超级大更新?!NVIDIA CUDA 13.1:开启下一代GPU编程新纪元,CUDA Tile与性能飞跃双驱动
NVIDIA CUDA 13.1:开启下一代GPU编程新纪元,CUDA Tile与性能飞跃双驱动
2025年12月4日,NVIDIA正式发布CUDA 13.1版本,这是自CUDA平台诞生二十年来规模最大、内容最全面的一次更新。该版本不仅推出了革命性的CUDA Tile编程模型,还在GPU资源管理、开发者工具、数学库等多个维度进行了深度优化,为AI、高性能计算等领域的开发者提供了更强大的工具支撑,助力充分释放下一代GPU的计算潜能。
一、核心突破:CUDA Tile重塑GPU编程模式
在传统的SIMT(单指令多线程)编程中,开发者需要手动划分数据并定义每个线程的执行路径,这不仅增加了编程复杂度,还难以充分适配不同架构GPU的硬件特性。CUDA 13.1推出的CUDA Tile,以“基于数据块(Tile)”的编程理念,将GPU编程提升到全新层次。
1. CUDA Tile的核心优势
- 硬件抽象化:开发者无需关注 tensor core 等专用硬件的底层细节,只需定义数据块(Tile)及对应的数学运算,编译器和运行时会自动优化执行方式,实现硬件能力的高效调用。
- 向前兼容性:基于CUDA Tile编写的代码可兼容未来GPU架构,无需因硬件升级而大规模重构,显著降低长期开发成本。
- AI场景优化:首个版本重点聚焦AI算法开发,后续版本将持续扩展功能,覆盖更多计算场景。
2. 两大核心组件
| 组件名称 | 功能描述 |
|---|---|
| CUDA Tile IR | 全新的虚拟指令集架构(ISA),为NVIDIA GPU编程提供统一的底层指令支持 |
| cuTile Python DSL | 专为数组和Tile-based内核设计的领域特定语言(DSL),让Python开发者能轻松编写高效GPU内核 |
3. 版本支持说明
目前,CUDA Tile仅支持NVIDIA Blackwell架构(计算能力10.x和12.x)的GPU产品;C++版本的实现将在后续CUDA更新中推出,未来还会扩展到更多GPU架构。
二、GPU资源管理升级:Green Context与MPS优化
为满足低延迟、高确定性的业务需求,CUDA 13.1在GPU资源 partitioning 上实现了精细化管控,主要体现在Green Context的 runtime API 开放和Multi-Process Service(MPS)的功能增强。
1. Green Context:轻量级资源隔离方案
Green Context是传统CUDA Context的轻量级替代方案,自CUDA 12.4起已在驱动API中可用,此次CUDA 13.1正式将其纳入runtime API,让开发者更便捷地实现资源管控:
- SM级资源划分:可将GPU的 Streaming Multiprocessors(SM)划分为多个独立分区,为不同任务分配专属SM资源,确保 latency-sensitive 任务优先执行。例如,将高优先级的实时推理代码分配到独立Green Context,避免与其他任务争抢资源。
- 灵活配置能力:新增可自定义的
split()API,支持通过更少的API调用构建复杂SM分区;同时支持配置工作队列,减少不同Green Context间的虚假依赖,提升执行效率。
2. MPS两大关键更新
MPS(多进程服务)是CUDA中支持多进程共享GPU资源的核心组件,此次更新新增两项重要功能:
- 内存局部性优化分区(MLOPart):仅支持Blackwell架构(计算能力10.0、10.3)的B200、B300 GPU,可将单块GPU虚拟化为多个“轻量设备”,每个设备拥有独立的计算和内存资源,显著提升内存访问局部性。未来版本将支持GB200、GB300。
- 静态SM分区:适用于Ampere及以上架构(计算能力8.0+),通过在启动MPS控制守护进程时添加
-S或--static-partitioning参数,可为MPS客户端分配专属SM“块”(如Hopper架构为8个SM/块),实现确定性资源分配和更强的进程隔离。
三、开发者工具:调试与 profiling 效率倍增
CUDA 13.1对多款核心开发者工具进行了功能增强,帮助开发者更快定位问题、优化性能。
1. Nsight Compute:CUDA Tile内核专属profiling
Nsight Compute 2025.4版本新增对CUDA Tile内核的 profiling 支持:
- 摘要页新增“Result Type”列,清晰区分Tile内核与SIMT内核;
- 详情页新增“Tile Statistics” section,汇总Tile维度、关键流水线利用率等核心指标;
- 源码页支持将性能指标映射到高层级cuTile内核源码,便于定位性能瓶颈。
此外,该版本还支持设备启动图(device-launched graphs)的CUDA图节点 profiling,并优化源码页导航,支持点击编译器生成和用户自定义标签跳转。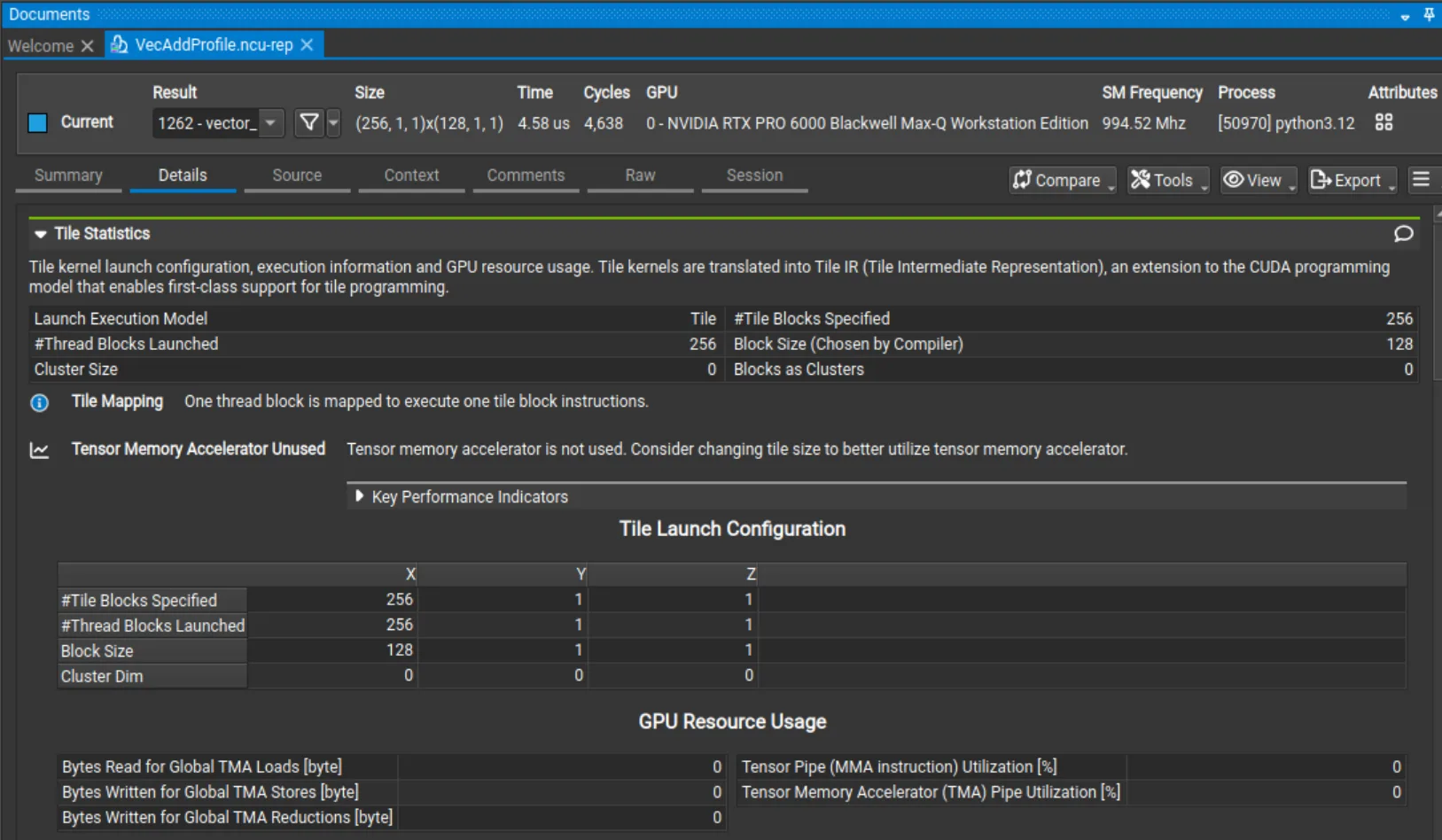
2. Compute Sanitizer:编译时内存错误检测
Compute Sanitizer 2025.4新增NVCC编译时补丁功能,通过-fdevice-sanitize=memcheck编译 flag,将内存错误检测逻辑直接集成到编译过程中:
- 优势:相比传统运行时检测,速度更快,且能捕捉更细微的内存问题(如相邻内存分配间的非法访问);
- 使用流程:
- 编译代码:
nvcc -fdevice-sanitize=memcheck -o myapp myapp.cu - 运行检测:
compute-sanitizer --tool memcheck myapp
目前仅支持memcheck工具,后续将扩展更多检测能力。
- 编译代码:
3. Nsight Systems:全链路追踪能力增强
Nsight Systems 2025.6.1同步发布,新增多项追踪功能:
- 系统级CUDA追踪:通过
--cuda-trace-scope支持跨进程树或全系统追踪; - 主机函数追踪:新增对CUDA Graph主机函数节点和
cudaLaunchHostFunc()的追踪; - 硬件追踪默认启用:支持硬件追踪的GPU将默认使用硬件模式,可通过
--trace=cuda-sw回退到软件模式; - Green Context可视化:时间线新增SM分配提示,直观展示GPU资源利用率。
四、数学库升级:性能与功能双突破
CUDA 13.1对cuBLAS、cuSPARSE、cuSOLVER等核心数学库进行了全面优化,尤其针对Blackwell架构提升了AI和科学计算场景的性能。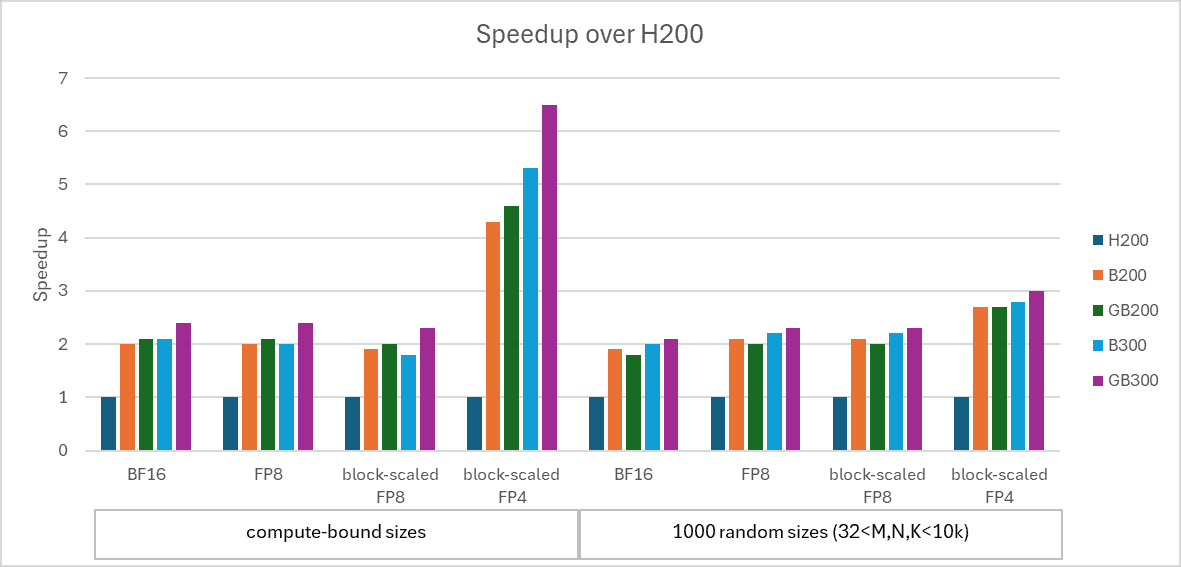
1. cuBLAS:Grouped GEMM与精度优化
- Grouped GEMM支持:新增实验性API,支持Blackwell GPU上FP8、BF16/FP16精度的分组矩阵乘法(Grouped GEMM),结合CUDA Graph实现无主机同步的设备端形状定义,在MoE(混合专家模型)场景中,相比多流GEMM实现提速最高4倍;
- 精度模拟增强:虽非CUDA 13.1新增,但CUDA Toolkit 13.0中cuBLAS已支持在GB200 NVL72、RTX PRO 6000 Blackwell等GPU的Tensor Core上模拟FP32/FP64精度,提升双精度矩阵乘法(FP64 matmul)性能。
2. cuSPARSE:稀疏矩阵计算提速
新增稀疏矩阵向量乘法(SpMVOp)API,相比传统CsrMV API性能更高,支持:
- CSR格式稀疏矩阵;
- 32位索引、双精度计算;
- 用户自定义收尾操作(epilogues)。
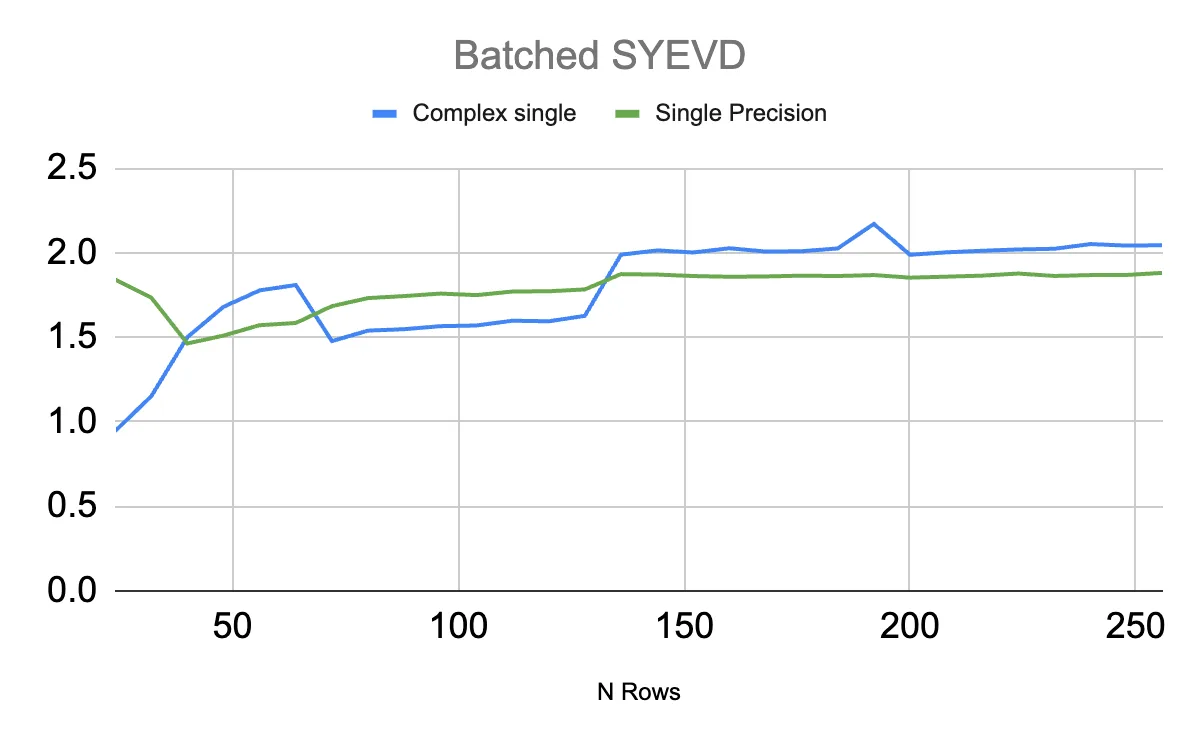
3. cuSOLVER:特征分解性能跃升
针对对称矩阵(SYEV)和通用矩阵(GEEV)的特征分解,cuSOLVER在Blackwell架构上实现显著提速:
- Batched SYEV:对5000个批量(24-256行)的对称矩阵计算,RTX PRO 6000 Blackwell相比L40S提速最高2倍,且随着矩阵行数增加(从5行到250行),提速从1.5倍逐步提升至2倍;
-
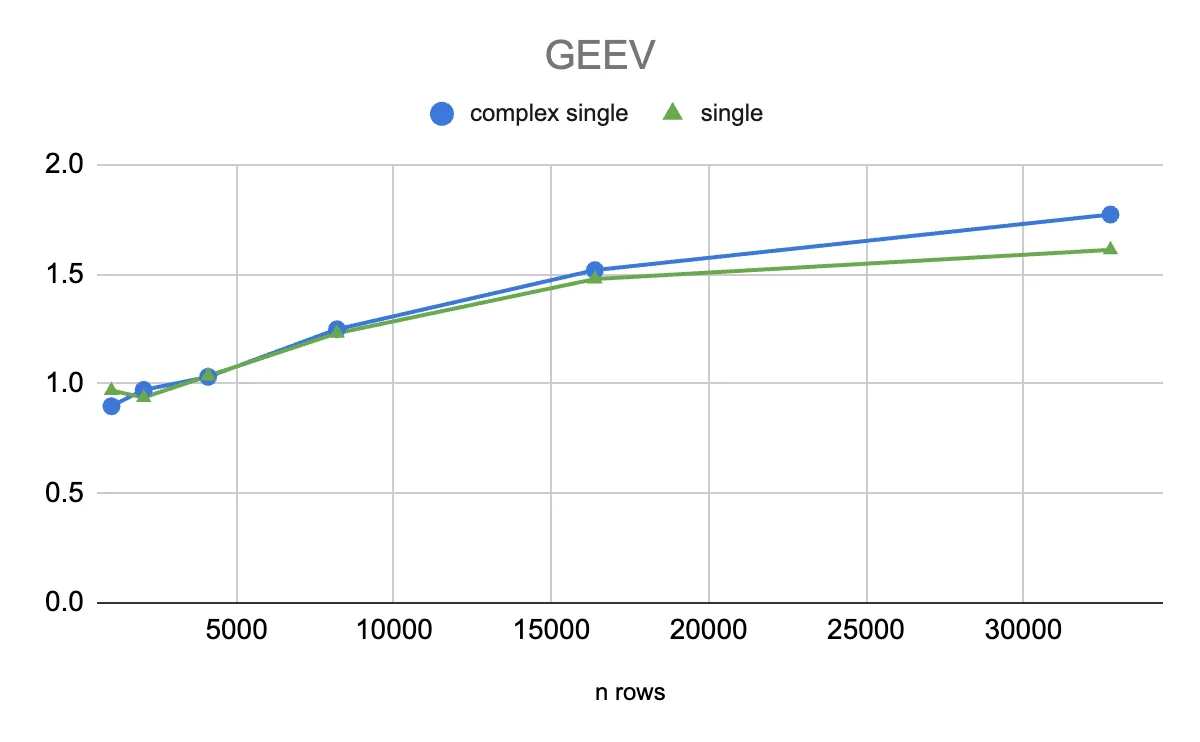
- GEEV:采用CPU-GPU混合算法(CPU线程处理QR算法中的提前收缩,GPU处理其余计算),对1024-32768行的通用矩阵,RTX PRO 6000 Blackwell相比L40S提速最高1.7倍(30000行时)。
4. cuFFT:设备端API赋能高性能FFT
新增cuFFT设备API,提供主机函数用于查询或生成设备函数代码及数据库元数据(输出为C++头文件),专为cuFFTDx库设计,可通过查询cuFFT生成优化的cuFFTDx代码块,进一步提升FFT计算性能。
五、CCCL 3.1:CUB库体验升级
CUDA Core Compute Libraries(CCCL)3.1作为CUDA 13.1的一部分,对CUB库(GPU并行算法库)进行了两项关键优化,简化开发流程并提升确定性。
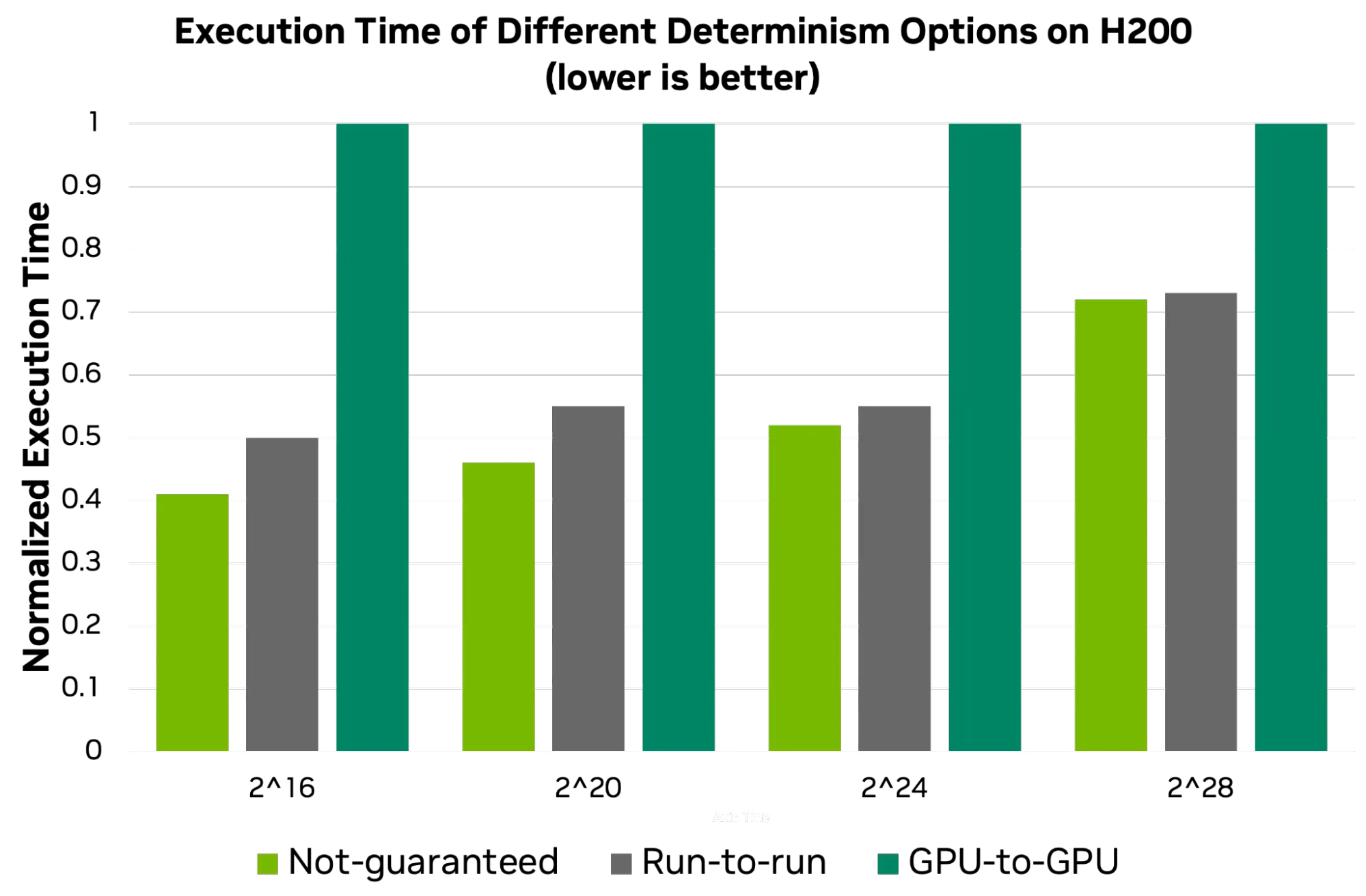
1. 浮点归约确定性可选
由于浮点加法的非结合性,传统cub::DeviceReduce仅保证同一GPU上多次运行结果一致(run-to-run)。CCCL 3.1新增两种确定性选项,支持性能与确定性的灵活权衡:
| 选项 | 实现方式 | 结果一致性 | 性能 |
|---|---|---|---|
| not-guaranteed | 单阶段原子归约 | 不保证一致 | 最快 |
| run-to-run | 双阶段归约(传统方式) | 同一GPU多次运行一致 | 中等 |
| gpu-to-gpu | 基于GTC 2024演讲的可复现归约 | 不同GPU间结果一致 | 最慢 |
使用示例:
// 选择性能与确定性权衡方案
// auto env = cuda::execution::require(cuda::execution::determinism::not_guaranteed);
// auto env = cuda::execution::require(cuda::execution::determinism::run_to_run);
auto env = cuda::execution::require(cuda::execution::determinism::gpu_to_gpu);
cub::DeviceReduce::Sum(..., env);
2. 单阶段API简化临时存储管理
传统CUB算法需通过“查询-分配-执行-释放”的两阶段调用管理临时存储,步骤繁琐且易因参数不一致出错。CCCL 3.1新增支持内存资源(memory resource)的API重载,可直接通过内存池自动管理临时存储,示例如下:
优化前(两阶段):
// 1. 查询临时存储大小
cub::DeviceScan::ExclusiveSum(d_temp_storage,
temp_storage_bytes,
nullptr, ...);
// 2. 分配临时存储
cudaMallocAsync(&d_temp_storage,
temp_storage_bytes, stream);
// 3. 执行扫描
cub::DeviceScan::ExclusiveSum(d_temp_storage,
temp_storage_bytes,
d_input...);
// 4. 释放临时存储
cudaFreeAsync(temp_storage, stream);
优化后(单阶段):
// 1. 创建设备内存池(底层使用cudaMallocAsync)
cuda::device_memory_pool mr{cuda::devices[0]};
// 2. 单调用执行,临时存储由内存池自动管理
cub::DeviceScan::ExclusiveSum(d_input,..., mr);
六、总结与行动指南
CUDA 13.1以CUDA Tile为核心,通过GPU资源精细化管理、开发者工具升级、数学库性能跃升和CUB API简化,为下一代GPU编程奠定了坚实基础。无论是AI算法开发、高性能计算,还是低延迟业务场景,都能通过该版本获得显著的开发效率和性能提升。
立即行动:
- 访问NVIDIA CUDA官网下载CUDA Toolkit 13.1;
- 查看CUDA Tile专属资源,快速上手Tile-based编程;
- 参考官方文档,探索Green Context、MPS静态分区等新功能在业务中的应用。
CUDA 13.1不仅是一次版本更新,更是NVIDIA对GPU编程范式的重新定义,标志着GPU计算正式进入“数据块驱动”的新时代。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 51
51 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)