RAG技术入门到精通:检索增强生成完全解析
RAG(检索增强生成)技术旨在解决大语言模型专业领域知识不足的问题。其核心流程包括数据清洗、文档分块、Embedding嵌入、检索和生成五个关键步骤。文章详细介绍了不同分块策略和检索方法,帮助开发者构建更精准、高效的RAG系统,提升大模型在专业领域的回答质量。
RAG(检索增强生成)技术旨在解决大语言模型专业领域知识不足的问题。其核心流程包括数据清洗、文档分块、Embedding嵌入、检索和生成五个关键步骤。文章详细介绍了不同分块策略和检索方法,帮助开发者构建更精准、高效的RAG系统,提升大模型在专业领域的回答质量。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
一、RAG 基本概念
RAG 即 Retrieval-Augmented Generation(检索增强生成)的缩写。
- Retrieval 检索
- Augmented 增强
- Generation 生成
它的概念是:利用检索的技术,来增强整个 LLM大语言模型 的回复质量。
- 检索什么:检索和我们问题相关的专业领域知识。
1.1 为什么要有 RAG,它是用于解决什么问题
首先要了解 LLM大语言模型的缺点。
- 专业领域知识不足。LLM大语言模型背后涉及了预训练,后训练,强化学习。但这些训练的数据集通常来说是通用的世界知识,对于某一个专业领域的知识其实是不足的。
- 信息过时。大语言模型以前还存在 “信息过时” 的问题,例如大语言模型不知道今天发生的事情。但现在各大模型已经通过 “联网搜索” 解决。
- 幻觉问题。幻觉即大语言模型一本正经的胡说八道,一本正经源于LLM训练数据集的 “自信”,胡说八道意味着LLM确实不知道问题的答案。但现在各大模型也通过 “允许LLM回答不知道” 和 “联网搜索” 解决。
- 安全性问题。这包括了数据安全(企业的机密信息不能上传LLM),输出安全(敏感/违法/歧视性内容 或者 违反企业合规或审计要求)等。
RAG 主要针对 “专业领域知识不足” 这个点。当询问 LLM 的时候,除了自己问题,使用 RAG 检索相关的 “专业领域知识”,再把相关的 “专业领域知识” 发送给 LLM,这样 LLM 就能根据 “专业领域” 知识回答得更准确。
1.2 为什么不能把整个专业领域知识给 LLM,而需要先检索一下?
原因一:Token 长度有限
整个专业领域知识是很长很多的。给到LLM的时候,这些专业领域知识需要转成 token,才能让 LLM 进行 “预测”。这个 token 长度是有限的,不是无限的。
一般来说,1个中文约等于1个token。例如现在知名度较高的模型:GPT-5 支持 27万的输入token;Gemini 100 万 token;Claude Sonnet 4 支持 50万 token;DeepSeek 支持 12万多的 token。
原因二:成本问题
token 意味着成本,意味着钱。如下是各个模型的价格:
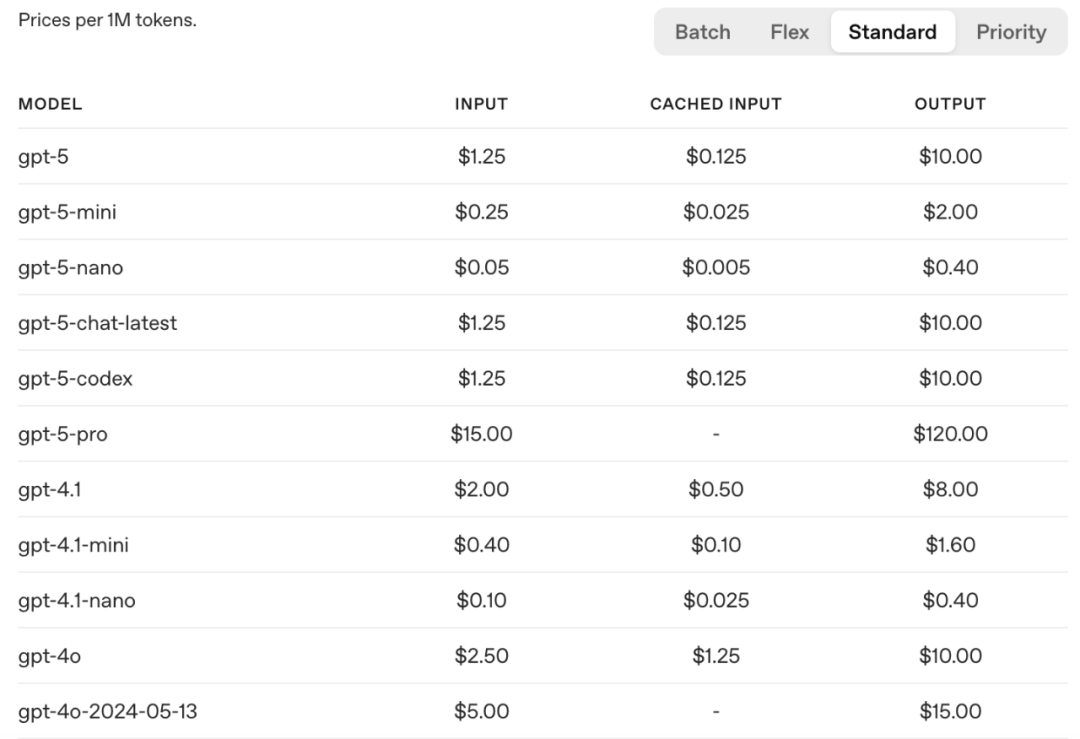
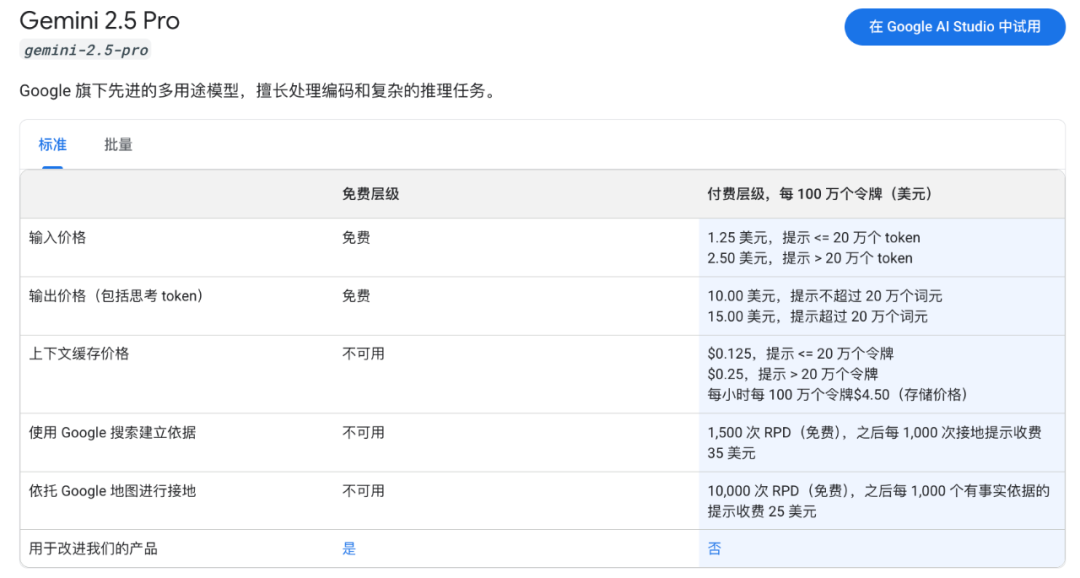

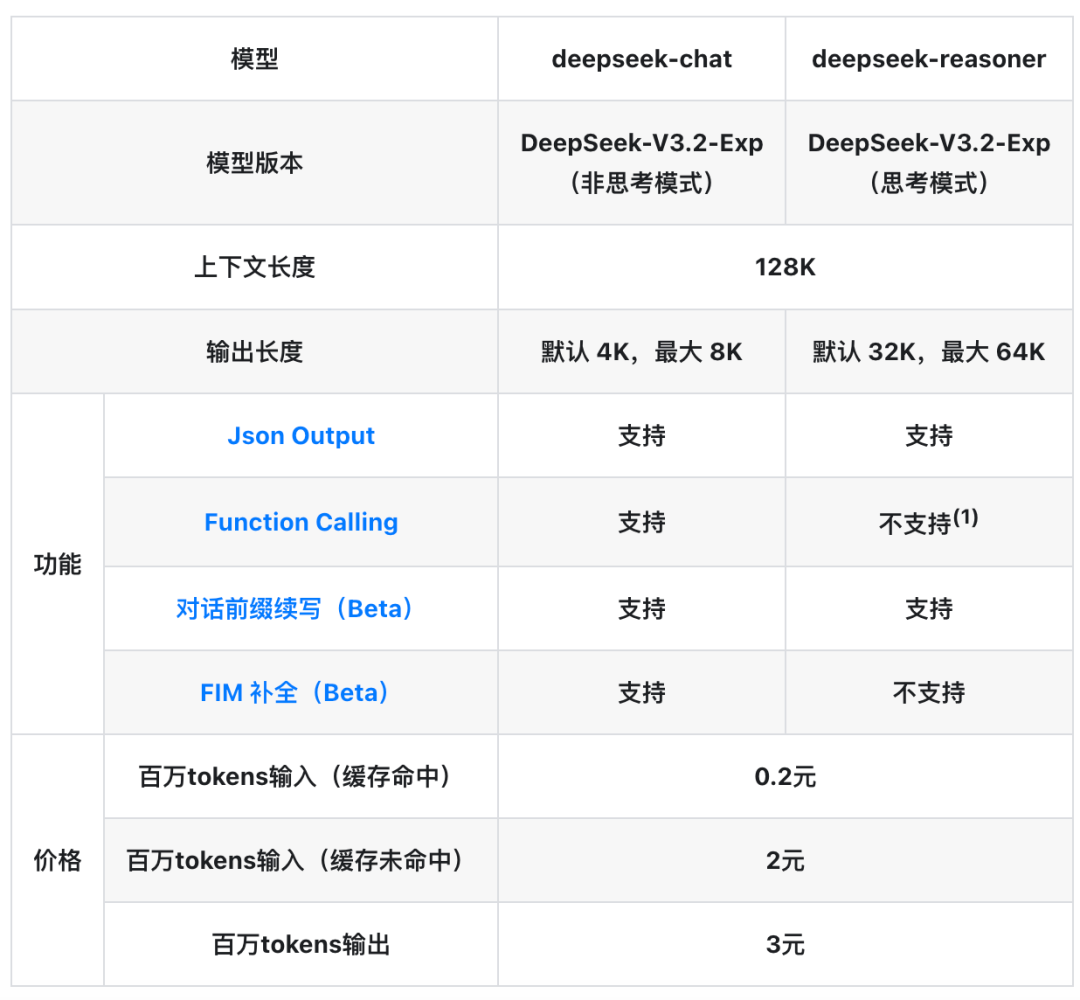
原因三:效果不好。参考 Dify 指定分段模式 :
即便部分大模型已支持上传完整的文档文件,但实验表明,检索效率依然弱于检索单个内容分段。
1.3 RAG 整体流程
参考 《极客时间》的《RAG 快速开发实战》的一张图:
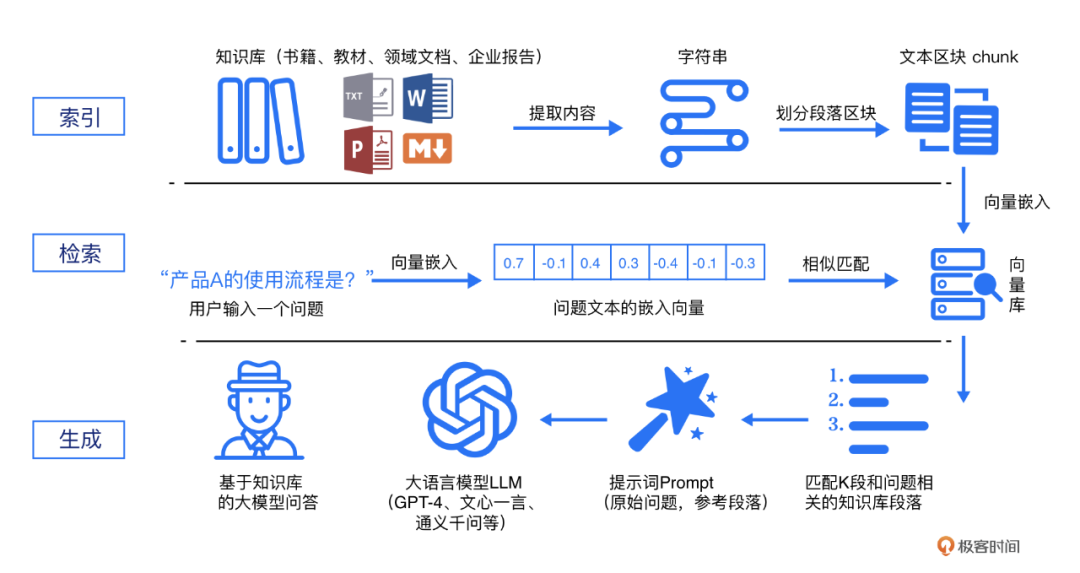
完整流程包括了:
- 数据清洗:上传 “专业领域知识” 文档,预处理内容(去除无意义的字符或者空行等)(这涉及到 ETL 的技术)。
- chunk 分块:把文档 “分块”(也成分段),切分成 chunk。
- Embedding 嵌入:把切分成chunk的内容 嵌入到向量数据库中(即)。
- 检索:根据用户提出的问题,检索向量数据库,查询出相关的专业领域知识。
- 生成:把用户提问的问题 和 专业领域知识 结合发送 给 LLM 大语言模型。
二、数据清洗
数据清洗的主要目的是:让原始知识文档变成 “干净可用” 的数据。这里会涉及到 ETL 的概念。
2.1 ETL
ETL 即 Extract(抽取),Transform(转换),Load(加载)。
- Extract 抽取:负责从不同的数据源系统中“拉”数据。
- Transform 转换:负责将原始数据转化为干净数据。
- 提取正文,去除 HTML 标签,脚注、目录页。
- 去除空行、控制字符、广告类文本。
- 规范化时间、单位。
- …… 等等。
- Load 加载:负责将处理好的数据导入目标系统。
在 LangChain 中,有各类 Loader,这些 Loader 则承担了 ETL 的职责。

在 Dify 知识库中,上传文件,参考 Dify 指定分段模式:
为了保证文本召回的效果,通常需要在将数据录入知识库之前便对其进行清理。例如,文本内容中存在无意义的字符或者空行可能会影响问题回复的质量,需要对其清洗。Dify 已内置的自动清洗策略。
三、chunk 分块
分块意味着如何把整个 “专业领域知识” 文档切分为一小个一小个的块(chunk)。
如何切分,chunk 的大小 等等都是需要讨论的关键话题。
3.1 chunk 的大小
把原始文档进行分块chunk的时候,第一个问题就是,chunk 的大小应该是多少。太大会导致检索不准,太小语义被切断,上下文丢失导致不准。并没有一个唯一的正确的标准。只能是根据各个场景的经验取值:
- 小 chunk(200 - 400 token,即 200-400个字):适合精确检索,FAQ,代码片段。
- 中 chunk(400 - 800 token):最常用,平衡了上下文和精确度。
- 大 chunk(800 - 1500 token):适合需要更多上下文的场景。
3.2 重叠部分的大小
重叠的设置可以有效的 防止信息被截断,保留上下文。一般建议是 chunk_size 的 10% - 20%,这些都是经验值。
3.3 文档拆分方式
例如通过段落边界、分隔符、标记,或语义边界来确定块边界的位置。
3.4 分块策略
3.4.1 固定大小策略
按照固定的字符数或 token 数,把文本均匀地切成若干块。每个块的长度几乎相等,不考虑句子或语义边界(这也是一个重要缺点)。某些场景下这种方式还是很有用的,比如:日志数据。
参考 LangChain 的定义:
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(
chunk_size = 500, # 每块最多 500 token
chunk_overlap = 50
)
chunks = text_splitter.split_text(long_text)
3.4.2 递归策略
递归即使用了一个分隔符优先级列表,(例如 ["\\n\\n", "\\n", ".", " ", ""]),
- 从第一个分隔符开始尝试(比如
"\\n\\n"),根据这个分隔符把文档切分成片段。 - 如果片段太大(超过 chunk_size),则递归地使用下一个分隔符(例如 “\n”)。
- 如果所有分隔符都尝试过,仍有片段太长,就直接按字符强制切割。
- 每个 chunk 之间可以保留一定的重叠部分(chunk_overlap),防止语义断裂。
参考 LangChain 的定义:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块最大字符数
chunk_overlap=100, # 块与块之间的重叠部分
length_function=len, # 长度计算函数(默认 len)
separators=["\n\n", "\n", ".", " ", ""], # 分隔符优先级
)
3.4.3 固定大小策略 vs 递归策略 对比:
原始文本:
LangChain 是一个用于构建基于大语言模型的应用的框架。
它提供了丰富的模块,用于实现对话、检索、工具调用等功能。
在 RAG 应用中,LangChain 可以帮助开发者轻松地实现文档检索与生成问答。
通过向量数据库(如 FAISS 或 Chroma),我们可以高效地管理知识库。
固定大小的分割:
chunk 1: LangChain 是一个用于构建基于大语言模型的应用的框架。
chunk 2: 应用的框架。它提供了丰富的模块,用于实现对话、检索、
chunk 3: 检索、工具调用等功能。RAG 模型是 LangChain 的一个重要
chunk 4: 一个重要应用方向。
递归的分割:
chunk 1: LangChain 是一个用于构建基于大语言模型的应用的框架。
chunk 2: 它提供了丰富的模块,用于实现对话、检索、工具调用等功能。
chunk 3: 在 RAG 应用中,LangChain 可以帮助开发者轻松地实现文档检索与生成问答。
chunk 4: 通过向量数据库(如 FAISS 或 Chroma),我们可以高效地管理知识库。
PS:为什么没有 overlap:
- 固定分块是 严格按长度切割 的,所以 overlap 一定会出现。
- 递归分块它是 按语义边界优先切割的。只有当文本 太长(超过 chunk_size)时,它才会进一步递归拆分,并在需要时才启用 overlap。换句话说:overlap 只会出现在「需要被硬切」的长 chunk 里,而不是每个 chunk 都会强制加。
3.4.4 其他的分块策略:

3.4.5 Dify 中的分块策略
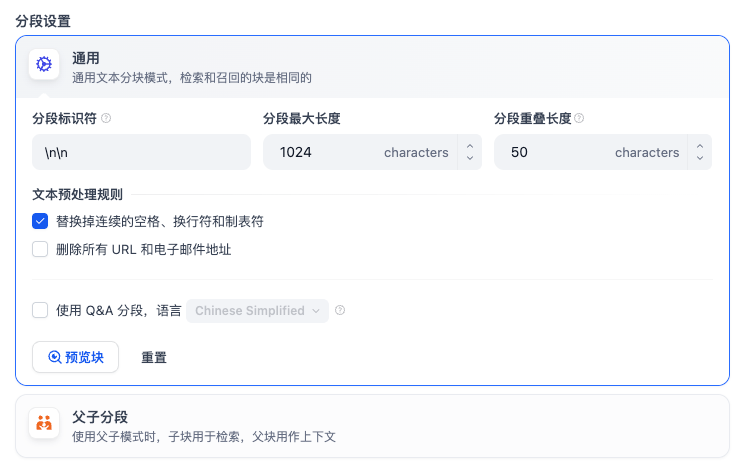
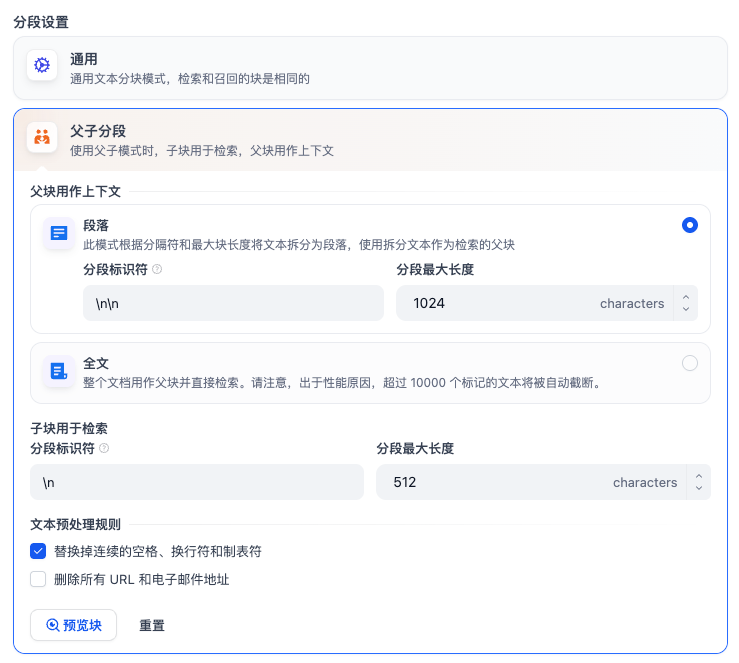
这里参考官方文档:指定分段模式。
- 通用分段:
- 将「问+答」作为一个完整单位切分(即 chunk)而非仅“按照段落”或“固定长度”切。
- 这里可以看到,分段标识符, 分段最大长度, 分段重叠长度 分别对应了之前的概念。
- 使用 Q&A 分段:当你的文档本身是“问题(Question)”-“回答(Answer)”对形式(例如 FAQ、知识库 Q&A 表格、客服常见问答)时,Dify 支持一个专门的分段方式,将每条“问 + 答”作为一个完整的 chunk。
- 父子分段:
- 父区块:保持较大的文本单位(如段落),提供丰富的上下文信息。
- 子区块:较小的文本单位(如句子),用于精确检索。
- 系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。
四、Embedding 嵌入
这里为什么叫 “嵌入到” 向量数据库中,不就是存入到数据库中吗?是为了显得更高级吗?
- 不是的。像保存到 MySQL,一般是把原始数据直接保存了。但是 RAG 这里的 Embedding 嵌入,强调了:Embedding(嵌入)= 把文本(符号信息)转换为向量(数值信息)的过程。 这样的一个转换过程。
另外对于 向量数据库,选择哪个,这里可以直接参考:
- 向量数据库 ranking。
- MTEB(Massive Text Embedding Benchmark)榜单。
五、检索
检索这里涉及到几个重要的概念:
- 全文检索。
- 向量检索。
- 混合检索。
- 重排序。
5.1 全文检索
全文索引是针对文本内容建立的索引,用于加速文本搜索。全文索引 = 对文本做分词 + 倒排索引 + 权重排序。举例:
有3个文档:
Doc1: 我喜欢猫
Doc2: 我喜欢狗
Doc3: 猫和狗都可爱
- 对文本做分词:
- Doc1 → [我, 喜欢, 猫]
- Doc2 → [我, 喜欢, 狗]
- Doc3 → [猫, 和, 狗, 都, 可爱]
- 建立倒排索引(倒排索引 = 从“词到文档”的映射):
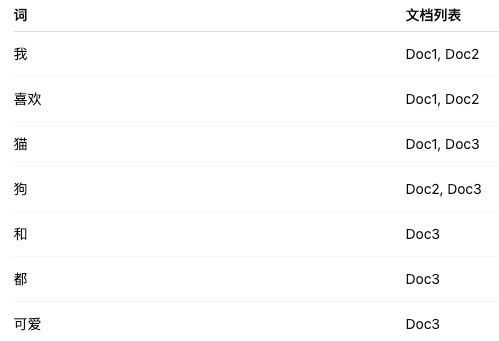
- 当用户搜索“猫” → 直接查表 → 找到 Doc1, Doc3
- 当搜索“猫 AND 狗” → 查 “猫” 得 Doc1, Doc3,查 “狗” 得 Doc2, Doc3 → 交集 Doc3
5.2 向量检索
向量检索 = 基于向量相似度查找最相关文档的过程。
- 核心:把文本、图片、音频等数据通过 Embedding 模型 转换为向量。
- 用户查询也转换成向量。
- 根据向量之间的 距离或相似度 找到最相关的数据。
5.3 混合检索
混合检索即 全文检索 + 向量检索。
核心思想:
- 全文检索:快速找到包含关键词的候选文档
- 向量检索:在候选文档中按语义相似度排序,找最相关的文档
这种方式的好处是:先用全文检索快速过滤大量文档 → 再用向量检索挑选最相关的文档。
流程:以用户提问为例:
-
用户查询 → “如何安装软件?”
-
全文检索:
-
检索出包含关键词 “安装” 或 “软件” 的文档集合
-
假设得到 100 条候选文档
-
向量检索 / 重排序:
-
把 100 条候选文档向量化
-
把用户问题向量化
-
计算相似度 → 排序 → 取 top-k 最相关文档
多路召回的概念
核心思想:用多个不同的策略同时召回候选文档,然后再进行排序。
混合检索 = 一种典型的多路召回实现(关键词 + 向量)
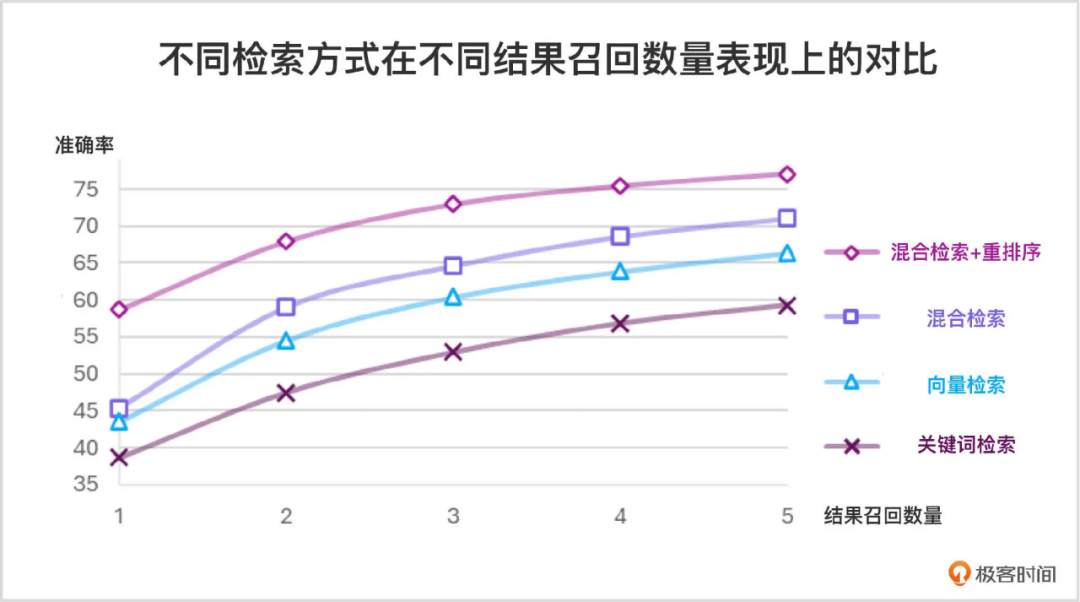
5.4 重排序
当从向量数据库中查询的时候,已经有了初步排序,为什么还需要重排序?
当在向量数据库里做检索时:
- 文本 → embedding → 向量
- 查询向量 → 计算相似度
- 返回 top-k 文档,按向量相似度排序
这样的排序:
- 向量相似度是单一指标:意味着 只考虑向量空间的语义距离,不考虑文本长度、完整性、关键词匹配度、文档权重、上下文匹配等。
- 语义相似度不完美:查询与文档虽然向量相似,但内容不完全匹配用户意图。
重排序的价值:就是在 向量数据库返回的 top-k 候选文档基础上,进一步优化排序,考虑更多信息。(例如结合多个信号:向量相似度 + 关键词匹配度 + 文档权重 + 文本长度等)
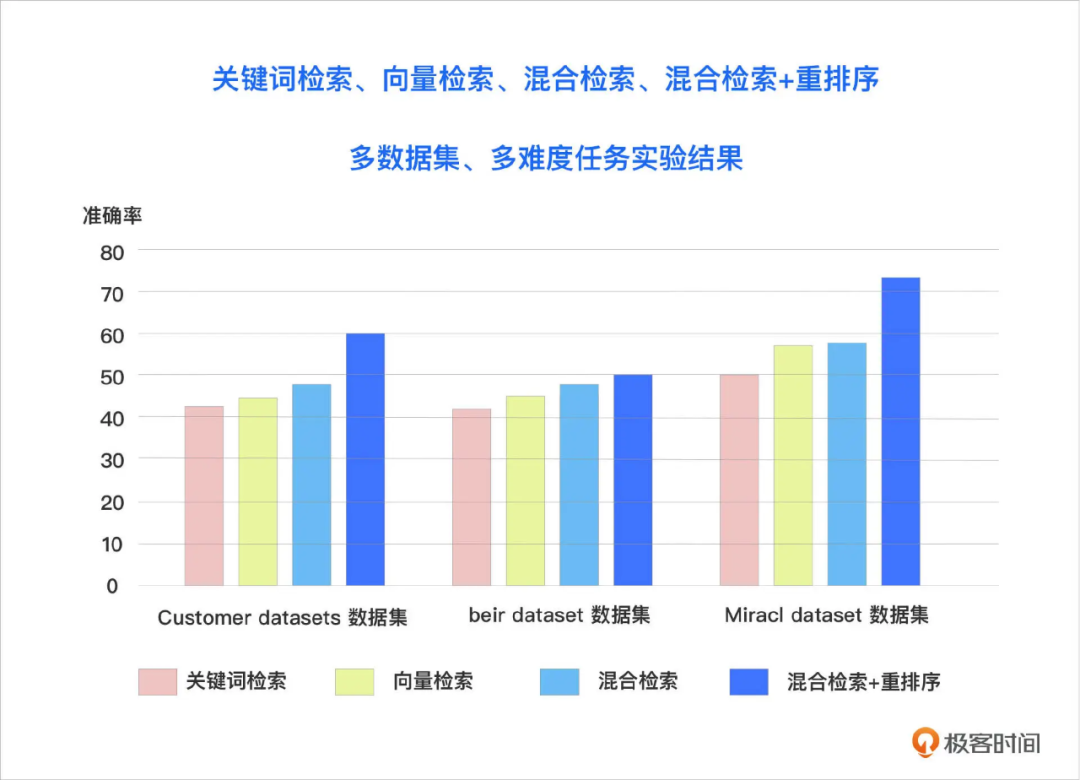
总结
- RAG 要解决的问题:LLM大语言模型专业领域知识不足。
- RAG 的整体流程: 数据清洗 → 分段 → Embedding 嵌入 → 检索 → 生成。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)