Gemini 3.0 国内可用性全解析:零门槛、多模型聚合的最佳实践
随着大模型技术在 2024—2025 年的迭代加速,AI 已从专业技术圈走向大众,并迅速成为工程师和内容创作者的日常生产力工具。Gemini 3.0 的发布,再次将行业性能上限向前推动一大步 —— 推理更强、多模态更稳、代码生成质量接近真实开发者水平,在公开基准测试中甚至实现了“全维度领先”。
随着大模型技术在 2024—2025 年的迭代加速,AI 已从专业技术圈走向大众,并迅速成为工程师和内容创作者的日常生产力工具。Gemini 3.0 的发布,再次将行业性能上限向前推动一大步 —— 推理更强、多模态更稳、代码生成质量接近真实开发者水平,在公开基准测试中甚至实现了“全维度领先”。
但对于国内开发者而言,一个现实的问题却始终存在:模型访问受限、API 获取复杂、网络要求高。这让很多人虽然“看过很多测评”,却依旧无法真正上手 Gemini 3.0 的强大能力。
为降低这一门槛,社区中出现了新的解决方案 —— 通过浏览器侧边栏,将 Gemini、GPT、Claude、Grok、Sora 等国际主流大模型聚合在同一个本地界面中。无需繁琐配置、无需额外环境,就能直接体验多模型推理、文档解析、图片/视频生成等能力。
本文将从工程实践角度出发,展示这种方案的技术原理、实际体验效果,并基于 Gemini 3.0 的能力给出实测示例,帮助开发者在国内环境中以最低成本、最快速度体验真正的“新一代大模型”。
Gemini 3.0 国内可用性全解析:零门槛、多模型聚合的最佳实践
随着 AI 大模型从技术圈的“尖端黑科技”逐渐进入普罗大众的效率工具领域,Gemini 3.0 的出现无疑再次提升了行业上限。在推理、多模态理解、代码生成等关键方向上,它在公开基准测试中几乎全面领先,让 “用 AI 构建复杂系统” 成为真正可实现的事情。
例如此前的实测中,只需几行提示词,Gemini 3.0 就能在约两分钟内生成一个可交互的 MacOS 视觉仿真环境,系统内的 Safari 浏览器甚至可以正常打开页面:
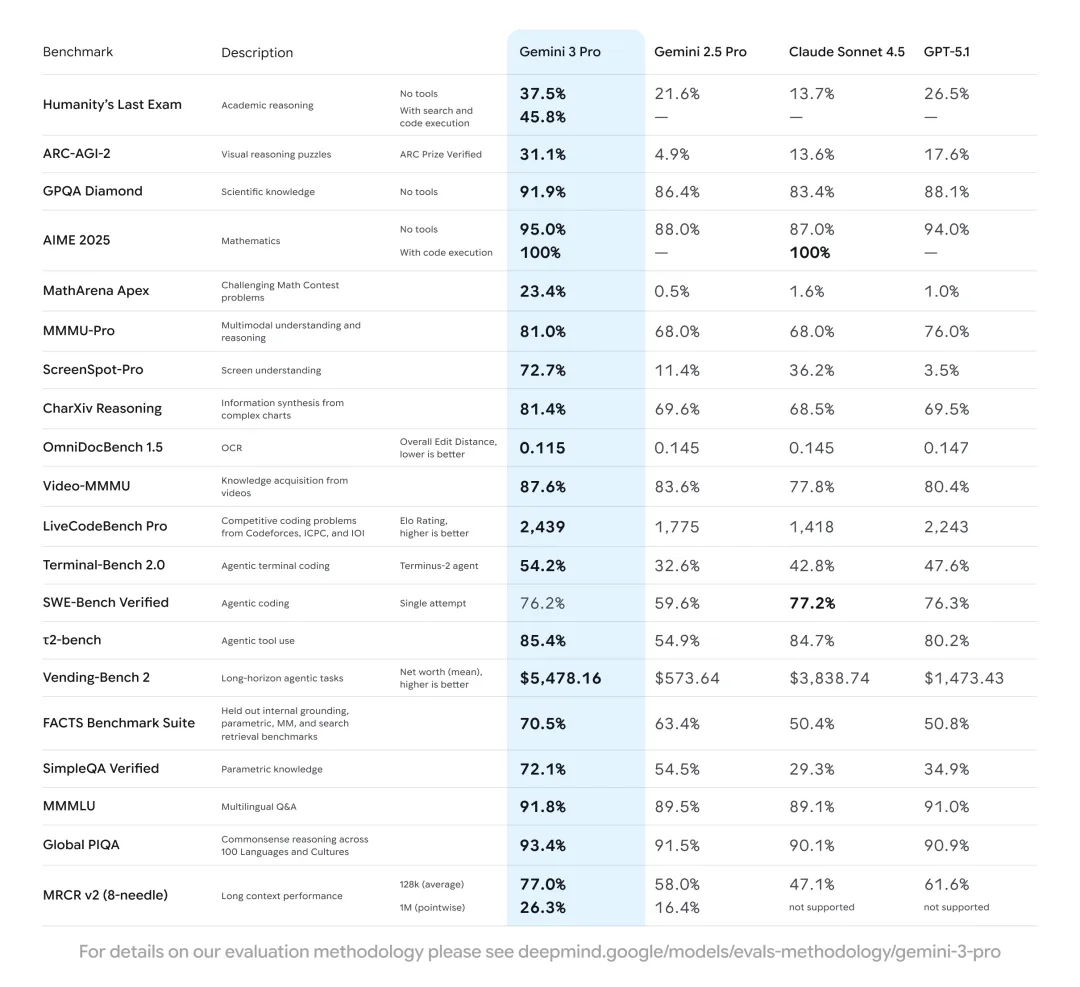
体验效果如下图所示,完整 UI 与操作逻辑几乎都被复刻:
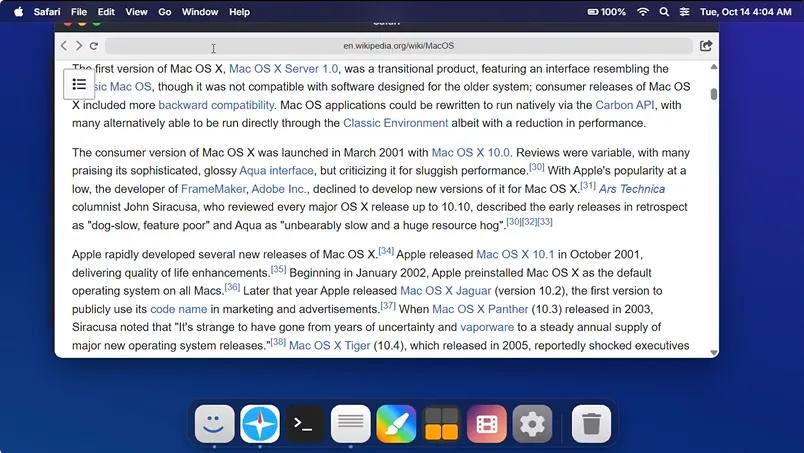
在社区中,开发者们利用 Gemini 3.0 构建了各种富交互项目:
如在线视频编辑器:
复刻的电脑版微信页:
无限刷短视频的 Web 应用:
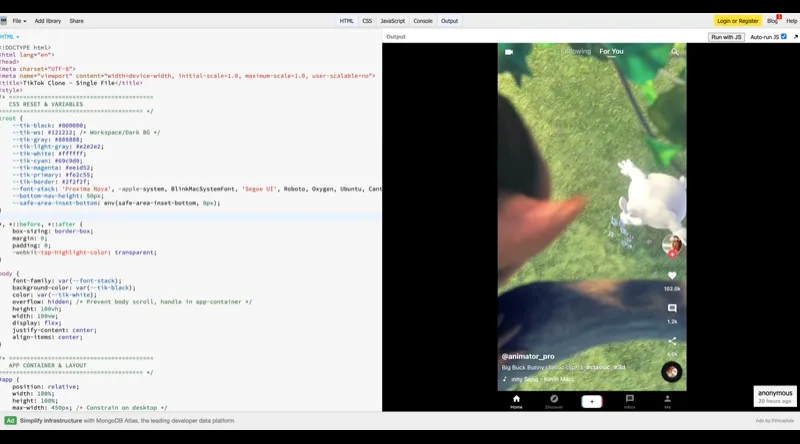
以及富文本冒险式小游戏:
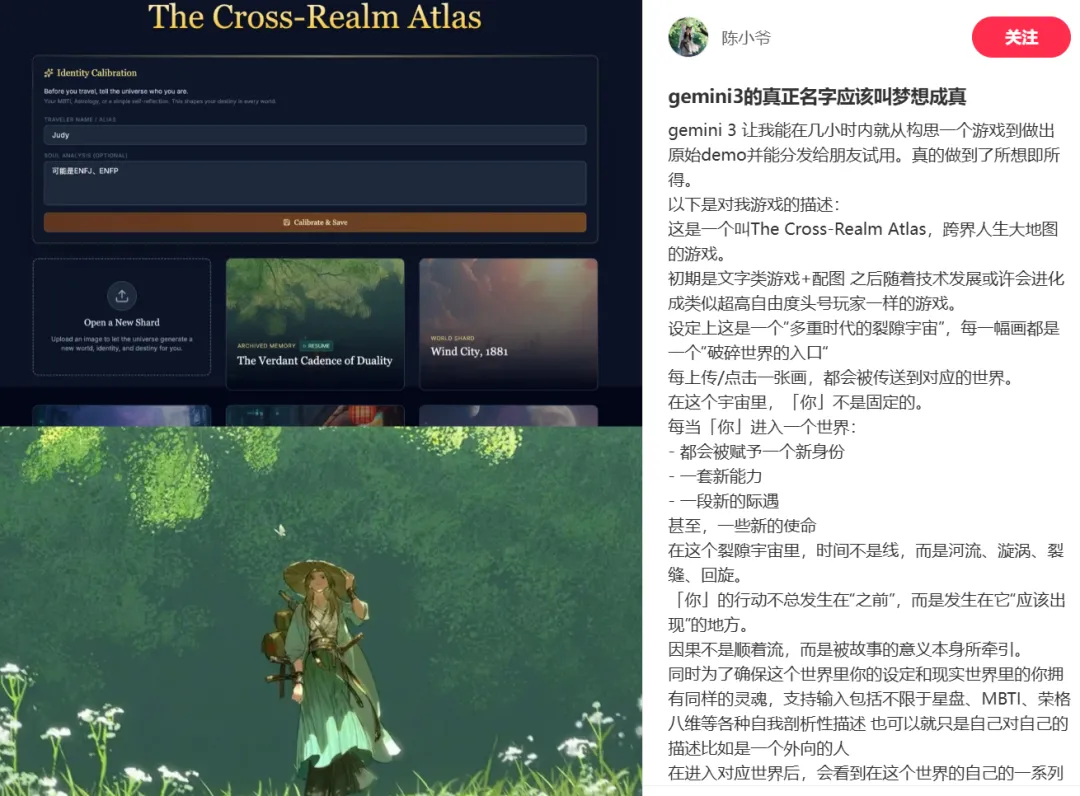
甚至包括带手势识别交互效果的网页 Demo:
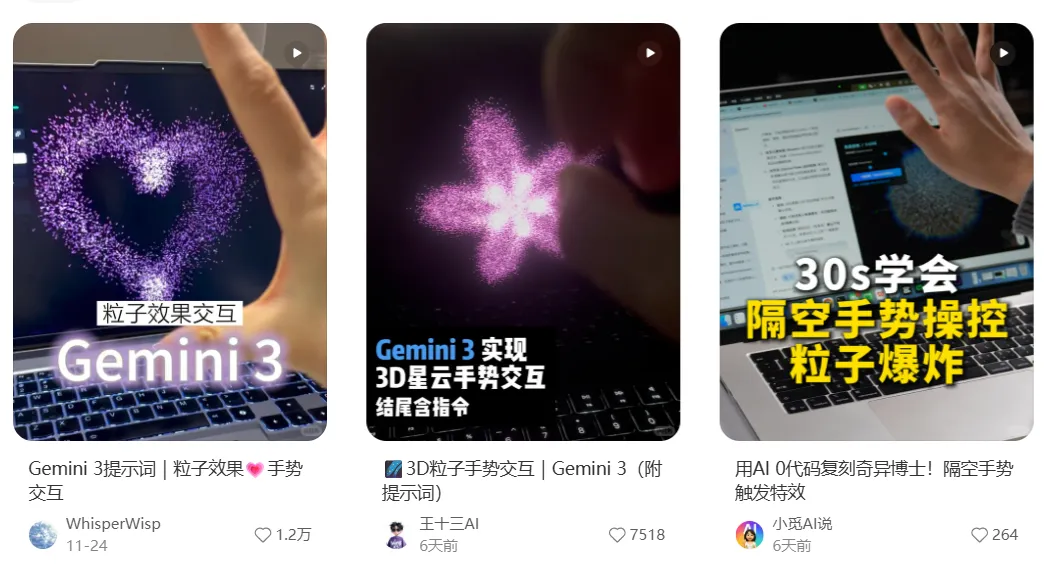
Gemini 3.0 的能力已经无可争议。但对于国内开发者来说,实际使用依然存在以下技术门槛:
- 模型官网访问受限
- API Key 的获取与调用流程较为复杂
- 部分模型需要稳定国际网络环境才能使用
因此,本文将聚焦一个核心问题:
在国内环境下,如何以尽量少的配置成本体验 Gemini 3.0 与其他多个顶尖模型?
为解决上述问题,有开发者社区做了一个技术整合方案 —— 通过浏览器侧边栏的形式,把主流大模型的能力聚合到本地浏览器中,减少访问限制与复杂安装步骤。
以下内容将基于此类技术方案,介绍其工作逻辑与使用方式。
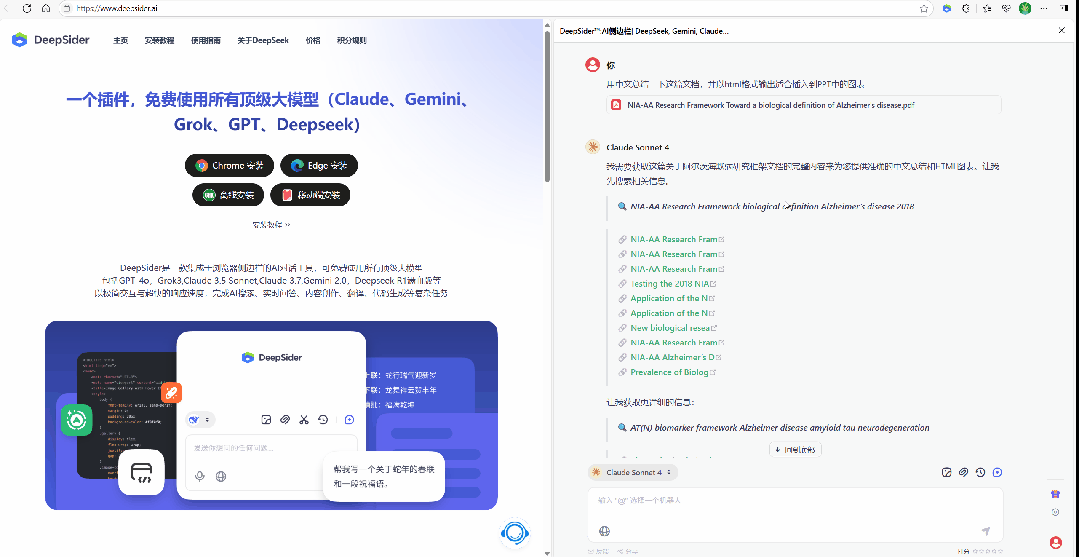
一、浏览器侧边栏模型调用方案的技术原理(以 DeepSider 类插件为例)
在现代浏览器(Chrome / Edge)中,扩展程序能够在侧边栏中加载本地 UI,并调用后台服务接口。
开发者通过这种方式将多个开放 API 进行了统一封装,使浏览器即可直接调用不同模型的推理能力。
从技术上讲,这一类插件的实现思路可拆解为:
-
前端界面
基于浏览器侧边栏渲染 Web UI,提供输入框、模型选择、文件上传等功能。 -
模型接口聚合层
通过后端代理实现多模型 API 的统一调用,包括 GPT 系列、Claude 系列、Gemini 系列等。 -
网络适配层
重点解决国内网络访问海外模型接口时的兼容性问题。 -
结果展示与本地集成功能
如代码高亮、文档解析、图片生成展示、视频生成结果预览等。
其优势是:
无需单独配置每个模型,也不需要国际网络环境,在浏览器内即可进行多模型推理。
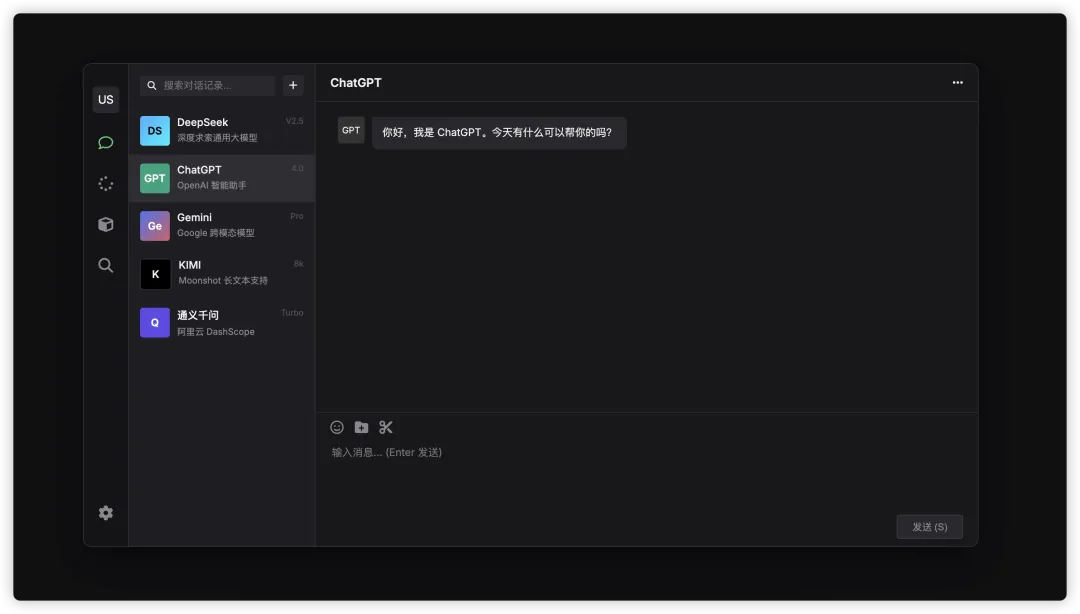
二、使用方式示例(基于浏览器侧边栏插件)
以下为使用过程中的截图说明,便于开发者理解其操作逻辑与界面。
1. 安装方式示例
以 Edge 为例,扩展程序可直接从浏览器商店获取:
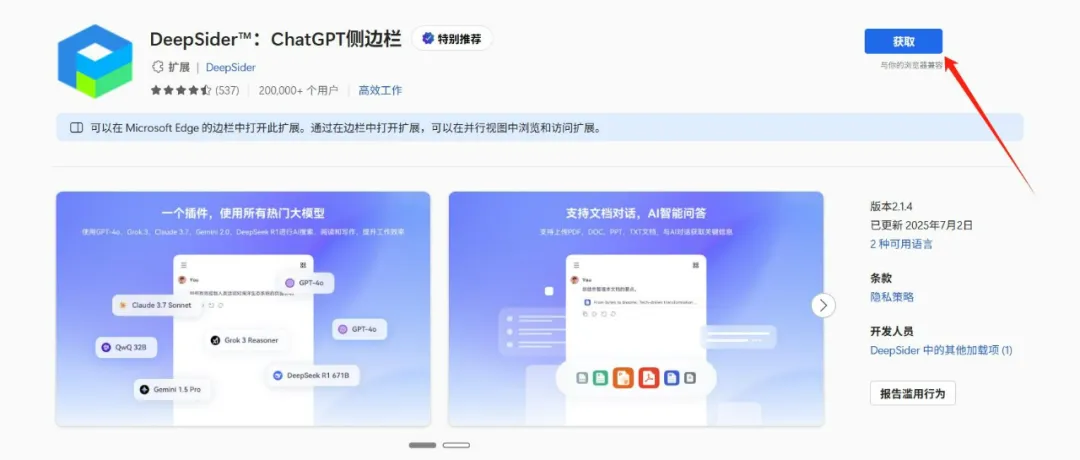
安装完成后,浏览器右上角即可呼出侧边栏窗口:
此时即可选择对应的大模型进行对话或文件解析。
三、Gemini 3.0 实际效果展示
在实测中,Gemini 3.0 Pro 能在几分钟内生成 1600+ 行的完整可运行代码:
例如经典的“小球碰撞模拟”案例:

Gemini 3.0 对需求理解准确,动画逻辑清晰,代码可直接在浏览器运行。
四、Gemini 3.0 的视觉能力:手写稿解析、文档结构理解
例如下面一份书写凌乱的手写文字,Gemini 3.0 Pro 也能准确解析:
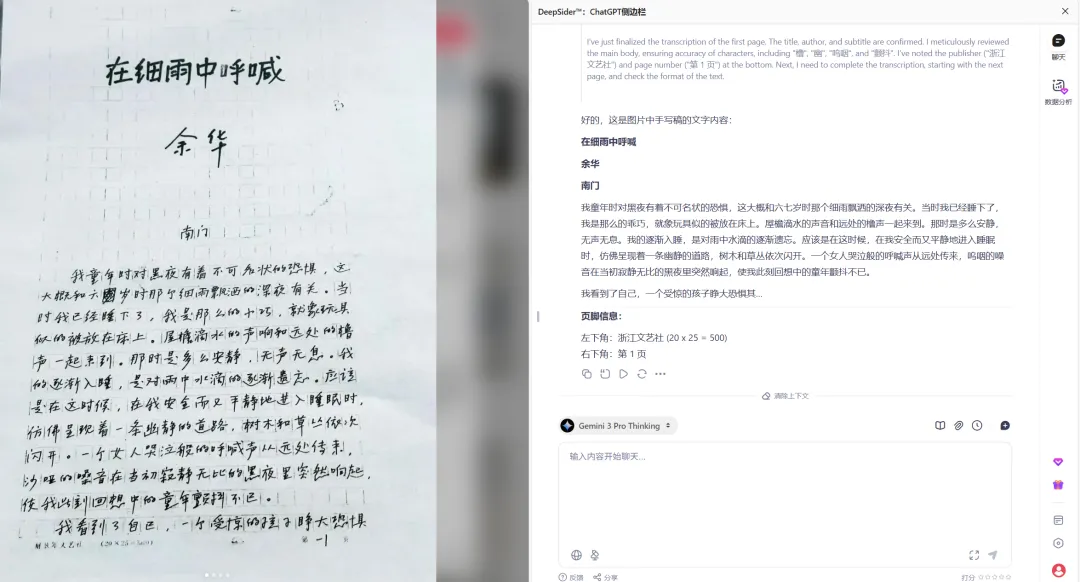
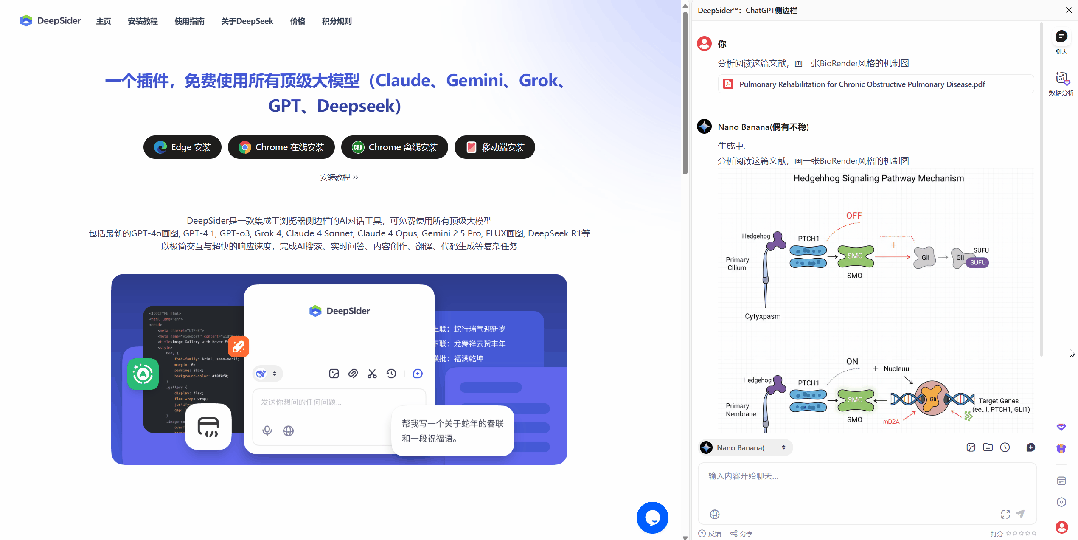
在科研场景中,它还能从英文文献中抽取结构化信息,用于生成科研绘图提示词:
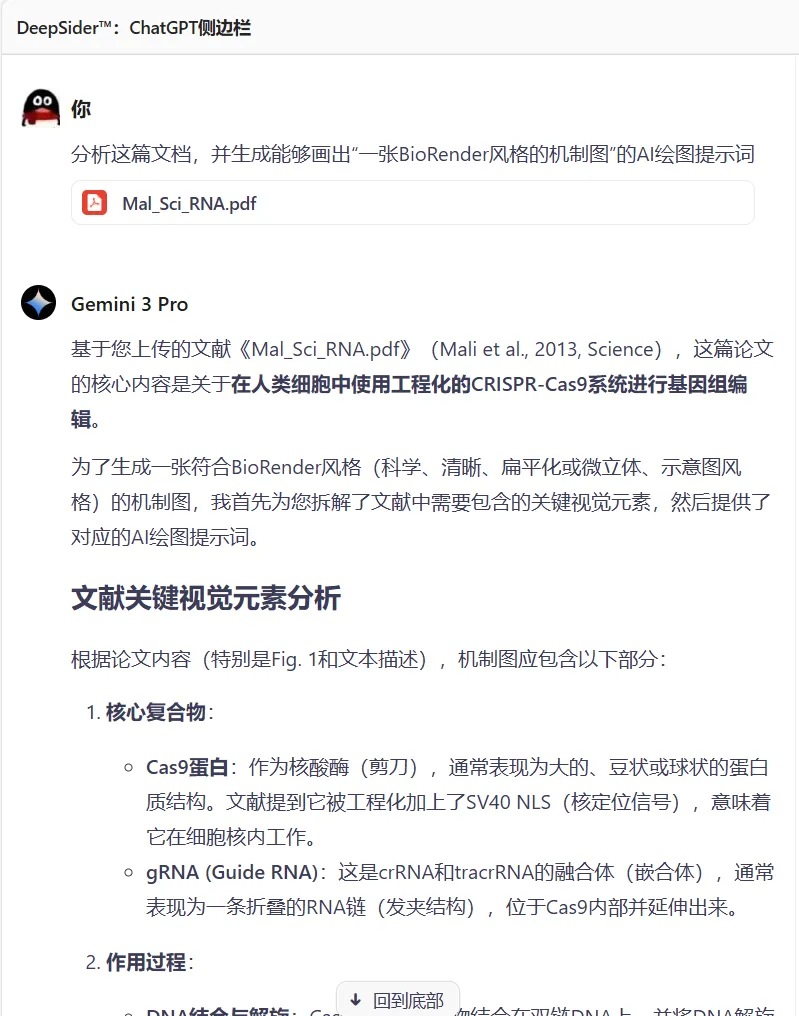
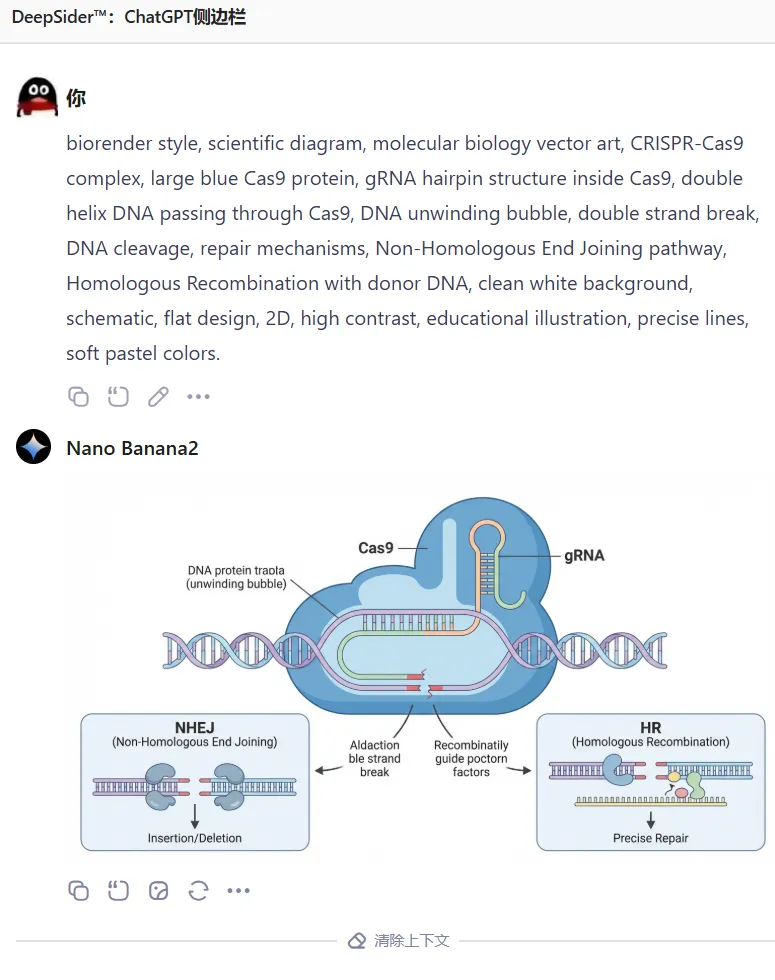
再交由图像模型(如 Nano Banana 2)即可直接产出科研图表:
五、侧边栏插件可调用的其他模型能力(示例)
除了 Gemini 3.0 外,侧边栏扩展还支持多种模型,例如:
- GPT-5、GPT-4.1 系列(含绘图、代码增强版)
- Claude 系列(Opus 等)
- Grok 系列
- Nano Banana 系列(高清图像)
- Sora 类视频生成模型(可生成 20+ 秒长视频)
模型选择界面如下:
可以在浏览器右侧直接一边浏览网页、一边使用模型:
六、文档解析、视频生成、图片生成等进阶功能
例如,使用视频模型生成广告片、故事片段、动漫短片:
图像模型用于生成影楼级照片:
也可自动生成科研图:
文档解析支持 PDF / Word / TXT 等:
网页总结功能示例:
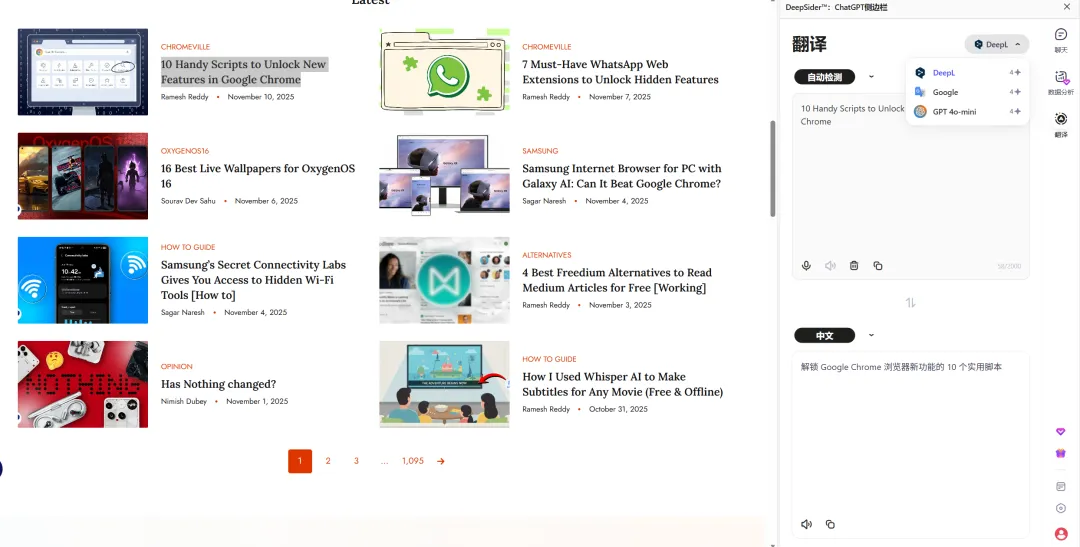
内置翻译功能(DeepL / Google / GPT 模型):
结语:更便捷的技术使用方式,而非替代官网
本文重点介绍的是一种 在国内环境下更容易体验多模型的技术手段:把大模型能力聚合到浏览器侧边栏,通过本地可访问的方式降低使用门槛。
核心价值在于:
- 不必为每个模型单独配置 API
- 不需要繁琐的国际网络环境
- 可在一个界面中快速切换模型
- 对开发者、科研人员、学生更友好
随着 AI 模型不断演进,工具链也越来越成熟。未来开发者只需要关注 “如何使用模型解决问题”,而不是“如何访问模型本身”。
Gemini 3.0 标志着新一代通用大模型正式进入“可用性与创造力并重”的阶段。它不仅具备强大的推理、多模态和代码生成能力,也开始真正能够构建可交互应用、解释视觉内容、辅助科研,并将复杂任务拆解为可执行的解决方案。
但更重要的是,通过浏览器侧边栏聚合模型的方式,国内开发者首次拥有了一种“低门槛、稳定、可扩展”的大模型使用路径。不需要复杂网络、不需要额外环境、不需要自行管理 API —— 打开浏览器即可体验世界顶尖 AI 的全部能力。
未来随着更多模型被接入、更多插件能力开放,这类方案很可能会成为国内工程师的“AI 工作台”。简单、直接、高效,也更符合当下 AI 工程化的趋势。
官网地址:deepsider.ai


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)