DeepSeek实战--RAG提升召回准确率
本文介绍了如何利用MaxKB知识库系统提升AI解答数学题的准确性。通过将数学试题转换为Markdown格式并优化分段规则,构建知识库后测试不同检索方式(向量、全文、混合搜索)的效果。实验表明,该方法能显著提高答案准确率,并提供详细解题步骤。但同时也发现模型会回答知识库外的内容,这需要进一步优化。该方案有效解决了大模型在数学问题上的幻觉问题,为学生提供了更可靠的解题辅助。
1. 背景
大模型提供的信息,因为幻觉问题,会出现“一本正经胡说八道”的情况,对于非研发人员,不知道大模型幻觉特性,很容易被误导。带着这个问题,我们今天来提升AI 回答数学问题的准确性,让学生获得更加准确的答案及解题方法。
2. 环境准备
智能知识库MaxKB,前文已经介绍部署过程
https://blog.csdn.net/qq_36918149/article/details/153527187?spm=1001.2014.3001.5501
3. 实战
Step1: 准备数学试题
先去拍一点,你娃或别人家娃的数学作业试题
Step2: AI 解析题目
用DeepSeek 将图片转换为文本,数据的格式推荐使用 MarkDown,原因有两点,一是 MarkDown 可以显示数学公式,二是做文档切分时,如果选择按标题等级区分,会比较容易。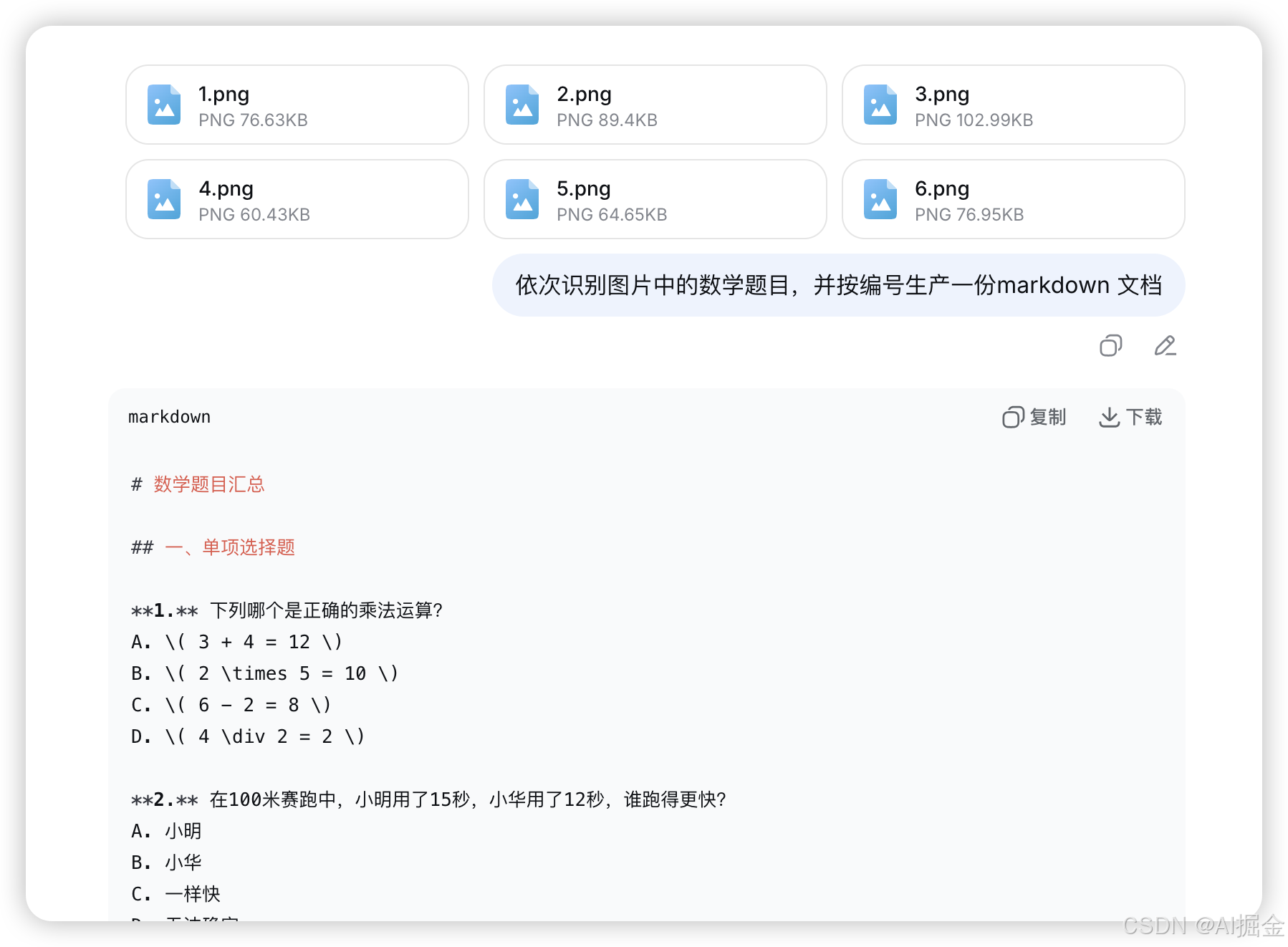
生成的markdown 文档
# 数学题目汇总
## 一、单项选择题
**1.** 下列哪个是正确的乘法运算?
A. \( 3 + 4 = 12 \)
B. \( 2 \times 5 = 10 \)
C. \( 6 - 2 = 8 \)
D. \( 4 \div 2 = 2 \)
**2.** 在100米赛跑中,小明用了15秒,小华用了12秒,谁跑得更快?
A. 小明
B. 小华
C. 一样快
D. 无法确定
答案:B
**4.** 如果今天是小明生日,他过了生日后,年龄会变成15岁,那么小明过生日前的年龄是多少岁?
A. 14岁
B. 15岁
C. 16岁
D. 13岁
答案:A
**5.** 下列哪个是正确的分数表示?
A. \(1/2\)
B. \(2/1\)
C. \(1/0\)
D. \(0/1\)
答案:A
**7.** 下列哪个是正确的减法运算?
A. \( 5 - 3 = 8 \)
B. \( 7 - 2 = 5 \)
C. \( 9 - 4 = 5 \)
D. \( 6 - 1 = 7 \)
答案:B
**10.** 如果一个苹果重200克,三个苹果重多少克?
A. 400克
B. 600克
C. 800克
D. 1000克
答案:B
Step3: AI 格式数学试题
将文档中的所有数学公式,用markdown inline math 表示
# 数学题目汇总
## 一、单项选择题
**1.** 下列哪个是正确的乘法运算?
A. $3 + 4 = 12$
B. $2 \times 5 = 10$
C. $6 - 2 = 8$
D. $4 \div 2 = 2$
**2.** 在100米赛跑中,小明用了15秒,小华用了12秒,谁跑得更快?
A. 小明
B. 小华
C. 一样快
D. 无法确定
答案:B
**4.** 如果今天是小明生日,他过了生日后,年龄会变成15岁,那么小明过生日前的年龄是多少岁?
A. 14岁
B. 15岁
C. 16岁
D. 13岁
答案:A
**5.** 下列哪个是正确的分数表示?
A. $1/2$
B. $2/1$
C. $1/0$
D. $0/1$
答案:A
**7.** 下列哪个是正确的减法运算?
A. $5 - 3 = 8$
B. $7 - 2 = 5$
C. $9 - 4 = 5$
D. $6 - 1 = 7$
答案:B
**10.** 如果一个苹果重200克,三个苹果重多少克?
A. 400克
B. 600克
C. 800克
D. 1000克
答案:B
Step4: 创建知识库
数据清洗完毕后,我们就可以建立知识库,并导入文档了。点击创建知识库,填入名称、描述、向量模型等信息,之后点击创建。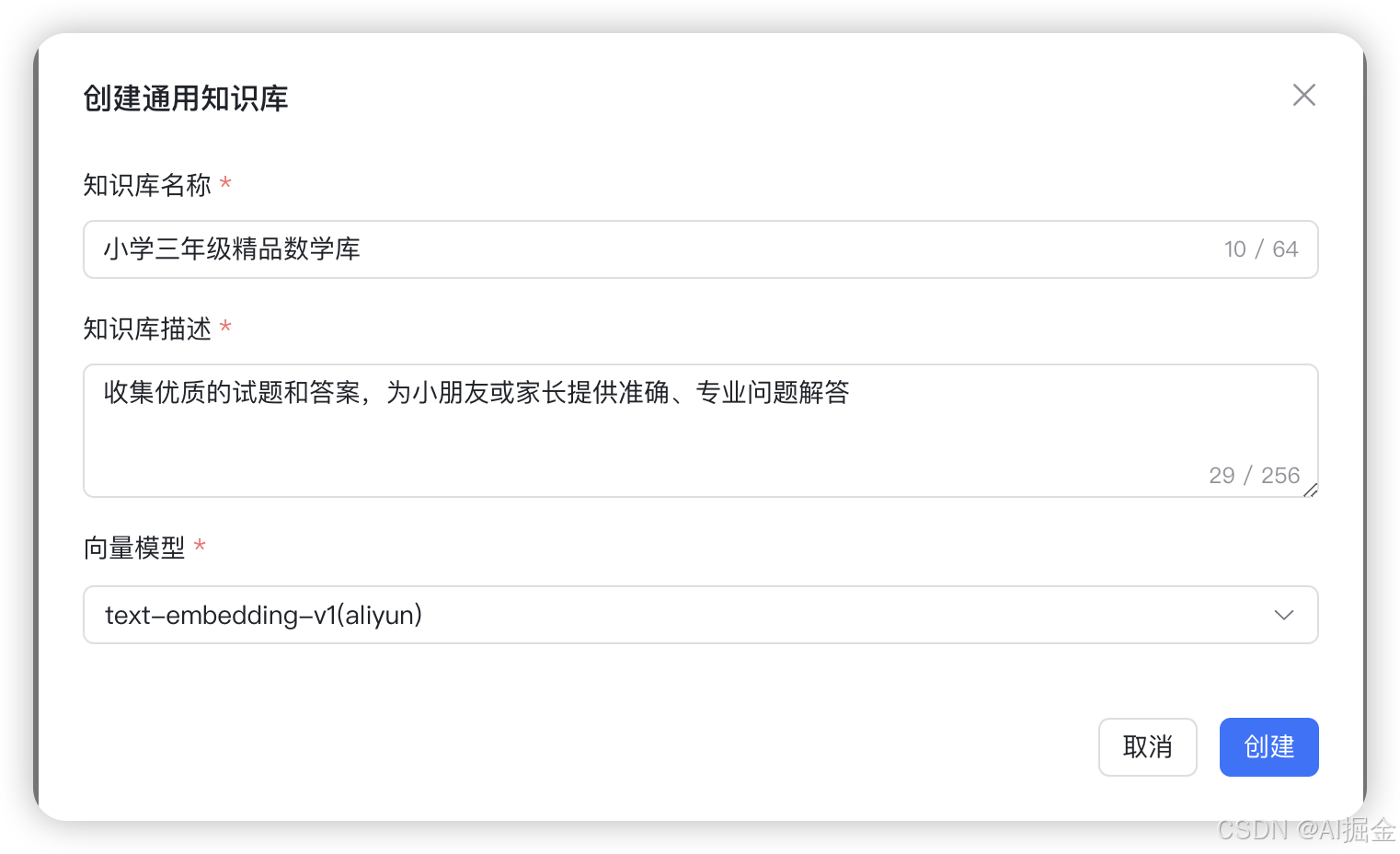
Step5: 上传资料
然后选择上传文档(上传 DeepSeek 帮我们整理过格式的版本)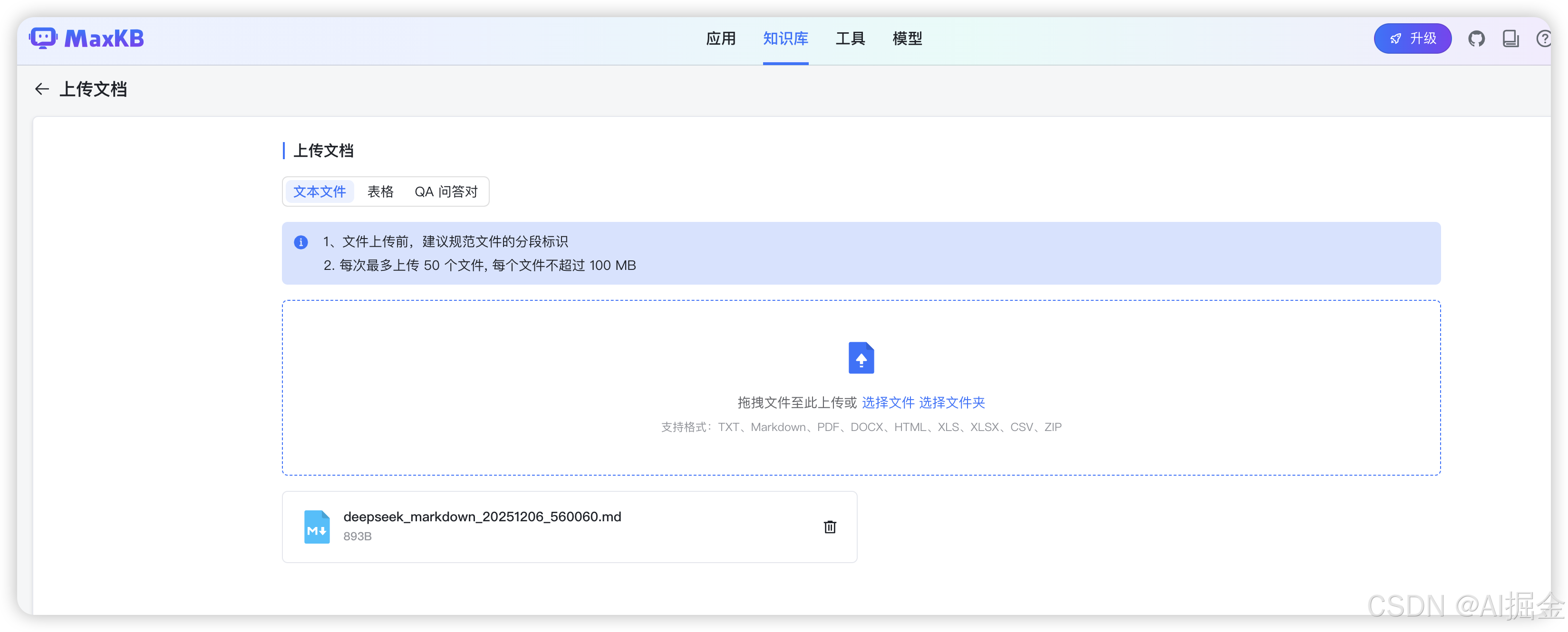
Step6: 分段
用智能分段,看一下效果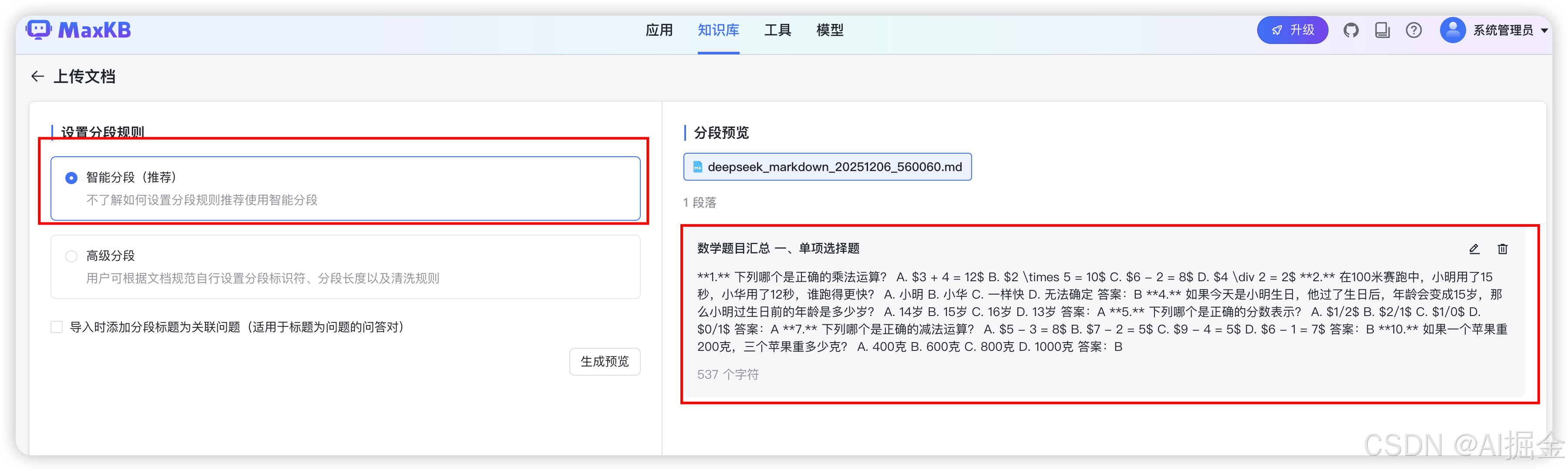
可以看到,其实分得并不理想。期待的效果是每一道题分一段,这样会匹配的非常准确,但现实是多道选择题挤到了一段里。这时我们就可以点击高级分段,看看能不能自己调整一下分段规则,达成想要的效果。我将文档中加入“----------”用于分段切割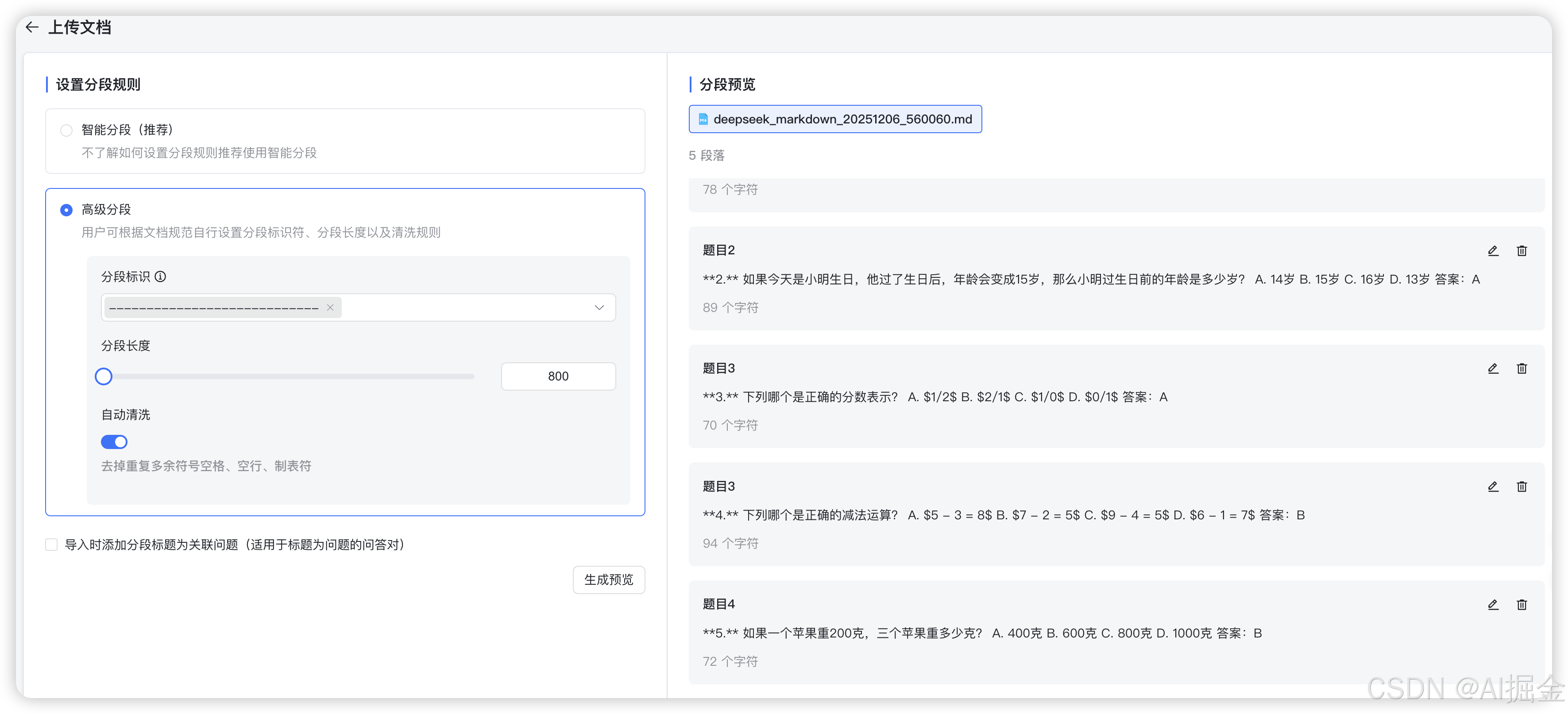
这时候点击开始导入,系统就会自动对这些分段进行向量化和存入向量数据库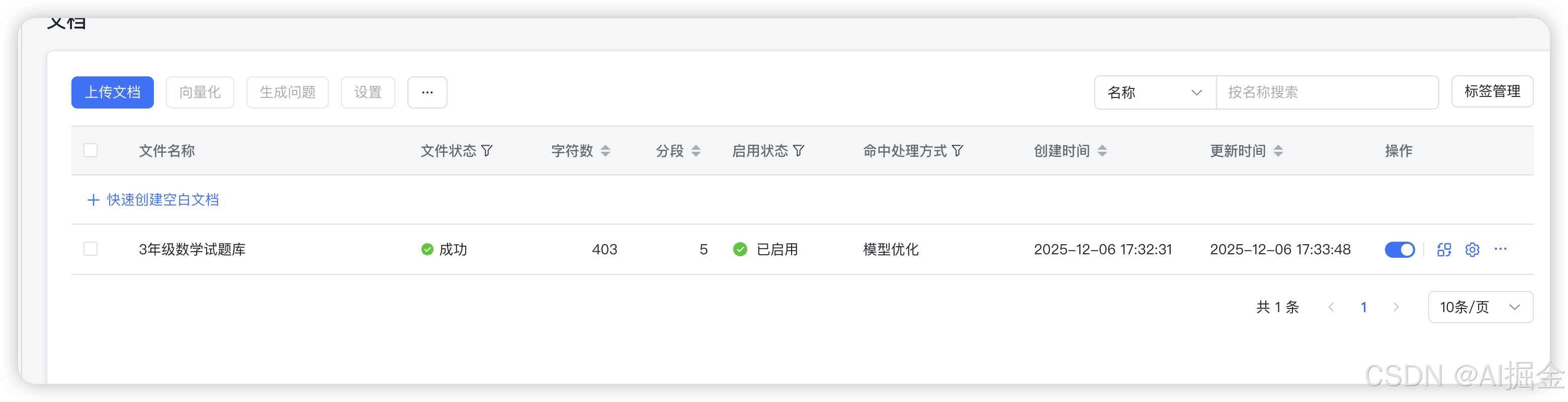
Step7: 命中测试
文档向量化后,我们可以通过左侧的命中测试,调节不同的参数,来测试文档搜索的效果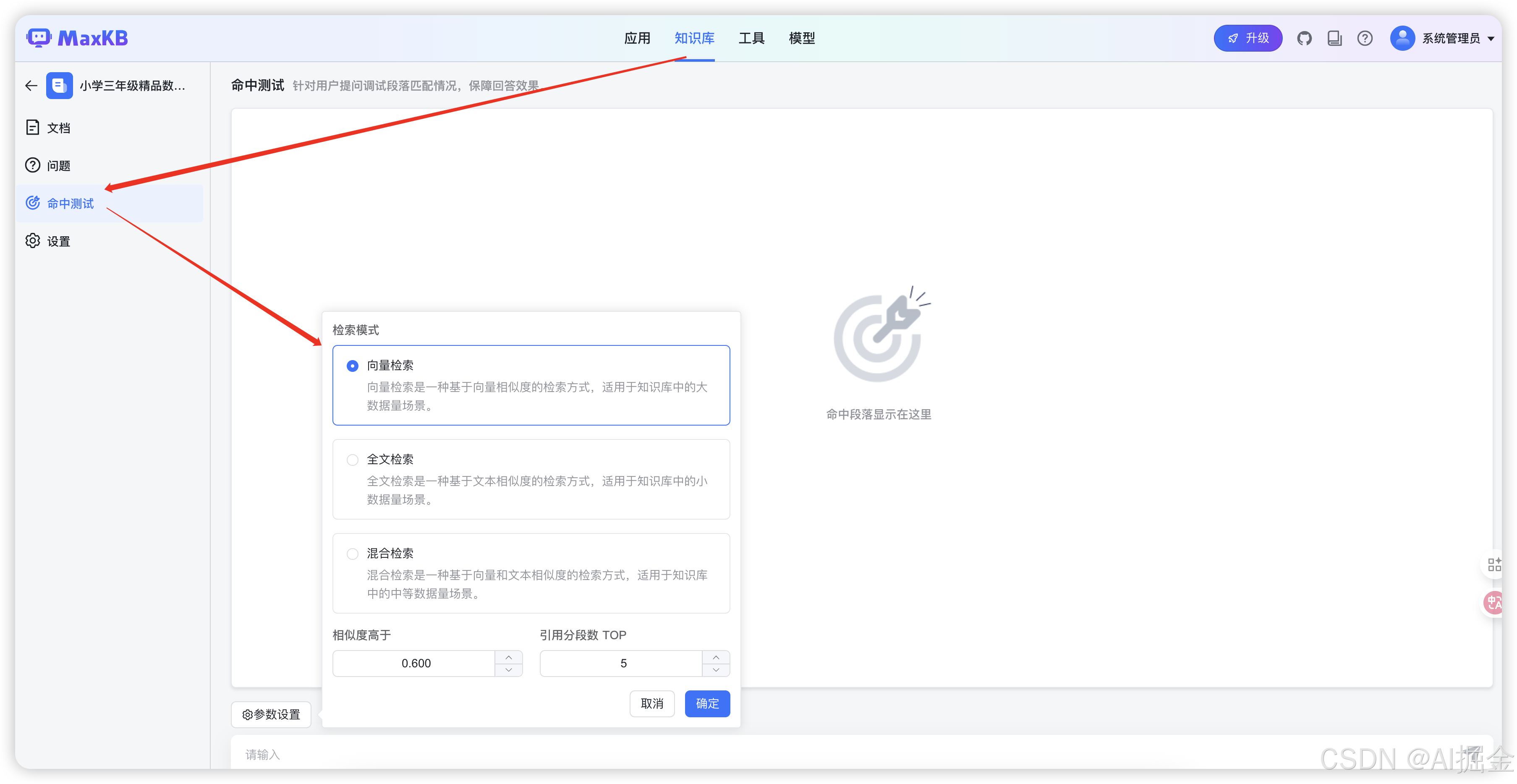
- 向量搜索:将 query 向量化后做匹配
- 全文搜索:是用的传统的 ElasticSearch 数据库,也就是说文档切片后一边会向量化进入到向量数据库,而另一边则存入ElasticSearch,供全文检索使用。这个检索过程类似百度搜索,就是返回的包含关键词最多的文档片段。
- 混合检索:则是既进行向量搜索,又进行全文搜索,之后对两边搜索到的结果,用算法做一个重新排名,最终得到一个相似片段的排名。
- 相似度高于:默认是 0.6,两个向量越相似,分值就越高。设置相似度阈值,是为了过滤掉我们认为相似度不高的检索结果。
我们把一个题目稍微换换说法,做一下命中测试,比较一下几种检索方式返回的效果。
原来题目:如果一个苹果重200克,三个苹果重多少克?
修改后题目:如果一个苹果重800克,5个苹果重多少克?
向量搜索,结果: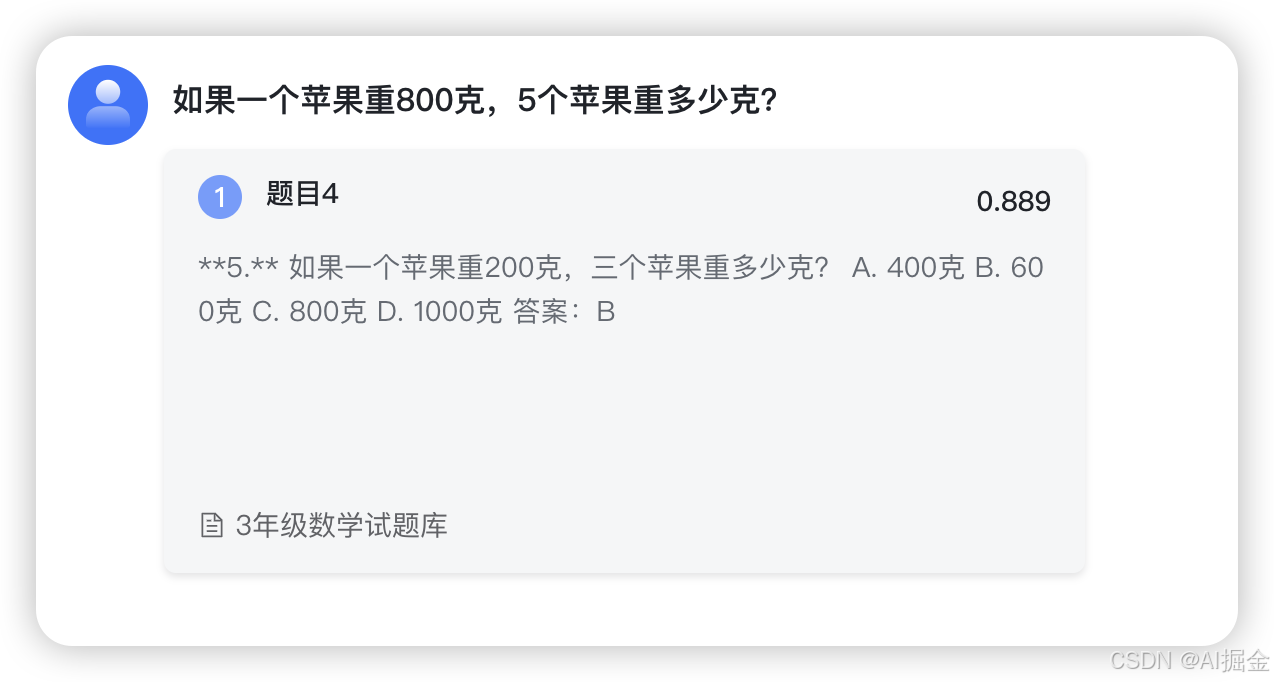
全文搜索,结果
混合检索,结果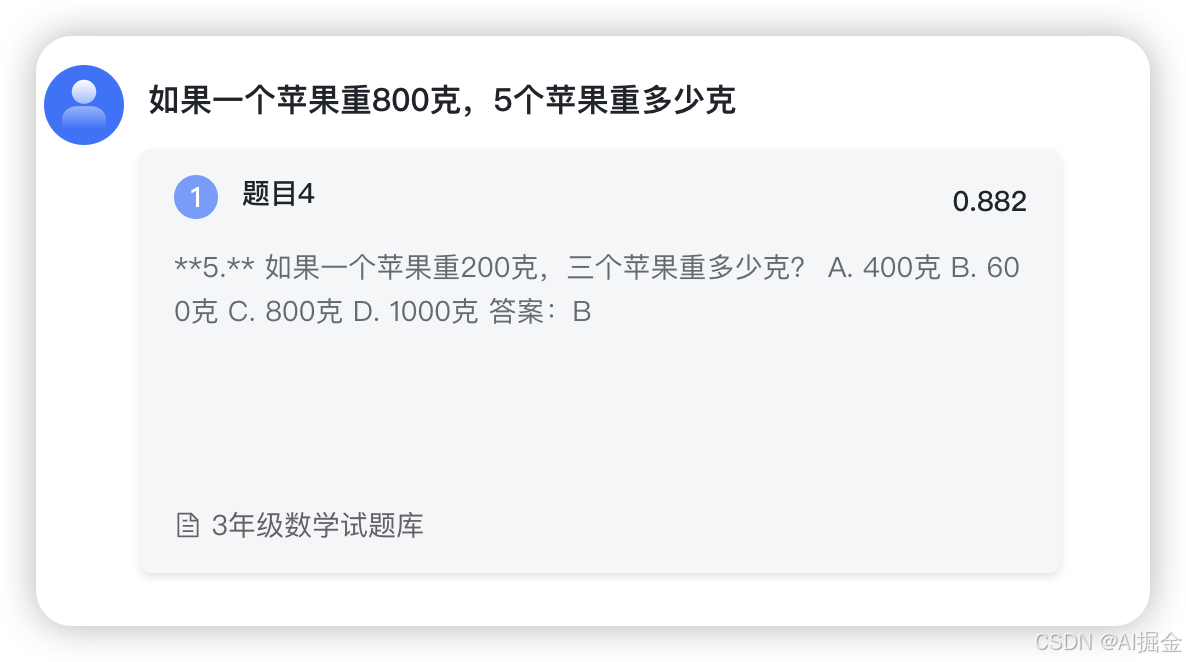
Step8: 创建知识库助手应用
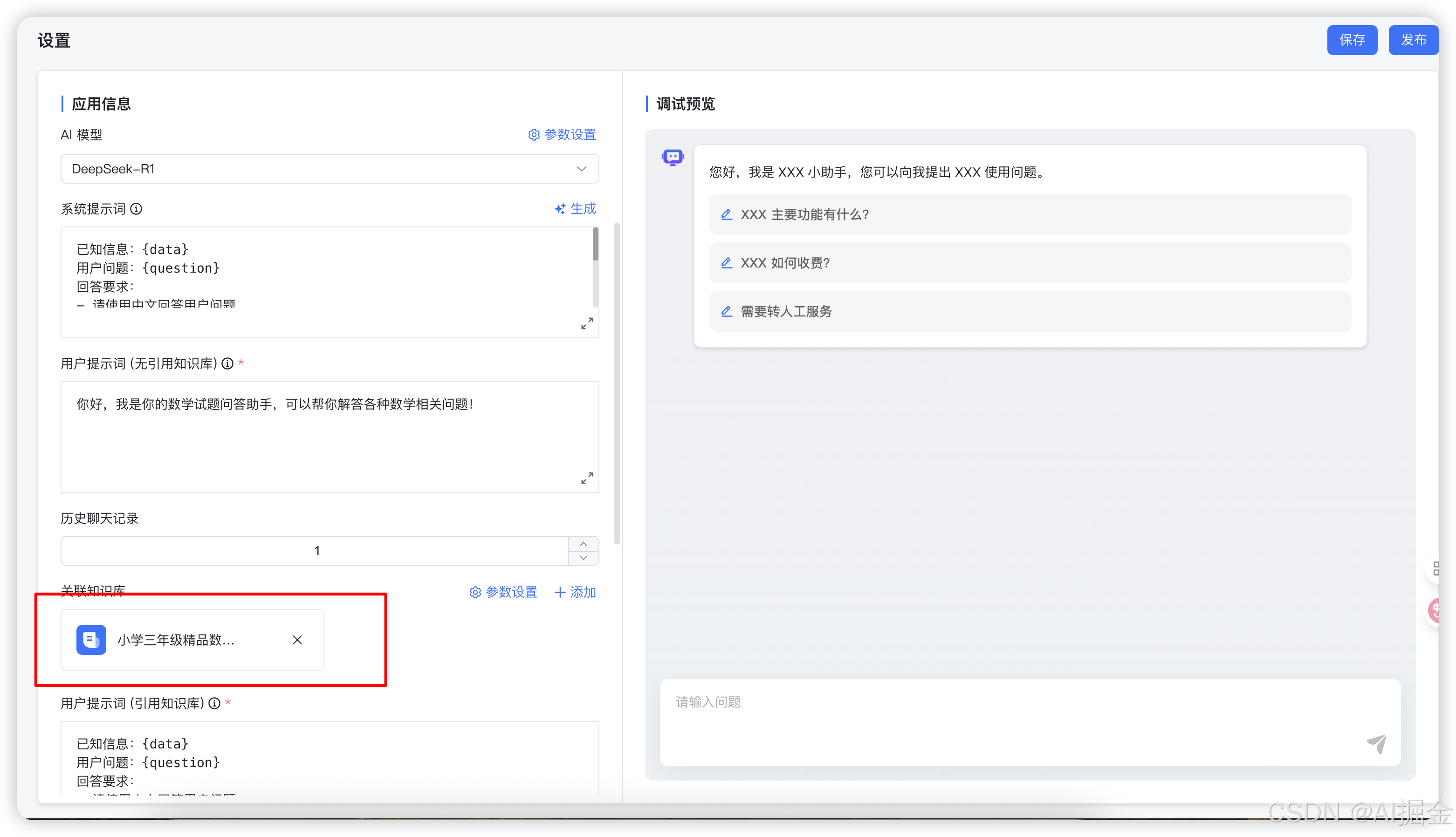
Step8: 关联知识库
Step8: 设置检索类型
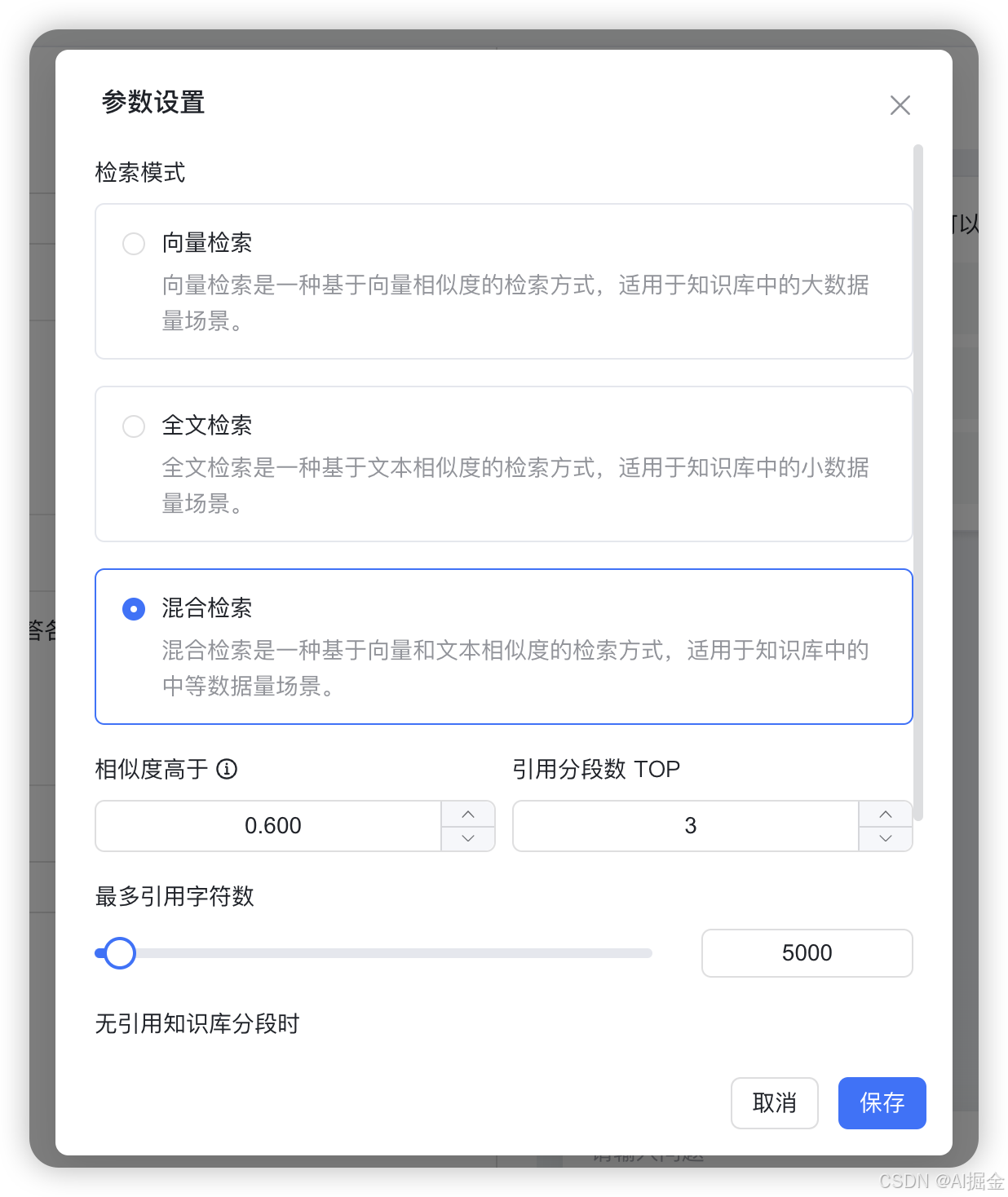
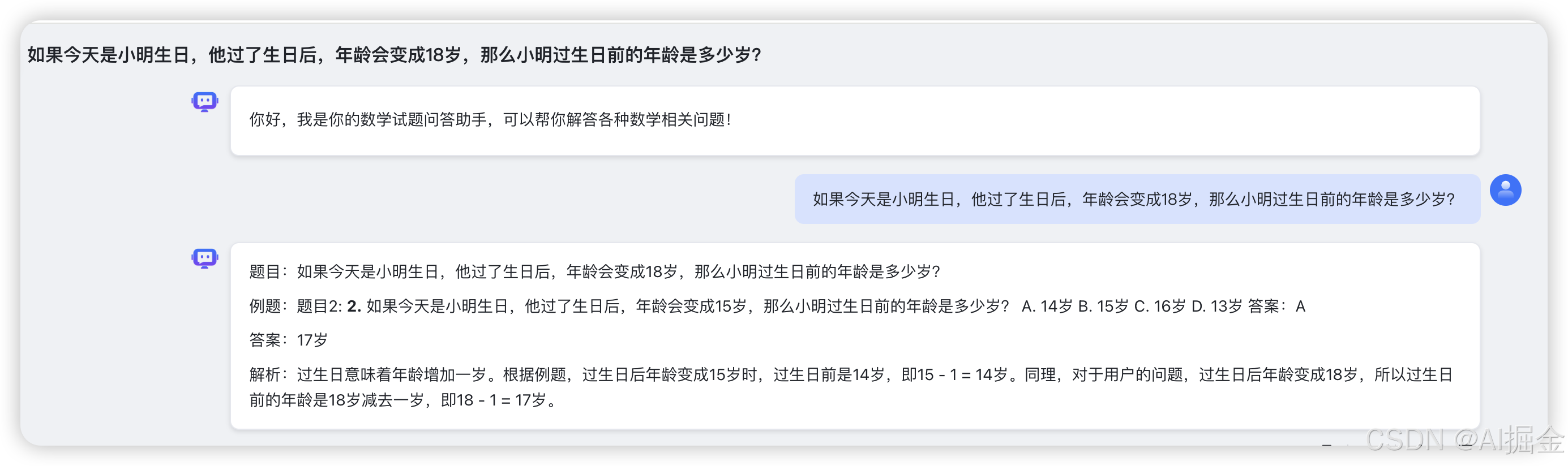
Step9: 效果验证
4. 总结
1)验证后发现,召回的结果,准确率确实高了很多,而且通过大模型推理,给出了解题的详细步骤
2)本打算只回答,知识库有的内容,但大模型会,回答其它的,比如这个问题(没有关联到知识库的知识点),下次我们再来解决这个问题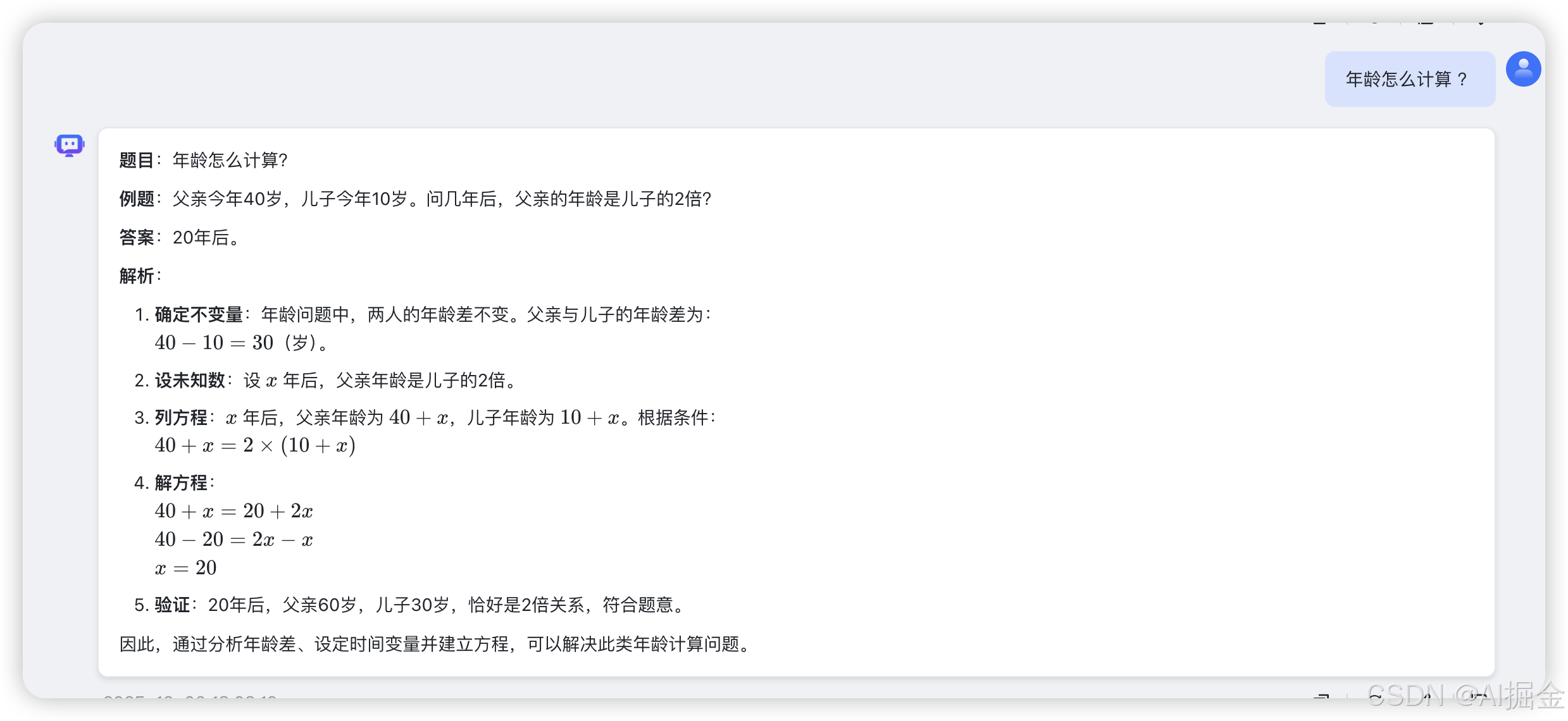 :
:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)