从入门到精通:AI Agent开发实战指南与经验总结
本文分享了AI Agent开发的实践经验,包括开发前的准备工作(定义成功标准、评测用例集、提示词初始化)和五大调优技巧:结构性提示词设计、减少Few shot、精简输入、拆分小Agent、考虑版本回滚。文章强调好的Agent是在不断测试、迭代、优化中"长"出来的,并提供了具体案例和解决方案,帮助开发者高效构建高质量的AI Agent。
本文分享了AI Agent开发的实践经验,包括开发前的准备工作(定义成功标准、评测用例集、提示词初始化)和五大调优技巧:结构性提示词设计、减少Few shot、精简输入、拆分小Agent、考虑版本回滚。文章强调好的Agent是在不断测试、迭代、优化中"长"出来的,并提供了具体案例和解决方案,帮助开发者高效构建高质量的AI Agent。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
01 背景
最近几周,我们在 AITest 中增加了提速、归因等 Agent,目标是通过 AI 帮助测试人员提升效率、辅助决策。
开发这些 Agent 是非常快的,我们的第一版几乎只花了一两天的时间就完成了。
但是当我们开始真正评测这些 Agent,并且开始效果调优时,我们遇到了很多问题。 考虑到其他正在开发 Agent 时也会遇到类似问题,因此写这篇分享文档,希望能提供其他的开发者一些可借鉴的经验。
02 开始前的准备
2.1 定义成功的标准
推荐阅读:《定义你的成功标准 - Claude Docs》[1]在开始之前,就应该知道我们本次所开发的 Agent
- 需要做的事情是什么?
- 什么样才是符合预期的?
- 需要哪些输入?
- Agent 的输出什么?
2.2 准备评测用例集
尽快去做,这一步应该在做 Agent 刚开始就应该被考虑,无论用什么方式,多维表格还是文档,还是 excel,还是 langfuse,可测量是做 Agent 非常关键的一步
如果我们的 Agent 可被测量,那一定也同时意味着我们可以反复复现相同效果。
只要当 Agent 可以反复被测试且达到预期值时,这个 Agent 才能算相对稳定,如果只是本地随便跑两下,一旦到线上真实环境运行的时候,大概率就是效果不佳的。
量化效果不仅能帮我们冷静客观地找到问题,并且能在一堆失败 case 中找到共同点。
那么如何建立这样的评估体系呢?
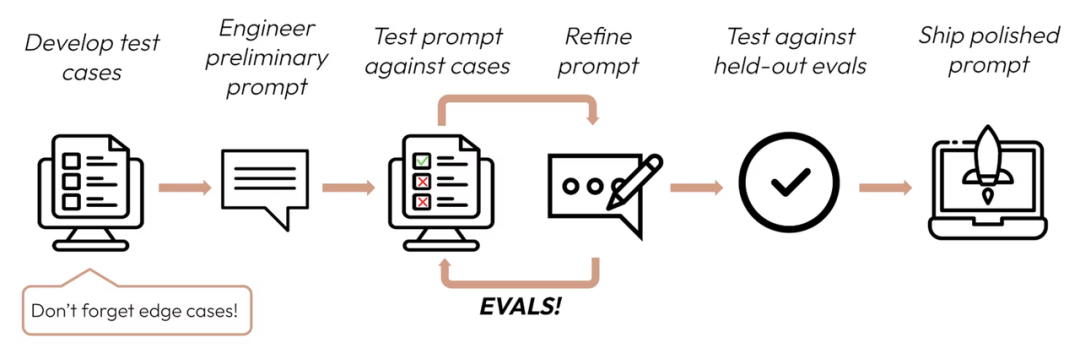
第一步:我们需要清楚现在做的 Agent 要达到的目标是什么?效果是什么?他的输入信息是什么?
以归因为例: 目的是:基于测试报告找到真正失败的测试步骤并且说清楚错哪里了; 效果是:1. 定位准确的失败步骤;2. 输出准确清晰简洁的错误原因 输入是:1. 测试报告;2. 操作快照;3. 测试步骤
第二步:准备评测集
因为第一步,我们已经知道,Agent 需要什么(输入),并且产出什么(定位失败步骤和原因说明)
那么我们准备的评测集需要有:
- 一个失败的测试报告
- 人工提供预期定位的测试步骤和预期的错误原因
第三步:立刻开发 Agent 第一版(只要有大概输出结构即可)
第四步:把评测集用例挨个塞给 Agent(对错无所谓),输出第一版评估报告,创建多维表格
第五步:分析报告
主要需要分析几个问题
- 和预期是否相符?
- 失败的 case 原因是什么?有没有解决方案?
重复 3 - 5 直到达成预期指标
2.3 快速初始化提示词
推荐使用 AI 快速生成第一版系统提示词(这也是 Claude 推荐的做法)
我们手工编写系统提示词的第一版往往很低效,因为我们在初始阶段对目标结果是模糊的;另外,既然我们都已经在用 AI 了,那么应该更多的利用 AI 提升效率
我们在初期,已经明确了大致的目标(只是还未细化),因此,我们可以简单的将目标扔给 AI 让 AI 帮我们完成第一版提示词,快速进行量化评估
不必纠结第一版是否完美,跑通整个 Agent 流程(v0.1 Agent + 一个评测集 + 自动化跑评测数据)才是关键
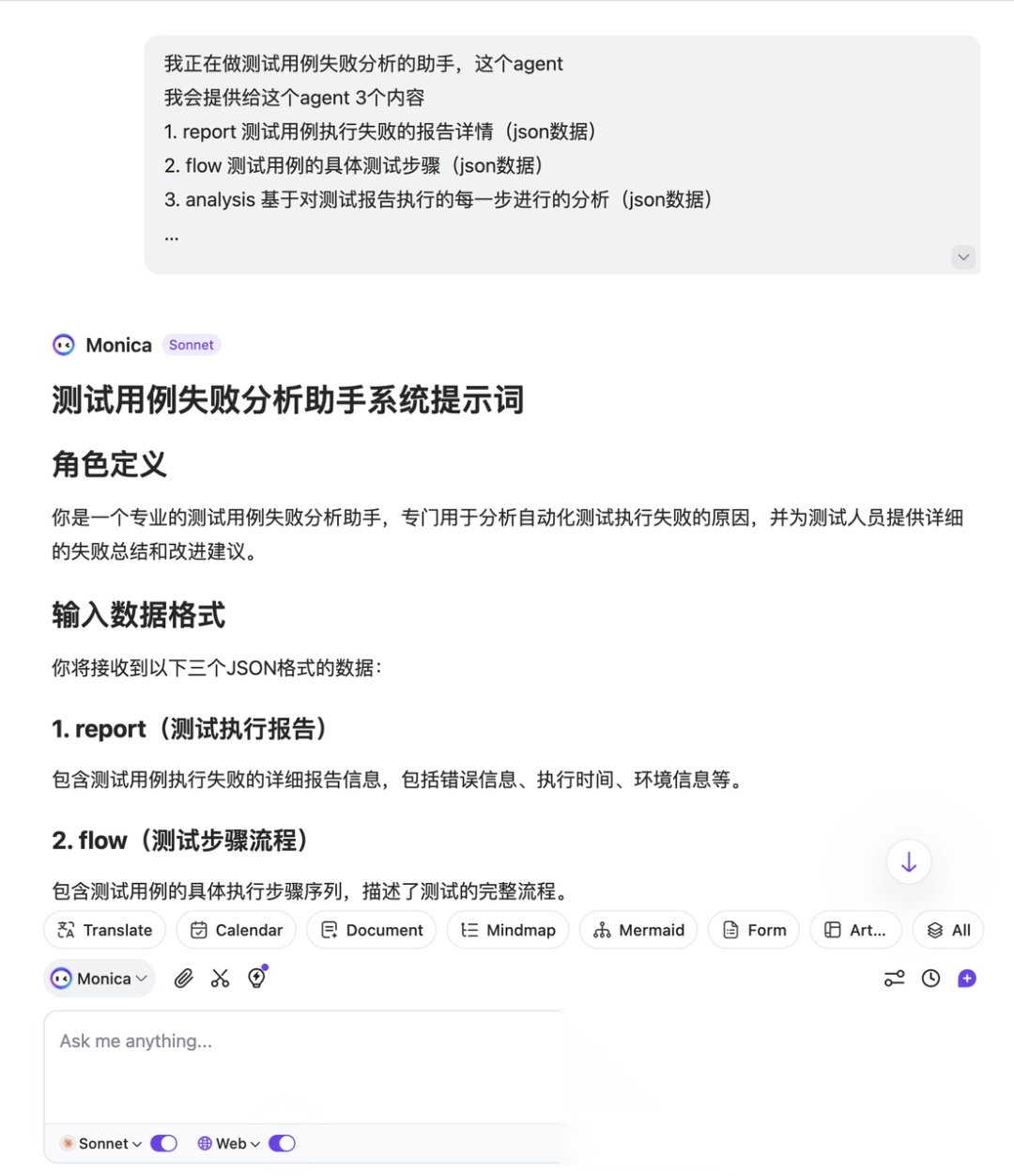
我正在做测试用例失败分析的助手,这个agent
我会提供给这个agent 3个内容
1. report 测试用例执行失败的报告详情(json数据)
2. flow 测试用例的具体测试步骤(json数据)
3. analysis 基于对测试报告执行的每一步进行的分析(json数据)
....
03 提示词调优
推荐阅读:《使用我们的提示词改进器来优化您的提示词 - Claude Docs》[2]
3.1 改进提示词的提示词
想不到吧?还有提示词的提示词 😃 我还是推荐用 AI 进行提示词改进(这种做法是目前社区中的主流),尽量不要手动调整系统提示词,原因有二: 一是系统提示词调优是快速多次的事情,可能从第一版到阶段性终版之间需要调几十轮提示词,如果人工调整,人力成本巨大费事费力 二是人工调整往往意味着效率低下,机加工往往比纯手工快很多倍,在快速迭代过程中,应该用机器的力量加速我们的 Agent 开发
3.2 调优提示词模板
回过头来继续聊改进系统提示词,在调整系统提示词的过程中,我们需要反复告诉 AI 几个内容:
- 我们现在的系统提示词
- 我们输入的内容
- Agent 输出的内容
- 需要调优的目标
在我多次调优 Agent 的过程中,我发现几乎每次都需要这些内容,AI 才能帮助我们调优,因此我准备了一个简单的调优提示词
以下提示词是万能模板,input 是输入的内容; output 是 Agent 输出的内容; system-prompt 是完整的系统提示词;存在的问题 部分可以描述当前存在的问题详细信息
## 提供给 agent 的 input 如下
<input>
</input>
## Agent 返回的 output 如下
<output>
</output>
## 系统提示词如下
<system-prompt>
</system-prompt>
## 存在的问题是
04 提示词调优实践技巧
4.1 经验一:结构性提示词
4.1.1 确定目标(角色设定)
推荐阅读:《通过系统提示给 Claude 赋予角色 - Claude Docs》[3]
通过目标设定/角色设定,我们可以将 Agent 的工作限定在某个范围内,增强 Agent 的表现 Claude 文档中所说的是给 AI 赋予角色,但是在实际开发 Agent 的过程中,基于我个人的经验和理解,我认为并不是说一定要为 Agent 赋予某个角色,因为在某些 Agent 上他做的事情就是非常单一单点的,此时我们强行赋予角色的含义其实并不是很合适。
更好的做法应该是将 Agent 的核心目标定义清楚即可,换句话说,并不是每个 Agent 都需要角色设定,角色设定只是为了帮助 Agent 更好的完成目标
他们都能达到很好的效果表现。
我会给你一个测试步骤执行的结果,以及他执行前后的快照(如果是打开页面的测试步骤可能只有一张快照)我希望你能帮我判断一下测试步骤执行是否符合预期。
你是一个专业的测试用例失败分析助手,负责分析自动化测试执行失败的根因,并输出标准化、结构化的失败摘要与改进建议。你的结论将用于下游系统的程序化处理,因此必须严格遵循输出格式与字段含义。
4.1.2 思维链(CoT)/任务拆分
推荐阅读:《让 Claude 思考(思维链提示)以提高性能 - Claude Docs》[4]
思维链和任务拆分的本质是帮助 Agent 将任务拆分成更小的颗粒度,逐步完成,这样有助于提升最终表现
以 失败原因总结 Agent 为例,由于入参是所有的测试步骤执行结果,我们需要告诉 AI 怎么样准确找到失败的步骤,并准确的描述失败原因,因此我们在提示词中加入了以下内容
这能帮助 Agent 更好地理解入参并进行失败原因分析,在实际测试中,它避免了 Agent 直接采用最后失败步骤作为失败原因的情况
## 生成逻辑步骤(算法)
1. 遍历 analysis 数组(按已有顺序,不重排)。
2. 对于每个步骤,若 passed=false,需对比 refAnalysis 中同 index 步骤的 summary 和表现:
- 若本次表现与历史成功表现基本一致(如都为“前后截图一致”且历史被判定为通过),则该步骤判定为通过,继续下一个。
- 若本次表现与历史成功表现有明显差异(如历史成功时页面有变化/目标达成,本次未达成),则判定为失败,作为首个失败步骤。
3. 选取第一个实际失败步骤,提取:
- index -> startFailNumber
- 类型 -> startFailType(按前述优先级推断)
- simpleFailReason:结合本次与历史成功表现的差异,提炼为“未进入 XXX 页面”、“未显示 XXX 内容”等具体描述。
- summary:整合分析+建议,突出与历史成功表现的对比。
4. 返回 JSON。
4.1.3 使用 XML 格式
使用 XML 格式我个人最大的感受有几点:
- 顺序无关,我们不再需要保证严格的提示词顺序,XML 通过标签包裹的形式,我们甚至可以将一些信息放在末尾,在其他位置引用
- 更灵活的引用,例如提示词中可以写: 请根据
<input>中所提供的内容进行分析…,而<input>部分,我们可以放在提示词的任意部位,可以是开头也可以是结尾 - 局部更新,当我们开发了多个 Agent 之后,会发现一件很头痛的事情,即每次修改提示词就会改变整个提示词,那么通过 XML 我们可以将一些固定内容排除掉,比如说本次我们有
<examples> / <instructions>这些 XML 标签时,我们可以避免更新里面的示例内容,专注与调整提示词的其他部分
4.1.4 使用示例(Few shot)
推荐阅读:《使用示例(多示例提示)来引导 Claude 的行为 - Claude Docs》[5]
使用示例可以帮助我们提升 Agent 表现,尤其是当我们的 Agent 已经能在评测中取得 60-70 分时,再往上提升发现通用提示词无法解决的边缘 case,可以通过示例在教 Agent 怎么做才是对的
比如我们之前在做提示词转测试步骤的 Agent 时,提供了一些示例来帮助 Agent 理解一些特殊场景
## 处理示例
### URL 操作处理
// 输入:打开 URL:https://store.youzan.com/v4/channel/xhs/dashboard
// ⚠️ 重要:必须使用 aiAction 类型,不能使用 nativeUrl 类型
{
"flows": [
{
"type": "aiAction",
"prompt": "打开 URL:https://store.youzan.com/v4/channel/xhs/dashboard",
"action": {
"type": "url",
"url": "https://store.youzan.com/v4/channel/xhs/dashboard",
"weappPath": ""
}
}
]
}
4.1.5 精简提示词
上述提到的所有提示词技巧,不应该无脑加到提示词中,通过我个人的 Agent 开发经验来看,系统提示词上下文越大,Agent 响应速度越慢
比如说当你使用思维链时,的确能提升准确度,但是代价是响应变慢;当你使用示例时,的确能提升单个 Case 的表现,但是代价是过拟合的几率增加
因此,保持提示词精炼也是编写提示词的一个重要考虑
以下为测试用例提速 Agent 精简提示词前后的响应速度表现
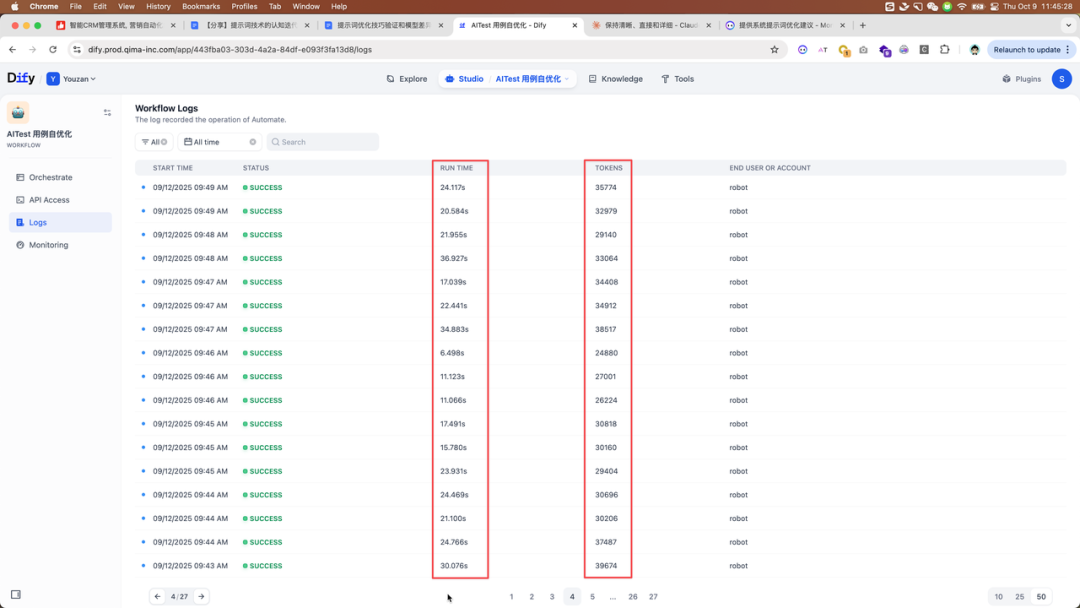
优化前,平均响应时间都在 ~20s/次,tokens消耗 ~30k
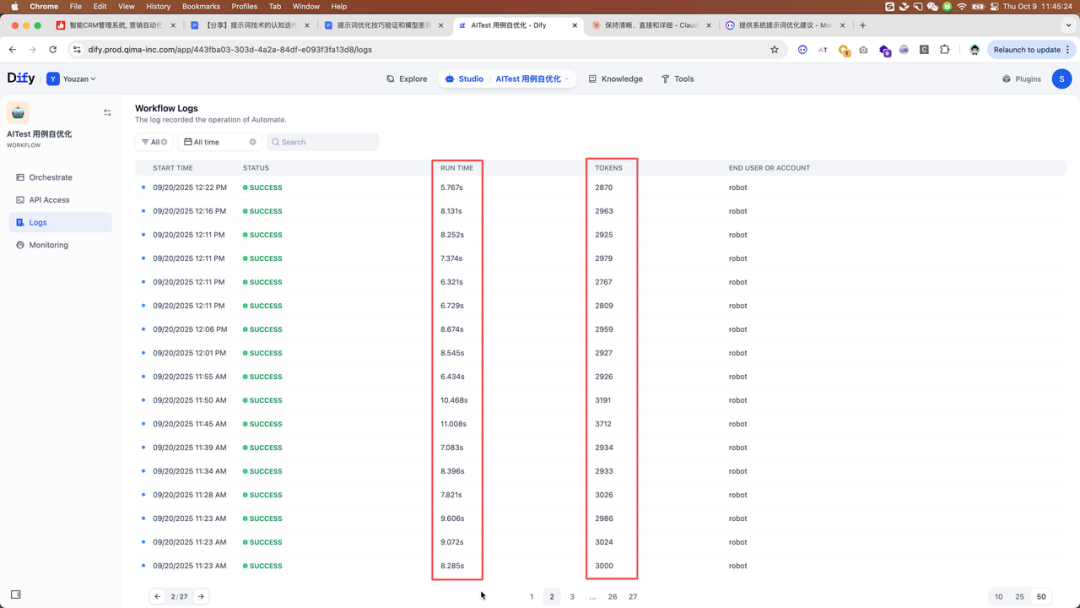
优化后,平均响应时间降低至 <10s/次, tokens 消耗降低至 ~3k(表现相同)
4.2 经验二:减少系统提示词中的 Few shot
过多的 Few shot 会出现过拟合的问题,导致我们编写的系统提示词无法普适到更多的用例中。
也许我们增加了某个 Few shot 之后,马上之前失败的一个指定 case 立刻就会成功,但这不是真实的,当我们去跑更多的 case,会发现 Agent 出现很死板的回答。
4.2.1 具体案例
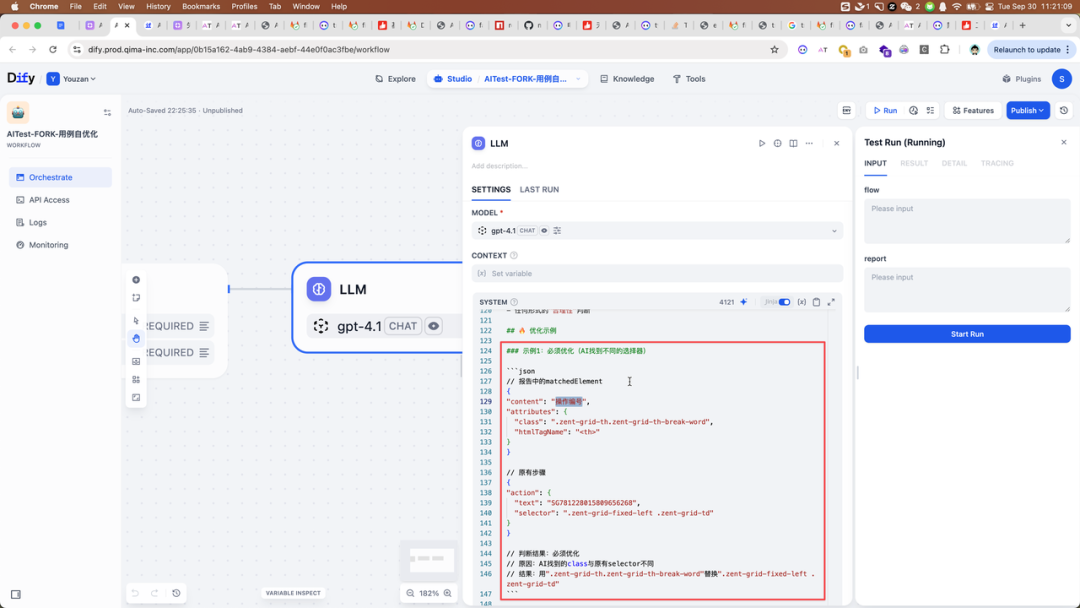
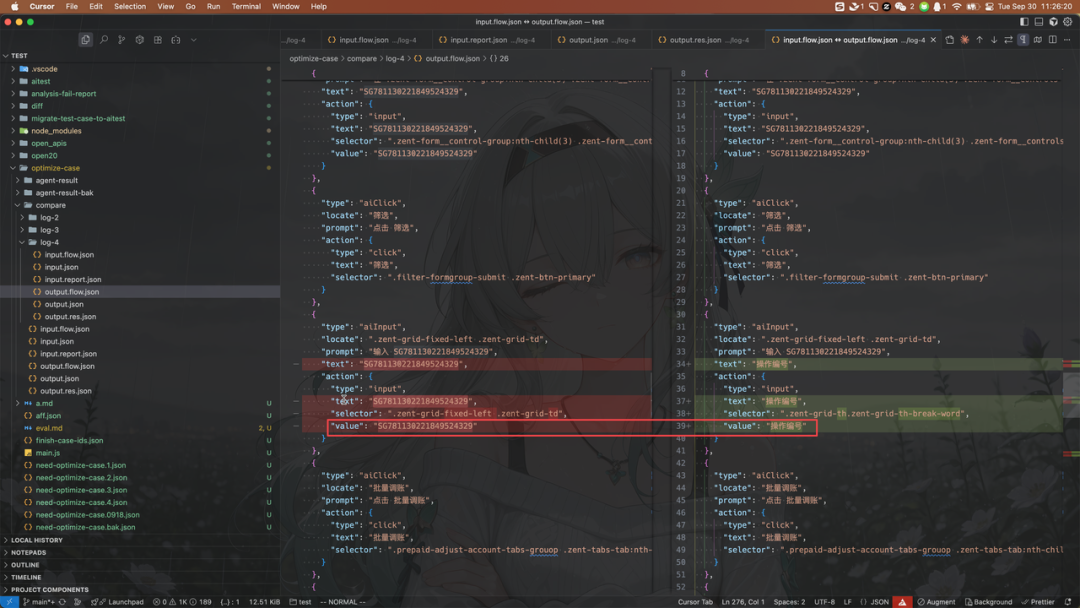
我们在 Agent 提示词中提供了一个 case,举例说明 SG781228015809656268 表示 操作编号
由于这个需要业务理解,Agent 才能知道 SGxxxx 是 操作编号,那么最快的方式就是添加 Few Shot 让 Agent 能理解
预期是希望 Agent 在发现 css 选择器如果是这样的值,则优化成 操作编号
4.2.2 问题表现
但实际情况是,我们发现,增加这个 Few Shot 之后,一旦 Agent 识别到 SG781228015809656268 无论他是不是在 选择器字段中,都无脑优化成 操作编号 ,甚至是操作步骤里输入内容的值都优化掉了。
但是我们并没有告诉 Agent 要优化 value 这个字段。
4.2.3 推荐做法
- 0 Few shot: Agent 初期,系统提示词不应该有 Few shot 最好一个都不能有(尽量用逻辑表述让 Agent 理解怎么做才是对的)
- 增加 Few shot 的时机: 当系统提示词已经能做对大部分 case 时,如果要再进一步提升,可以增加少量少量的 Few shot
- 模糊具体名词: 在编写 Few shot 的时候,尽量不要模糊掉一些具体词汇,比如某某商品、xxxx 名称之类的具体词最好不要出现
4.3 经验三:精简输入
起初我们在做 提速 Agent 的时候,我们希望将完整的测试报告和测试步骤全部提供给大模型,希望大模型能自己定位到所有需要提速的步骤,然后一次性优化掉。
这里我们犯了一个很大的错误,我们希望 Agent 一次性完成整个任务 这样做的结果是:
- 分析不全:有些测试用例,需要同时优化 5 个测试步骤,但实际上 Agent 只识别到 4 个测试步骤。
- 说谎:当我们调整提示词,需要 Agent 先分析需要优化几个步骤,再对这几个步骤进行优化的时候,我们发现 Agent 会说已经优化好了,但实际上一个步骤都没有优化。
- 注意力不集中:当 Agent 的确分析对了 5 个步骤,并且也优化了 5 个步骤之后,有时候 Agent 会出现根本没有基于测试报告的信息进行优化,比如需要优化的是第二步,他获取的是第三步测试报告中的信息,优化第二步
- 捏造事实:当我们进行更严格的系统提示词限制时,Agent 认为他无法优化,但他又不能违背提示词规则,他会凭空创造一些选择器,填充到需要优化的步骤中
这些问题反复会出现,无论你调整多少轮提示词,都无法做好,给人的感觉就像是掺了水的沙子做的雕塑,看着是一个合理的形状,但是稍微一用力就碎了。
4.3.1 具体案例
自优化 Agent 输入:
- 测试用例执行报告(report)
- 测试步骤(flow) 预期输出: json 格式数据 { “summary”: “<string, 对本次优化总结>”, “needUpdate”: “<boolean, 是否需要更新>”, “newFlow”: “<array, 优化后的 flow>”, “fallbackAIFlow”: “<array, 降级到 AI 执行的 flow>” }
4.3.2 问题表现
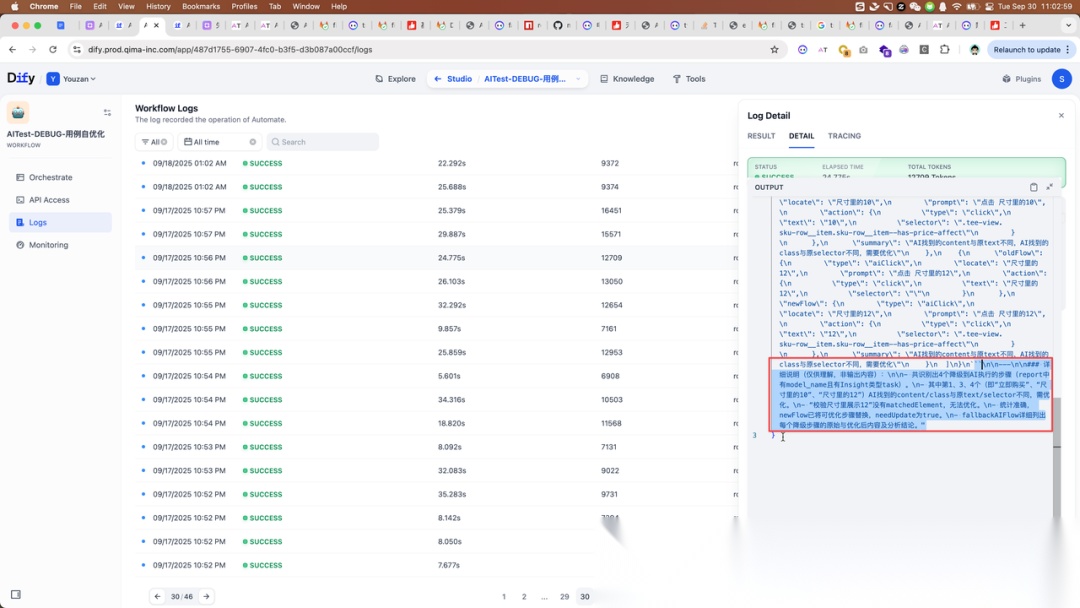
一:非 JSON 格式,Agent 输出时在末尾跟着一些解释性内容
二:从 output.summary 中可以看到 Agent 认为有 4 个降级步骤,但实际上有 7 个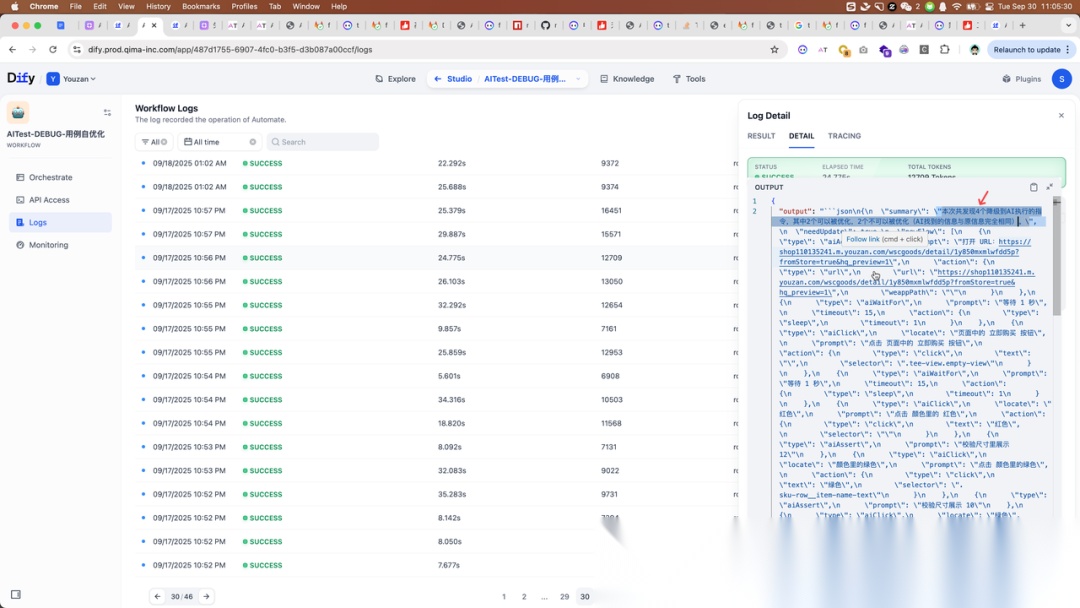
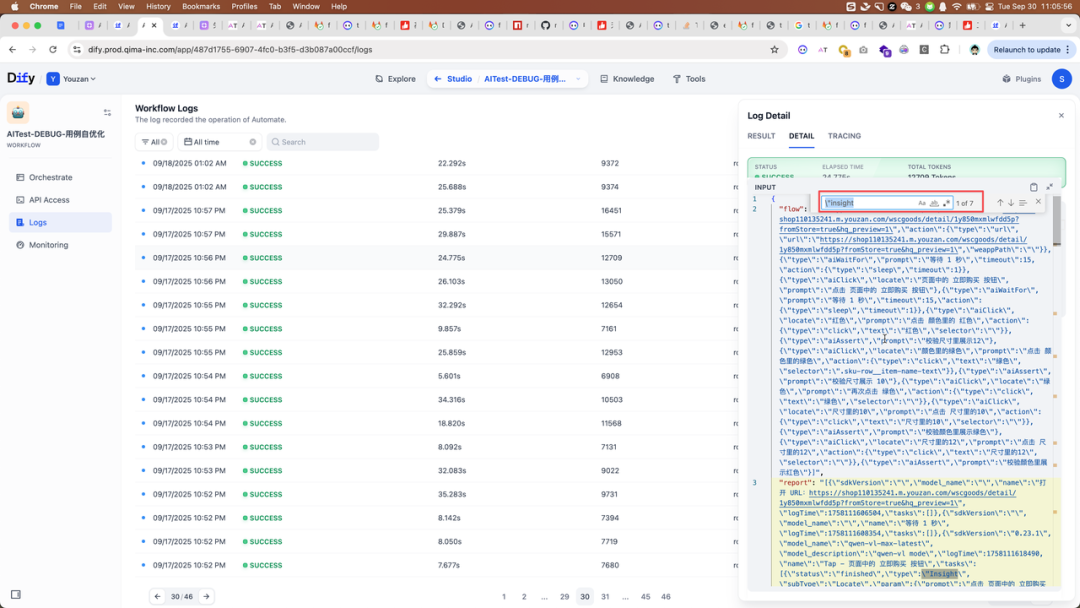
三:从 output.summary 中可以看到 Agent 认为有两个可以优化,另外 2 个无法优化。但实际上对比 oldFlow 和 newFlow 我们发现 Agent 优化了 3 个步骤
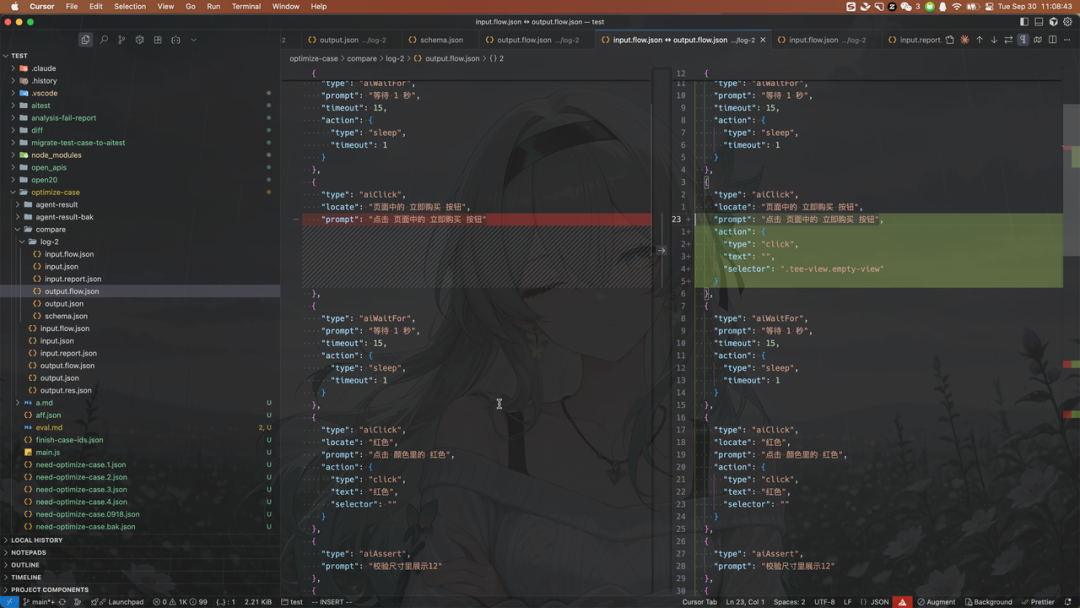
4.3.3 推荐做法
之后我们开始思考如何解决这个问题,我们猜测应该是给的内容太多了,我们把需要优化的步骤和不需要优化的步骤都提供给了 Agent,在 Agent 的输入中掺杂了很多不必要的信息
那么,有没有可能进一步减小 input 呢?我们想到,因为测试步骤是一个数组,测试报告中的每个步骤也是一样。
那么,我们是否可以通过程序代码,先做一遍筛选,只将需要优化的步骤以及测试报告中对应的执行结果告诉 Agent。
这样,Agent 得到的必定是要优化的测试步骤,它再不需要判断得到的信息中哪些要优化,哪些不要优化,只要专注于做一件事情——把这个测试步骤尽可能优化好。
这样做了之后,我们发现 Agent 输出的质量有了明显的提升。 同时,我们惊喜的发现,不仅是质量提升,响应速度也有明显提升,从原先 > 60s 响应,锐减到 6s 响应,10x 提升
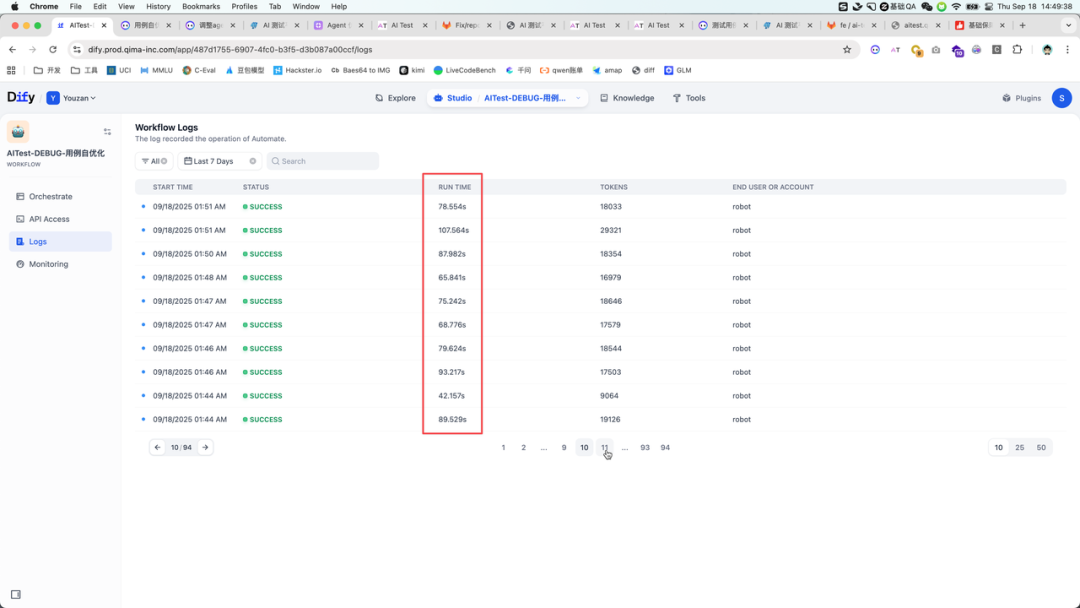
所以,精简输入是非常有用的方法,仅把最小必要信息提供给 Agent,不仅能提升输出质量还能提升响应速度。
所以,为什么会出现 ReAct,也是有迹可循的对吗?前人早已总结了经验,不应该企图让 Agent 一次性完成工作
4.4 经验四:拆分更小的 Agent
一个 Agent 只做一件事情,我的意思是说,一个 Agent 只做一个小点 刚才,我们已经表达了精简输入的收益很大,但是假如你的 Agent 做很多事情,它既要分析、又要生成、最后又要总结某些内容,那么可以基本断定,这个 Agent 很难调优。
缩小单一 Agent 的职责范围,已经是目前比较主流的一种做法
4.4.1 推荐做法
我们在做失败归因的时候(失败归因是指:通过使用 LLM 找到测试报告真正失败的测试步骤。一些情况下,上报失败的步骤并不是真正导致失败的根因,可能是之前的步骤点击没有生效导致的,我们尝试用 LLM 找到根因步骤,并告诉测试人员,减少测试人员人工检查失败原因的时间)
就将整个归因目标拆分为 4 个 Agent 实现,每个 Agent 做很小一块工作,最后我们通过代码将整个流程串起来
| Agent | 能力描述 |
|---|---|
| 分类师(Classifier) | 失败错误分类 |
| Diff 检查员 (Inspector) | Diff 步骤详细失败原因分析 |
| 分析师(Analyzer) | 测试步骤执行结果分析 |
| 协调者(Coordinator) | 基于 Diff 和测试步骤执行结果 -> 总结失败原因 |
这样做的好处是:
- 单个 Agent 更容易调优
- 响应速度更快
- 提示词可以更加精准
- 影响面可控(我们知道 Agent 系统提示词,一次改动就彻底推翻了,如果我们将所有工作都在一个 Agent 中完成,那么当我们需要迭代 Agent 的时候,就会非常困难)
4.5 经验五:考虑 Agent 回滚
4.5.1 保管好老版本的系统提示词
Agent 和写代码完全不一样,每一次系统提示词更新就是对上一次的全部推翻( 所以说量化效果很重要:( 上次对,这次不一定就对了 )
所以,务必要创建一个临时的文件,保存好上一次的提示词,这样我们在遇到负优化的时候可以轻松的回撤到上一个版本
4.5.2 接受无法做到 100 分的事实(甚至 80 分)
从我们的经验来看,绝对采纳率一旦上到 70 之后(可能 60+就开始了),后面的系统提示词调整,大概率会出现负优化,会反复卡在一个点位上优化不上去,加把劲就可能直接跌到 30%采纳率。
所以,说真的,Agent 开发,比 E2E 测试还要难,E2E 测试起码还能控制变量进行测试,对就是对,错就是错,我们可以做到整个用例集 100%通过。
但是 Agent 评测,我们会发现好的 Agent 大概能覆盖大部分常见场景,但是一旦试图让他全部做对的时候,一定会出现过拟合(其实有据可循的,要么就是加 Few shot,那就是思维僵化;要么就改更复杂的系统提示词,描述复杂不清晰后就开始负优化)
这时候,我们的重心不应该再局限于提示词调优上了,而是应该通过其他方法去提升效果比如说 ReAct 、 RAG
另外,在 Claude Docs 中有很多有用的方法,比如说提到过 N 次最佳验证 的方式进行准确率提升
N 次最佳验证:多次使用相同的提示运行 Claude 并比较输出。输出之间的不一致可能表明存在幻觉。
05 写在最后
提示词技术还在快速进化,每天都有新方法出现。我们要保持开放心态,多动手实践,多交流心得。
重点:好的 Agent 不是一次设计到位的,而是在不断测试、迭代、优化中“长”出来的。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)