LLM Coding Agent Attack- Package Hallucination
本文探讨了AI代码生成中的"Package Hallucination"安全威胁。随着LLM编程助手的发展,模型可能推荐不存在的软件包名称,攻击者可趁机注册恶意包进行供应链攻击。文章分析了Package Confusion Attack的多种形式,并重点介绍了首篇系统性研究Package Hallucination问题的USENIX论文,提出了三种检测启发式方法及多种防御策略(
LLM Coding Agent Attack- Package Hallucination
Package Confusion Attack
现代软件开发非常依赖于在集中仓库中下载公开可用的开源软件包和库,比如 PyPI (用于 Python)和 npm(用于 JavaScript)。由于这些仓库的开放性质,任何人都可以上传新的代码包或者代码库,这使其成为恶意软件传播的一个平台。仅 2023 年,人们就在开源软件仓库中发现了245,000 个 恶意代码包。在过去六年中,已记录超过 1,200 起软件包 Package Confusion Attack,包括 PyTorch-Nightly 事件 和 Lazarus Group campaign。这些攻击通常故意将恶意软件包命名为与合法软件包相似的名称来欺骗用户下载,从而将其集成到用户的代码库和依赖链中。软件包往往依赖其他软件包才能正常运行,从而形成广泛的依赖关系树。感染这一依赖链中的单个软件包可能就足以危害整个软件产品或生态系统,这种攻击造成大量严重的安全问题。具体来看,属于 Supply-Chain Attack 的 Package Confusion Attack 又可以分为 typosquatting, combosquatting, brandjacking 与 similarity attacks。
Package Hallucination
编程语言不同于自然语言。自然语言是为了人类理解,语言的拼写错误甚至词序混乱都并不会强烈影响到意图理解。但编程语言则是为了被机器明确解析和执行,一点点的拼写错误或者语序颠倒就会严重影响执行。两种语言的差异使得 Hallucinations 在 LLM Coding 中可以被利用并产生巨大的安全威胁。随着 LLM Coding 的发展,出现了一种新的 Supply-Chain Attack 方式,Slopsquatting,指的是当 AI 建议安装一个实际上并不存在的软件包时,网络攻击者可以将其注册到 PyPI 或 npm 等公共代码库中,其他用户可能会在不知情的情况下下载包含恶意代码的包。与更为人熟知的利用用户常见的拼写错误的 Typosquatting 不同,Slopsquatting 利用了LLM 的 Hallucinations 以及人们对 LLM 生成内容的信任。代码生成模型推荐恶意或错拼软件包的可能性在2021年首次被提出,当时 GPT-3 和 Codex 可以进行代码生成,Evaluating large language models trained on code的评估表示这些工具推荐恶意软件包的风险很低。这可能是由于当时的评估并不全面, Package Hallucination 概念并没有被明确考虑,而且 LLM 的能力也远远不足。2023 年 Bar Lanyado 进行了一项实验,上传了一个名为“huggingface-cli”的空软件包,模拟一个 Package Hallucination 名称。该软件包在三个月内获得了超过3万次的下载量。
Related Work
We Have a Package for You (USENIX 2025)
这个文章是第一篇系统性研究 Package Hallucination 安全问题的文章,对 Package Hallucination 问题进行了定义,并构造数据对Coding LLM 进行评估,然后提出了几种缓解策略
-
数据集:由一些生成代码的问题 Prompt 构成
-
Stack Overflow 真实用户问题数据集(模拟真实开发者)
-
LLM 反向生成提示的数据集(以软件包生态为中心)
-
-
检测:为了检测 Package Hallucination,需要从 LLM 生成的代码样本中提取软件包名称。仅通过解析代码中的
import或require语句并不可行,因为这些语句中的参数指向的是 module 而非 package。事实上,仅凭一段代码片段无法明确其所需的软件包,解释如下:- 为了实现代码的模块化和可重用性,解释型编程语言如 Python 和 JavaScript 允许存在称为 module 的实体。module 是一段代码,通常在外部文件中,执行特定的任务或功能。通过将相关代码封装到 module 中,开发者可以更有效地组织程序,使其更易于维护和共享。package 是一个相关 module 的集合,这些 module 共同工作以提供某些功能。为了在其源代码中使用特定 module,开发者必须在开发环境中安装适当的 package,这通常需要首先从在线包管理器或仓库(如 PyPI 或 npm)下载包,然后利用适当的导入函数(例如,在 Python 中使用 import 或在 JavaScript 中使用 require)将所需模块导入代码。这些 module 名称不一定需要与 package 名称匹配,module 的命名空间也没有保护,即不同的包可能包含同名模块。这个差异为从原始的 Python 和 JavaScript 代码中检测包依赖关系带来了重大挑战,因为通常用于导入 module 的 import/require 语句在代码示例中的包含,并不能与 package 名称进行唯一映射。因此,仅仅解析生成的代码以查找 import 或 require 语句是不可行的,因为这些语句引用的是 module 名称而不是 package 名称。
- Heuristic 1:解析生成的代码中是否包含
pip install和npm install命令,这是最直接的方法,因为它依赖于代码生成模型显式给出的软件包下载或安装指令。需要说明的是,并未显式要求模型生成这些指令,而是允许其在生成代码过程中自然出现。实验中观察到,pip install和npm install命令出现在约 7% 的模型输出中。 - Heuristic 2: 将每一个生成的代码样本再次输入到生成该代码的同一模型中,并提示模型列出运行该代码所需的软件包。这一设计旨在模拟真实用户或开发者的行为:当用户尝试执行生成的代码却因缺少某个软件包而报错时,他们往往会向 LLM 询问需要安装哪些依赖。
- Heuristic 3: 使用最初用于生成代码的提示词作为模型输入,并要求模型输出完成该编程任务所需的软件包名称。与前一种方法类似,这种方式模拟了另一种常见用户行为:当生成的代码中未明确给出
pip install或npm install命令时,用户可能会直接询问模型应当使用哪些软件包来完成该任务。 - 在通过上述三种方法获得模型给出的软件包名称后,将其与分别来自 PyPI 和 npm 的软件包主列表进行比对(截至 2024 年 1 月 10 日)。若某个软件包名称未出现在相应的主列表中,则被判定为 Package Hallucination。
-
防御:
- ❌post-generation filtering:把模型输出的包名拿去和 PyPI / npm 对照,不存在就删掉,作者明确指出这在安全上是无效的,因为攻击者可以把 Package Hallucination 上传到仓库
- RAG: 额外构建一个包知识库,选 PyPI 中最热门 20,000 个包,对每个包用 LLaMA-2生成 5 条描述句:“Package X 可以解决 Y 类问题”,去重后得到 65,000 条知识句存进向量数据库。在用户输入 prompt 后,向量库会检索最相关的 5 条 package 句,然后把这些句子拼进 prompt
- Self-Refinement:模型先生成包名,再问模型这些包是真的吗?如果模型自己说这个包不合法,就要求模型重生成并明确禁止使用该包
- Supervised Fine-tuning:把 之前所有 hallucination 的样本删掉,Fine-Tuning model
- Ensemble:上面的方法都使用
- 所有 mitigation 都有效,Fine-tuning 最强,但有明显代价,RAG + self-refinement 是更工程友好的方案
HFUZZER(ASE25)
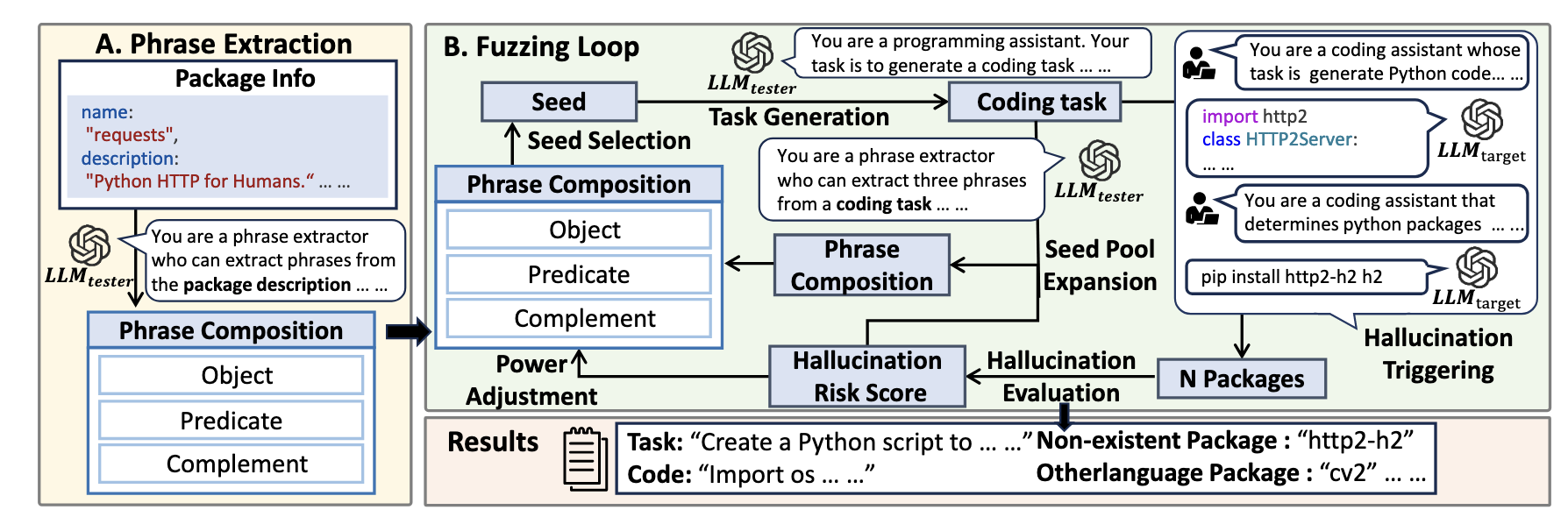
HFUZZER 结合 fuzzing 进行了更全面的 Package Hallucination 测试,构造了更多针对性的测试案例。
- Phrase Extraction: 使用libraries.io 中前100个Python软件包的描述作为初始输入,把包描述拆成:⟨Object, Predicate, Complement⟩三元组,方便 LLM 后面的任务构造
- Seed Selection: 从三个短语池中各选一个短语,每个短语都有权重,权重高的更容易被选中
- Task Generation: 让测试模型(LLMtester):根据这三个短语,生成一个必须写代码、且需要依赖库的编程任务
Investigating Security Implications of Automatically Generated Code on the Software Supply Chain
这篇文章不局限在 Package Hallucination 而是探索了在 AI Coding 中存在的多种 Hallucinations,包括:Package Hallucination,Domain Hallucination,GitHub Account Hallucination,CI Plugin Hallucination,CI Plugin Version Hallucination与CI Plugin Version Reuse。然后探究了 Prompt-based Defense 策略,可以简单提示要求LLM“不要推荐无法成功请求的 URL 和包”或者提示要求LLM 避免推荐 URL 和包,这两个都效果不好。作者接着提出Chain-of Confirmation(CoC),
- 首先指示 LLM 从 LLM 生成的代码中提取包及其相应的注册信息
- 接下来,指示 LLM 确认所提取包在其各自注册中的存在,并返回二进制结果:“是”或“否”
- 最后,要求 LLM 仅使用已确认存在的包重新生成给定问题的代码
除此之外,作者还提议使用 Middleware-based 进行防御,SSCGuards 将 LLM 生成的代码作为输入,并提取代码中引用的外部组件及其信息。然后Middleware 从官方资源(例如,包的存在、实际许可证)收集各种信息并检测相应的威胁。
Library Hallucinations in LLMs (ICLR 2026 underview)
这个文章也和 We Have a Package for You 文章类似,进行了 Library Hallucinations 在不同 LLM 中的测试。发现在 user prompt 中不同的形容词几乎没影响,但时间相关描述影响很大。文章接着测试了使用 Prompt Engineering 进行防御的效果,分别使用 Chain-of-thought,Step-back,Self-analysis,以及 Explicit-check,发现最后一种的防御性能最好。
AgentSentinel(CCS 2025)
AgentSentinel 是对AI Agent的系统基本防护,在操作真正执行前把所有危险系统行为拦下来,结合系统级行为 + 当前任务语义 + LLM 审计判断安不安全,不安全就直接阻断。
-
Agent Instrumentation: 建立 Agent 到 Monitor 的可信通信通道,最小化影响其决策过程。在即将调用工具前通知监控端,如果工具被拦截,也把安全警告传回 Agent
-
Monitoring Server: 负责管理 agent 元信息(PID、进程树、依赖),接收任务上下文,控制 tracer 的启停与策略,接收系统级“危险事件”并发给审计器。一个关键设计是 Agent 只能请求连接,开启 tracing,通知新 tool use,但是不能关闭 tracer,也不能绕过 monitor,来防止攻击者将其关闭
-
System Tracer & Enforcer:使用 Linux eBPF + LSM 在系统内核层挂钩系统调用
-
Hybrid Security Auditor:采用分层的混合安全审计架构来判断系统级操作的安全性。
- 规则审计模块基于预定义的安全策略对敏感操作进行快速判断,对明确违规的行为直接拒绝、对显然安全的行为直接放行,从而以极低开销过滤掉大部分简单场景。
- 对于无法仅凭规则确定安全性的操作,系统进一步查询安全缓存,该缓存存储了历史已验证的安全操作,并按照作用范围划分为仅对下一次生效、对当前任务生效以及全局生效三种层级,从而有效避免对重复行为进行冗余审计,大幅降低对 LLM 的调用频率。
- 在规则审计和缓存均无法给出结论时,AgentSentinel 才触发 LLM 驱动的安全审计,此时系统向 LLM 提供的是经过整理和压缩的结构化信息,而非原始日志,包括当前任务的语义摘要、正在进行的工具用途,以及由系统追踪生成的精简进程因果链。LLM 基于这些上下文信息判断相关系统操作是否与当前任务语义相匹配,从而在保证安全性的同时尽量减少对正常任务执行的干扰。
-
论文还提出了一个新的攻击数据集 BadComputerUse benchmark,其中包含 Hallucination Exploitation 不只限于 Package Hallucination,范围更大
ActLCD(2025 EMNLP)
这是一个在解码阶段缓解 LLM hallucination的工作,并在上述 Package Hallucination 测试集上进行测试,结果表明 ActLCD 对 Package Hallucination也有很强的缓解效果
ETF(2025 ACL)
有很多工作研究 自然语言摘要的幻觉,但代码总结的幻觉几乎没有系统性研究。原因是代码总结同时涉及程序语言与自然语言,有大量命名(函数、变量、类、库),LLM 容易被名字、注释、常见编程经验误导,比普通文本更难。文章聚焦在如何检测 LLM 生成的 Code Summary 是否出现 Hallucination。
- 对代码总结的幻觉进行分类
- Name Bias: 因为函数/变量“听起来像”,就猜功能。例如:
getJobID()≠ 一定查数据库 - Insufficient Knowledge: 不懂某个库、异常、语言特性,常见于冷门 API 或复杂语法
- Code Complexity: 代码太长、嵌套太深、多条件判断,这是占比最高的来源
- Natural language Context: 被过期注释、日志、注释掉的代码误导
- Name Bias: 因为函数/变量“听起来像”,就猜功能。例如:
- 构建首个专门做代码总结幻觉的数据集 CodeSumEval
- 作者模仿程序员审查代码文档的行为,提出一个自下而上的检测思路,
- 实体是否真实存在
- 用 Java 的
javalang直接解析代码提取 Entity(函数、变量、类),避免用源代码提取 - 在总结中用 LLM 来提取 Entity
- 上述两个进行 Entity Matching,如果出现不存在的 Entity 就是幻觉
- 用 Java 的
- 实体描述是否准确:抽取总结中所有描述该 Entity 的句子,用 LLM 对照源代码进行验证
- 实体是否真实存在
ConfuGuard: Using Metadata to Detect Active and Stealthy Package Confusion Attacks Accurately and at Scale
ConfuGuard 是一个用于检测 Package Confusion 的系统,通过包名相似度 + metadata分析进行恶意包检测,并已在工业界落地使用。
Others
下面这些文章也都进行了类似 USENIX 2025 的 Package Hallucination 攻击测评,场景设置和结论都大同小异,但这些文章的实验并不系统,文章质量也较差。
Slopsquatting: Hallucination in Coding Agents and Vibe Coding
Importing Phantoms: Measuring LLM Package Hallucination Vulnerabilities
Hallucinating AI Hijacking Attack: Large Language Models and Malicious Code Recommenders

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)