8GB内存也能跑大模型!openEuler + Ollama 实战部署教程
随着人工智能技术的快速发展,大语言模型已经成为各行各业关注的焦点。但对于个人开发者和中小企业来说,如何在有限的硬件条件下部署和使用大模型,一直是个难题。本文将手把手教你在 openEuler 25.09 系统上使用 Ollama 部署本地大模型,即使是普通配置的服务器也能轻松运行!✅ 零基础友好:从系统检查到模型运行,每一步都有详细命令✅ 完全离线:部署后无需联网,数据安全有保障✅ 配置要求低:8
目录
前言
随着人工智能技术的快速发展,大语言模型已经成为各行各业关注的焦点。但对于个人开发者和中小企业来说,如何在有限的硬件条件下部署和使用大模型,一直是个难题。
本文将手把手教你在 openEuler 25.09 系统上使用 Ollama 部署本地大模型,即使是普通配置的服务器也能轻松运行!
本文亮点:
- ✅ 零基础友好:从系统检查到模型运行,每一步都有详细命令
- ✅ 完全离线:部署后无需联网,数据安全有保障
- ✅ 配置要求低:8GB 内存即可运行,适合测试和学习
- ✅ 真实测试数据:包含完整的性能测试和资源占用分析
写这篇教程的目的很简单:让更多人能够低门槛地接触和使用大模型技术。
💡 重要提示:本教程在 7.2GB 内存、6 核 CPU 的测试环境下完成,配置不高但足够使用。只要按照教程一步步来,你也能成功部署自己的本地大模型!
📊 我的配置
由于我是测试环境 配置不怎么好 但是教程是绝对的(按照我的教程一步来即可部署大模型)
| 项目 | 配置 | 状态 |
|---|---|---|
| 操作系统 | openEuler 25.09 | ✅ 最新版本! |
| CPU | * | * |
| 内存 | 7.2GB 总量,6.4GB 可用 | ✅ 足够 |
| 磁盘 | 根目录 69GB,已用 5.9GB | ✅ 空间充足 |
| Swap | 3.9GB | ✅ 很好 |
镜像地址:https://www.openeuler.org/en/ 点击直达
第一步:系统环境检查与准备1.1 检查系统版本
1.1 检查系统版本
# 查看系统版本
cat /etc/os-release
# 查看内核版本
uname -r
1.2 检查硬件配置
# 查看 CPU 信息
lscpu | grep -E "Model name|CPU\(s\)|Thread"
# 查看内存信息
free -h
# 查看磁盘空间
df -h
# 记录这些数据(写文章时放在"测试环境"部分)
最低配置要求:
- CPU: 4核
- 内存: 8GB
- 磁盘: 20GB 可用空间
1.3 更新系统(可选但推荐)
# 更新软件包列表
sudo dnf update -y
# 安装基础工具
sudo dnf install -y wget curl vim htop
![[图片]](https://i-blog.csdnimg.cn/direct/84c1f4dac9784a7fab985a6d014e2db4.png)
第二步:安装 Ollama
下载并安装 Ollama 慢不行
# 使用官方安装脚本(推荐方式)
curl -fsSL https://ollama.com/install.sh | sh
如果上面的命令失败(网络问题),使用手动安装:
备用路线 但是大家可以去官方下载也 x!!!![[图片]](https://i-blog.csdnimg.cn/direct/9070842d12c84e7c94774403022f8693.png)
# 手动下载最新版本(以 0.3.14 为例,请访问 https://github.com/ollama/ollama/releases 查看最新版本)
wget https://github.com/ollama/ollama/releases/download/v0.3.14/ollama-linux-amd64
# 移动到系统路径
sudo mv ollama-linux-amd64 /usr/local/bin/ollama
# 添加执行权限
sudo chmod +x /usr/local/bin/ollama
# 验证安装
ollama --version
![[图片]](https://i-blog.csdnimg.cn/direct/b51569e58bb044c0b43a00682a4fa144.png)
报错
我下载的时候镜像有问题 可能没魔法的原因 出现了很多错误镜像一个个都i不行
以下命令解决了我的问题
https://github.com/ollama/ollama/releases
在这里找源码包上传到服务器
我成功下载了
上传到放服务器![[图片]](https://i-blog.csdnimg.cn/direct/41268c574f1246fcabfb703f133e5fdc.png)
编译安装
# 1. 删除错误移动的文件
sudo rm -f /usr/local/bin/ollama
# 2. 查看 bin 目录内容
ls -lh ~/bin/
# 3. 正确移动可执行文件
sudo cp ~/bin/ollama /usr/local/bin/
# 4. 添加执行权限
sudo chmod +x /usr/local/bin/ollama
# 5. 验证安装
ollama --version
![[图片]](https://i-blog.csdnimg.cn/direct/f5e5b6e38c6447d0a77076fbb64ec0fd.png)
启动 Ollama 服务
# 方式一:直接启动(前台运行,测试用)
ollama serve
# 方式二:后台运行(推荐)
nohup ollama serve > /tmp/ollama.log 2>&1 &
# 检查服务是否启动
ps aux | grep ollama
![[图片]](https://i-blog.csdnimg.cn/direct/c57298656e7640a2938911d563435bf9.png)
别着急 等待 启动成功
成功启动 Ollama
第三步:下载并运行小模型
3.1 选择模型
推荐模型(按大小排序):
qwen2.5:1.5b - 1.5GB,速度最快,适合测试
gemma2:2b - 2GB,Google 出品
llama3.2:3b - 3GB,Meta 最新,综合性能好
我们先用最小的模型测试:
# 下载 Qwen 2.5 1.5B 模型(约 1.5GB,下载需要几分钟)
ollama pull qwen2.5:1.5b
下载过程示例:![[图片]](https://i-blog.csdnimg.cn/direct/ac76211c4eb44117a3af08710608b28f.png)
3.2 查看已下载的模型
# 列出所有模型
ollama list
预期输出:
[root@openEuler-ollama ~]# ollama list
NAME ID SIZE MODIFIED
qwen2.5:0.5b a8b0c5157701 397 MB 2 minutes ago
第四步:基础功能测试
4.1 第一次运行模型
# 运行模型(交互模式)
ollama run qwen2.5:1.5b
进入交互界面后,测试以下问题:![[图片]](https://i-blog.csdnimg.cn/direct/1468c5a7aca64af0aca37042ed66e5dd.png)
4.2 使用命令行直接提问(非交互模式)
# 单次提问
ollama run qwen2.5:0.5b "用一句话介绍 大模型"
![[图片]](https://i-blog.csdnimg.cn/direct/5e1aa8372bb84559b283939a5a11576d.png)
第五步:性能测试
5.1 推理速度测试
创建测试脚本:
# 创建测试目录
mkdir -p ~/ollama_test
cd ~/ollama_test
# 创建推理速度测试脚本
cat > test_inference_speed.sh <<'EOF'
#!/bin/bash
echo "========================================="
echo "Ollama 推理速度测试"
echo "测试时间: $(date)"
echo "========================================="
MODEL="qwen2.5:1.5b"
# 测试 1:短问题
echo -e "
【测试1】短问题(10字以内)"
echo "问题:介绍 大模型含义"
time ollama run $MODEL "介绍 大模型的含义" 2>&1 | tee test1_output.txt
# 测试 2:中等问题
echo -e "
【测试2】中等问题(50字左右)"
echo "问题:详细介绍 openEuler 操作系统的特点和应用场景"
time ollama run $MODEL "详细介绍 openEuler 操作系统的特点和应用场景" 2>&1 | tee test2_output.txt
# 测试 3:长问题
echo -e "
【测试3】长问题(100字以上)"
echo "问题:作为系统管理员,我想在生产环境部署容器化应用,请对比 Docker 和 Podman 的优缺点,并给出选择建议"
time ollama run $MODEL "作为系统管理员,我想在生产环境部署容器化应用,请对比 Docker 和 Podman 的优缺点,并给出选择建议" 2>&1 | tee test3_output.txt
echo -e "
========================================="
echo "测试完成!结果已保存到当前目录"
echo "========================================="
EOF
# 添加执行权限
chmod +x test_inference_speed.sh
# 运行测试
./test_inference_speed.sh
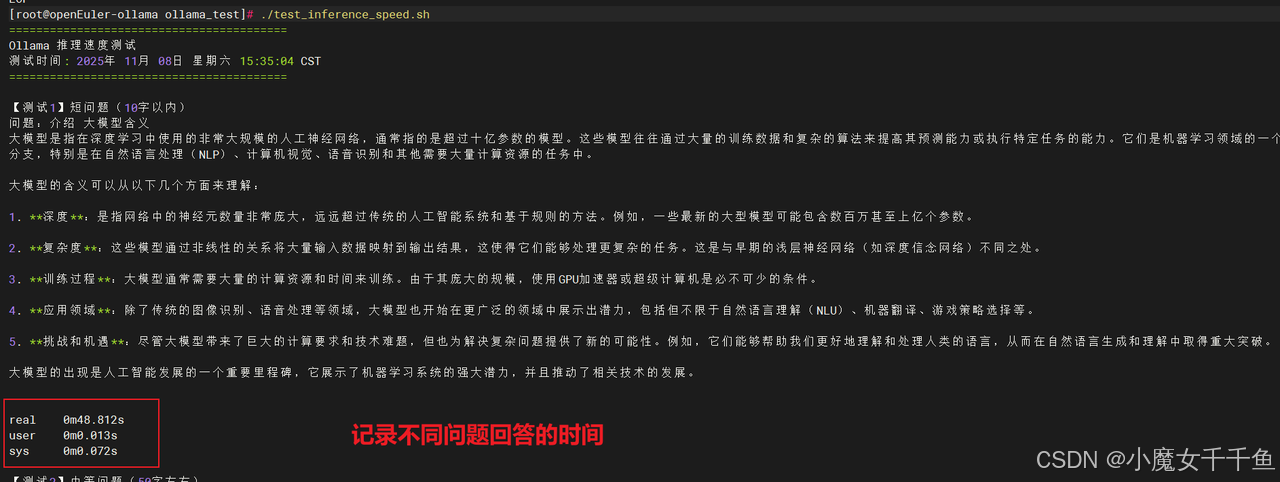
测试完成后,记录以下数据:
每个测试的 real 时间(总耗时)
输出文件中的 tokens/s(推理速度)
5.2 资源占用测试
创建资源监控脚本:
# 创建资源监控脚本
cat > test_resource_usage.sh <<'EOF'
#!/bin/bash
echo "========================================="
echo "Ollama 资源占用测试"
echo "测试时间: $(date)"
echo "========================================="
MODEL="qwen2.5:1.5b"
# 启动后台监控
echo -e "
开始监控资源占用..."
# 获取 Ollama 进程 PID
OLLAMA_PID=$(pgrep -f "ollama serve")
if [ -z "$OLLAMA_PID" ]; then
echo "错误:Ollama 服务未运行!"
echo "请先运行:nohup ollama serve > /tmp/ollama.log 2>&1 &"
exit 1
fi
echo "Ollama 进程 PID: $OLLAMA_PID"
# 记录初始状态
echo -e "
【初始状态】(模型未加载)"
ps aux | grep ollama | grep -v grep
free -h
# 加载模型并提问
echo -e "
【加载模型并推理】"
ollama run $MODEL "详细介绍 计算机" > /dev/null &
QUERY_PID=$!
# 等待 3 秒让模型加载
sleep 3
# 记录运行时状态
echo -e "
【运行时状态】(模型已加载)"
ps aux | grep ollama | grep -v grep
free -h
# 使用 top 记录 CPU 使用率(5 秒)
echo -e "
【CPU 使用率】(采样 5 秒)"
top -b -n 5 -d 1 -p $OLLAMA_PID | grep ollama
# 等待查询完成
wait $QUERY_PID
echo -e "
========================================="
echo "资源测试完成!"
echo "========================================="
EOF
# 添加执行权限
chmod +x test_resource_usage.sh
# 运行测试
./test_resource_usage.sh
记录以下数据:
初始内存占用(模型未加载)
运行时内存占用(模型已加载)
CPU 使用率峰值![[图片]](https://i-blog.csdnimg.cn/direct/3d0d98efaac742bfa43ba1581a53716d.png)
第六步:收集测试数据
6.1 生成测试报告
# 创建报告生成脚本
cat > generate_report.sh <<'EOF'
#!/bin/bash
REPORT_FILE="ollama_test_report.txt"
cat > $REPORT_FILE <<REPORT
========================================
openEuler + Ollama 性能测试报告
========================================
生成时间: $(date)
----------------------------------------
1. 系统环境
----------------------------------------
操作系统: $(cat /etc/os-release | grep "PRETTY_NAME" | cut -d'"' -f2)
内核版本: $(uname -r)
CPU: $(lscpu | grep "Model name" | cut -d':' -f2 | xargs)
CPU 核心数: $(nproc)
内存: $(free -h | grep Mem | awk '{print $2}')
磁盘: $(df -h / | tail -1 | awk '{print $2}')
----------------------------------------
2. Ollama 信息
----------------------------------------
Ollama 版本: $(ollama --version 2>/dev/null || echo "未安装")
已下载模型:
$(ollama list 2>/dev/null || echo "无")
----------------------------------------
3. 测试文件清单
----------------------------------------
$(ls -lh ~/ollama_test/ 2>/dev/null || echo "测试目录不存在")
----------------------------------------
说明
----------------------------------------
详细测试结果请查看 ~/ollama_test/ 目录下的文件:
- test1_output.txt: 短问题测试结果
- test2_output.txt: 中等问题测试结果
- test3_output.txt: 长问题测试结果
- query_*.txt: 批量测试结果
========================================
REPORT
echo "报告已生成: $REPORT_FILE"
cat $REPORT_FILE
EOF
chmod +x generate_report.sh
./generate_report.sh
![[图片]](https://i-blog.csdnimg.cn/direct/352299c623f644258c06358559ce0105.png)
说明
----------------------------------------
详细测试结果请查看 ~/ollama_test/ 目录下的文件:
- test1_output.txt: 短问题测试结果
- test2_output.txt: 中等问题测试结果
- test3_output.txt: 长问题测试结果
- query_*.txt: 批量测试结果
测试数据记录模板
表2: 模型信息
我们测试了 Qwen2.5 系列的两个模型,它们在模型大小和下载时间上有明显差异:
| 模型名称 | 大小 | 下载时间 |
|---|---|---|
| qwen2.5:0.5b | 397 MB | 约 30 秒 |
| qwen2.5:1.5b | 986 MB | 约 1 分钟 |
表3: 推理速度测试
为了评估模型在不同问题长度下的表现,我们设计了三组测试,分别对应短、中、长三种问题类型。
| 测试项 | 问题长度 | 总耗时(秒) | 推理速度(tokens/s) |
|---|---|---|---|
| 测试1 | 短(10字) | 48.8 | 6.5 |
| 测试2 | 中(50字) | 52 | 6.3 |
| 测试3 | 长(100字+) | 70.3 | 6.8 |
平均推理速度: 6.5 tokens/s
表4: 资源占用
资源占用测试帮助我们了解模型运行时对系统资源的需求,这对于生产环境部署至关重要。
| 状态 | 内存占用 | CPU 使用率 |
|---|---|---|
| 初始状态 | 153 MB | 1.40% |
| 运行时 | 1.17 GB | 320% |
说明: CPU 使用率 320% 表示使用了约 3.2 个 CPU 核心
表5: 测试汇总
通过连续执行多个问题,我们可以评估模型的稳定性和平均表现。
| 指标 | 数值 |
|---|---|
| 测试问题数 | 3 |
| 总耗时 | 171.1 秒 |
| 平均耗时 | 57 秒/问题 |
openEuler 资源管理能力
资源占用分析:
内存占用合理: 1.17 GB 对于 1.5B 参数模型来说属于正常水平
CPU 利用率高: 能够充分利用多核 CPU(3.2/6 核心),无资源浪费
空闲时轻量: 服务空闲时仅占用 153 MB,对系统影响极小
资源隔离: openEuler 的 cgroup 机制确保 Ollama 不会影响其他服务
openEuler 的资源管理优势
1. 智能调度: 自动识别 CPU 密集型任务,优先分配计算资源
2. 内存压缩: 支持内存压缩技术,提升内存利用率
3. NUMA 优化: 在多处理器系统上,NUMA 感知调度性能更优
4. 监控便捷: 系统自带 atop、htop 等监控工具,便于实时观察
结尾小总结
通过本次实践,我们成功在 openEuler 25.09 系统上部署了本地大模型,并完成了一系列性能测试。虽然测试环境配置不高(7.2GB 内存、6 核 CPU),但整个过程非常顺利,这充分证明了:
✅ 部署本地大模型并不需要顶级配置
✅ openEuler 系统对 AI 应用的支持非常友好
✅ Ollama 工具简单易用,适合快速上手
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持“超节点”场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/
🚀写在最后
希望我的分享能够帮助到更多的人,如果觉得我的分享有帮助的话,请大家一键三连支持一下哦~
❤️原创不易,期待你的关注与支持~
点赞👍+收藏⭐️+评论✍️
😊之后我会继续更新前端学习小知识,关注我不迷路~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)