MaaS 平台 AI Agent 构建技术指南
现在来搭建一下本地开发环境,安装 Python 3.9+(推荐 3.10 版本),配置 pip 镜像源(阿里云 / 清华源)),通过邮箱 / 手机号注册账号,如果是企业用户的话,需完成实名认证(上传营业执照 + 法人身份证明),个人用户直接跳过。然后进入【API KEY 管理】页面,点击 “创建 API KEY”,命名为 “AI-Agent - 专属密钥”1.Token 精细化配置:按场景设置合
首先,先进入蓝耘官网(https://maas.lanyun.net),通过邮箱 / 手机号注册账号,如果是企业用户的话,需完成实名认证(上传营业执照 + 法人身份证明),个人用户直接跳过
- 登录账号,进入【MaaS 平台】首页,确认账号状态为 “已激活
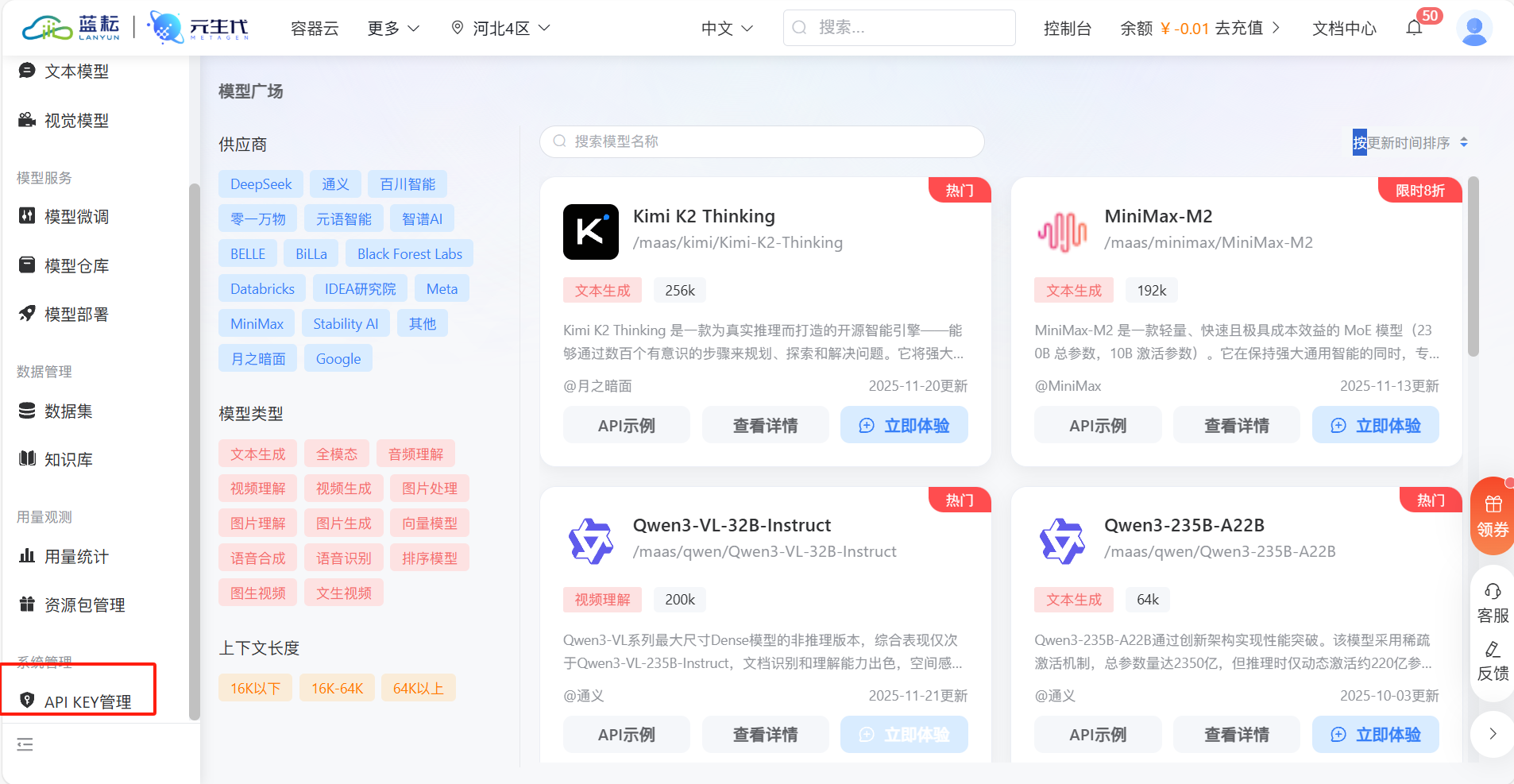
然后进入【API KEY 管理】页面,点击 “创建 API KEY”,命名为 “AI-Agent - 专属密钥”
复制生成的sk-xxx格式密钥(仅显示一次),立即本地存储
现在来搭建一下本地开发环境,安装 Python 3.9+(推荐 3.10 版本),配置 pip 镜像源(阿里云 / 清华源)
pip install requests==2.31.0 asyncio==3.4.3 python-dotenv==1.0.0
# 可视化需求额外执行:pip install tkinter==8.6 PyQt6==6.5.2在项目根目录创建.env文件,粘贴刚刚复制的密钥:
LANYUN_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxx
DEFAULT_MODEL=deepseek-r1
BASE_URL=https://maas-api.lanyun.net
MAX_TOKENS=2048
TEMPERATURE=0.7使用时应该明确 Agent 核心场景,主要分四个:
| 应用场景 | 推荐模型 | 模型 ID(API 调用用) | 关键参数配置 |
| 客服对话 / 文本问答 | DeepSeek-R1 | deepseek-r1 | temperature=0.3-0.5,提升精准度 |
| 长文档分析(≥8k 字) | DeepSeek-V3.2-Exp | deepseek-v3.2-exp | max_tokens=8192,启用稀疏注意力 |
| 多模态生成(图文) | QwQ-32B | qwq-32b | temperature=0.7-0.9,增加创意性 |
| 代码生成 / 数据分析 | Kimi K2 Instruct | /maas/kimi/Kimi-K2-Instruct | max_tokens=4096,top_p=0.9 |
接着进行接口连通性测试,咱们使用 Postman 或 Python 脚本验证 API 可用性:
import requests
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("LANYUN_API_KEY")
base_url = os.getenv("LANYUN_API_BASE")
def test_model_connection():
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"model": os.getenv("DEFAULT_MODEL"),
"messages": [{"role": "user", "content": "验证连接:请返回'连接成功'"}],
"max_tokens": 100,
"temperature": 0.1
}
response = requests.post(
f"{base_url}/chat/completions",
headers=headers,
json=payload,
timeout=10
)
if response.status_code == 200:
print("接口验证成功:", response.json()["choices"][0]["message"]["content"])
else:
print("验证失败:", response.status_code, response.text)
if __name__ == "__main__":
test_model_connection()运行脚本后,若返回 “连接成功” 则说明环境配置无误;若提示权限错误,需检查模型 ID 是否与密钥权限匹配。
在基础 Agent 开发上给出一个文本对话例子:
class LanyunTextAgent:
def __init__(self):
self.api_key = os.getenv("LANYUN_API_KEY")
self.base_url = os.getenv("LANYUN_API_BASE")
self.default_model = os.getenv("DEFAULT_MODEL")
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# 上下文存储(生产环境建议用Redis)
self.context = {}
def get_response(self, user_id, user_query, system_prompt=None):
"""
获取Agent响应,支持上下文管理
:param user_id: 用户唯一标识(用于区分会话)
:param user_query: 用户查询
:param system_prompt: 系统提示词(定义Agent角色)
:return: 模型响应文本
"""
# 初始化/更新上下文
if user_id not in self.context:
self.context[user_id] = []
if system_prompt:
self.context[user_id].append({"role": "system", "content": system_prompt})
self.context[user_id].append({"role": "user", "content": user_query})
# 调用蓝耘MaaS API
payload = {
"model": self.default_model,
"messages": self.context[user_id],
"max_tokens": int(os.getenv("MAX_TOKENS")),
"temperature": float(os.getenv("TEMPERATURE"))
}
response = requests.post(
f"{self.base_url}/chat/completions",
headers=self.headers,
json=payload,
timeout=15
)
response.raise_for_status() # 抛出HTTP错误
ai_response = response.json()["choices"][0]["message"]["content"]
# 更新上下文(保留最近10轮对话,避免Token溢出)
self.context[user_id].append({"role": "assistant", "content": ai_response})
if len(self.context[user_id]) > 20: # 系统+用户+助手各10轮
self.context[user_id] = self.context[user_id][-20:]
return ai_response
# 调用示例
if __name__ == "__main__":
agent = LanyunTextAgent()
# 定义Agent角色(客服助手)
system_prompt = "你是企业客服助手,回答简洁专业,仅回复与产品相关的问题"
# 多轮对话
print(agent.get_response("user_001", "你们的产品支持哪些模型?", system_prompt))
print(agent.get_response("user_001", "QwQ-32B模型适合什么场景?")) # 自动关联上下文本地知识库集成(企业级必备)
def load_knowledge_base(file_path):
"""加载本地知识库(如产品手册、行业文档)"""
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
def enhance_prompt(user_query, knowledge_base):
"""构造知识库增强提示词,避免模型幻觉"""
return f"""基于以下知识库内容回答用户问题,仅使用知识库信息,不编造内容:
{knowledge_base}
用户问题:{user_query}
回答要求:简洁明了,分点说明(如需)"""
# 集成到Agent
agent = LanyunTextAgent()
knowledge = load_knowledge_base("product_manual.txt") # 本地产品手册
enhanced_query = enhance_prompt("产品的售后服务政策是什么?", knowledge)
print(agent.get_response("user_001", enhanced_query, "你是企业客服助手,基于提供的知识库回答问题"))多模型协同调用(多模态场景)
def multi_model_agent(user_query, user_id):
"""根据用户需求自动切换模型"""
text_agent = LanyunTextAgent()
# 文本需求识别
if "生成图片" in user_query or "图像" in user_query:
# 调用QwQ-32B图像生成模型
image_prompt = text_agent.get_response(user_id, f"提取图像生成关键词:{user_query}", "仅返回关键词列表,不额外说明")
return call_image_model(image_prompt) # 图像生成API调用(参考蓝耘官方文档)
elif "分析文档" in user_query or len(user_query) > 2000:
# 长文本处理切换DeepSeek-V3.2-Exp
text_agent.default_model = "deepseek-v3.2-exp"
return text_agent.get_response(user_id, user_query, "详细分析长文本内容,提炼核心观点")
else:
return text_agent.get_response(user_id, user_query)集成 NextChat(搭建专属聊天界面)
1.克隆 NextChat 源码:git clone https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web.git
2.进入项目目录,创建.env.local文件:(用pytjon转化)
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxx # 蓝耘API密钥
OPENAI_API_BASE_URL=https://maas-api.lanyun.net/v1 # 蓝耘API地址
DEFAULT_MODEL=deepseek-r1 # 默认模型
MODEL_LIST=["deepseek-r1","qwq-32b","/maas/kimi/Kimi-K2-Instruct"] # 支持的模型列表3.启动服务:npm run dev,访问http://localhost:3000即可使用自定义 Agent 界面
进阶优化:性能与成本双提升(3 大策略)
策略 1:性能优化(响应速度 + 并发能力)
- 模型量化与优化:调用 API 时添加优化参数,显存占用降低 55%,响应延迟提升 75%:
payload = {
"model": "deepseek-r1",
"messages": self.context[user_id],
"max_tokens": 2048,
"temperature": 0.7,
"quantization": "int8", # INT8量化
"graph_optimization": True # 图优化
}2.缓存策略:用 Redis 缓存高频查询结果,命中率可达 70% 以上:
import redis
r = redis.Redis(host=os.getenv("REDIS_HOST"), port=int(os.getenv("REDIS_PORT")), db=0)
def get_cached_response(user_query):
cache_key = f"agent_cache:{hash(user_query)}"
if r.exists(cache_key):
return r.get(cache_key).decode()
else:
response = agent.get_response("default_user", user_query)
r.setex(cache_key, int(os.getenv("CACHE_EXPIRE")), response)
return response3.并发控制:通过信号量限制并发数(推荐 8-12),避免 API 限流:
import asyncio
semaphore = asyncio.Semaphore(10) # 最大并发10
async def async_get_response(user_id, user_query):
async with semaphore:
# 异步调用逻辑(基于aiohttp)
pass策略 2:成本控制(Token 优化 + 计费模式)
1.Token 精细化配置:按场景设置合理的max_tokens,避免浪费:
短问答:512-1024 Token
文档总结:1024-2048 Token
创意生成:2048-4096 Token
2.批处理调用:将多个相似请求合并为批量调用,减少 API 请求次数:
def batch_process(prompts):
"""批量处理多个查询"""
payload = {
"model": "deepseek-r1",
"batch": [{"messages": [{"role": "user", "content": p}]} for p in prompts],
"max_tokens": 1024
}
response = requests.post(f"{base_url}/batch/chat/completions", headers=headers, json=payload)
return [item["choices"][0]["message"]["content"] for item in response.json()["data"]]策略 3:稳定性保障(容错 + 监控)
1.异常处理机制:
def get_response_with_retry(user_id, user_query, retries=3):
for i in range(retries):
try:
return agent.get_response(user_id, user_query)
except requests.exceptions.Timeout:
if i == retries - 1:
return "请求超时,请稍后再试"
await asyncio.sleep(1 + i) # 指数退避重试
except requests.exceptions.RequestException as e:
return f"服务异常:{str(e)}"- 日志与监控:记录 API 调用日志(请求参数、响应状态、Token 消耗),推荐使用 ELK 栈收集分析;同时启用蓝耘平台的监控告警,设置:
- Token 余额告警:剩余≤10 万时触发邮件通知
- 调用失败率告警:失败率≥5% 时实时推送钉钉 / 企业微信

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)