大模型的基础相关概念
技术领域解决的根本问题实现的商业价值比喻压缩技术“装不下”问题降低部署门槛,让模型能在现有硬件上运行给大象瘦身,让它能进普通房间高效架构“算不动”问题突破计算复杂度限制,处理更复杂任务重新设计大象的骨骼,让它更高效移动推理优化“用不起”问题降低服务成本,实现高并发低延迟优化大象的工作流程,让它服务更多人。
一、大模型的核心概念
1、大模型的基本概念
大模型是指拥有超大规模参数(通常在数十亿以上)和训练数据,并在通用任务上展现出强大能力的机器学习模型。通常是指大语言模型(Large Language Model,简写成LLM),是一种基于大量参数、大数据以及大算力的模型,这三点是大模型的基石。
- 大量参数:指模型的一些参数和超参数,这些参数是模型从数据中学到的“知识”的载体,参数数量越大,模型能存储和处理的信息就越复杂。从早期的百万级,发展到如今的千亿、万亿级。例如,GPT-3有1750亿参数。
- 大数据:指的是模型的生成是经过大量数据训练得到的,数据量可达TB甚至PB级别。
- 大算力:算力是驱动大数据和大量参数的“引擎”,主要用于训练和推理。训练一个大模型需要成千上万个高性能GPU/TPU持续运行数周甚至数月,成本高达数百万至数千万美元。
当模型规模超过某个临界点后,它会突然展现出在小型模型中没有的、不可预测的新能力,如复杂的推理、上下文学习、分步骤思维链等。通过“大力出奇迹”的规模化路径,让模型学习到一个极其通用的、世界的“知识表示”,然后通过微调或提示工程,可以灵活应用于下游无数具体任务(如翻译、摘要、对话、编程)。
2、大模型的核心框架(Transformer)
自注意力机制:Transformer最革命性的部分。它允许模型在处理一个词时,同时关注输入序列中的所有其他词,并动态计算它们之间的关联强度(权重),完美解决了长距离依赖问题。
计算关联权重主要是使用query向量、key向量、value向量这三个向量进行计算(每个词对应的query向量与其他词对应的key向量进行点积得到相关性分数、根据相关性分数与softmax函数进行标准化得到注意力权重,最终使用注意力权重对所有词的value进行加权求和得到最终该词的相关含义)
编码器-解码器结构:
- 编码器:用于理解输入文本(如BERT)。它将输入序列转换为富含上下文信息的“表示”。
- 解码器:用于生成输出文本(如GPT系列)。它基于编码器的输出和已生成的上文,逐个预测下一个词。
- 仅解码器架构:目前主流(如GPT、LLaMA)。它去掉了独立的编码器,直接用解码器同时完成“理解”和“生成”任务,结构更简洁高效。
位置编码:由于Transformer本身没有顺序概念,需要额外注入位置信息,让模型知道词的先后顺序。
- 量化Quantization:将FP16/FP32权重压缩成int4/int8以换取更低的内存和更快的推理。本质上是压缩。
- 蒸馏Knowledge Distillation:用来将大而强大的模型压缩成更小更轻便的模型,但尽量保持接近的能力。可以看作是从大模型中学习到一个小模型,本质上是训练
量化还是原先的旧模型,但蒸馏会产生新模型
3、大模型的训练框架
训练框架就是一套自动化、高效率的施工管理系统和工具,现在大模型训练主要依赖三大核心框架,他们提供从底层计算到高级抽象的工具链。
(1)Pytorch+生态系统
Pytorch以其动态图和直观的API成为研究和工业界的首选。其大模型训练能力主要是通过扩展库实现的。
其核心支柱有三个:
- PyTorch Distributed:提供
DDP和FSDP等原生分布式训练组件。 - Transformers (Hugging Face):提供了几乎所有制式大模型的架构实现、预训练权重和训练脚本,是事实上的模型库标准。
- Accelerate (Hugging Face):简化分布式训练代码,让用户能“一行代码”适配多GPU/多机训练。
它有两大核心扩展框架:DeepSpeed (Microsoft) 和 Megatron-LM (NVIDIA)。DeepSpeed的核心装新是ZeRO系列(解决数据并行中显存冗余的问题);Megatron-LM的核心创新为高效、定制化的张量并行与流水线并行实现。
两者结合,取长补短:用DeepSpeed的ZeRO-3管理数据和优化器状态,用Megatron的张量与流水线并行管理模型。这是当前训练超大规模模型(如BLOOM-176B)的黄金标准组合。
(2)JAX/Flax + 生态系统(Google系)
该训练框架是由Google主导,在TPU上具有原生又是,设计思想独特。其核心思想为:函数式纯函数(所有变换都是确定的,便于调试和并行)+即时编译(通过jax.jit将python函数变以成为高效的XLA内核)+自动并行(pjit等原语可声明式指定张量如何被分区,框架自动处理通信)
其主要框架有Flax(神经网络库);Optax(优化器库)。
代表模型有:PaLM,Gemini
(3)TensorFlow
早期大模型训练的主要框架,目前在一些特定场景(如Google内部、多模态模型)仍有应用。
-
代表性框架:Mesh TensorFlow,专为分布式训练设计。
-
现状:生态系统活跃度被PyTorch超越,但在部署和边缘端仍有优势。
4、大模型的并行策略
并行策略就是如何组织GPU,分工协作完成庞大工程的方法论。其核心目标是:将一个巨大的模型和数据集,拆分到成千上万的GPU上的协同计算。主要有4中基本策略,通常组合使用。
(1)数据并行
思想:复制整个模型到每个GPU上,每个GPU处理不同的数据批次,计算梯度后同步聚合。
通信内容:梯度或模型参数(同步时)。
优点:实现简单,是扩展批大小的标准方法。
缺点:每个GPU需要存储完整的模型副本,显存成为瓶颈。无法训练比单个GPU显存大的模型。
代表技术:PyTorch DDP, DeepSpeed ZeRO-1/2。
(2)模型并行
思想:将单个模型的不同部分放置在不同的GPU上。一个批次的数据需要依次流经所有GPU。
分类:
-
流水线并行:按“层”切分模型。如将一个24层的模型分成4段,每段6层放在一个GPU上。像一个工厂流水线,不同GPU同时处理不同批次的数据。
-
挑战:存在“流水线气泡”,部分GPU会空闲等待。
-
优化:GPipe(引入微批次), PipeDream(更复杂的调度)。
-
-
张量/模型并行:按“层内维度”切分单个层的运算。如将大权重矩阵的运算拆分到多个GPU上。
-
例子:将注意力头的计算或前馈网络的矩阵乘进行拆分(Megatron-LM的核心)。
-
通信量巨大,通常在节点内(NVLink高速互联) 使用。
-
优点:可以训练远超单卡显存的模型。
缺点:实现复杂,通信开销大,对计算图有侵入性
(3)混合并行
这是训练千亿级模型的实际标准,是上述策略的三维组合。
三个维度:
-
数据并行:跨节点复制多个完整的“模型副本组”。
-
流水线并行:在节点间将模型按层切分。
-
张量并行:在节点内(多卡) 将单层模型进一步切分。
工作流程:
-
假设我们有64张GPU(8个节点,每个节点8卡)。
-
张量并行:将1个模型层拆分到1个节点的8张卡上(小组)。
-
流水线并行:将整个模型拆分到4个节点上,每个节点负责模型的一部分(一段)。
-
数据并行:剩下的 4个节点 作为另一个副本组,处理不同的数据。这样总共有 2个数据并行组。
-
最终形成
数据并行(2) x 流水线并行(4) x 张量并行(8) = 64 GPUs。
| 场景与目标 | 推荐策略 | 说明 |
|---|---|---|
| 模型较小(<10B), GPU较多 | 纯数据并行(DDP/ZeRO-2) | 实现最简单,效率高。 |
| 模型较大,单个节点放不下 | 数据并行 + ZeRO-3 | 优先尝试ZeRO-3,它比纯模型并行更简单。 |
| 模型极大(>100B) | 3D并行(Megatron+DeepSpeed) | 行业标准,需要精细调优。在节点内用张量并行,节点间用流水线并行,再用ZeRO管理数据和优化器状态。 |
| 处理超长序列(>32K) | 序列并行 + 张量并行 | 将长序列的维度也进行切分。 |
| 追求极限训练速度 | 纯张量/流水线并行(Megatron) | 减少数据并行带来的梯度同步开销,但需要大量定制化。 |
二、大模型的分类与选择
1、大模型的分类
| 分类维度 | 主要类别 | 核心特点与训练目标 | 选型建议 | 代表模型 |
|---|---|---|---|---|
| 架构与训练目标 |
自回归 模型 |
训练目标:预测下一个词(因果语言建模)。 特点:单向上下文,擅长生成。 |
需要创造新内容的时候选择该类模型 | GPT系列、Llama、Mistral |
| 掩码语言模型 |
训练目标:预测句子中被掩盖的词(掩码语言建模)。 特点:双向上下文,擅长理解。 |
需要分析、理解或提取文本特征的时候选择该类模型 | BERT、RoBERTa | |
| 编码器-解码器 |
训练目标:将输入序列转换为输出序列(序列到序列)。 特点:兼顾编码与生成。 |
需要翻译、文本摘要、问答等将一种序列转化成另一种序列的时候 | T5/FLAN-T5、BART | |
| 模态 | 纯文本模型 | 处理和理解文本信息。 |
所有基于文本的任务 任务仅涉及文字时由县考虑,其效率最高生态最成熟 |
GPT-3.5, LLaMA-2 |
| 视觉模型 |
分为理解型和生成型 理解型:看图片输出标签 生成型:根据文字输出图片 |
图像分类、目标检测等需要处理或生成图片的时候选择 | YOLO, DALL-E (生成) | |
| 语音模型 |
分为识别型和合成型 识别型:语音转成文字 生成型:文字转成语音 |
语音识别、合成的报告需要处理或生成语音时进行选择 | Whisper, VALL-E | |
| 多模态模型 | 同时处理和关联文本、图像、音频等多种类型信息。 | 任务需要同时理解和关联多种信息(如图文结合)时选择。这是当前最前沿的方向。 | GPT-4V, Llama 4 (支持图文) | |
| 用途与能力层级 | 基础模型 | 经大规模预训练,拥有通用知识,但未针对指令优化。需要指令微调。 | 如果你想从头打造一个专属应用,并拥有高质量领域数据,可选它作为基底 | LLaMA-2 Base, GPT-3 Base |
| 指令微调模型 | 在基础模型上,使用指令数据微调,能更好理解并遵循人类指令。 | 如果你想要一个开箱即用的智能对话或创作助手,应直接选择此类模型。 | ChatGPT, LLaMA-2 Chat | |
| 工具增强/Agent系统 | 模型具备调用外部工具(搜索、计算器、API)的能力,以完成复杂任务。 | 当任务需要获取实时信息、执行精确计算或操作外部软件时选择。 | GPT-4 with Tools, AutoGPT | |
| 部署形态 | 云端API | 模型部署在提供商服务器,通过接口调用。优点:易用、免运维。 | 快速集成、验证想法或应用无高隐私要求的时候的首选 | OpenAI API, 文心一言API |
| 本地推理 | 模型部署在自有服务器或计算集群。优点:数据安全、可控性强。 | 对数据隐私要求高的企业应用 | 本地部署的 Llama 2, ChatGLM3 | |
| 边缘设备 | 模型经压缩后部署在手机、IoT设备等。优点:低延迟、隐私保护。 | 在智能手机、汽车、IoT设备上需要实时AI功能的场景选择。 | 手机端的 TinyLLaMA |
2、大模型的选择
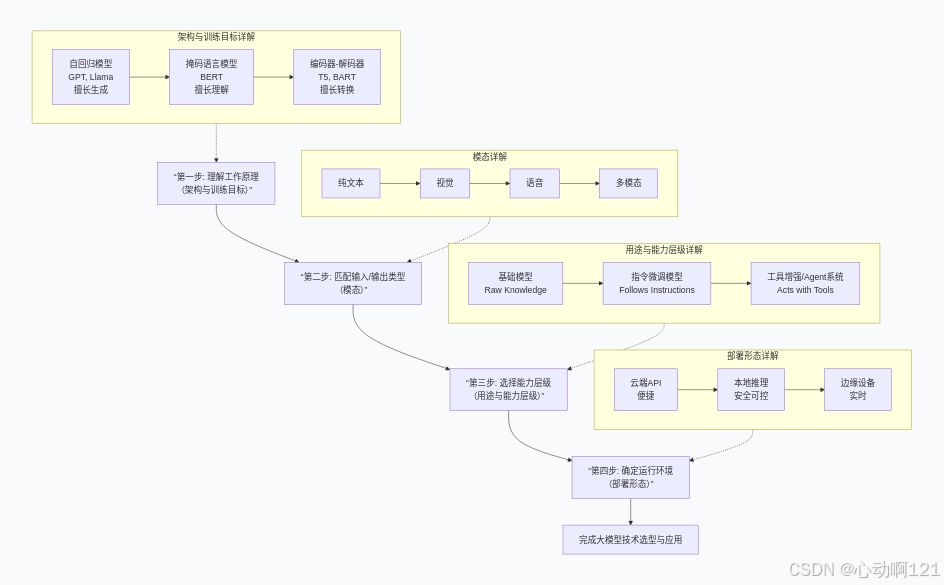
当面对具体任务进行选型的时候,可以按照以下的路径进行思考:
-
任务本质是什么? (对应架构)
-
要生成文章或对话 → 选自回归模型。
-
要分析文本情感 → 选掩码语言模型。
-
要做英文翻译 → 选编码器-解码器。
-
-
处理什么类型的数据? (对应模态)
-
只有文字 → 选纯文本模型。
-
需要“看懂”图片 → 选多模态模型或视觉模型。
-
-
需要多强的“开箱即用”能力? (对应用途)
-
希望直接对话 → 选指令微调模型。
-
希望它能联网查资料 → 选工具增强型/Agent。
-
-
在什么环境下使用? (对应部署)
-
快速测试 → 用云端API。
-
处理公司机密文档 → 必须本地推理。
-
集成到手机App中 → 需适配边缘设备模型。
-
三、大模型的优化与效率提升
模型效率优化的目标是在保持模型性能的前提下,降低计算、存储和推理成本,使得大模型能够在资源有限的环境中部署。
1、压缩技术
压缩技术的主要作用就是让大模型能够在实际硬件上运行,降低部署门槛和成本。
| 技术 | 核心思想 | 主要效果 |
|---|---|---|
| 量化 | 降低模型权重和激活值的数值精度(如FP32→INT8/INT4) | 减少存储(~75%)、加速推理、降低内存带宽需求 |
| 知识蒸馏 | 用小模型(学生)学习大模型(教师)的输出或中间表示 | 模型小型化、保留大模型能力、推理更快 |
| 剪枝 | 移除模型中不重要的权重或神经元(结构化/非结构化) | 稀疏化模型、减少计算量、内存占用降低 |
| 低秩分解 | 将大权重矩阵分解为多个小矩阵的乘积 | 减少参数数量、加速计算 |
2、高效架构
高效的架构就是重新设计大模型的“大脑结构”,从根本上改变模型的计算方式,土坯传统架构的限制。
| 方向 | 代表技术/模型 | 目标 |
|---|---|---|
| 稀疏注意力 | Longformer, BigBird | 处理长文本时减少计算复杂度(O(n²)→O(n)) |
| 混合专家 | Mixture of Experts (MoE) | 激活部分参数处理每个输入,总参数量大但计算量小 |
| 高效Transformer变体 | Linformer, Performer | 改进注意力机制的计算效率 |
3、推理优化
大模型推理有两个致命的瓶颈:
内存带宽墙:也就是从显存加载权重的时候内存带宽受限,token生成速度 ≈ 内存带宽 / 模型大小,也就是说:对于70B模型:即使计算再快,也被带宽限制在~10 token/秒
自回归的串行诅咒:生成10个token,传统方式:必须 token1 → token2 → ... → token10(无法并行,因为生成token2需要token1的结果),导致GPU大部分时间在等待、利用率可能低于30%。
| 训练优化技术 | 目的 |
|---|---|
| 混合精度训练 | 使用FP16/BF16降低显存占用,加速训练(AMP) |
| 梯度检查点 | 用时间换空间,减少训练时的显存消耗 |
| 3D并行 | 数据并行 + 流水线并行 + 张量并行,实现超大规模模型训练 |
| ZeRO优化器 | DeepSpeed的核心,优化分布式训练的显存使用 |
| 推理优化技术 | |
| KV缓存优化 | 重用注意力计算中的Key/Value,加速自回归生成 |
| 推测解码 | 让小模型先草稿生成,大模型并行验证,加速推理 |
| 连续批处理 | 动态批处理不同长度的请求,提高GPU利用率 |
| 模型编译 | 使用TensorRT、TVM等编译优化推理计算图 |
4、优化的内容总结
| 技术领域 | 解决的根本问题 | 实现的商业价值 | 比喻 |
|---|---|---|---|
| 压缩技术 | “装不下”问题 | 降低部署门槛,让模型能在现有硬件上运行 | 给大象瘦身,让它能进普通房间 |
| 高效架构 | “算不动”问题 | 突破计算复杂度限制,处理更复杂任务 | 重新设计大象的骨骼,让它更高效移动 |
| 推理优化 | “用不起”问题 | 降低服务成本,实现高并发低延迟 | 优化大象的工作流程,让它服务更多人 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)