【Linux】MIPS 架构下的非对齐访问 (Unaligned Access) 深度解析
摘要: MIPS架构对内存对齐有严格要求,非对齐访问会触发地址错误异常(AdEL/AdES)。Linux内核通过do_ade处理异常,可选择模拟执行(性能损耗大)或发送SIGBUS信号终止进程。常见触发场景包括强制类型转换、打包结构体和动态内存分配。解决方案包括使用专用指令(LWL/LWR)、memcpy安全拷贝、优化数据结构对齐,以及通过/proc/sys/mips/mips_unaligned
MIPS 架构下的非对齐访问 (Unaligned Access) 深度解析
1. 什么是内存对齐 (Memory Alignment)?
在计算机体系结构中,内存通常被组织为字节数组。然而,为了提高性能,CPU 往往按“字 (Word)”的粒度(如 32 位或 64 位)访问内存。
- 自然对齐 (Natural Alignment):如果一个数据类型的地址是其大小的倍数,则称该数据是“自然对齐”的。
uint8_t(1 字节): 任意地址对齐 (Address % 1 == 0)uint16_t(2 字节): 地址必须是 2 的倍数 (Address % 2 == 0)uint32_t(4 字节): 地址必须是 4 的倍数 (Address % 4 == 0)double/uint64_t(8 字节): 地址必须是 8 的倍数 (Address % 8 == 0)
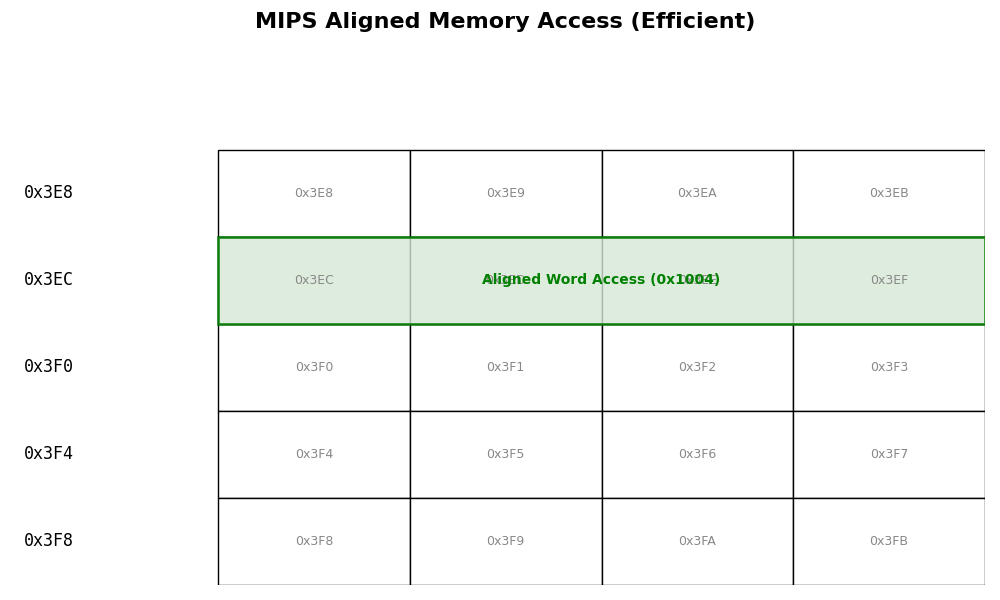
图 1:对齐访问示意图。CPU 一次总线周期即可读取完整数据。
2. MIPS 架构的特殊性:严苛的对齐要求
与 x86 架构(通常硬件自动处理非对齐访问,仅牺牲少量性能)不同,经典的 MIPS 架构不支持硬件自动处理非对齐的内存访问。
2.1 硬件行为
当 MIPS CPU 执行加载 (Load) 或存储 (Store) 指令时,如果目标地址没有对齐:
LW(Load Word) 指令访问的地址不是 4 的倍数。LH(Load Halfword) 指令访问的地址不是 2 的倍数。
CPU 会立即触发一个地址错误异常 (Address Error Exception):
- AdEL (Address Error Load): 加载数据时发生的地址未对齐。
- AdES (Address Error Store): 存储数据时发生的地址未对齐。
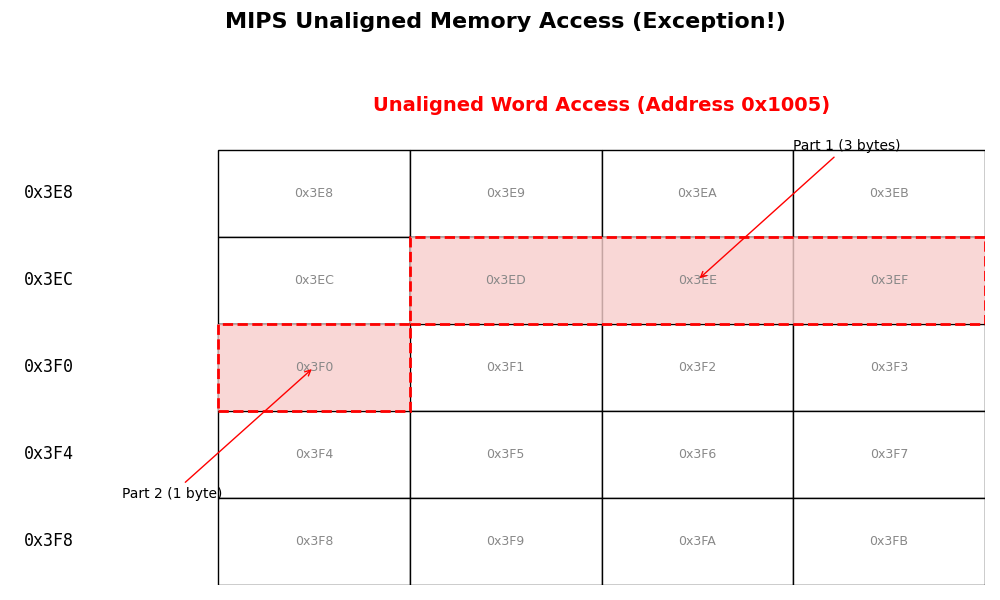
图 2:非对齐访问示意图。数据跨越了两个内存字,MIPS 硬件无法直接处理,触发异常。
3. 异常处理流程与 Linux 内核机制
当异常触发后,控制权会立即交给 Linux 内核的异常处理程序。
3.1 处理流程图
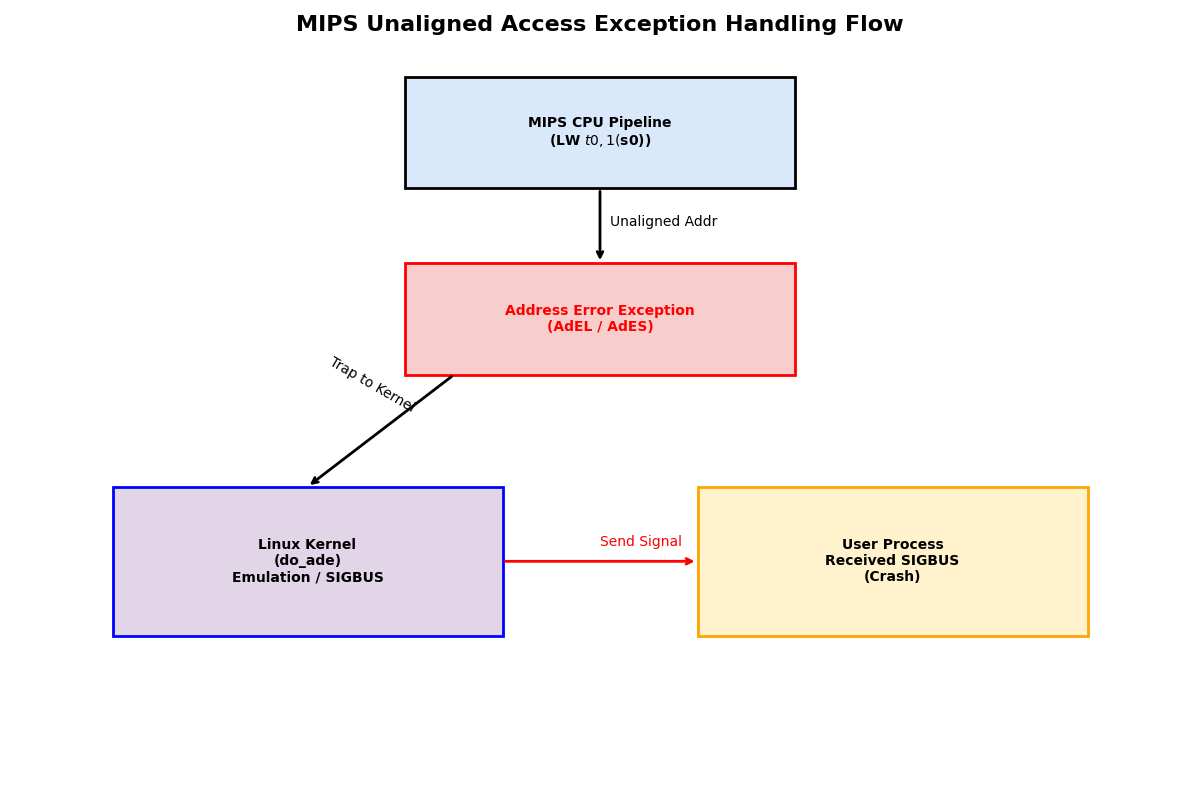
图 3:MIPS 非对齐访问异常处理流程
3.2 内核处理策略 (do_ade)
Linux 内核的 do_ade (Address Error) 函数负责处理此类异常。根据内核配置,主要有两种处理方式:
A. 模拟执行 (Emulation) - 性能杀手
内核会捕获异常,识别出是哪条指令导致的非对齐访问,然后通过软件方式“模拟”该指令的执行。
- 原理: 内核分别读取两个相关的内存字,拼接出用户需要的数据,放入目标寄存器,然后跳过故障指令继续执行。
- 代价: 极其昂贵!一次非对齐访问可能消耗数百个 CPU 时钟周期(相比之下,正常访问仅需 1-2 个周期)。
- 日志: 你可能会在
dmesg中看到大量的Unaligned access at instruction ...警告。
B. 发送信号 (Signal) - 程序崩溃
如果内核配置为不模拟(或者通过 /proc/sys/mips/mips_unaligned_access 禁用了模拟),内核会直接向触发异常的进程发送 SIGBUS (Bus Error) 信号。
- 结果: 进程通常会立即终止(Core Dump)。
4. 常见触发场景与代码示例
4.1 强制类型转换 (Casting)
这是最常见的原因。将一个字节对齐的指针(如 char*)强制转换为字对齐指针(如 int*)。
char buffer[10]; // buffer 可能从任意地址开始,或者 buffer[1] 肯定不是 4 字节对齐
char *ptr = &buffer[1]; // ptr = 0x1001 (假设 buffer = 0x1000)
uint32_t *val_ptr = (uint32_t *)ptr;
*val_ptr = 0xDEADBEEF; // <--- 触发 AdES 异常!
4.2 结构体打包 (Packed Structures)
在网络协议解析中常用 __attribute__((packed)),这会导致编译器生成未对齐的成员偏移。
struct __attribute__((packed)) Header {
uint8_t version; // 1 byte
uint32_t length; // Offset = 1 (未对齐!)
};
struct Header h;
h.length = 100; // 如果编译器生成普通的 SW 指令,将触发异常
注:现代 GCC 对于 packed 结构体通常会自动生成特殊的非对齐访问指令序列(LWL/LWR),但在指针转换时仍需小心。
4.3 alloca 动态栈分配
如前文所述,alloca 分配的内存可能只满足最小对齐要求,如果强制按更大粒度访问(如 double),可能触发异常。
5. 解决方案与最佳实践
5.1 使用专用指令 (LWL/LWR, SWL/SWR)
MIPS 指令集提供了专门用于非对齐访问的指令对:
LWL(Load Word Left) /LWR(Load Word Right)SWL(Store Word Left) /SWR(Store Word Right)
编译器支持: 使用 __attribute__((packed)) 或者编译器选项 -munaligned-access (如果支持) 可以让编译器自动生成这些指令。
5.2 使用 memcpy
这是最安全、移植性最好的方法。memcpy 能够处理任意地址的数据拷贝。
// 错误写法
// uint32_t val = *(uint32_t*)(buffer + 1);
// 正确写法
uint32_t val;
memcpy(&val, buffer + 1, sizeof(uint32_t));
5.3 修正数据结构定义
尽量避免使用 packed 属性,或者手动填充 (Padding) 结构体以保证自然对齐。
struct Header {
uint8_t version;
uint8_t _padding[3]; // 手动填充
uint32_t length; // 自然对齐
};
5.4 内核调试接口
你可以通过 procfs 查看和控制内核行为:
# 查看统计信息
cat /proc/sys/mips/mips_unaligned_access
# 控制策略 (0=默认, 1=强制模拟, 2=强制SIGBUS)
# echo 1 > /proc/sys/mips/mips_unaligned_access
6. 总结
在 MIPS 平台上开发,必须时刻警惕内存对齐问题。虽然内核提供了模拟机制作为兜底,但这会带来严重的性能惩罚。通过良好的编码规范(避免随意强转指针、使用 memcpy、合理设计结构体),可以彻底根除此类隐患,确保程序的高效稳定运行。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)