STM32N6 AI官方软件包介绍 LAT1609
为了方便客户使用和评估STM32N6的性能,ST官方发布了一系列的参考例程,用于快速评估和开发,本文将简单介绍这些demo的获取途径,并简单介绍其中部分例程。
关键字:AI, STM32N6
1. 简介
为了方便客户使用和评估STM32N6的性能,ST官方发布了一系列的参考例程,用于快速评 估和开发,本文将简单介绍这些demo的获取途径,并简单介绍其中部分例程。
例程的官网地址:https://www.st.com/en/development-tools/stm32n6-ai.html
另外,建议工程师参考ST官方github总入口: https://github.com/STMicroelectronics/STM32AI_Overall_Offer
2. 总览
在https://github.com/STMicroelectronics/STM32AI_Overall_Offer内,总共有以下 demo:
| 分类 | 项目(点击跳转) | 描述 |
| Demo binary | STM32N6 AI | 官网总入口,binary文件以及相关 demo。 |
| Getting Started | Audio | 简单的音频应用:音频事件检测(AED)和 语音增强 (SE) |
| Getting Started | Image Classification |
简单视觉类应用:图片分类
|
| Getting Started | Object Detection |
简单视觉类应用:目标检测
|
| Getting Started | Pose Estimation |
简单视觉类应用:姿态评估
|
| Getting Started | Instance Segmentation |
简单视觉类应用:实例分割
|
| Getting Started | Segmantic Segmentation |
简单视觉类应用:语义分割
|
| Optimized application | People detection and tracking |
基于FreeRTOS的人体检测和追踪
|
| Optimized application | Pose estimation |
基于FreeRTOS的姿态评估
|
| Optimized application | Hand landmarks |
基于FreeRTOS的手部关键点检测
|
| Optimized application | AI with h264 encoder and USB UVC | 基于AI的多媒体应用, H264 编码和USB and USB UVC Optimized UVC实现。 |
| Optimized application | Power measurement utilities | 基于STM32N6570-DK的功耗测量应 用。 |







3. 音频应用:音频事件检测(AED)和语音增强 (SE)
3.1. AED
AED应用首先通过MIC采集数据,然后对音频数据进行特征提取,最后再由模型进行分类 处理。Audio软件包中有完整的MFCC音频中间件,以及AI模型的处理流程。
AED工程可以对环境音进行分类,比如犬吠声,直升机噪声,下雨背景声,时钟滴答声,婴 儿啼哭声等。用户可以使用自己的音频数据集进行重新训练,并可以非常简单快速的改为KWS 语音关键字分类等音频分类应用。
部署方式有两种,第一种是使用ST model zoo的服务进行部署,可以使用自己的模型,也 可以使用ST预训练的模型,参考:https://github.com/STMicroelectronics/stm32ai modelzoo-services,需要按下面的方式修改yaml配置文件.
指定工程和模型:
general:
project_name: aed_project
model_path:/audio_event_detection/yamnet/ST_pretrainedmodel_p ublic_dataset/esc10/yamnet_1024_64x96_tl/yamnet_1024_64x96_tl_qdq_int8.onnx
指定数据集和类别:
dataset:
name: esc10
class_names: ['dog', 'chainsaw', 'crackling_fire', 'helicopter', 'rain', 'crying_baby', 'clock_tick', 'sneezing', 'rooster', 'sea_waves']
指定预处理参数:
feature_extraction:
patch_length: 96
n_mels: 64 ...
指定本地工具路径和环境:
tools:
stedgeai:
version: 10.0.0
optimization: balanced
on_cloud: False
path_to_stedgeai: C://STM32Cube/Repository/Packs/STMicroelectronics/X CUBE-AI//Utilities/windows/stedgeai.exe
path_to_cubeIDE: C:/ /STM32CubeIDE/stm32cubeide.exe
设置部署相关参数:
deployment: c_project_path: ../../application_code/audio/STM32N6
IDE: GCC
verbosity: 1
hardware_setup:
serie: STM32N6
board: STM32N6570-DK
build_conf : "N6 Audio Bare Metal" # this is default configuration
# build_conf : "N6 Audio Thread X"
# build_conf : "N6 Audio Bare Metal Low Power"
# build_conf : "N6 Audio Thread X Low Power"
unknown_class_threshold: 0.5 # Threshold used for OOD detection. Mutually exclusive with use_garbage_class
# Set to 0 to disable. To enable, set to any float between 0 and 1.
第二种部署方法是本地部署:
这种方法不需要使用model zoo service,仅需要使用本地的脚本文件。
具体脚本实现在deploy-model.sh中,位于Projects\X-CUBE-AI\models目录下。
其包含三个参数:
1. 模型文件:xxx.onnx 类型的模型文件,可以来自 ST 官方参考的模型,也可以是自己的模型。 2. 模型类型:SE/AED。
3. 编译配置:BM/BM_LP/TX/TX_LP,BM:裸机程序,无操作系统。LP:加入了低功耗处理。 TX:使用ThreadX操作系统。
除此之外,还需要修改工程中的一些配置,比如:
<getting-start-install-dir>/Projects/DPU/ai_model_config.h
修改模型输出:
#define CTRL_X_CUBE_AI_MODE_NB_OUTPUT (1U) /* or (2U)*/
#define CTRL_X_CUBE_AI_MODE_OUTPUT_1 (CTRL_AI_CLASS_DISTRIBUTION)
修改模型类别:
#define CTRL_X_CUBE_AI_MODE_CLASS_NUMBER (10U)
#define CTRL_X_CUBE_AI_MODE_CLASS_LIST (1U) /* or (2U)*/ (CTRL_AI_CLASS_DISTRIBUTION) (10U) {"chainsaw","clock_tick",\ "crackling_fire","crying_baby","dog","helicopter","rain",\ "rooster","sea_waves","sneezing"}
修改预处理类型:
#define CTRL_X_CUBE_AI_PREPROC (CTRL_AI_SPECTROGRAM_LOG_MEL)
图1. 预处理流程
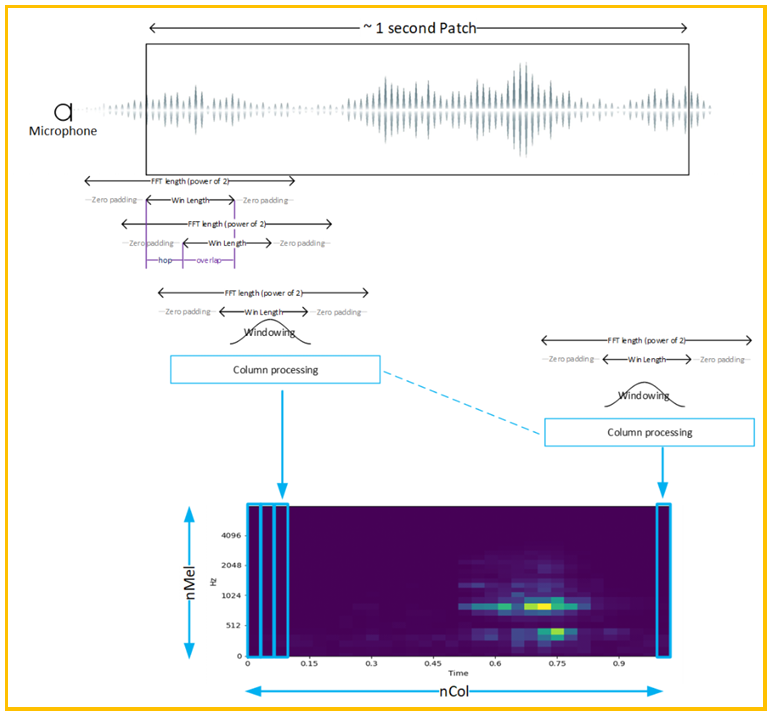
音频的预处理流程如上图1所示,首先做一段FFT,然后加窗,其后再对每列进行logMel 滤波,DCT等处理,之后使用一定的窗口进行移帧,对每一帧都进行同样的处理,最后在时间上 会得到上图1中的MFCC频谱。该流程是音频处理的通用特征工程,同样可以应用于KWS等应 用场景。
3.2. AED使用的模型
ST官方提供了三个不同的模型:
ST预训练模型参考:https://github.com/STMicroelectronics/stm32ai-modelzoo services/tree/main/audio_event_detection/pretrained_models
3.2.1. miniresnet
该模型参考了ResNet的实现,ResNet主要特点是在卷积层中的跳跃连接,从而解决梯度 消失和梯度爆炸的问题。
Miniresnet基于ResNet18网络拓扑,自定义了block功能,然后进行堆叠和跳跃连接, 用户可以指定堆叠的stack的数量,从而改变网络的大小。
关于池化层,ST参考的模型中删除了卷积后加池化的传统操作,因为在实验测试中发现如 果不实现池化,在模型大小,推理时间,内存占用方面能够更好的得到平衡。
模型的输入形状为(64, 50, 1),即64个梅尔通道数,50帧音频,1个通道。输入为(-1, 10), 代表10个分类结果。
基本性能参考下表:
图2. 内存和推理时间
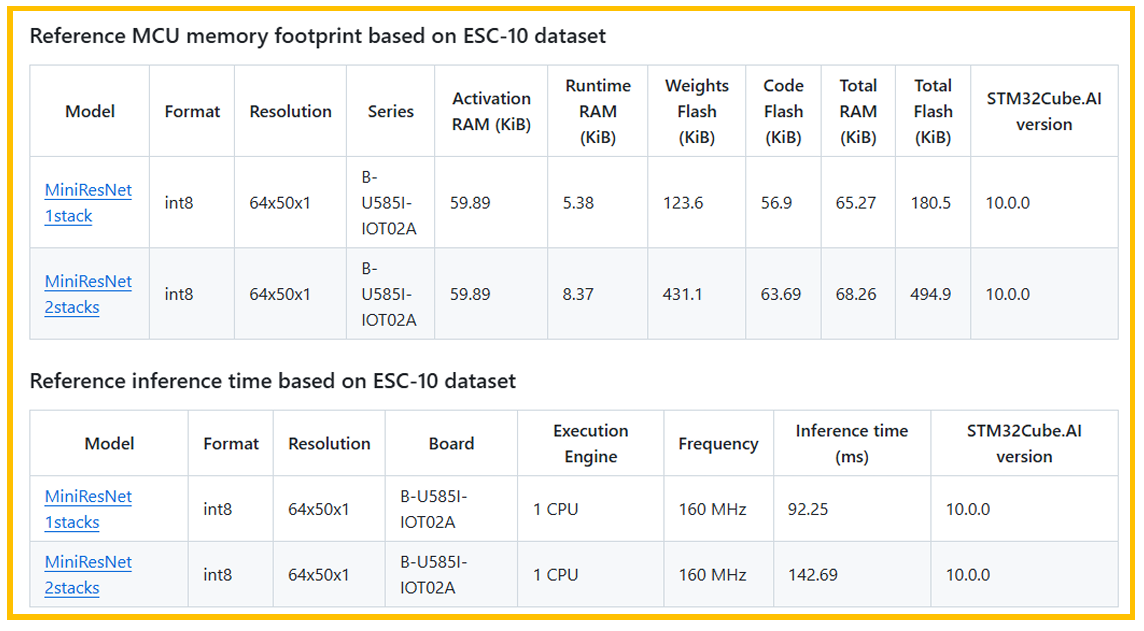
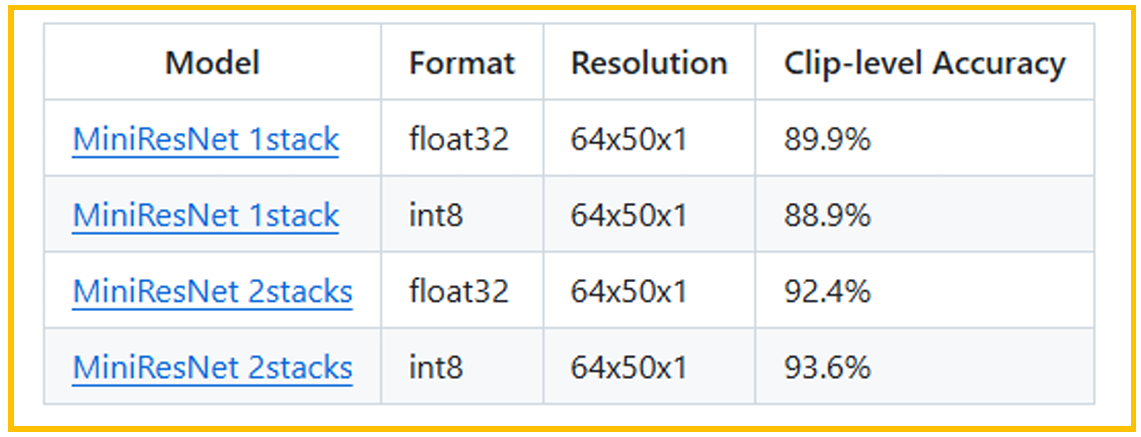
图3. 准确率
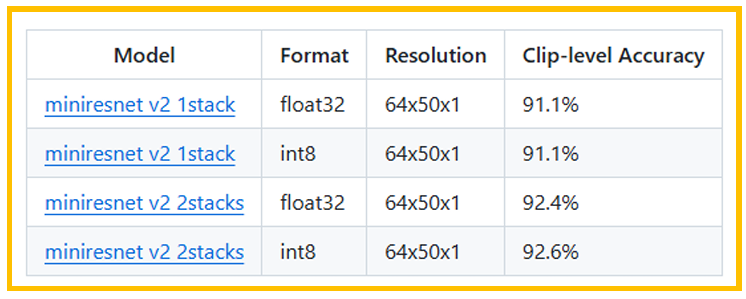
3.2.2. miniresnet v2
和miniresnet类似,miniresnet v2也参考了ResNetv2的实现,ResNetv2相对于 ResNet改变了跳跃连接的顺序,改变了ReLU的激活函数,主要是为了训练时候更快的收敛。
图4. 内存占用和推理时间
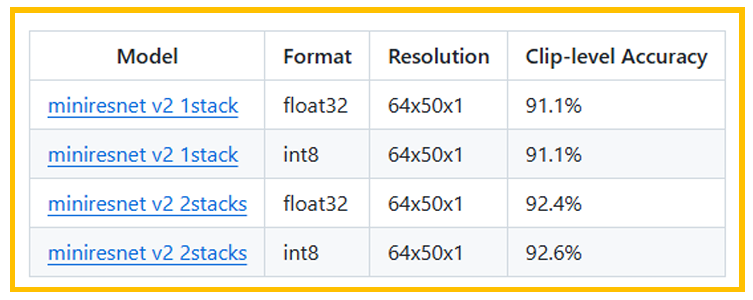
图5. 准确率
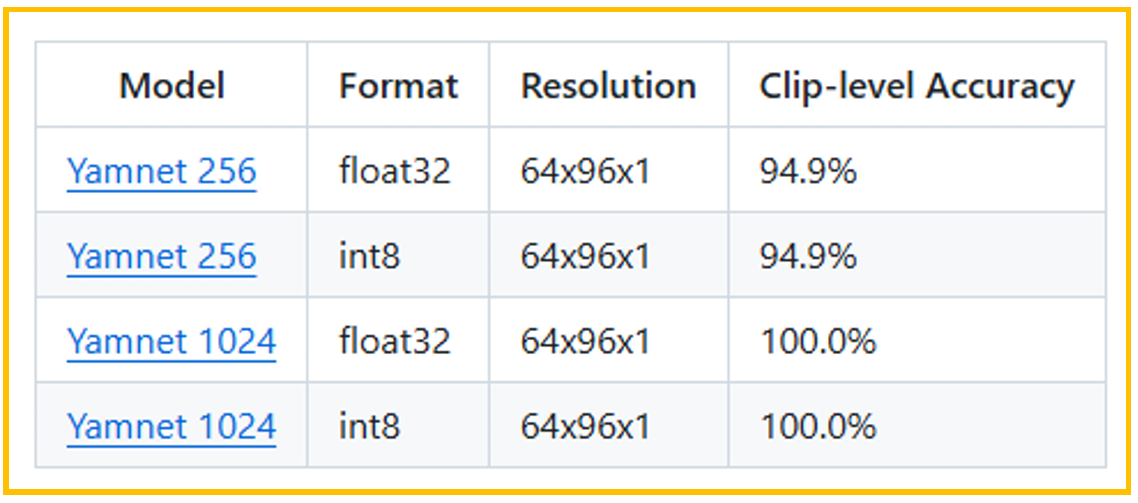
3.2.3. yamnet
yamnet模型,是基于MobileNetv1框架的模型,主要使用了卷积和深度可分离的卷积。 原始的yamnet模型太大,ST在原始模型上进行了一定的裁剪。
性能和指标参考下图:
图6. 内存占用和推理时间
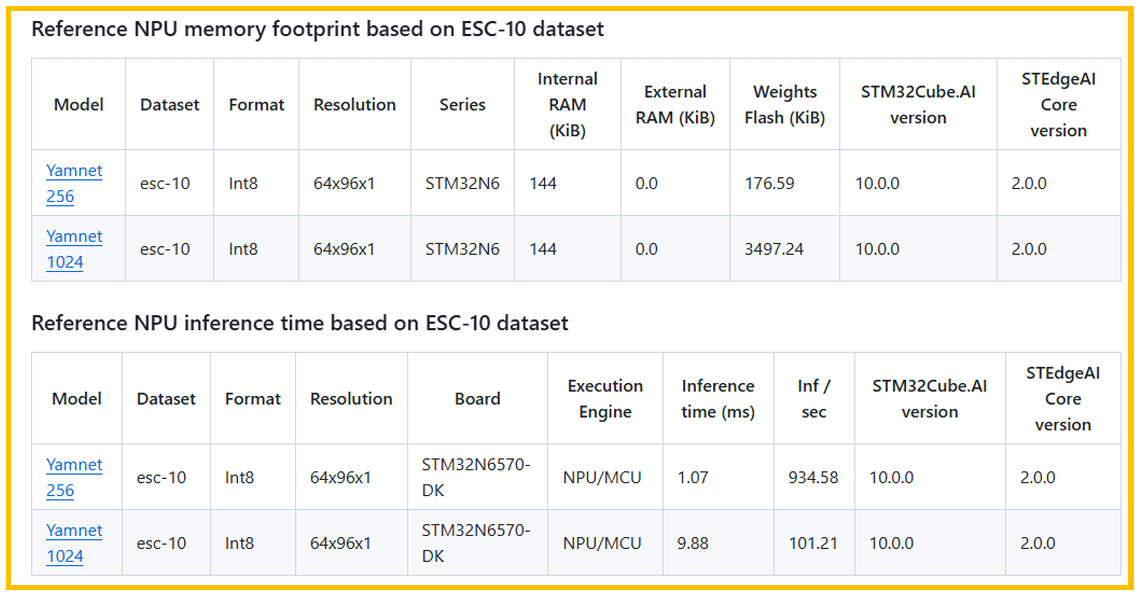
图7. 准确率
3.3. SE
SE 是音频降噪类的应用,该应用可以从带噪声的语音中恢复出更清晰的语音信号。由于噪 声的种类多种多样,传统的滤波方法非常有限。
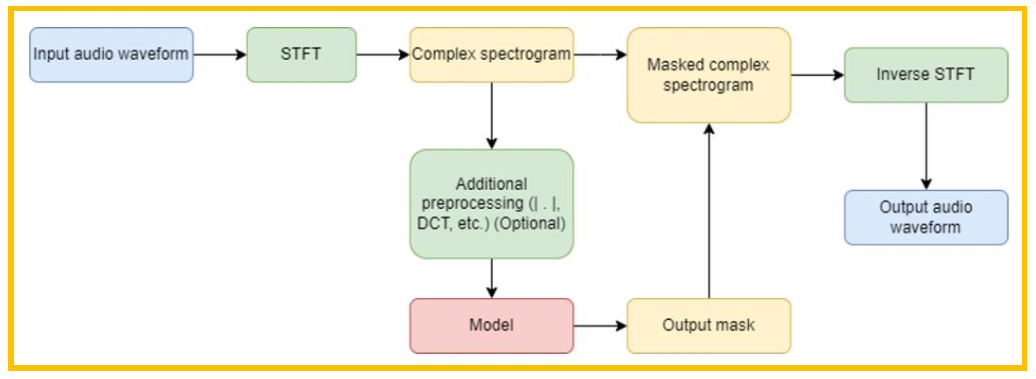
图8. 基本流程
SE 处理的基本流程如上所示,输入是带有噪声的语音信号,先经过STFT得到复频域的幅度 谱和相位谱,然后对其进行额外的如DCT操作等,预处理完成后输入模型进行处理,得到输出 的mask,使用输出的mask对频域进行处理,再使用逆STFT变换,最后得到输出的音频。
简单总结如下:带噪语音 → STFT → 幅度谱 → CNN → 增强幅度谱 → ISTFT(结合相位) → 增强语音。
其模型的损失函数可以是MSE,用于计算增强谱和干净谱的差异,经过CNN网络,最后得 到mask。训练使用的数据需要大量带噪语音和干净语音对。
其模型结构可以参考ST官方使用TCNN结构,官方的结构基于论文重新调整了一下结构, 删除了encoder和decoder部分,保留了主要的TCN结构,用STFT和ISTFT替代了 encoder 和decoder。 ST 预训练模型参考:https://github.com/STMicroelectronics/stm32ai modelzoo/blob/main/speech_enhancement/stft_tcnn/README.md

图9. 内存等基本信息

图10. 推理时间

图11. 指标
Note:在2.0.0版本上的推理时间有很大的优化空间,2.0.0版本上很多卷积操作还依赖于 软件实现,在更新版本中将由硬件NPU实现,修复该问题后推理时间会大幅优化,有兴趣可以 从官网下载模型,然后在最新版本的STEdgeAI工具上重新测试。
4. 视觉应用:Hand landmark
不同视觉类应用有一定的通用性,Hand landmark工程内用了两个模型,一个模型用于识别 手掌,一个模型用于标记关键点。本文以Hand Landmark为例,介绍基本的流程。
4.1. 摄像头配置
目前官方demo中主要支持三款摄像头:
• MB1854B IMX335 :DK板中自带的摄像头。
• ST VD66GY:ST全局快门的TOF。
• ST VD55G1:ST全局快门的TOF。
Camera sensor 的方向可以配置为:
• CMW_MIRRORFLIP_NONE:无翻转无镜像
• CMW_MIRRORFLIP_FLIP:翻转
• CMW_MIRRORFLIP_MIRROR:镜像
• CMW_MIRRORFLIP_FLIP_MIRROR:镜像+翻转
Hand landmark 的默认配置为:
#define CAMERA_FLIP CMW_MIRRORFLIP_MIRROR
图12. DCMIPP框图
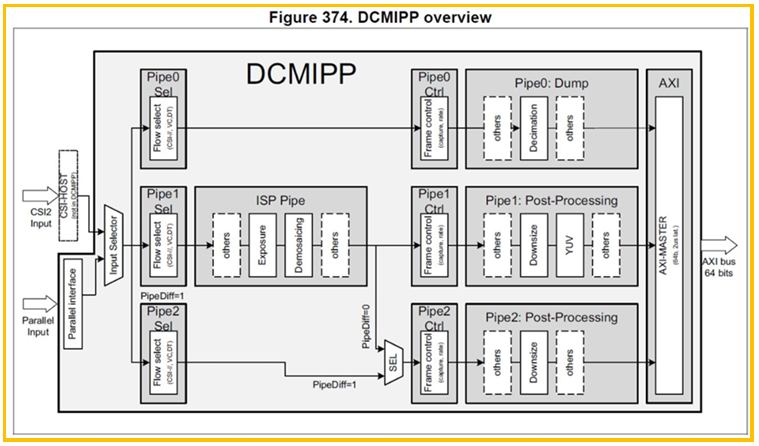
DCMIPP的大体框架如上图,总共有三个PIPE可以选择,数据源可以是CSI的接口也可以 是并口,不同PIPE对应的功能不同,一般PIPE1用于显示,PIPE2用于神经网络的输入。每个 功能块的详细差异建议参考官网手册RM0486。
图13. 数据流
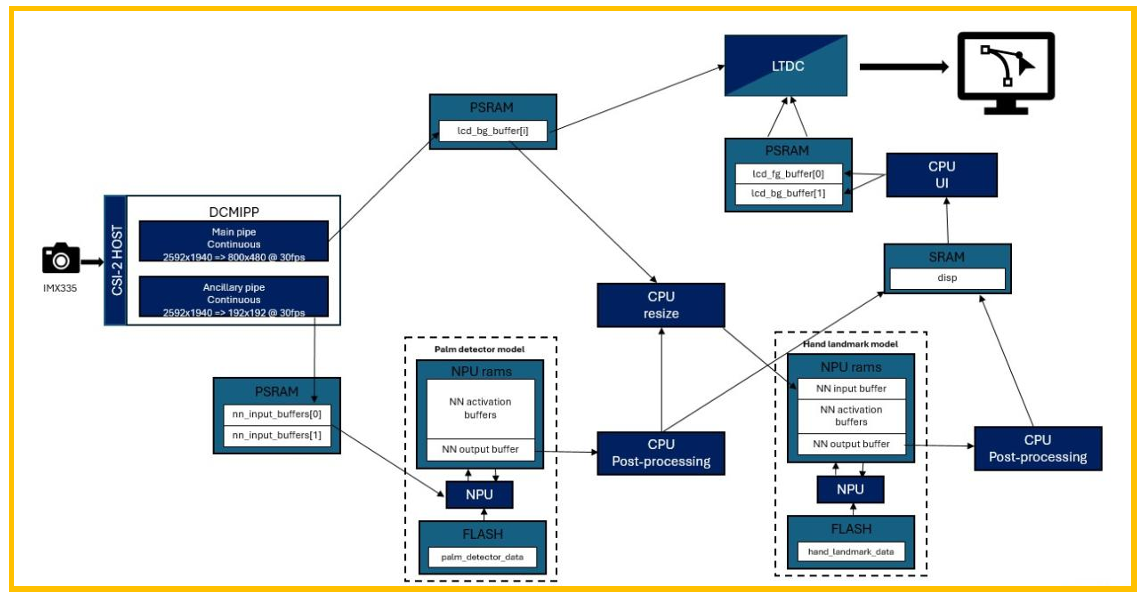
Hand landmark的数据流如上图所示,摄像头CSI接口输入2592x1940的数据流,经过 PIPE1转换为800x480,用于LCD进行显示,同时经过PIPE2转换为192x192的图片,放在 nn_input_buffer内,然后给第一个手掌检测模型,手掌检测模型进行后处理输出手掌的ROI区 LAT1609 LAT1609 - Rev 1.0 page 13/19 域以及旋转角度,然后使用CPU或GPU在用于显示的图片上进行Crop和Resize,将手掌区域 裁剪并压缩成第二个模型的输入形状,然后放入第二个关键点检测模型内进行推理,得到21个 关键点,与此同时,实时更新一些信息用于显示屏,画出手掌的框和关键点。
纵横比配置:
摄像头的输入图像,放在LCD显示屏上进行显示或者是放入神经网络进行识别,通常需要 对其进行压缩或裁剪。对于图像的分辨率,会有不同的模式对其进行处理,目前ST提供的中间 件中支持以下几种常见的处理:
图14. ASPECT_RATIO_CROP
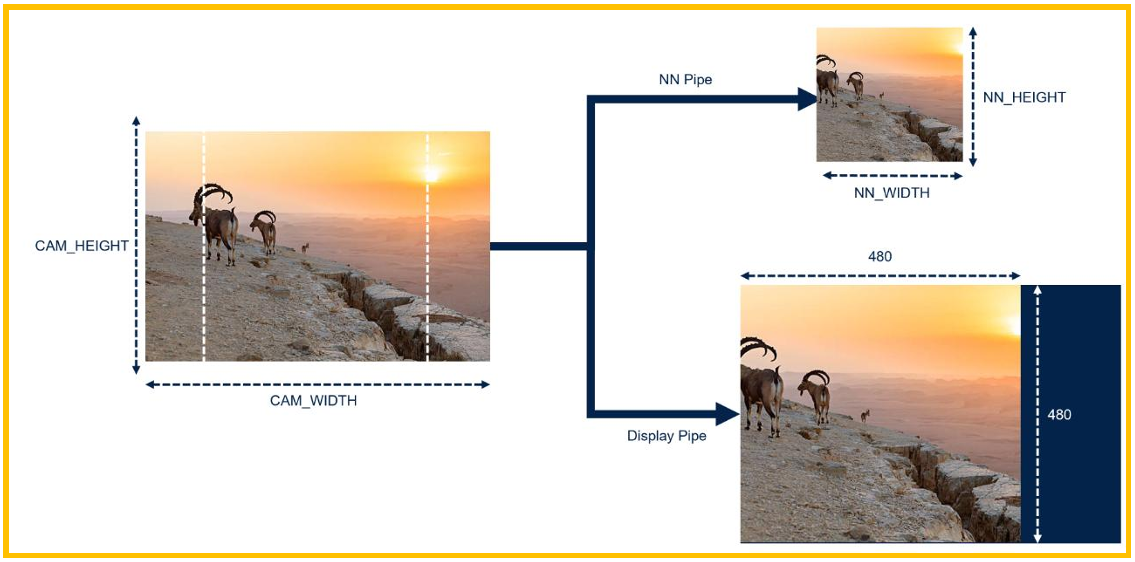
ASPECT_RATIO_CROP:对于NN pipe,将保持宽高比,但边沿的像素点会丢失。对于显 示用的display pipe,将和NN pipe使用一模一样的像素,但会放大到480x480的大小。
图15. ASPECT_RATIO_FIT
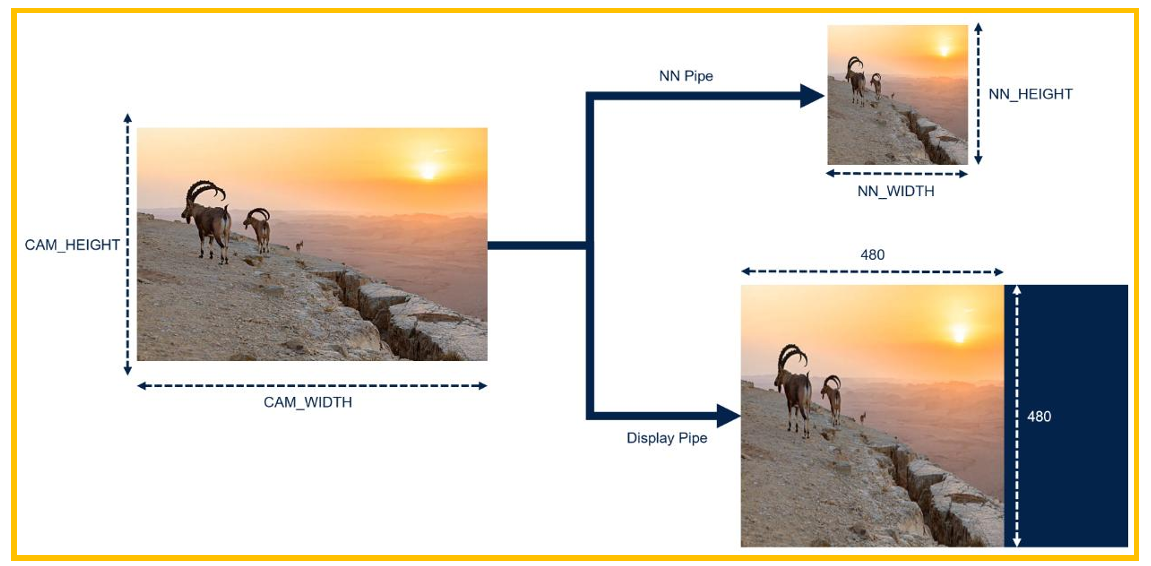
ASPECT_RATIO_FIT:该模式对于NN Pipe,会将原始图片压缩到NN输入的高和宽,但 由于NN需要的高宽比和摄像头的不一致,图片会发生变形,对于显示的display pipe,其使用 的和NN pipe的内容一致,但会放大到480x480的大小。
图16. ASPECT_RATIO_FULLSCREEN
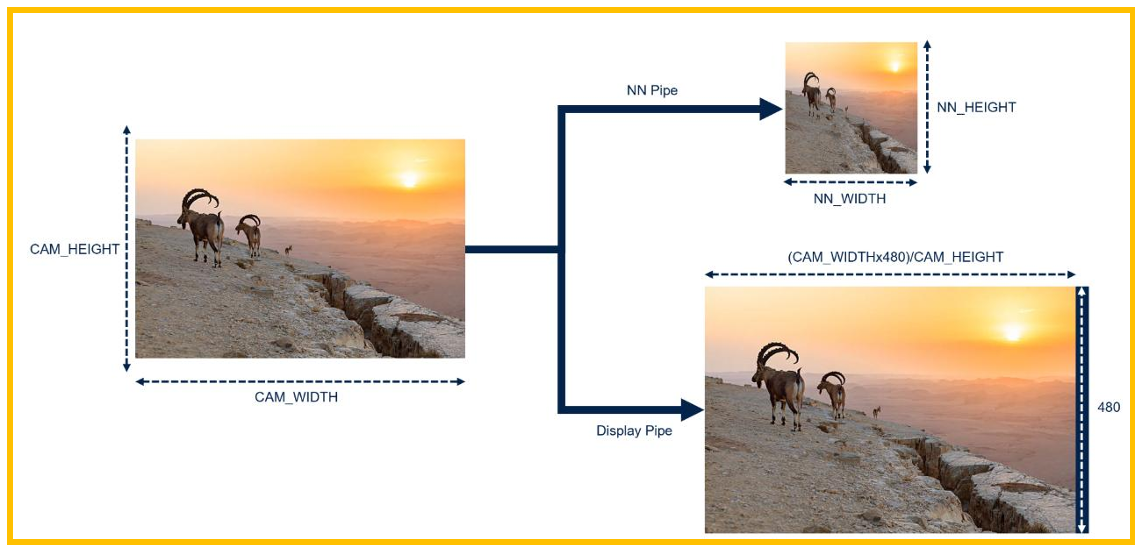
ASPECT_RATIO_FULLSCREEN:全屏模式,该模式对于NN pipe和前面模式一样,会将原 始图片压缩到NN的高宽比,这会使图片发生变形。对于Display pipe,则和前面模式不同,将 会对原始图片的高和宽进行一定比例的转换,使其适应到全屏800x480的比例。
CMW_Aspect_ratio_manual_roi:Hand landmark demo中使用的是这种实现,该方法 可以根据设定的ROI区域对原始图片进行裁剪,和ASPECT_RATIO_FULLSCREEN类似,但是 先进行CROP,将原始图片裁剪至LCD高宽比大小一致的区域,Display pipe保持裁剪后同比 例伸缩,NN pipe则是在裁剪后再压缩,会存在变形。
4.2. 模型部署
在Model目录下,有一个自动部署的脚本generate-n6-model.sh,内容如下:
图17. 部署脚本
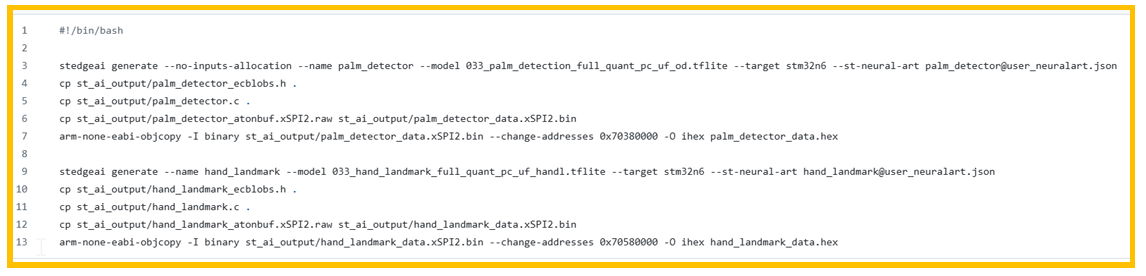
该脚本内主要使用stedgeai工具对模型进行转换,stedgeai generate指令会生成相 关.c, .h和模型权重文件。
参数:
--no-inputs-allocation:不再重新分配空间存储inputs。
--name palm_detector :命名为palm_detector,与后面的关键点检测模型区分开。
--model 033_palm_detection_full_quant_pc_uf_od.tflite :使用的模型文件。
--target stm32n6 :部署目标位STM32N6。
--st-neural-art palm_detector@user_neuralart.json:编译选项为 user_neuralart.json 文件中的 palm_detector。
CP指令将.c,.h 和.bin 拷贝到相关目录。
arm-none-eabi-objcopy -I binary st_ai_output/palm_detector_data.xSPI2.bin - change-addresses 0x70380000 -O ihex palm_detector_data.hex
这段指令将.bin添加地址信息0x70380000,即要烧录到flash中的地址,然后重命名为 xxx.hex。
后面一段只是将模型换成了关键点检测模型,其余类似,不再赘述。
图18. user_neuralart.json

user_neuralart.json 是配置文件,其中定义了两个不同的配置,一个用于手掌模型,一个用 于关键点模型。每个模型配置项主要有两项:
memory_pool: 指向内存配置文件,实际开发板如果内存布局有变更,需要更改该文件。
Options: stedgeai 要使用的编译选项,具体选项的含义可以查看stedgeai安装目录中相应 的documentation 目录中的文档,一般使用官方默认的即可,不需要修改。
图19. .mpool 文件
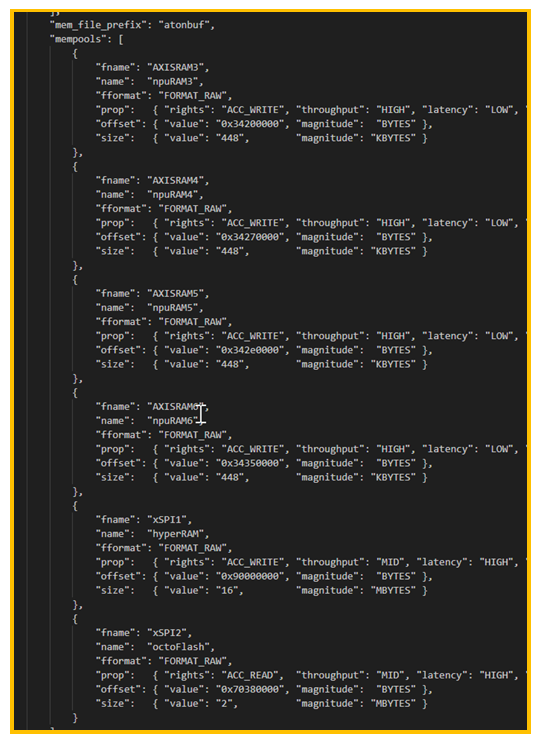
5. 总结
本文简单介绍了ST在github上AI相关的demo,包括语音和视觉类的应用,更详细的内 容及源码,建议直接从github上获取并阅读。
意法半导体公司及其子公司 (“ST”)保留随时对 ST 产品和 / 或本文档进行变更的权利,恕不另行通知。买方在订货之前应获取关于 ST 产 品的最新信息。 ST 产品的销售依照订单确认时的相关 ST 销售条款。 买方自行负责对 ST 产品的选择和使用, ST 概不承担与应用协助或买方产品设计相关的任何责任。 ST 不对任何知识产权进行任何明示或默示的授权或许可。 转售的 ST 产品如有不同于此处提供的信息的规定,将导致 ST 针对该产品授予的任何保证失效。 ST 和 ST 徽标是 ST 的商标。若需 ST 商标的更多信息,请参考 www.st.com/trademarks。所有其他产品或服务名称均为其 各自所有者的财 产。 本文档是ST中国本地团队的技术性文章,旨在交流与分享,并期望借此给予客户产品应用上足够的帮助或提醒。若文中内容存有局限或与ST 官网资料不一致,请以实际应用验证结果和ST官网最新发布的内容为准。您拥有完全自主权是否采纳本文档(包括代码,电路图等)信息, 我们也不承担因使用或采纳本文档内容而导致的任何风险。 本文档中的信息取代本文档所有早期版本中提供的信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)