简单问答到工程探索——提示词工程到上下文工程的演进
摘要:AI领域正经历向"智能体推理"的重大转变,大语言模型使用从单轮文本生成转向多步骤、工具集成的复杂工作流。数据显示,推理模型已占使用量的50%,xAI和Google的模型占据主导地位。工具调用采用率显著上升,编程任务成为主要驱动力,平均提示词长度增长4倍至6K tokens,补全长度增长3倍至400 tokens。这种转变要求模型提供商提升延迟处理、上下文支持等能力,同时基
原文 https://openrouter.ai/state-of-ai
综合趋势(推理份额上升、工具使用扩展、序列增长以及编程任务异常复杂)表明,大语言模型使用的重心已经转移。典型的大语言模型请求不再是简单的问题或孤立的指令。相反,它成为结构化、类智能体循环的一部分,涉及调用外部工具、对状态进行推理,并在更长的上下文中持续进行。
对于模型提供商而言,这提高了对默认能力的要求。延迟、工具处理、上下文支持以及对格式错误或对抗性工具链的鲁棒性变得日益关键。对于基础设施运营商来说,推理平台现在不仅需要管理无状态请求,还需要管理长时间运行的对话、执行轨迹和权限敏感的工具集成。很快,即使现在尚未完全如此,智能体推理将占据推理工作负载的大部分。
大语言模型使用本身的基本形态。语言模型在生产环境中的使用方式正在发生根本性转变:从单轮文本补全转向多步骤、工具集成和推理密集型的工作流。我们将这种转变称为智能体推理的兴起,即模型不仅被部署用于生成文本,更能通过规划、调用工具或在扩展的上下文中交互来行动。
推理模型现已占据总使用量的一半
数据指向一个清晰的结论:面向推理的模型正成为实际工作负载的默认选择,流经它们的 token 份额现已成为用户希望如何与 AI 系统交互的一个领先指标。![![[Pasted image 20251207190505.png]]](https://i-blog.csdnimg.cn/direct/042cd98d17dc4716915acde6bdc4c2ac.png)
推理与非推理模型 Token 趋势。自 2025 年初以来,通过推理优化模型处理的 token 份额稳步上升。该指标反映的是推理模型服务的所有 token 的比例,而非模型输出中"推理 token"的份额。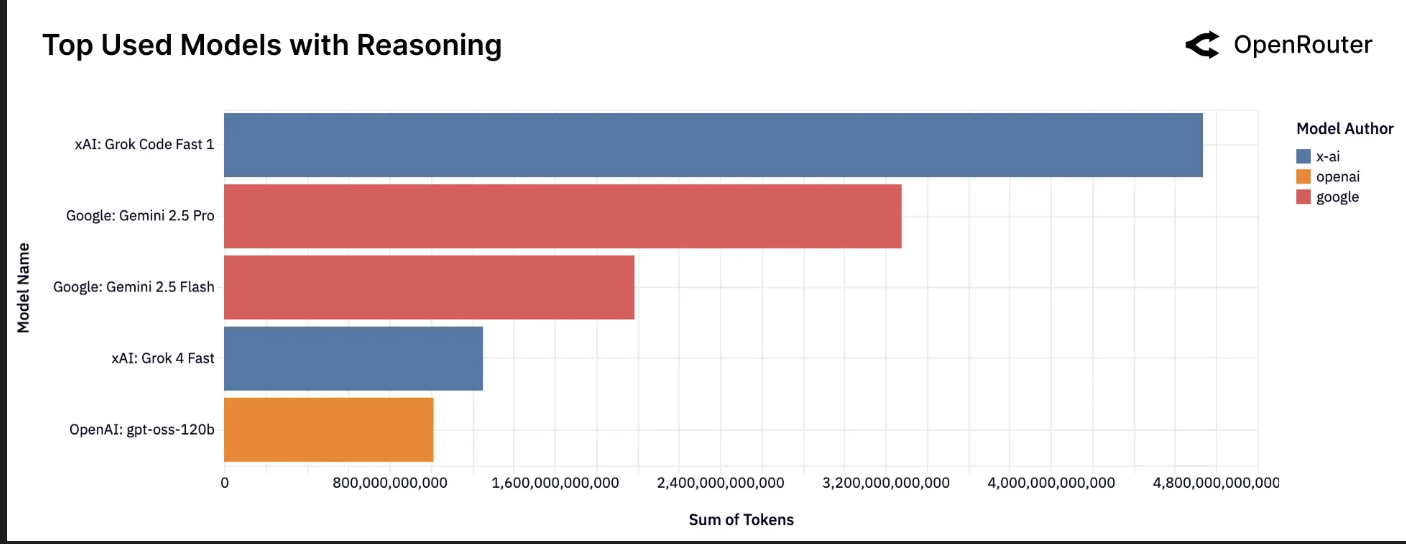
按 Token 量排名前列的推理模型。在推理模型中,xAI 的 Grok Code Fast 1 目前处理了推理相关 token 流量的最大份额,其次是 Google 的 Gemini 2.5 Pro 和 Gemini 2.5 Flash。xAI 的 Grok 4 Fast 和 OpenAI 的 gpt-oss-120b 构成了头部阵营。
工具调用采用率上升
在高价值工作流中,启用工具使用正在增长。没有可靠工具格式的模型在企业采用和编排环境中有落后的风险。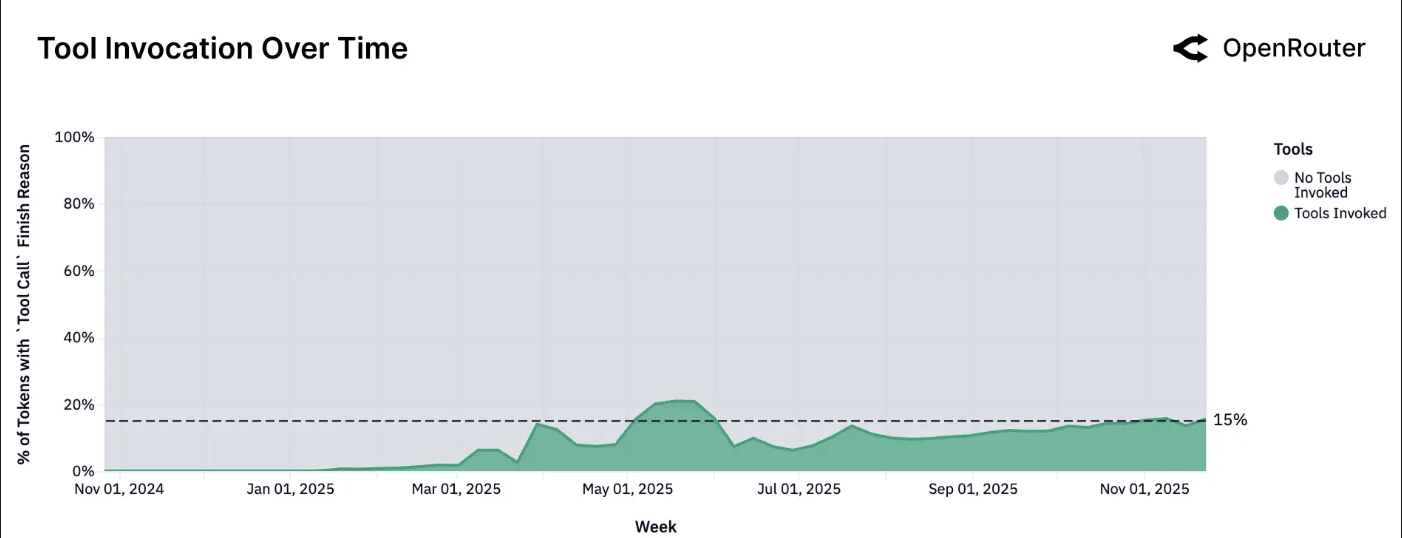
工具调用次数。按请求完成原因归类为工具调用的 token 总占比,这意味着在请求期间实际调用了工具。该指标反映了成功的工具调用;包含工具定义的请求数量按比例更高。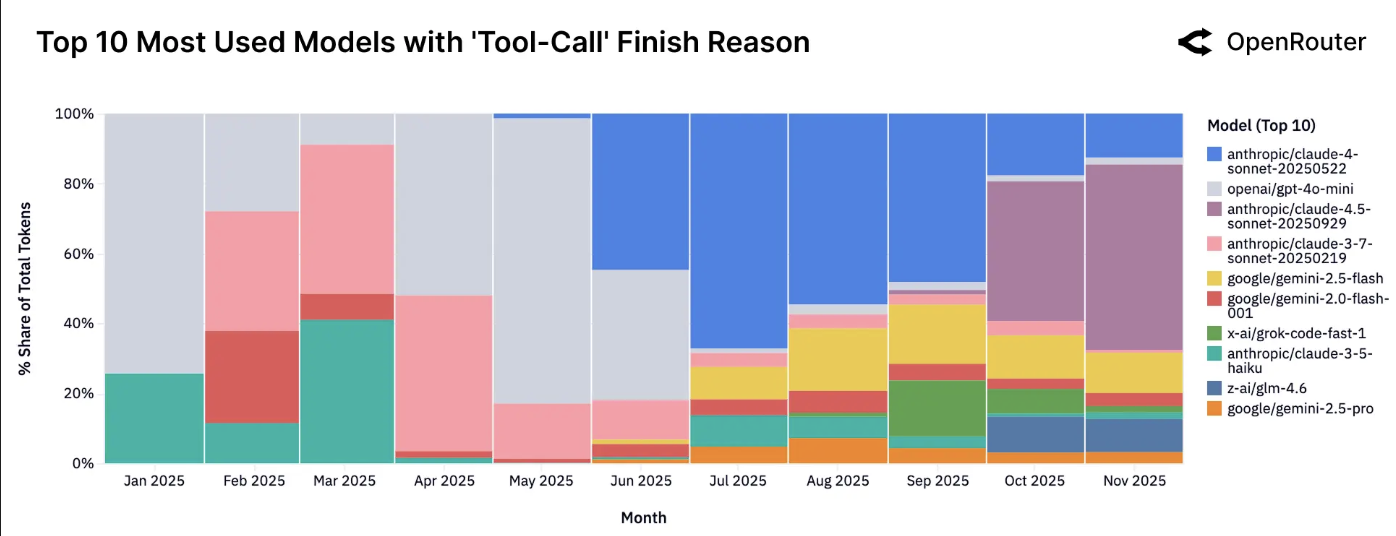
按工具提供量排名前列的模型。工具提供主要集中在为智能体推理明确优化的模型中,例如 Claude Sonnet、Gemini Flash。
提示词与补全结构剖析
模型工作负载的形态在过去一年中发生了显著变化。提示词(输入)和补全(输出)的令牌量均急剧上升,尽管规模和速率不同。每个请求的平均提示词令牌数从大约 1.5K 增加到超过 6K,增长了约四倍,而补全令牌数则从约 150 个增加到 400 个,增长了近三倍。相对的增长幅度突显了向更复杂、上下文更丰富的工作负载的决定性转变。
这一模式反映了模型使用的新常态。当今典型的请求较少涉及开放式生成(“写一篇文章”),而更多地涉及对大量用户提供的材料(如代码库、文档、转录本或长对话)进行推理,并产生简洁、高价值的见解。模型正越来越多地充当分析引擎,而非创意生成器。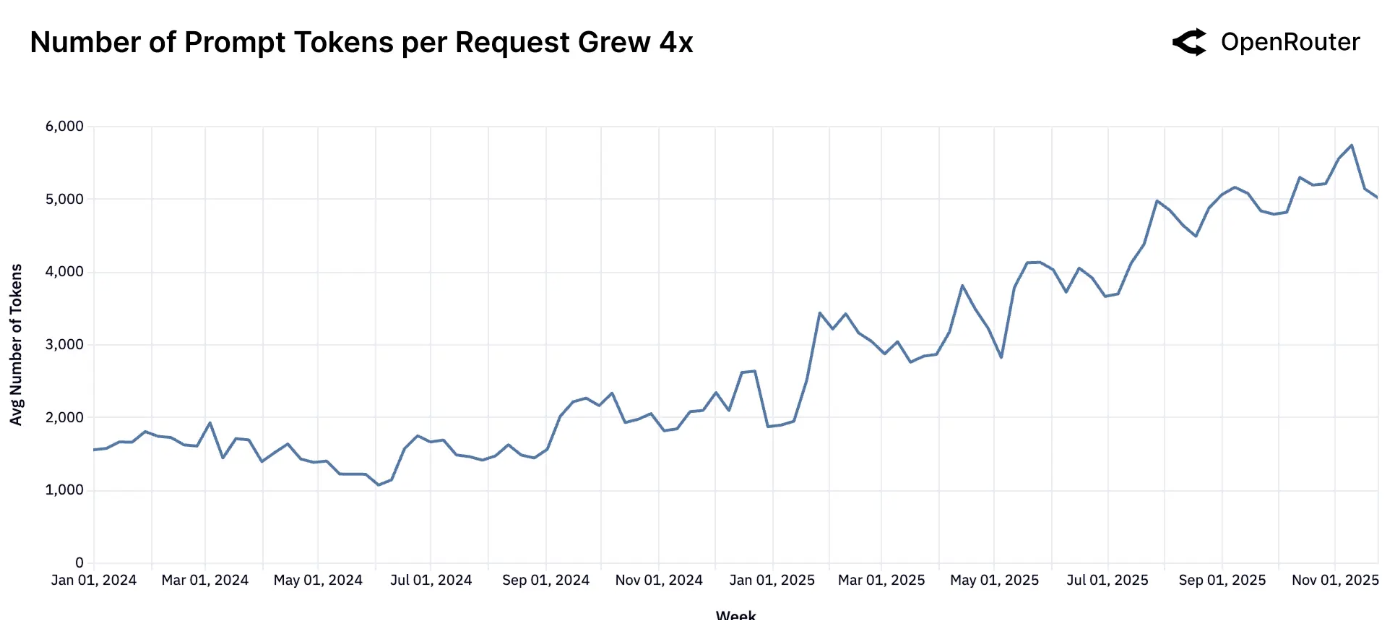
提示词令牌数量呈上升趋势。自 2024 年初以来,平均提示词长度增长了近四倍,反映出工作负载的上下文越来越重。
补全令牌数量几乎增长三倍。输出长度也有所增加,尽管基数较小,这表明响应更丰富、更详细,这主要归因于推理令牌。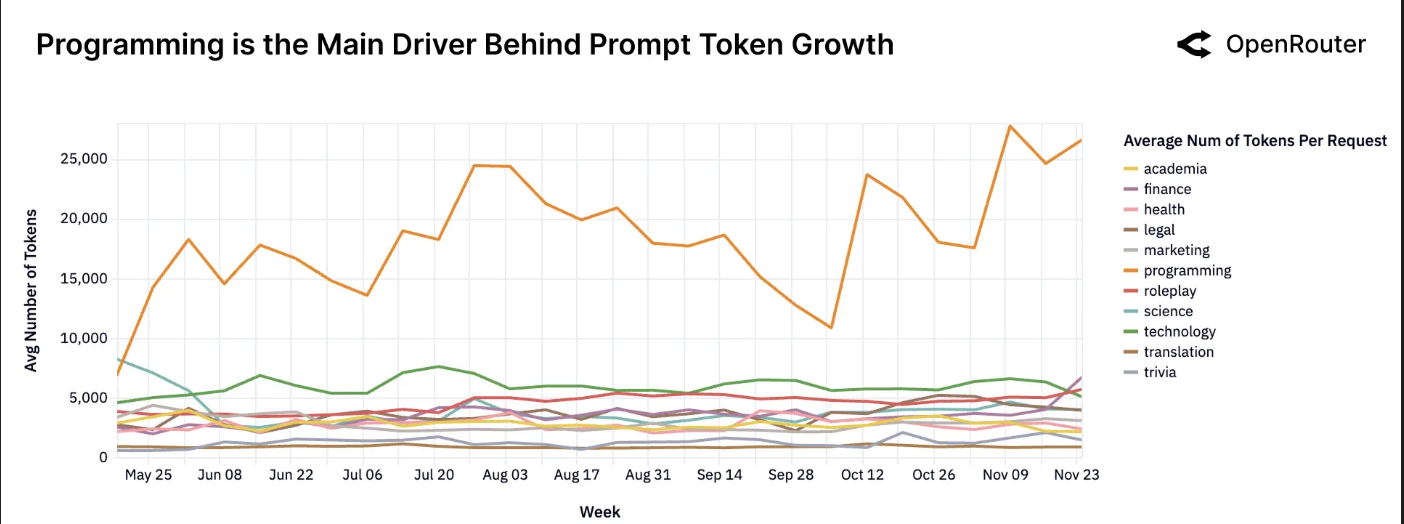
编程是提示词增长的主要驱动力。由于标签数据自 2025 年春季起可用,编程相关任务始终需要最大的输入上下文。
更长的序列,更复杂的交互
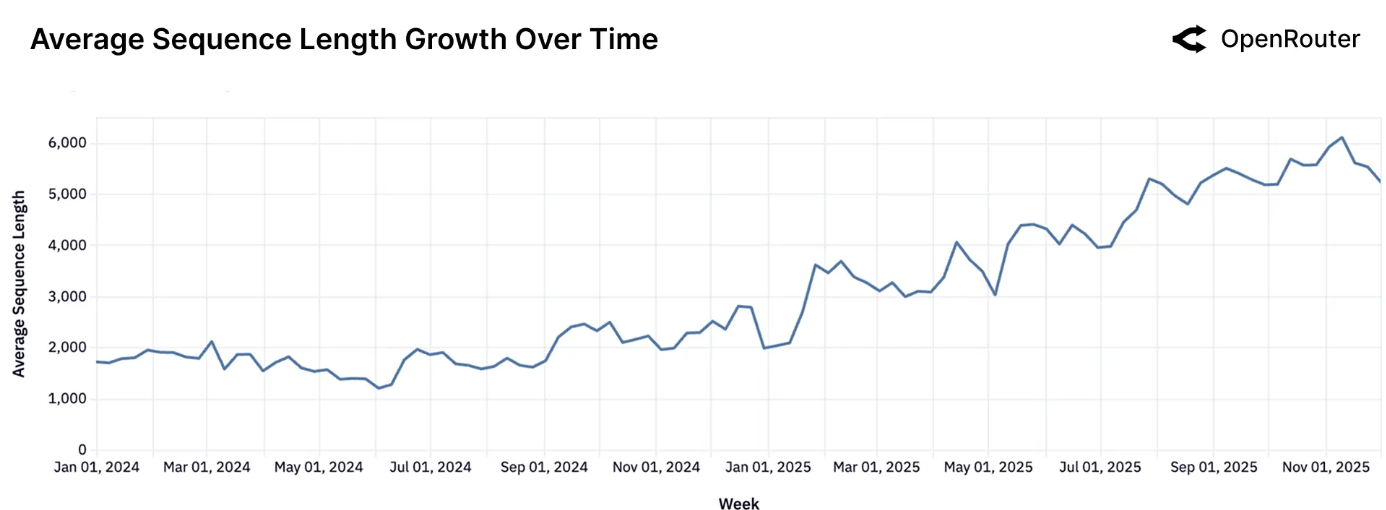
平均序列长度随时间变化。每次生成的平均令牌数(提示词 + 补全)。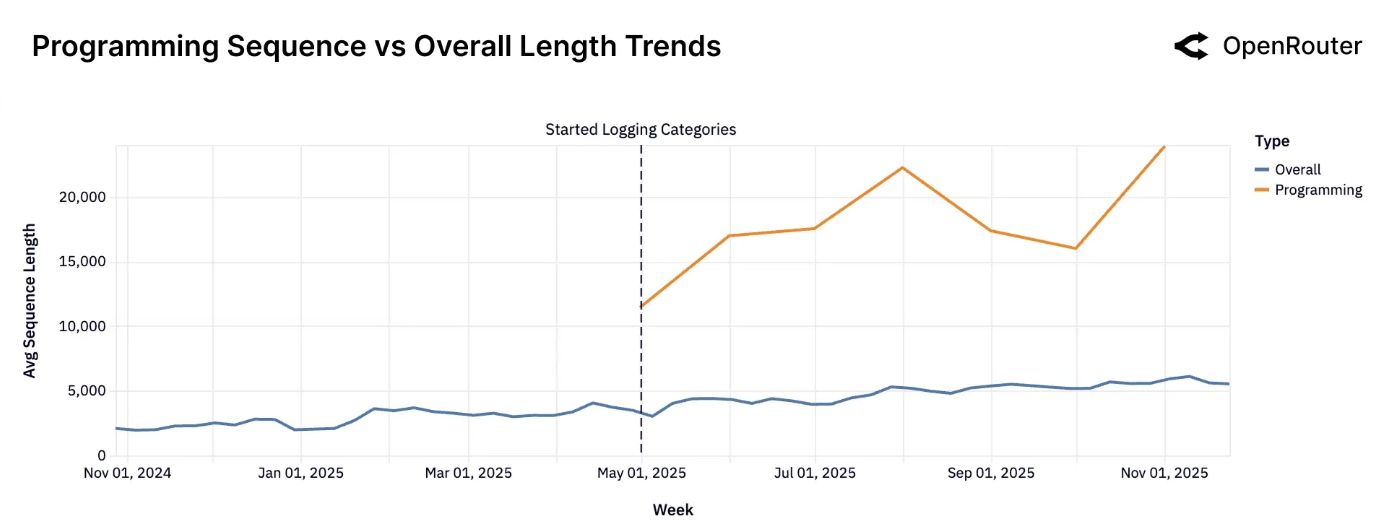
编程任务与整体任务的序列长度对比。编程提示词通常更长,且增长更快。
如前一节所述,第二张图提供了更清晰的说明:与编程相关的提示词现在的平均令牌长度是通用提示词的3-4倍。这种差异表明,软件开发工作流是更长交互的主要驱动力。长序列不仅仅是用户的冗长表达:它们是嵌入式、更复杂的智能体工作流的标志。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)