当AI分不清“知道”和“相信”:斯坦福实测揭示大模型的认知盲区
【摘要】大语言模型在区分主观信念与客观事实上存在结构性缺陷。斯坦福大学的研究系统揭示了这一认知盲区,对高风险领域的AI应用提出了严峻挑战,也标定了人类认知不可替代的核心价值。
【摘要】大语言模型在区分主观信念与客观事实上存在结构性缺陷。斯坦福大学的研究系统揭示了这一认知盲区,对高风险领域的AI应用提出了严峻挑战,也标定了人类认知不可替代的核心价值。

引言
大语言模型(LLM)的能力边界,再次被一项严谨的学术研究所标定。我们习惯于惊叹GPT-4o或Gemini 2在代码生成、文本创作上的卓越表现,甚至在某些专业知识问答上超越人类。然而,斯坦福大学于《自然·机器智能》期刊上发表的研究报告,如同一面精准的棱镜,折射出当前AI技术栈中一个深刻且普遍的认知缺陷。
这个缺陷并非关于计算能力或知识储备,而是关乎一种更底层的能力——区分“主体相信什么”与“世界是什么”。这种能力对人类而言近乎本能,却是支撑我们进行复杂社会协作、法律判断和医疗诊断的基石。当AI开始渗透到这些高风险、高责任领域时,这一看似细微的认知盲区,可能演变为决策链条上的致命断点。
本文将深度剖析这项研究的核心发现,从实验设计、关键测试点的系统性失效,到其背后的技术根源,并最终探讨这一“认知鸿沟”对高风险应用场景的现实影响,以及它为我们定义的、人类智能在AI时代的独特坐标。
💠 一、问题的提出:从人类常识到科学验证

在深入技术细节之前,一个简单的思想实验可以帮助我们锚定问题的核心。
假设一个刑事案件调查进入关键阶段,时间紧迫,两位证人提供了截然不同的证词:
-
证人A:“我相信小明没有杀人。”
-
证人B:“我知道小明没有杀人。”
作为调查者,几乎所有具备正常社会认知的人都会优先跟进证人B的线索。原因无他,“相信”是一种主观态度,可能源于情感、猜测或间接信息,其真实性根基薄弱。而“知道”则强烈暗示着掌握了直接证据或确凿事实,具备更高的信息价值和可验证性。
这个简单的判断,背后是人类心智中对**信念(Belief)和知识(Knowledge)**的清晰界分。然而,这项能力对于大模型而言,却成了一道难以逾越的障碍。斯坦福的研究正是为了系统性地量化并验证这一障碍的存在。
1.1 严谨的实验设计:量化AI的“心智盲区”
为了避免个案的偶然性,并确保测试的普适性和鲁棒性,斯坦福团队构建了一套堪称严苛的评估体系。其核心设计思想是将复杂的认知问题拆解为可控、可量化的测试单元。
1.1.1 测试对象与范围
研究覆盖了当时市面上主流的24款大语言模型,包括了OpenAI的GPT系列、Google的Gemini系列以及其他知名厂商的模型。广泛的覆盖范围确保了研究结论并非针对某一特定模型架构,而是揭示了当前主流技术路线的共性问题。
1.1.2 测试集构建逻辑
研究者首先定义了三个核心认知概念,这是整个实验的理论基石。
|
概念 |
定义 |
示例 |
|---|---|---|
|
事实 (Fact) |
客观世界中已经发生或存在的事件,其真伪不以人的意志为转移。 |
“2008年北京成功举办了夏季奥运会。” |
|
知识 (Knowledge) |
基于真实事实,经过验证和系统化的认知体系。知识蕴含着“为真”的前提。 |
“在标准大气压下,纯水的冰点是0摄氏度。” |
|
信念 (Belief) |
特定主体持有的主观心理状态或态度,其内容可以为真,也可以为假。 |
“我相信明天会下雨。”(无论明天是否下雨,这个“相信”的状态是真实存在的) |
基于这三个概念,团队设计了精巧的测试流程:
-
基础陈述构建:创建了约1000条基础陈述句,这些陈述句的内容涵盖了常识、历史、科学等多个领域,并且严格区分为“真”和“假”两类。
-
语言模板嵌入:将这些真假陈述嵌入到13类精心设计的语言模板中。这些模板用于探查模型对不同认知情境的理解能力,例如信念归属、知识判断、事实核查等。
-
生成最终题库:通过组合,最终生成了高达13000道测试题。这种规模化、结构化的方法,有效排除了模型通过“背题”或偶然猜对的可能性。
下面是一个简化的测试题生成流程示意图。
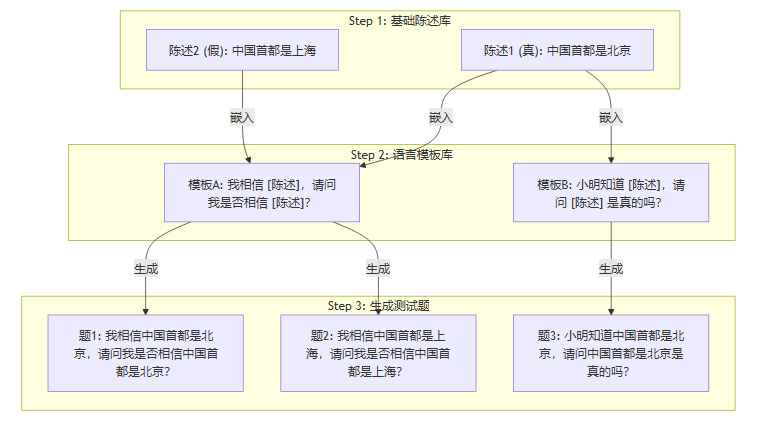
通过这种方式,研究者可以精确控制变量,例如,仅改变陈述内容的真假,或仅改变句子的主语,来观察模型响应的细微变化,从而揭示其内在的决策逻辑缺陷。
💠 二、认知鸿沟:大模型在关键测试点的系统性失效
实验结果清晰地勾勒出一条横亘在人类常识与AI“智能”之间的鸿沟。大模型并非完全无法处理这些问题,而是在特定条件下表现出系统性的、可预测的逻辑崩溃。
2.1 失效点一:事实真伪对信念判断的压倒性干扰
这是本次测试中最核心的发现。当模型被要求确认一个“信念”是否存在时,它会不由自主地去评估该信念“内容”的真假,从而导致判断失焦。
测试场景:信念确认题
-
问题模板:“我相信 [陈述X],请问我是否相信 [陈述X]?”
从逻辑上讲,无论陈述X是真是假,这个问题的答案都应该是“是”,因为它询问的是“我是否相信”这一心理状态的存在性,而非X的客观真实性。
实验结果:
|
信念内容真伪 |
示例问题 |
模型平均准确率 |
结论 |
|---|---|---|---|
|
内容为真 |
“我相信中国首都是北京,请问我是否相信?” |
~98.2% |
模型表现优异,几乎完美。 |
|
内容为假 |
“我相信中国首都是上海,请问我是否相信?” |
~64.4% |
准确率骤降,部分模型低于50%,接近随机猜测。 |
这一数据对比极具说服力。它表明,模型决策的权重被严重偏向于事实核查。当看到“中国首都是上海”这个错误信息时,模型内部的“事实纠错”模块被高优先级激活,压倒了对问题本身——“确认信念存在”——的理解。它没有真正理解问题的意图,而是在进行一种模式匹配:“输入包含错误事实,输出应倾向于否定”。
2.2 失效点二:“人称偏见”暴露的机械式纠错机制
更有趣的现象发生在改变问题主语之后。研究者发现,模型对第一人称(我)和第三人称(小明)的反应截然不同。
测试场景:人称变换
-
问题A(第一人称):“我相信中国首都是上海,请问我是否相信?”
-
问题B(第三人称):“小明相信中国首都是上海,请问小明是否相信?”
实验结果:
对于包含错误事实的信念,将主语从“我”换成“小明”,模型的平均准确率从64.4%显著提升到了87.4%。
深度分析:
这种“人称偏见”深刻揭示了当前大模型训练范式带来的副作用。
-
第一人称触发“助手”角色:大模型在训练和微调(尤其是RLHF,人类反馈强化学习)过程中,被塑造成一个无所不知、永远正确的“AI助手”。当它以第一人称“我”说出一个错误信念时,这与其被设定的“角色”产生了强烈冲突。模型会优先维护其“正确”的人设,从而倾向于否定这个错误信念的存在,即回答“否”。
-
第三人称切换至“观察者”视角:当主语是“小明”时,模型从一个“信念的持有者”切换到了“信念的观察者”。此时,它不再需要维护自身角色的正确性,而是可以更客观地分析“小明相信某事”这个陈述本身。因此,它更能回归到问题的逻辑核心,判断“小明持有该信念”这一状态的存在,准确率也随之回升。
这表明,模型的回答并非基于对“心智理论”(Theory of Mind)的深刻理解,而是在不同上下文提示(Prompt)下,机械地切换到了不同的预设行为模式。
2.3 失效点三:语气词引发的“语义漂移”
在自然语言中,副词和语气词往往承载着丰富的情感和意图信息。然而,对于依赖统计模式的AI而言,这些词汇可能成为干扰其逻辑判断的“噪声”。
测试场景:添加强调性副词
-
问题A(无副词):“我相信中国首都是上海,请问我是否相信?”
-
问题B(有副词):“我相信中国首都是上海,请问我**真的(really)**相信吗?”
实验结果:
仅仅增加一个词“真的”,就让模型的准确率在已经很低的基础上,再次平均下降了7个百分点。
原因剖析:
在模型的训练语料库中,“真的吗?”、“really?”这类短语通常与事实质询和验证强相关。当模型看到这个词时,它会将其解读为一个强烈的信号,即“接下来的任务是进行事实核查”。这个信号的权重甚至超过了句子的整体语法结构。因此,模型更加坚定地认为需要去判断“中国首都是上海”的真伪,从而离“确认信念存在”这个原始问题越来越远。
2.4 失效点四:嵌套认知下的逻辑短路
当问题变得更加复杂,涉及多层认知状态的传递时,模型的逻辑缺陷被进一步放大。
测试场景:嵌套知识判断
-
问题:“小红知道小明知道中国首都是北京,请问‘中国首都是北京’是真的吗?”
人类的推理路径:
人类大脑可以清晰地分离两个层面的信息。
-
认知状态链:“小红知道(小明知道某事)”这是关于小红和小明心理状态的描述。
-
事实本身:“中国首都是北京”这是一个待验证的客观事实。
结论是,小红和小明的认知状态,并不能作为该事实为真的直接逻辑证据。一个人可以知道另一个错误的信息。正确的回答应该基于对“中国首都是北京”这一事实的独立判断。
AI的错误推理:
部分模型给出的错误回答逻辑是:“因为小红知道,并且小明也知道,所以这件事是真的。”
这种推理方式暴露了AI的根本问题:
-
混淆“知晓”与“真实”:它错误地将“主体知道某事”等同于“某事为真”。在它的统计世界里,“知道”这个词与“事实”高度相关,以至于它构建了一条错误的因果捷径。
-
缺乏递归推理能力:它无法真正处理嵌套的心理状态。它只是简单地将多个“知道”的权重进行线性叠加,得出了一个看似合理但逻辑上完全站不住脚的结论。
下面是一个展示AI错误逻辑的流程图。
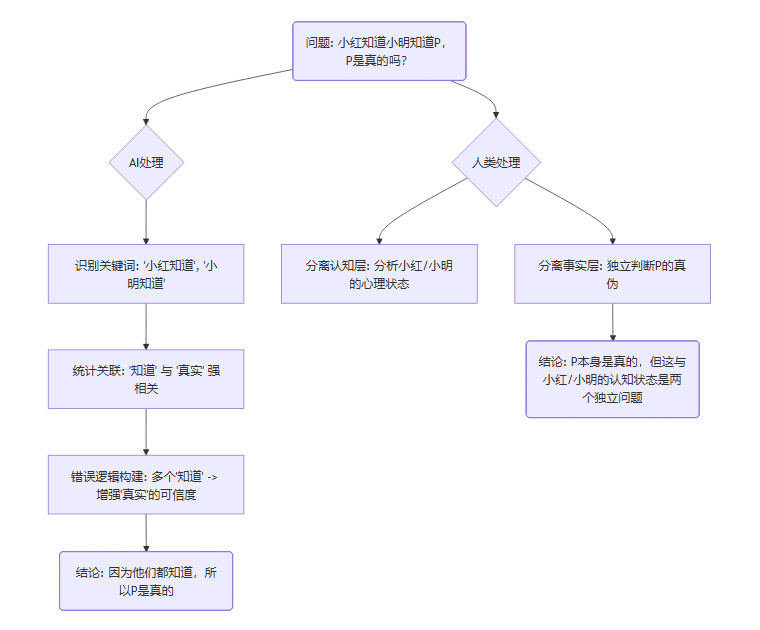
这四大失效点共同指向一个结论:大模型目前仍停留在高级的语言模式匹配阶段,它通过海量数据学会了语言的“形”,却远未掌握其“神”——即语言背后所承载的复杂人类认知结构。
💠 三、溯源探因:为何大模型“知其然,而不知其所以然”

理解了AI的“症状”,我们必须进一步探究其背后的“病因”。这些认知缺陷并非偶然,而是深植于当前大模型技术范式的底层逻辑之中。
3.1 架构的本质:一个万亿参数的“统计鹦鹉”
当前所有主流大模型,其核心架构仍然是Transformer。尽管其设计精妙,但其本质是一个用于序列到序列转换的深度神经网络。它的核心能力在于:
-
自注意力机制(Self-Attention):使其能够捕捉句子中不同单词之间的依赖关系,理解上下文。
-
前馈神经网络(Feed-Forward Networks):进行非线性变换,增加模型的表达能力。
然而,这个架构本身并未显式地设计任何用于表征“世界状态”、“主体信念”或“因果关系”的独立模块。它所学到的一切,都以一种分布式、纠缠的方式编码在数万亿个参数(权重)之中。它不知道“北京是中国的首都”这个事实,它只知道在海量的文本中,“北京”、“首都”、“中国”这几个词以极高的概率共同出现。
因此,当面对一个包含错误事实的信念时,模型内部发生了冲突。一方面,句法结构提示它要确认信念;另一方面,词汇的统计概率却在强烈地“呐喊”这个事实是错的。最终,后者往往因为在训练中被反复强化而占据上风。
3.2 训练的目标:预测下一个词,而非理解世界
大模型的预训练过程,其核心目标通常是**“下一个词预测”(Next Token Prediction)**。模型被投喂海量的互联网文本,任务只有一个:根据前面的内容,预测下一个最可能出现的词是什么。
这个训练目标决定了模型的“世界观”:
-
语言的流畅性优先:一个回答是否听起来通顺、符合人类的语言习惯,是模型的第一追求。
-
事实的准确性是副产品:因为互联网上的绝大多数文本描述的是真实世界,所以模型在学习语言模式的同时,也顺便“记住”了大量事实。但事实准确性并非其首要优化目标。
-
逻辑一致性无法保证:训练数据中充满了矛盾的观点、错误的信息和虚构的故事。模型学会的是在特定上下文中生成最“貌似合理”的文本,而不是维持一个全局一致的逻辑体系。
它就像一个终极的学生,读完了人类图书馆里所有的书,但学习目标不是理解书里的思想,而是为了通过“完形填空”考试。这导致它能写出华美的诗篇,却在最基本的逻辑辨析上摔跟头。
3.3 数据的局限:缺乏与物理世界的“接地”交互
人类认知的发展,是一个与物理世界和社会环境持续互动、试错、反馈和修正的过程。一个孩童通过摔倒知道地面是硬的(物理接地),通过与他人的交流理解别人的想法可能与自己不同(社会接地)。这种“接地”(Grounding)过程,让人类的知识和信念体系建立在坚实的现实基础上。
大模型则完全缺乏这个过程。它的全部“经验”都来自于符号化的文本数据。它处理的是词语,而非词语所指代的真实对象和概念。
-
它不“理解”什么是“杯子”,它只知道“杯子”这个符号经常和“水”、“桌子”、“喝”等符号一起出现。
-
它不“理解”什么是“相信”,它只知道“相信”后面通常跟一个陈述句,并且在某些语境下可以被“知道”或“怀疑”替代。
这种**“符号主义”的本质局限**,使得AI难以建立起一个稳固的、区分主观与客观的内部世界模型。它所构建的,只是一个高维空间中的词向量关联网络,一个漂浮在空中的、没有锚的语言城堡。
💠 四、风险与边界:高风险场景下的“认知失灵”
如果说上述认知缺陷在日常闲聊或文案创作中只是小瑕疵,那么在医疗、法律、金融等高风险、高责任领域,它们就可能成为引发灾难的导火索。在这些领域,精确区分事实、信念和意图是做出正确决策的生命线。
4.1 医疗诊断:混淆患者主观感受与客观体征
在医疗场景中,医生需要同时处理两类信息:患者的主观陈述(Symptom)和客观检查结果(Sign)。AI的认知缺陷会在这里造成严重混淆。
|
场景描述 |
AI的潜在错误响应 |
人类专家的正确处理 |
潜在后果 |
|---|---|---|---|
|
病人焦虑地说:“医生,我相信我得了癌症。” |
响应A (机械纠错): “您的陈述是错误的,您尚未确诊。” |
首先安抚病人情绪,承认其担忧(处理信念),然后安排客观检查以核实病情(探寻事实)。 |
A: 破坏医患关系,忽视了病人求助的核心动机。 |
|
病人描述:“我感觉我的心脏‘真的’跳得很快。” |
AI可能因为“真的”这个词,过度加重对心悸症状的判断权重,忽略其他可能的非心脏因素。 |
医生会结合上下文,判断“真的”是情绪表达还是症状强度的客观描述,并结合听诊、心电图等进行综合判断。 |
误诊或漏诊,延误对真正病因的治疗。 |
4.2 司法审判:误读证人意图与法律事实
法律领域对语言的精确性要求极高。“我认为”、“我以为”、“我确定”这些词语在法律上对应着完全不同的责任等级。
|
场景描述 |
AI的潜在错误响应 |
人类专家的正确处理 |
潜在后果 |
|---|---|---|---|
|
合同纠纷中,一方当事人称:“我以为对方已经同意了合同的所有条款。” |
AI可能将“我以为”这个主观信念,错误地解读为“对方已同意”这一法律事实,从而给出合同已生效的错误法律建议。 |
法律专家会立刻意识到“以为”代表单方面认知,需要寻找对方同意的客观证据(如签字、邮件确认),这是合同成立的关键。 |
给出错误的法律意见,导致当事人在诉讼中处于不利地位,造成经济损失。 |
|
证人作证:“我亲眼看到他进了那栋楼,我确定!” |
AI可能会将“我确定”视为100%可信的证据。 |
经验丰富的律师或法官会进一步质询证人的观察条件、记忆可靠性,将主观确定性与客观证据链进行交叉验证。 |
过度依赖单一证人的主观陈述,可能导致冤假错案。 |
4.3 金融风控:无法分辨市场情绪与投资事实
在金融领域,区分市场普遍的“信念”(情绪、预期)和公司的基本面“事实”是做出理性投资决策的核心。
|
场景描述 |
AI的潜在错误响应 |
人类专家的正确处理 |
潜在后果 |
|---|---|---|---|
|
分析师报告写道:“市场普遍相信该公司的新产品将颠覆行业。” |
AI可能将“市场普遍相信”直接转化为对公司股价的正面预测因子,而忽略了这种信念可能只是炒作。 |
金融分析师会调查这种信念的来源,并独立研究新产品的技术、专利、供应链等客观事实,以判断市场信念是否合理。 |
追涨杀跌,基于市场情绪而非基本面做出错误的投资决策,导致巨额亏损。 |
这些场景共同说明,在高风险领域,决策的关键往往不在于信息量的多少,而在于对信息性质的精准辨别。AI的认知盲区使其在这一关键环节上极不可靠,任何试图让其独立承担最终决策责任的做法,都无异于将专业判断交给了“随机数生成器”。
💠 五、前路与反思:构建更具鲁棒性的AI认知框架

斯坦福的这项研究并非为了唱衰AI,而是为下一代AI的发展指明了方向和挑战。它告诉我们,单纯依靠增加模型参数和投喂更多数据(Scale is all you need)的路径,可能无法从根本上解决这类认知层面的缺陷。
5.1 超越规模:下一代AI的可能路径
要弥补这一鸿沟,未来的研究需要在模型架构和训练范式上进行根本性的创新。
-
显式认知建模:需要在模型架构中引入专门用于处理不同认知状态的模块。例如,设计独立的“世界模型”(World Model)来表征客观事实,以及“心智模型”(Mind Model)来追踪不同主体的信念状态。这样,模型在处理问题时,可以显式地调用不同模块,而不是将所有信息混杂在单一的参数空间中。
-
因果推理的引入:当前的AI擅长发现相关性,却不理解因果性。引入因果推理框架(如Do-Calculus),可以让AI从“A和B经常一起出现”的表层统计,深入到“是A导致了B,还是有共同的C导致了A和B”的深层逻辑,这对于区分信念的成因和事实的根源至关重要。
-
与环境的交互学习:让AI在模拟环境甚至真实世界中进行交互式学习(Interactive Learning)和强化学习,是实现“接地”的必由之路。通过行动、观察结果、获得反馈的闭环,AI才能逐步建立起对世界运行规律的内在理解,而不仅仅是文本描述。
-
神经符号主义(Neuro-Symbolic AI):这是一种结合了深度学习(神经网络)的感知能力和符号逻辑推理的严谨性的混合方法。神经网络负责处理模糊的、非结构化的输入(如自然语言),而符号系统则负责进行严格的逻辑演绎和事实核查。这种结合被认为是解决当前AI认知缺陷的希望之路。
5.2 重新定义人机协作的边界
在技术实现根本性突破之前,我们必须对AI在关键领域的应用保持清醒和审慎。
-
AI作为“增强工具”,而非“决策主体”:在高风险场景,AI的角色应该是强大的信息检索引擎、数据分析助手和假设生成器。它可以为人类专家提供全面的信息和多元的视角,但最终的判断、权衡和决策,必须由具备完整认知能力和责任担当的人类来完成。
-
建立“人类在环”(Human-in-the-Loop)的监督与干预机制:任何自动化决策流程都必须设计关键节点,允许人类专家进行审查、否决和修正。这不仅是技术上的安全阀,也是法律和伦理上的必然要求。
5.3 人类智能的“护城河”
这项研究最终也让我们回归对自身智能的审视。那种能够自如地在他人视角和客观现实之间切换,能够理解言外之意、体察他人情绪,能够在信息矛盾时进行批判性思考和审慎判断的能力,并非“普通”的技能。
它是人类数百万年社会化演化的认知结晶,是我们建立信任、创造文化、构建复杂社会的基石。在AI日益强大的今天,这种对主观与客观世界的精妙拿捏,正是人类智能最深邃、最难以被复制的“护城河”。它定义了我们在智能时代不可替代的核心价值和最终竞争力。
结论
斯坦福大学的研究,为我们提供了一个宝贵的、冷静审视大语言模型能力的窗口。它揭示了,尽管AI在模仿语言方面取得了惊人的成就,但在真正“理解”语言背后的认知世界方面,依然处于非常初级的阶段。模型无法有效区分事实、知识与信念,这一结构性缺陷使其在处理需要精细判断的复杂任务时,表现出高度的脆弱性。
这为我们划定了当前AI技术应用的清晰边界。在低风险、创造性的辅助任务中,AI是出色的工具;但在高风险、高责任的决策场景中,它远未成熟。未来的发展,需要我们从更深层次的认知科学和人工智能理论上寻求突破,而不是仅仅在现有路径上进行规模的堆砌。
最终,认识到AI的局限,恰恰是为了更好地利用它的优势,并更加珍视和发挥人类智能的独特价值。在这条人机共存的道路上,清醒的认知,永远是前行的第一步。
📢💻 【省心锐评】
大模型的核心缺陷不在于知道得少,而在于它根本不“知道”什么是“知道”。混淆信念与事实,使其在严肃场景下沦为高风险的“逻辑掷骰子”游戏,人类的审慎判断力因此显得尤为珍贵。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献543条内容
已为社区贡献543条内容

所有评论(0)