一文深度解析递归语言模型(RLM):突破LLM上下文瓶颈的创新推理策略
大型语言模型(LLM)的卓越价值已成为行业共识,它们不仅是现代工业发展的核心支柱,更在各行各业的数字化转型中持续拓展应用边界,深刻改变着生产与服务模式。随着语言模型在架构设计与功能性能上的持续迭代升级,不少人或许会认为其发展已趋近极致。然而,技术创新的脚步从未停歇——近期,名为递归语言模型(RLM)的新兴技术异军突起,成功占据AI领域的核心焦点,为语言模型的发展开辟了全新赛道。RLM究竟是什么?它
大型语言模型(LLM)的卓越价值已成为行业共识,它们不仅是现代工业发展的核心支柱,更在各行各业的数字化转型中持续拓展应用边界,深刻改变着生产与服务模式。
随着语言模型在架构设计与功能性能上的持续迭代升级,不少人或许会认为其发展已趋近极致。然而,技术创新的脚步从未停歇——近期,名为递归语言模型(RLM)的新兴技术异军突起,成功占据AI领域的核心焦点,为语言模型的发展开辟了全新赛道。
RLM究竟是什么?它与传统LLM存在怎样的关联?又将如何推动人工智能技术的前沿突破?本文将以深入浅出的逻辑架构、通俗易懂的阐释方式,全面剖析这项创新技术的核心原理与应用价值。在此之前,我们首先聚焦当前LLM普遍面临的关键技术瓶颈。
LLM的根本性技术局限
大型语言模型存在一个与生俱来的架构限制——“词元窗口”(Token Window)。这一限制由Transformer的位置嵌入机制与内存容量共同决定,指模型在单次前向传播过程中能够有效读取的最大词元数量。若输入文本的词元总数超出该限制,模型将无法完成处理,类似试图将5GB的文件加载至仅500MB内存的程序中,必然引发内存溢出问题。以下为当前主流模型的最大词元窗口配置:
|
模型 |
最大词元窗口 |
|
Google Gemini(最新版) |
1,000,000 |
|
OpenAI GPT-5(最新版) |
400,000 |
|
Anthropic Claude(最新版) |
200,000 |
通常而言,词元窗口的数值越大,模型理论上的处理能力越强,但事实果真如此吗?
上下文腐烂:词元窗口内的隐形性能损耗
更深层的问题在于,即便提示文本完全适配词元窗口的容量限制,随着输入文本长度的增加,模型性能仍会悄然下滑。这种现象的核心成因在于:模型的注意力机制会逐渐分散,早期输入的关键信息影响力持续衰减,文本中远距离段落间的逻辑关联难以被有效捕捉——这一技术痛点被定义为“上下文腐烂”(context rot)。
因此,即便部分模型宣称支持百万级词元输入,其实际无法对全部信息进行可靠推理。在实际应用场景中,模型性能往往在未达到词元窗口上限时便已出现显著崩溃。
上下文窗口:有效处理能力的真实边界
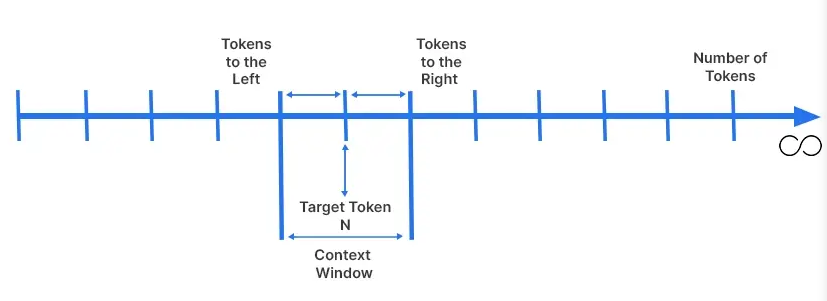
【上下文窗口示例】
上下文窗口指模型在性能崩溃前能够稳定利用的有效信息量,其数值并非固定不变,而是会根据提示文本的复杂程度与数据类型动态调整。LLM的有效上下文窗口远小于其标称的词元窗口,且与确定性的词元窗口不同,上下文窗口的实际范围完全依赖于任务场景的复杂程度。这一结论已通过实证得到验证:具备大词元窗口的LLM在推理类任务中表现欠佳,核心原因便是此类任务需要模型同时保留并处理几乎所有输入信息。
长上下文窗口与大词元窗口的需求始终存在,但因文本长度引发的上下文丢失问题,长期以来被视为LLM难以逾越的技术障碍——至少在RLM出现之前是如此。
递归语言模型(RLM):破解瓶颈的创新方案
尽管名称中包含“模型”二字,RLM并非如LLM、VLM、SLM那般的新型模型类别,本质上是一种专为解决长提示文本上下文腐烂问题设计的推理策略。其核心逻辑在于将长提示文本视为外部环境的组成部分,允许LLM通过编程方式对提示片段进行检查、分解,并递归调用自身完成处理。
这一机制使得模型的有效上下文窗口实现数倍拓展,其核心工作流程如下:
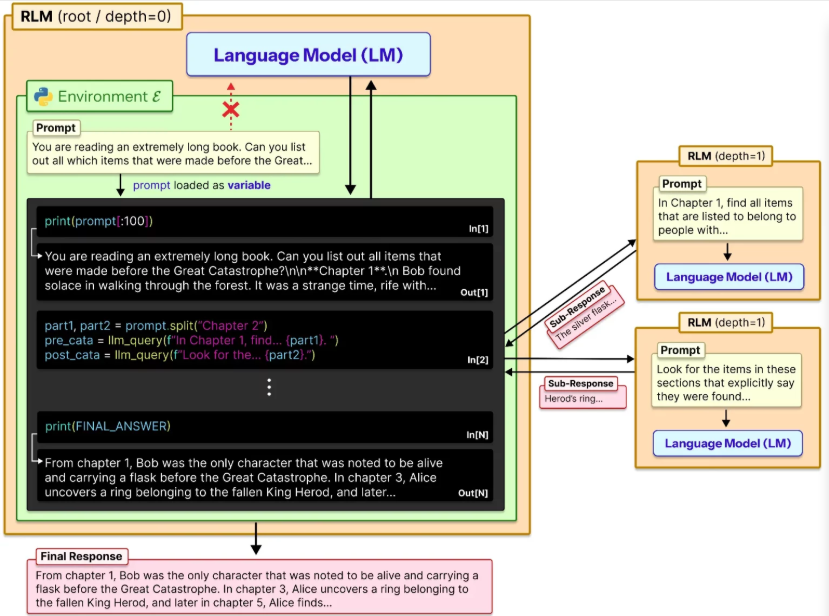
【递归语言模型(RLM)将提示视为环境的一部分 | 来源:arXiv】
从技术原理来看,RLM为LLM赋予了外部记忆空间及相应的操作能力,具体实现步骤包括:
1. 将完整提示文本加载至指定变量中;
2. 根据内存容量或预设参数对变量中的文本进行分割处理;
3. 将分割后的文本片段逐一发送至LLM,同步保存输出结果以供后续调用;
4. 重复上述步骤,完成所有提示片段的独立处理与结果记录;
5. 整合所有片段的输出结果,生成模型的最终响应。
在这一过程中,可引入o3-mini等轻量化子模型,辅助完成子提示的总结归纳与局部推理任务,进一步提升处理效率。
RLM与传统分块技术的本质区别
初看之下,RLM的处理逻辑似乎与传统分块(chunking)技术相似,但二者存在根本性差异:传统分块技术要求模型在处理后续片段时遗忘前文信息,导致上下文关联性断裂;而RLM将完整提示文本保存在模型外部,允许LLM根据任务需求随时选择性回访任意片段,其核心是对记忆的动态导航而非简单总结。
RLM的核心技术突破
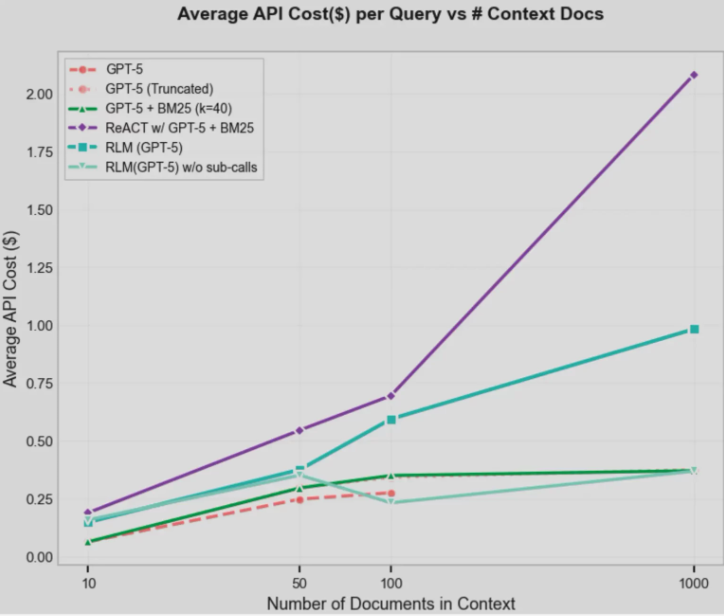
RLM成功攻克了传统LLM长期无法解决的四大核心难题:
1. 海量数据推理:模型无需遗忘前文信息,可灵活回访超大容量输入文本的任意章节,实现跨段落的逻辑关联分析;
2. 多文档合成:能够突破上下文限制,从分散的多个数据源中精准提取关键证据,完成跨文档的信息整合;
3. 信息密集型任务:即便答案需要基于输入文本的每一行信息推导,仍能保持稳定的处理性能;
4. 长结构化输出:在词元窗口限制之外独立构建各部分结果,最终实现无缝拼接,生成逻辑连贯的长文本输出。
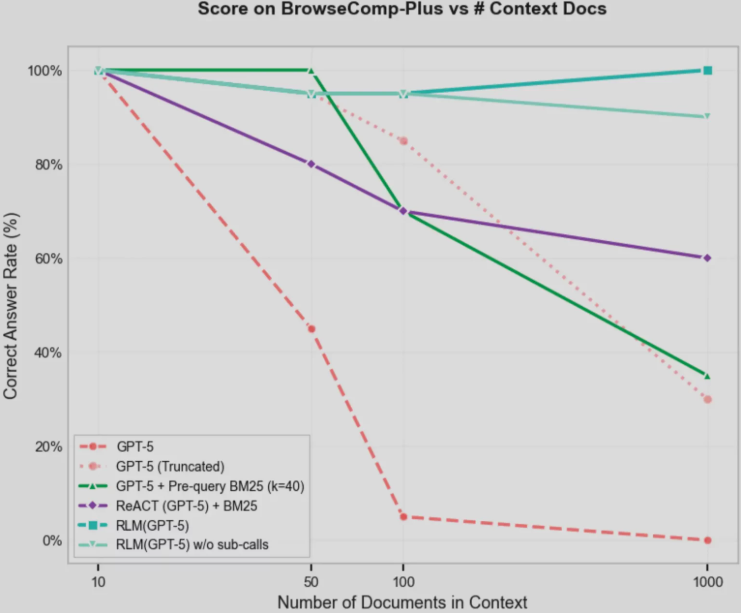
简而言之,RLM赋予了LLM处理超大规模、超高密度、复杂结构文本的能力,突破了传统提示技术的应用边界。
RLM的技术权衡与局限性
尽管RLM解决了诸多关键技术难题,但在实际应用中仍存在一定局限性,具体如下表所示:
|
局限性 |
影响 |
|
模型间提示不匹配 |
相同的RLM提示在不同模型中易产生不稳定行为,引发过多无效递归调用 |
|
对编码能力要求较高 |
性能较弱的模型难以在REPL环境中可靠地完成上下文操作 |
|
输出标记耗尽风险 |
过长的推理链可能超出模型的输出限制,导致推理轨迹被截断 |
|
不支持异步子调用 |
顺序递归机制会显著增加任务处理延迟,影响实时性体验 |
总体而言,RLM的核心权衡在于:以牺牲部分原始处理速度与稳定性为代价,换取模型在处理规模与推理深度上的显著提升。
结语
在RLM出现之前,LLM的规模扩展始终围绕两个核心维度:增加模型参数数量与扩大词元窗口容量。而RLM的创新之处在于引入了第三个关键维度——推理结构优化。这一技术变革的核心逻辑并非构建“更大的大脑”,而是教会模型像人类一样利用“大脑之外的记忆”,通过外部存储与递归调用实现复杂任务的高效处理。
RLM代表了一种整体性的技术视角,它并非对传统模型操作方法的简单迭代,而是基于全新逻辑的突破性创新,为语言模型的未来发展提供了全新思路与方向。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献374条内容
已为社区贡献374条内容

所有评论(0)