AI大模型核心概念解析:从Token到模型蒸馏
作为后端开发者,您不需要成为算法专家,但需掌握这些核心概念的工程含义,才能在架构设计、资源规划和团队协作中做出正确决策。希望这篇详解助您夯实基础,高效驾驭 AI 大模型浪潮!
关键认知升级
作为后端开发者,您不需要成为算法专家,但需掌握这些核心概念的工程含义,才能在架构设计、资源规划和团队协作中做出正确决策。希望这篇详解助您夯实基础,高效驾驭 AI 大模型浪潮!
(1)参数量 ≠ 实际计算量:MoE 模型(如 Mixtral)用稀疏激活降低开销。
(2)微调不必全量:LoRA/QLoRA 让中小团队也能定制大模型。
(3)RAG 是当前最实用的落地路径:避免重训,快速接入业务数据。
(4)上下文长度要按需选择:不是越长越好,要考虑延迟与成本。
(5)量化是部署的关键:GGUF(llama.cpp)、AWQ、GPTQ 让大模型跑在消费硬件上。
深入理解AI大模型的核心概念是构建智能系统的关键。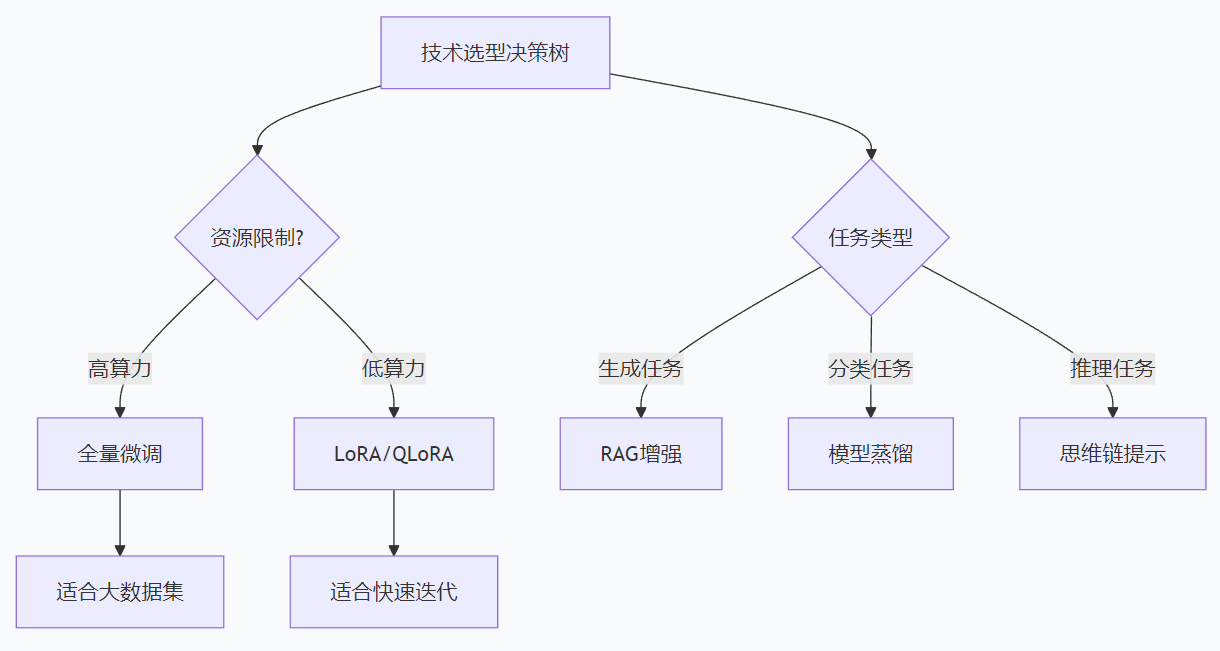
以下将系统性地梳理关键术语及其技术细节,结合实际场景与工程视角,帮助您快速建立知识框架。
1. Token:模型处理的基本单元
定义:在NLP领域,Token是模型处理文本的最小语义单位,通常对应单词、子词或字符片段。例如,英文句子"playing football"会被分词为[“play”, “##ing”, “football”](BPE算法)。
示例
(1)英文:“unhappiness” → [“un”, “happi”, “ness”]
(2)中文:“人工智能很强大” → [“人”, “工”, “智能”, “很”, “强大”](取决于 tokenizer)
原理:分词器(Tokenizer)通过预训练字典将文本映射为数字ID,模型通过处理这些ID进行计算。
重要性:
(1)模型的输入输出均以 token ID 序列形式表示,token直接影响模型输入输出的能力,决定文本表示效率。
(2)上下文长度(如 32k tokens)限制了单次可处理的文本量
工程影响及挑战:
(1)长文本处理:超出上下文长度需截断或分块+滑动窗口处理
(2)多语言支持:需适配不同语言的分词规则,不同语言 tokenization 效率差异大(中文通常比英文更“省 token”)
2. MoE(Mixture of Experts):可扩展的专家混合架构
定义:通过多个子网络(专家)和动态路由机制(门控网络)实现高效计算。
架构:
class MoE(nn.Module):
def __init__(self, experts: List[nn.Module], gate: nn.Module):
self.experts = experts
self.gate = gate
def forward(self, x):
weights = self.gate(x) # 计算各专家权重
outputs = sum(w * expert(x) for w, expert in zip(weights, self.experts))
优势:
(1)线性扩展性:专家数量增加不显著提升计算量
(2)动态资源分配:根据输入选择激活专家
典型应用:Google Switch Transformer通过MoE实现万亿参数模型的高效训练。
限制:推理时需管理专家负载均衡,增加系统复杂度。
3. RAG(Retrieval-Augmented Generation):增强生成的知识库范式
工作流:用户提问 → 2. 向量检索(从知识库召回 Top-K 文档)→ 3. 将问题+文档拼接为 prompt → 4. LLM 生成答案
关键技术:
(1)Embedding 模型:bge-large-zh(中文)、text-embedding-3-large(OpenAI)
(2)向量数据库:Milvus、Pinecone、Chroma、Weaviate
(3)分块策略:滑动窗口、语义分段(如 LangChain 的 RecursiveCharacterTextSplitter)
优势
(1)解决幻觉(Hallucination)
(2)支持实时/私有数据更新
(3)无需重新训练模型
场景对比
| 场景 | 传统LLM | RAG方案 |
|---|---|---|
| 实时数据查询 | 无法处理 | 可接入数据库 |
| 法律文书生成 | 知识模糊 | 支持条款引用 |
| 客服知识库问答 | 固定知识 | 动态更新知识 |
4. 微调(Fine-tuning):从通用到专用的桥梁
主流技术对比:
| 方法 | 参数更新量 | 显存占用 | 适用场景 |
|---|---|---|---|
| 全量微调 | 100% | 高 | 大数据集(>10万样本) |
| LoRA | 0.1-1% | 极低 | 小数据集快速迭代 |
| QLoRA | 0.1-1% | 超低 | 百亿参数模型单卡训练 |
名词说明
(1)LoRA(Low-Rank Adaptation):高效微调的核心技术,不修改原始大模型权重,而是在关键层(如注意力的 Q/K/V 投影矩阵)旁路注入低秩可训练矩阵。
(2)QLoRA:让百亿模型也能在单卡微调,QLoRA = Quantization + LoRA
工程实践:
(1)参数冻结策略:通常仅对最后几层注意力机制进行微调
(2)学习率调度:采用线性衰减或余弦退火防止过拟合
5. 上下文长度(Context Length):模型的"短期记忆"容量
现状
(1)早期模型:2K tokens(如 LLaMA-1)
(2)当前主流:32K(Llama 3)、128K(DeepSeek)、甚至 1M(Claude 3.5)
技术指标:通常以Token数衡量(如GPT-4的32k tokens)
实现挑战:
(1)位置编码扩展:需改造绝对位置编码为相对位置编码
(2)内存优化:使用FlashAttention等技术降低显存占用
工程建议:
(1)长上下文 ≠ 必须使用:多数任务 4K–8K 足够
(2)超长上下文显著增加延迟和显存,需权衡 ROI
演进趋势:2025年主流模型已实现百万级Token处理能力(如DeepSeek的1M context)
6. 模型蒸馏(Knowledge Distillation):压缩模型的炼金术
目标:用大模型(Teacher)指导小模型(Student)学习,压缩模型体积。
核心公式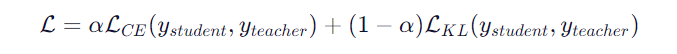
其中α控制分类损失与知识蒸馏损失的权重。
典型案例:
(1)BERT→DistilBERT(40%参数量,95%性能保留)
(2)GPT-3→GPT-NeoX(参数量从1750亿降至200亿)
工程权衡:精度损失与推理速度提升的平衡点需通过实验确定。
7. 模型参数(Model Parameters):能力与成本的天平
量化分析
| 参数量级 | 显存占用(FP16) | 训练成本(以A100计) |
|---|---|---|
| 100M | 2GB | ~$100 |
| 1B | 20GB | ~$10,000 |
| 100B | 200GB | ~$1M |
参数效率:MoE架构可使实际活跃参数占比降至5-10%,显著降低计算开销。
8. 参数量级:1B、7B、70B 到底是什么意思
单位换算
1B = 1 Billion = 10⁹ = 1,000,000,000(十亿)
常见单位:
M(Million)= 百万 = 10⁶
B(Billion)= 十亿 = 10⁹
T(Trillion)= 万亿 = 10¹²
例如:7B 参数 = 7 × 10⁹ = 70 亿个可训练参数。
存储与显存估算(以 FP16 精度为例)
| 参数量 | FP16 显存占用(仅模型权重) | 实际训练显存(含优化器、梯度等) |
|---|---|---|
| 1B | ~2 GB | ~16–20 GB |
| 7B | ~14 GB | ~80–100 GB |
| 13B | ~26 GB | ~160 GB |
| -70B | ~140 | GB >1 TB(需多卡+模型并行) |
注:FP16 每个参数占 2 字节;训练时还需存储梯度(同大小)和 Adam 优化器状态(2×参数大小),故总显存 ≈ 4×模型权重。
9. 主流开源大模型参数量级参考
| 模型系列 | 典型参数量 | 特点 | 适用场景 |
|---|---|---|---|
| Llama 3 | 8B / 70B | Meta 开源,性能强,社区生态好 | 通用推理、微调 |
| Mistral | 7B / Mixtral 8x7B (MoE) | 高效推理,支持长上下文(32k+) | API 服务、RAG |
| Qwen (通义千问) | 1.8B / 7B / 72B | 中文优化,支持多语言 | 中文 NLP、企业私有部署 |
| DeepSeek | 7B / 67B | 支持 | 128K 上下文,代码能力强 长文档、编程助手 |
| Phi-3 | 3.8B | 微软轻量级,小模型高性能 | 边缘设备、低资源部署 |
💡 Mixtral 8x7B 虽标称“56B”,但 MoE 架构下每次前向仅激活 2 个专家(约 14B 活跃参数),实际计算量接近 13B 模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)