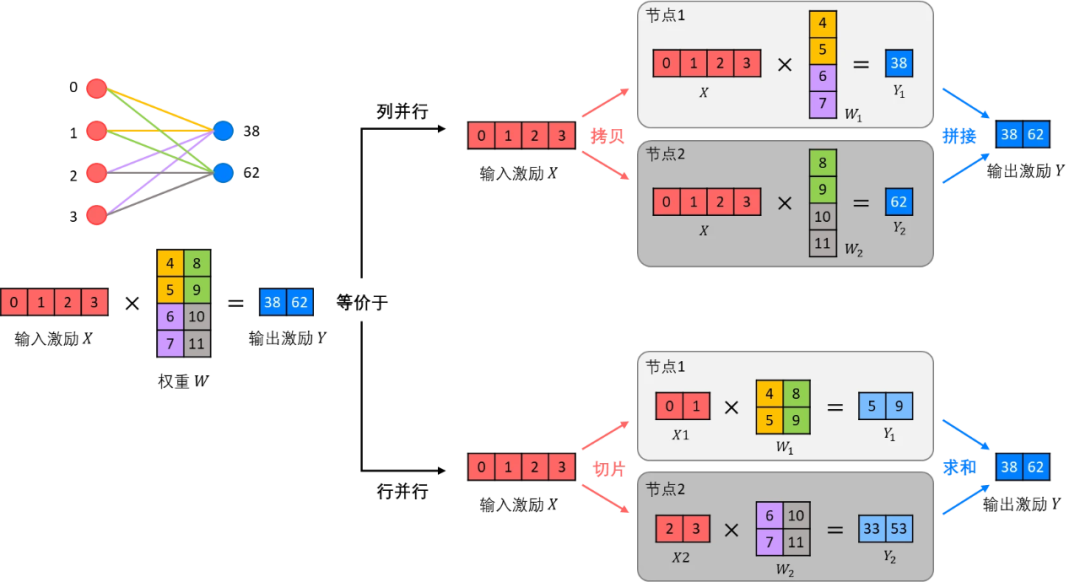
每个节点处理切分后的子张量。最后,通过集合通信操作(如All-Gather或All-Reduce)来合并结果。
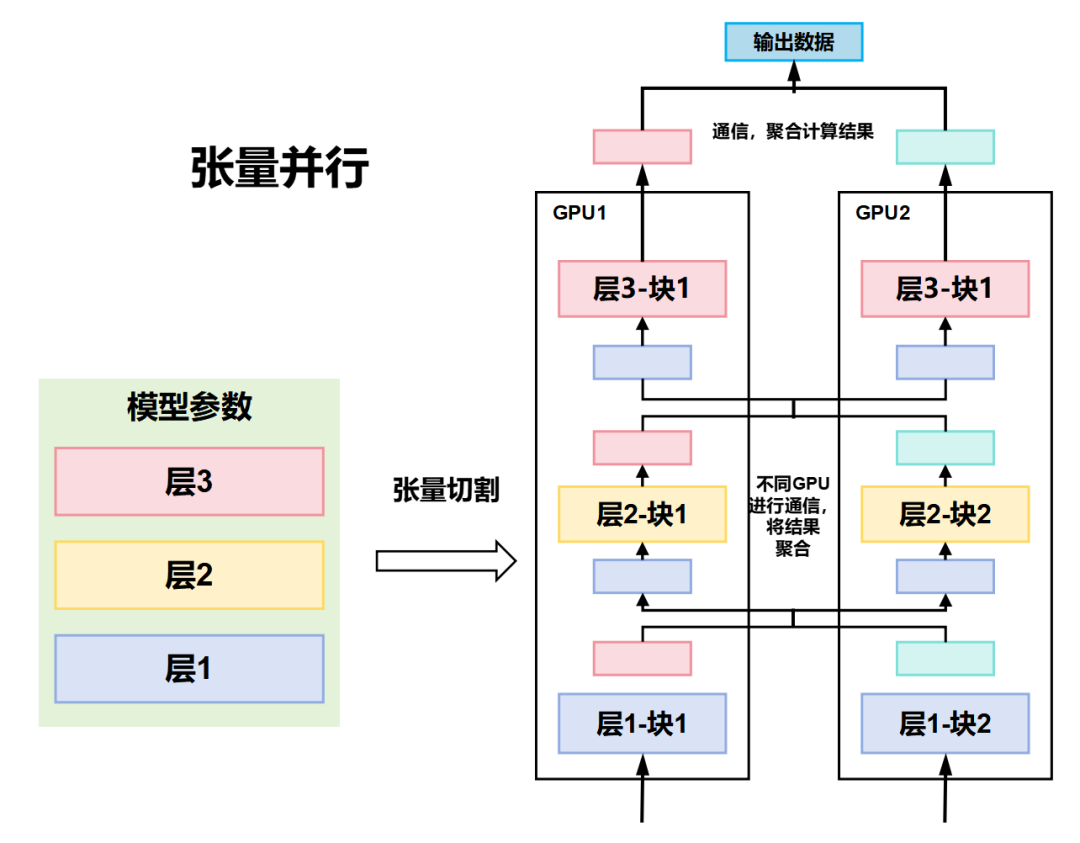
张量并行的优点,是适合单个张量过大的情况,可以显著减少单个节点的内存占用。
张量并行的缺点,是当切分维度较多的时候,通信开销比较大。而且,张量并行的实现过程较为复杂,需要仔细设计切分方式和通信策略。
放一张数据并行、流水线并行、张量并行的简单对比:
▉ 专家并行
2025年初DeepSeek爆红的时候,有一个词也跟着火了,那就是MoE(Mixture of Experts,混合专家模型)。
MoE模型的核心是“多个专家层+路由网络(门控网络)”。
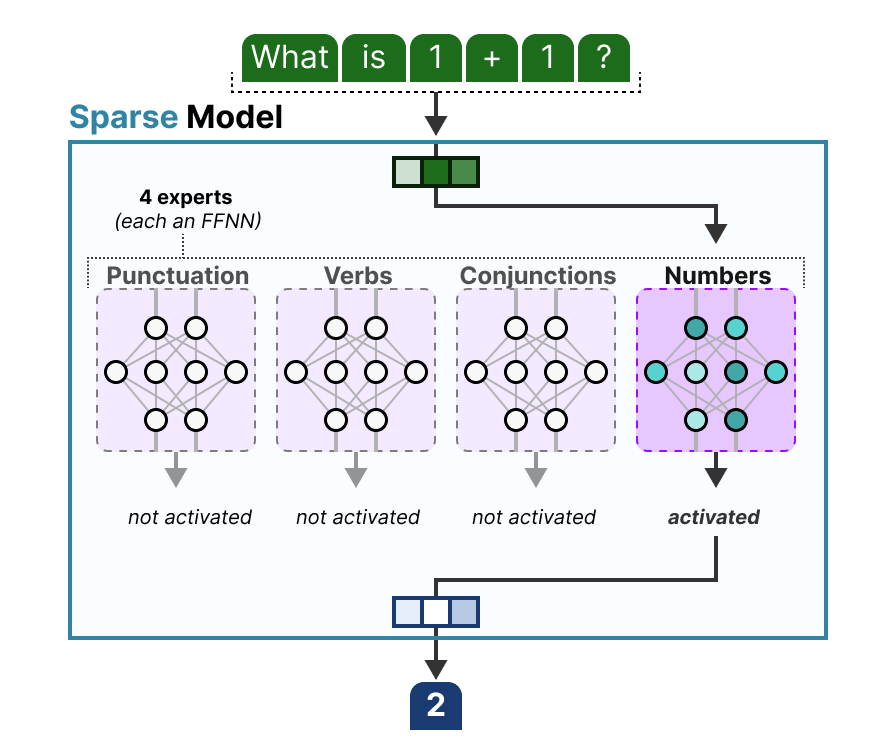
专家层的每个专家负责处理特定类型的token(如语法、语义相关)。路由网络根据输入token的特征,选择少数专家处理这个token,其他专家不激活。
MoE实现了任务分工、按需分配算力,因此大幅提升了模型效率。
专家并行(Expert Parallelism),是MoE(混合专家模型)中的一种并行计算策略。它通过将专家(子模型)分配到不同的GPU上,实现计算负载的分布式处理,提高计算效率。
专家并行与之前所有的并行相比,最大的不同在于,输入数据需要通过一个动态的路由选择机制分发给相应专家,此处会涉及到一个所有节点上的数据重分配的动作。
然后,在所有专家处理完成后,又需要将分散在不同节点上的数据按原来的次序整合起来。
这样的跨片通信模式,称为All-to-All。
专家并行可能存在负载不均衡的问题。某个专家所接收到的输入数据大于了其所能接收的范围,就可能导致Tokens不被处理或不能被按时处理,成为瓶颈。
所以,设计合理的门控机制和专家选择策略,是部署专家并行的关键。
▉ 混合并行
在实际应用中,尤其是训练万亿参数级别的超大模型时,几乎不会只使用单一的并行策略,而是采用多维度的混合并行(结合使用多种并行策略)。
例如:
数据并行+张量并行:数据并行处理批量样本,张量并行处理单样本的大矩阵计算。
流水线并行+专家并行:流水线并行划分模型层,专家并行划分层内专家模块。
更高级的,是3D并行,通过“数据并行+张量并行+流水线并行”,实现三重拆分,是超大模型训练的主流方案。
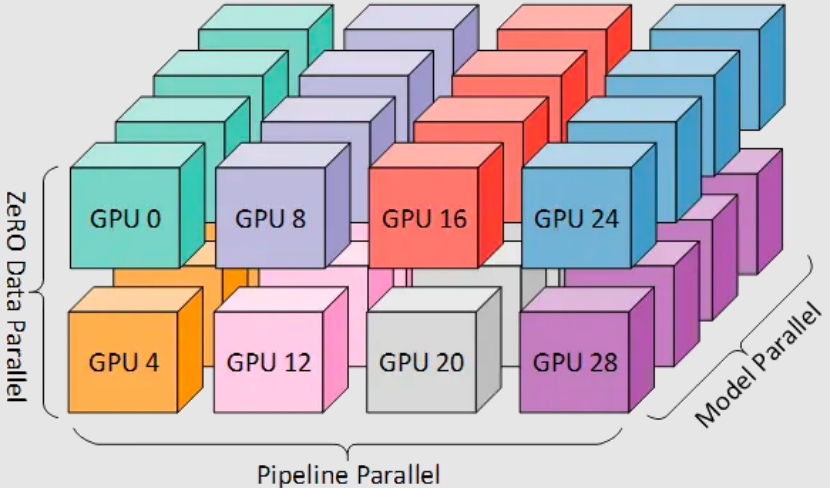
3D并行
▉ 最后的话
好啦,以上就是关于DP、PP、TP、EP等并行训练方式的介绍。大家都看懂了没?
并行计算方式其实非常复杂,刚才我们只是做了最简单的介绍。但在真实工作中,开发者无需了解具体的实现细节,因为业界提供了例如DeepSpeed(微软开源,支持3D并行+ZeRO内存优化)、Megatron-LM(NVIDIA开源,3D并行的标杆)、FSDP等开源软件,能够让开发者直接进行大语言模型训练。
之所以要专门介绍并行训练方式,其实更多是为了帮助大家深入地理解算力集群架构和网络的设计。
大家可以看到,不同的并行训练方式,有着不同的通信流量特点。算力集群整体架构和网络设计,需要尽量去适配这些并行计算方式的流量特点,才能满足模型训推任务的要求,实现更高的工作效率。
比如说,数据并行,由于需要频繁同步梯度信息,对网络带宽要求较高,需要确保网络带宽能够满足大量梯度数据快速传输的需求,避免因带宽不足导致通信延迟,影响训练效率。
流水线并行,大模型的每一段,在不同的服务器上以流水线的方式逐步计算,涉及到多个服务器“串起来”,就建议部署在比较靠近的服务器上(尽量部署在叶脊网络的同一个leaf叶下)。
张量并行,通信数据量大,就建议部署在一台服务器的多个GPU上进行计算。
专家并行中,不同专家分配在不同GPU上,GPU间需要交换中间计算结果等信息,其通信流量特点取决于专家的数量以及数据交互的频率等,也需要合理规划GPU间的连接方式和通信路径。
总之,在GPU算卡性能越来越难以提升的背景下,深入研究并行计算的设计,从架构和网络上挖掘潜力,是业界的必然选择。
随着AI浪潮的继续发展,以后是否还会出现其它的并行训练方式呢?让我们拭目以待吧!
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献309条内容
已为社区贡献309条内容

所有评论(0)