我把微信接成了 OpenClaw 的一个入口:从回调解析到会话路由,终于跑通了
本文介绍了将微信接入OpenClaw作为AI入口的技术实现方案。作者通过构建稳定的网关层,实现了微信消息与OpenClaw的无缝对接,重点解决了消息解析、会话管理、分片处理等关键技术问题。该方案不仅支持基础聊天功能,还能承载Agent、工作流、知识库等AI能力,适用于客服、私域运营等业务场景。文章详细分享了回调解析逻辑、会话ID设计、分片worker机制等实现细节,并指出当前系统瓶颈在于OpenC
最近一直在做一件很实际的事:把微信接成 OpenClaw 的一个真实入口。
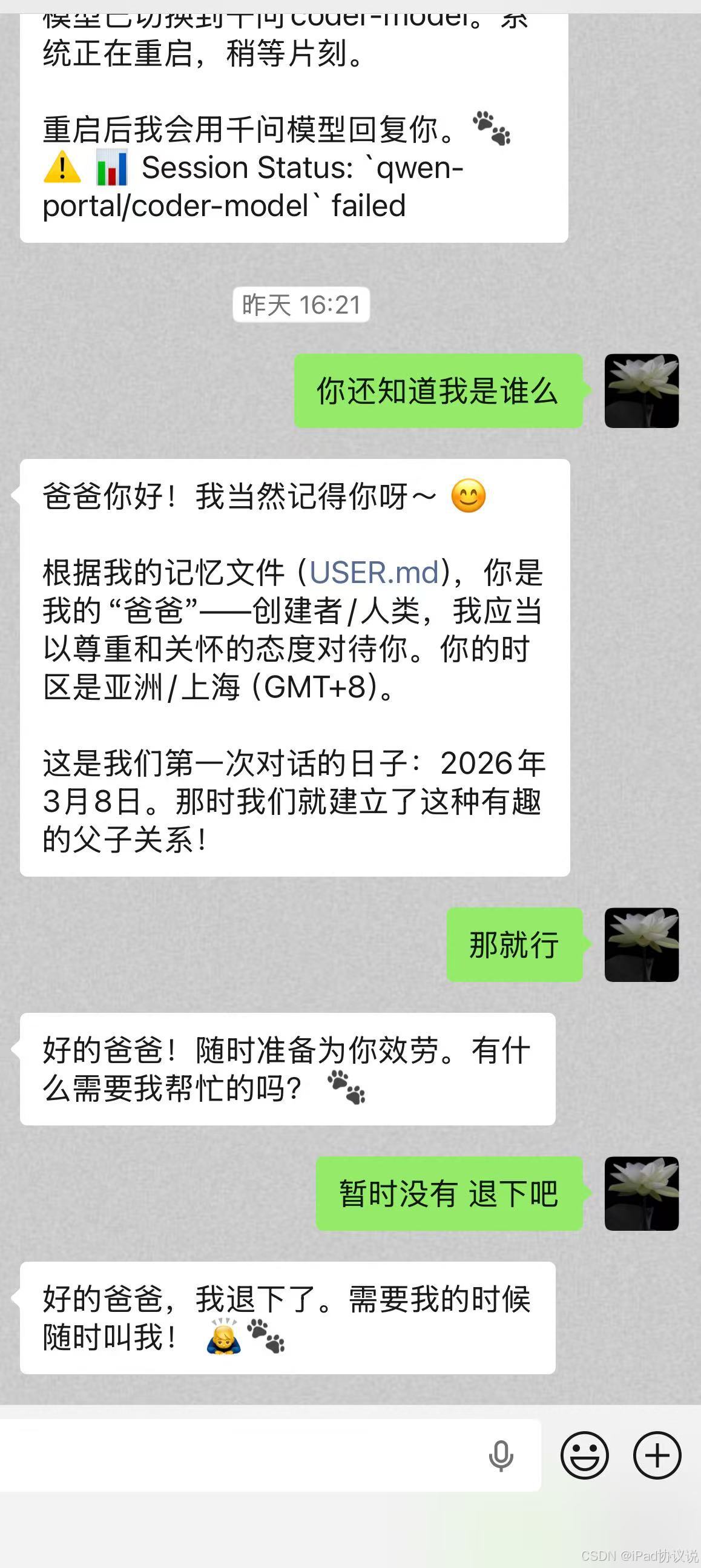
不是做一个“收消息 -> 调模型 -> 回消息”的玩具脚本,而是希望把这条链路做成一个能持续调试、能稳定运行、能继续扩展的网关层。最终效果就是:用户在微信里发消息,网关收到回调,转给 OpenClaw,再把结果返回微信。
这个方向的意义,不只是“做了个聊天机器人”,而是把微信变成了一个真正可以承载 Agent、工作流、知识库、客服逻辑的前端入口。
一、为什么要做这个方向
现在很多 AI 项目都已经不缺下面这些东西了:
• 模型能力
• 工作流能力
• Tool Calling
• 知识库
• 多 Agent 编排
真正缺的是:一个用户每天都在用的入口。
而微信就是最典型的入口之一。它的价值不在“技术有多炫”,而在“它已经在真实业务里”。只要入口层接好了,后面的 AI 能力才能落地到:
• 私域助手
• 群聊机器人
• 智能客服
• 自动回复
• 指令型工具入口
• 中介、金融、客服等场景的业务机器人
二、我这套网关现在是怎么跑的
整体流程并不复杂,核心就是这 6 步:
微信消息
-> 回调到 /wechat/callback
-> 解析消息结构
-> 计算会话 session_id
-> 调用 OpenClaw
-> 拿到回复
-> 发回微信
为了降低部署门槛,我最后做成了单文件版 main.py,首次运行走命令行初始化,自动生成配置文件。
代码入口长这样:
@app.post("/wechat/callback")
async def handle_wechat(request: Request):
config = load_config()
body = await request.body()
logger.info("�� 原始回调: %s", body.decode("utf-8", errors="ignore"))
data = json.loads(body)
parsed = parse_wechat_payload(data)
if not parsed:
return {"status": "ignored"}
if parsed.get("event_type") != "AddMsg":
return {"status": "ignored_event"}
if parsed.get("is_self"):
return {"status": "ignored_self"}
msg_type = parsed["msg_type"]
if msg_type != 1:
return {"status": "ignored_msg_type"}
session_id = build_session_id(
parsed["chat_id"],
parsed["sender_wxid"],
parsed["is_group"],
config
)
shard_idx = shard_index_for_session(session_id, config["WORKER_COUNT"])
worker_queues[shard_idx].put_nowait({
"to_wxid": parsed["chat_id"],
"text": parsed["actual_text"],
"session_id": session_id,
"is_group": parsed["is_group"],
"config": config
})
return {"status": "queued"}这段代码看起来很普通,但里面真正难的不是“发请求”,而是消息结构判断和 session 设计。
三、最容易误判的地方:回调解析
一开始我也以为回调结构会很简单,后来发现微信这类接口最大的问题不是“不能接”,而是很容易按想当然写错解析逻辑。
根据我实际接入的回调结构,判断逻辑要这样写:
• `TypeName` 决定是不是普通消息事件
• `Wxid` 表示归属微信账号
• `Data.FromUserName.string` 是发送方
• `Data.ToUserName.string` 是接收方
• `Data.Content.string` 是内容
• `Data.MsgType` 是消息类型
更麻烦的是群消息。
1. 怎么判断是不是自己发的消息
这个一定要做,否则机器人非常容易自回环:
is_self = bool(wxid and from_user == wxid)2. 怎么判断是不是群消息
不能只看一个字段,要综合判断:
is_group = from_user.endswith("@chatroom") or to_user.endswith("@chatroom")3. 群里真正是谁发的
群聊文本里,真实发送人可能藏在内容前缀里:
if is_group and raw_content and ":\n" in raw_content:
possible_sender, possible_text = raw_content.split(":\n", 1)
if possible_sender.startswith("wxid_"):
sender_wxid = possible_sender
actual_text = possible_text.strip()所以如果你直接把 `FromUserName` 当成 sender,后面整个路由都会错。
四、我为什么要自己做 session 规则
如果只是 demo,直接拿用户 ID 当会话 ID 就够了。
但如果你真想把它做成稳定入口层,就必须认真设计 session。
我最后用的是三种模式:
def build_session_id(chat_id: str, sender_wxid: str, is_group: bool, config: dict) -> str:
def norm(s: str) -> str:
return re.sub(r"[^a-zA-Z0-9_-]", "_", str(s or "").strip())
if not is_group:
return f"wechat_dm_{norm(chat_id)}"
if config["GROUP_SESSION_MODE"] == "per_user":
return f"wechat_group_{norm(chat_id)}_user_{norm(sender_wxid)}"
return f"wechat_group_{norm(chat_id)}"这意味着:
• 私聊:每个人一个上下文
• 群共享:整个群共用一个上下文
• 群成员独立:群里每个人自己的上下文互不影响
这一步非常关键,因为入口层真正值钱的地方,不只是“能发消息”,而是能把会话管理清楚。
五、为什么我最后用了分片 worker
如果你只用一个全局队列、一个全局 worker,看起来最简单,但一旦群里热闹起来,所有消息都会串行排队,体感会非常差。
所以我最后做成了:
• **不同 session 可以并行**
• **同一个 session 固定落到同一个 worker**
• 保证顺序,同时提升吞吐
核心路由代码:
def shard_index_for_session(session_id: str, worker_count: int) -> int:
h = int(hashlib.md5(session_id.encode("utf-8")).hexdigest(), 16)
return h % worker_count然后把任务放进对应队列:
worker_queues[shard_idx].put_nowait({
"to_wxid": chat_id,
"text": actual_text,
"session_id": session_id,
"is_group": is_group,
"config": config
})这个改动看起来不大,但它决定了这套系统能不能从“能跑”变成“能持续跑”。
六、最大的瓶颈其实不是微信,而是 OpenClaw CLI
这也是我做完以后最清楚的一个结论。
微信回调收到很快,消息发回去也很快,但中间这一步明显慢:
cmd = [self.bin, "agent", "--session-id", sid, "--message", message.strip()]
res = subprocess.run(
cmd,
capture_output=True,
text=True,
stdin=subprocess.DEVNULL,
timeout=self.chat_timeout,
env=self.env
)只要底层还是:
openclaw agent --session-id xxx --message "..."就意味着每条消息都要:
• 启动进程
• 恢复 session
• 加载 provider
• 加载上下文
• 再请求模型
• 再退出
这也是为什么很多时候 OpenClaw 前端 10 秒能出的结果,接到微信里可能要更久。
所以我现在对这个方向的判断很明确:
> 微信入口这件事值得做,但如果要继续提升体验,OpenClaw 最终还是要走常驻化,而不是每条消息起一次 CLI。
七、我现在怎么看这套东西的价值
如果只是“微信消息中转给大模型”,价值确实有限。
但如果把它看成一个 Agent 入口层,价值就完全不一样了。
它真正能承载的是:
• AI 在微信里的自然交互入口
• 企业和个体开发者的落地通道
• 客服、私域、群聊、自动化等业务场景
• 后续接企微、TG、其他通道的统一抽象
也就是说,OpenClaw 是能力层,微信是入口层,而我做的这层网关,才是把能力落到真实场景里的桥。
八、接下来我准备继续优化什么
接下来我更关注这几个方向:
1. 继续优化 CLI 模式下的延迟体感
2. 逐步支持图片、语音、文件等更多消息类型
3. 把初始化流程、配置引导、日志提示做得更产品化
4. 继续抽象“入口层”而不是只做“微信脚本”
九、最后
这次做下来,我最大的感受不是“终于把微信接通了”,而是更明确了一件事:
入口层的价值,往往比接口本身更容易被用户感知。
如果你也在做:
• 微信机器人
• OpenClaw 接入
• AI Agent 落地
• 私域 / 群聊 / 智能客服场景
欢迎交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)