告别大模型 “瞎胡说”:RAG(检索增强生成)如何让 AI 更懂事实?
RAG 的本质,是给生成式 AI 加上了 “事实锚点”。它没有抛弃大模型的生成能力,而是通过检索让生成的内容 “有据可依”;它也没有局限于检索的死板,而是通过生成让答案更流畅、更灵活。对于技术从业者来说,RAG 提供了一种 “参数高效” 的解决方案 —— 不用追求更大的模型,通过结合外部知识库,就能在知识密集型任务上实现 SOTA;对于普通用户来说,RAG 让 AI 的答案更可信、更实用,减少了
在 AI 生成内容的时代,我们早已习惯用大模型解答疑问、生成文案。但有时会有这样的尴尬:AI 自信满满给出的答案,却和事实严重不符(也就是常说的 “模型幻觉”);想让 AI 更新对新事件的认知,却要重新投入海量资源训练;追问答案来源时,AI 只能 “沉默以对”?
2020 年,Facebook AI Research 等机构联合发表在NeurIPS 的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》,提出了一种名为 RAG(检索增强生成)的解决方案。它像给生成式 AI 配上了一个 “实时可查的知识库”,让模型 “先查资料再说话”,彻底改变了大模型处理知识密集型任务的方式。
一、大模型的 “知识困境”:为什么会 “瞎胡说”?
在 RAG 出现之前,大模型处理知识主要靠两种方式,却都存在明显短板:
1. 闭门造车:纯参数化记忆的局限
传统生成式模型(如 GPT、BART)的知识,全部存储在自身的参数中 —— 相当于把海量数据 “死记硬背” 下来。这种方式的问题很突出:
- 容易 “失忆” 或 “编瞎话”:模型无法记住所有细节,尤其是冷门知识,生成时会靠概率 “编造” 看似合理的内容;
- 知识无法实时更新:想让模型知道 2024 年的新政策、新事件,必须重新训练,成本极高;
- 缺乏可解释性:你永远不知道模型的答案来自哪份资料,无法验证可信度。
2. 照本宣科:纯检索模型的不足
另一种思路是 “检索 + 提取”:用搜索引擎找到相关文档,再从文档中摘抄答案。但这种方式灵活性太差,只能输出固定片段,无法像生成模型那样组织流畅、自然的语言,也难以应对需要整合多份文档信息的复杂问题。
RAG 的核心创新,就是把这两种方式的优点结合起来:用 “检索” 保证知识的准确性和时效性,用 “生成” 保证表达的流畅性和灵活性。
二、RAG 的工作原理:AI 如何 “先查资料再说话”?
RAG 的结构并不复杂,本质是 “检索器 + 生成器” 的协同工作,再加上一个海量的外部知识库。我们用通俗的步骤拆解它的完整流程:
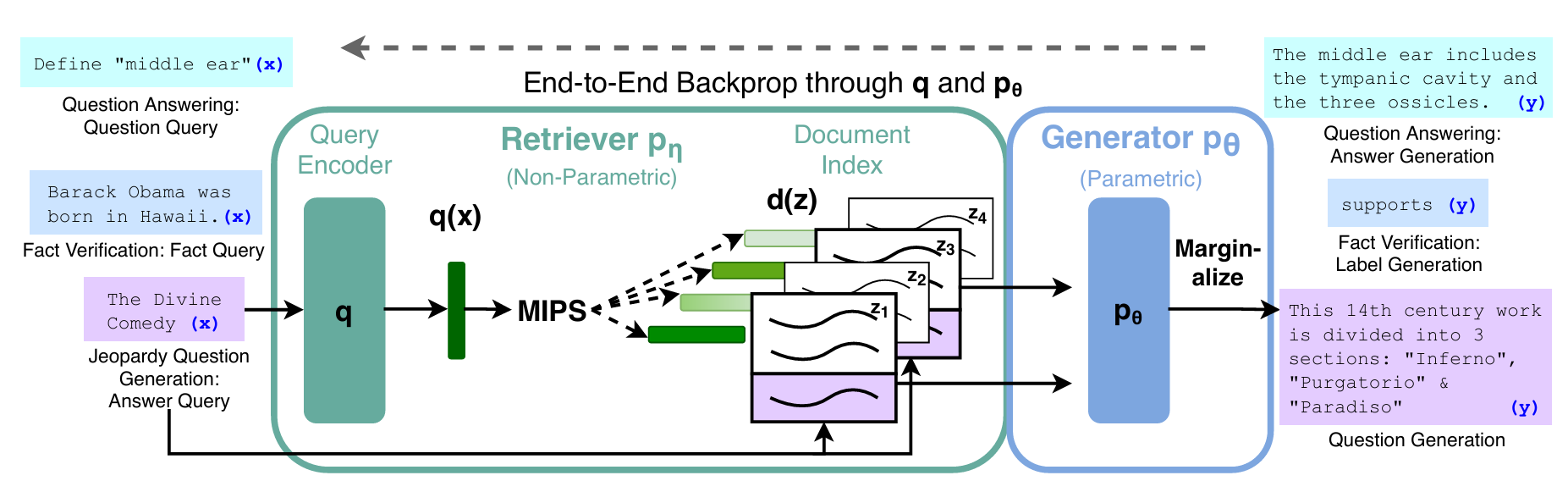
1. 准备阶段:搭建 “电子参考书库”(非参数化记忆)
RAG 的 “知识库” 不是杂乱的文档堆,而是经过预处理的 “向量索引”:
- 数据源:可以是维基百科、行业文档、企业知识库等(论文中用了 2018 年维基百科 dump,拆分后约 2100 万篇文档片段);
- 预处理:用 BERT 等编码器,把每篇文档转换成电脑能理解的 “稠密向量”(论文中是 728 维);
- 存储:用 FAISS 等工具构建向量索引,相当于把 “参考书” 整理成带索引的字典,方便快速查找。
2. 检索阶段:快速找到相关 “参考资料”
当你提出问题(比如 “什么是中耳?”),RAG 的 “检索器” 会立刻行动:
- 问题编码:把你的问题也转换成向量(称为 q (x));
- 快速匹配:用 MIPS(最大内积搜索)技术,在向量索引中找和问题向量最相似的文档向量(d (z))。这里的关键是 “快速”—— 通过提前对文档向量聚类(比如聚成 1000 个簇),先筛选出几个最相关的簇,再在簇内计算精确相似度,不用遍历所有文档;
- 结果返回:最终选出 top-K 篇最相关的文档(论文中 K=5 或 10),作为生成答案的 “参考资料”。
3. 生成阶段:基于资料组织流畅答案(参数化记忆)
这一步是 RAG 的 “生成器” 登场,它的核心是一个预训练的 seq2seq 模型(论文中用了 BART-large):
- 输入拼接:把 “你的问题 + 检索到的参考文档” 拼接成一个长序列;
- 逐词生成:通过 seq2seq 模型的 “编码器→解码器” 流程,逐词生成答案。生成时会同时依赖两部分信息:一是参考文档中的事实,二是之前生成的词汇(保证语法连贯);
- 两种生成模式:
- RAG-Sequence:用同一批参考文档生成完整答案,适合简单问题;
- RAG-Token:每个词汇生成时都能选择不同的参考文档,适合需要整合多份资料的复杂问题。
整个流程的精髓在于 “端到端训练”—— 检索器和生成器会一起优化,让 “找资料” 和 “写答案” 形成协同:检索器更懂该找什么资料,生成器更会用资料写答案。
三、RAG 的实力:实验结果证明有多靠谱?
论文在多个知识密集型任务上测试了 RAG,结果可以用 “全面碾压” 来形容,关键亮点如下:
1. 开放域问答:刷新 SOTA,比纯生成 / 纯检索更能打
在 Natural Questions、WebQuestions 等经典 QA 任务中,RAG-Sequence 和 RAG-Token 都创下了当时的最佳成绩:
- 比纯参数模型(如 T5-11B)准确率高 8% 以上,解决了 “模型记不住冷门知识” 的问题;
- 比纯检索模型(如 DPR)更灵活,哪怕参考文档中没有直接答案,也能基于相关信息推理生成;
- 更夸张的是,当检索到的文档中没有正确答案时,RAG 仍能达到 11.8% 的准确率,而纯检索模型准确率为 0。
2. 内容生成:更 factual、更具体、更少幻觉
在 MS-MARCO 摘要问答、Jeopardy 问题生成任务中,RAG 的优势同样明显:
- 人类评价显示,42.7% 的场景下 RAG 生成的内容更符合事实,只有 7.1% 的场景不如纯生成模型;
- 生成的内容更具体,比如问 “苏格兰用什么货币”,RAG 会明确回答 “英镑(Pound sterling)”,而纯生成模型可能只说 “英镑”,缺乏细节;
- 多样性也更强,相同问题不会反复生成相似答案。
3. 事实验证:不用专门训练,也能精准判断
在 FEVER 事实验证任务中(判断 “奥巴马出生在夏威夷” 是否为真),RAG 不用专门训练 “如何找证据”,就能达到接近 SOTA 的准确率:
- 3 分类任务(支持 / 反驳 / 信息不足)准确率 72.5%,仅比专门优化的管道模型低 4.3%;
- 检索到的文档中,90% 的情况下 top-10 文档包含真实证据,说明检索器的精准度极高。
4. 知识更新:换个索引就行,不用重新训练
这是 RAG 最实用的优势之一:当世界发生变化(比如新总统上任、新政策出台),不用像纯参数模型那样重新训练,只要替换掉外部知识库的向量索引(比如把 2018 年维基百科换成 2024 年版),模型就能立刻 “学会” 新知识。论文测试显示,更换索引后,RAG 对新事件的回答准确率从 12% 提升到 68%。
四、RAG 的实际应用:不止于论文,已落地这些场景
如今,RAG 早已不是停留在论文中的技术,而是成为知识密集型 AI 应用的 “标配”,典型场景包括:
1. 智能问答机器人
比如客服机器人、教育问答系统,需要精准回答用户的专业问题(如 “社保断缴会影响养老金吗?”)。RAG 能快速检索企业知识库或政策文档,生成准确且有依据的答案,还能附上参考来源。
2. 内容创作与编辑
写行业报告、新闻稿时,RAG 可以实时检索最新数据、案例,避免内容过时或出现事实错误。比如写 “2024 年 AI 发展趋势”,RAG 会自动查找当年的最新研究成果和应用案例,让内容更具可信度。
3. 事实验证与舆情分析
媒体、公关行业可以用 RAG 快速验证网络传言的真实性(如 “某品牌产品存在质量问题”),通过检索权威来源的信息,生成验证报告,避免虚假信息扩散。
4. 个性化知识库助手
个人或团队可以搭建自定义知识库(如学术论文、项目文档),用 RAG 实现 “私人问答”。比如研究员可以用 RAG 快速检索自己的论文库,回答 “我之前在某篇论文中提到的算法细节是什么?”
5. 大模型安全检测(结合之前的场景)
像我们之前聊到的 “越狱提示词检测”,RAG 可以检索已知的恶意提示词库,快速判断用户输入是否存在风险,再生成安全响应,既保证检测准确率,又能灵活应对新出现的越狱变体。
五、RAG 的未来:还有哪些值得期待的方向?
论文发表至今,RAG 技术一直在快速迭代,未来的发展方向主要集中在:
1. 多模态 RAG
目前 RAG 主要处理文本知识库,未来会支持图片、视频、音频等多模态资料。比如你问 “这个产品的外观是什么样的?”,RAG 会检索产品图片,再生成文字描述。
2. 实时动态检索
现在的 RAG 大多依赖静态知识库,未来会结合实时搜索引擎,获取最新信息(如 “今天北京的空气质量如何?”),让 AI 的知识永远 “不过时”。
3. 更小、更高效的模型
论文中的 RAG 需要较大的计算资源,未来会通过模型压缩、量化等技术,让 RAG 能在手机、边缘设备上运行,降低使用门槛。
4. 更强的推理能力
目前 RAG 主要是整合资料,未来会加入更复杂的推理逻辑,比如处理 “如果... 会怎样?” 这类假设性问题,需要结合多份资料进行逻辑推导。
六、总结:RAG 的核心价值 —— 让 AI “靠谱” 地生成
RAG 的本质,是给生成式 AI 加上了 “事实锚点”。它没有抛弃大模型的生成能力,而是通过检索让生成的内容 “有据可依”;它也没有局限于检索的死板,而是通过生成让答案更流畅、更灵活。
对于技术从业者来说,RAG 提供了一种 “参数高效” 的解决方案 —— 不用追求更大的模型,通过结合外部知识库,就能在知识密集型任务上实现 SOTA;对于普通用户来说,RAG 让 AI 的答案更可信、更实用,减少了 “被 AI 误导” 的风险。
如果你想尝试 RAG,现在已经有了非常成熟的工具:HuggingFace Transformers 库内置了 RAG 模型,LangChain、RAGFlow 等框架提供了开箱即用的实现,个人电脑(32GB 内存 + 16GB 显存)就能跑通基础实验。
未来,随着 RAG 技术的不断完善,AI 会越来越像一个 “靠谱的顾问”—— 既懂表达,又懂事实,真正成为我们工作、学习中的得力助手。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)