【AAAI 2025】FedAdamW:面向大模型联邦学习的通信高效优化器
联邦学习(Federated Learning, FL)本身就不轻松:多客户端、数据 非 i.i.d.、通信频繁、隐私约束再把Transformer、ViT、RoBERTa 这种大模型丢进去,难度瞬间升级:在 CNN 上还能凑合到了 Transformer 上,经常收敛慢、效果差大模型基本离不开AdamW这样的自适应优化器 + decoupled weight decay在本地训练阶段,用 Ada
FedAdamW:面向大模型联邦学习的通信高效优化器
(摘要):
AdamW 已经成为训练大规模模型最有效的优化器之一,我们也在联邦学习(Federated Learning, FL)场景中观察到了它的有效性。然而,将 AdamW 直接应用于联邦学习会面临若干重要挑战:
(1) 由于数据存在异质性,AdamW 的二阶动量估计 v 往往方差较大;
(2) AdamW 在本地训练中的过拟合可能导致客户端漂移(client drift);
(3) 在每一轮通信中重新初始化动量估计(v, m)会减慢收敛速度。
为了解决上述问题,我们提出了第一个联邦版 AdamW 算法 FedAdamW,用于训练和微调各类大模型。FedAdamW 通过本地校正机制(local correction mechanism)与解耦权重衰减(decoupled weight decay)来对齐本地更新与全局更新,从而缓解本地过拟合。FedAdamW 高效聚合二阶动量估计的均值,以此降低其方差并用于重新初始化。
在理论方面,我们证明了 FedAdamW 在无需额外异质性假设的情况下,能够达到
O ( L Δ σ l 2 S K R ε 2 + L Δ R ) O\Big(\sqrt{\frac{L\Delta\sigma_l^2}{SKR\varepsilon^2}} + \frac{L\Delta}{R}\Big) O(SKRε2LΔσl2+RLΔ)
的线性加速收敛率,其中 S 为每轮参与的客户端数量,K 为本地迭代步数,R 为总通信轮数。我们进一步采用 PAC-Bayesian 泛化分析,解释了在本地训练中使用解耦权重衰减提升泛化能力的原因。
在实验方面,我们在多种语言与视觉 Transformer 模型上验证了 FedAdamW 的有效性。与多种基线方法相比,FedAdamW 显著减少了所需的通信轮数,并提升了测试精度。该方法的代码已开源于:https://github.com/junkangLiu0/FedAdamW。
原论文:FedAdamW: A Communication-Efficient Optimizer with Convergence and Generalization Guarantees for Federated Large Models
代码地址(GitHub):🔗 https://github.com/junkangLiu0/FedAdamW
一作 Junkang Liu(刘俊康)的公开资料/简介链接。
🔗 Google 学术个人主页
https://scholar.google.com/citations?user=N7pJWIoAAAAJ&hl=zh-CN ([谷歌学术][1])
目录
一、写在前面:大模型+联邦学习 = 双重地狱?
联邦学习(Federated Learning, FL)本身就不轻松:
-
多客户端、数据 非 i.i.d.、通信频繁、隐私约束
再把 Transformer、ViT、RoBERTa 这种大模型 丢进去,难度瞬间升级: -
传统 FedAvg + SGD:
- 在 CNN 上还能凑合
- 到了 Transformer 上,经常收敛慢、效果差
-
现实经验告诉我们:
- 大模型基本离不开 AdamW 这样的自适应优化器 + decoupled weight decay
论文作者的一个关键观察是:
在本地训练阶段,用 AdamW 的效果明显优于 SGD,但直接把 Local AdamW 拿来做联邦学习,会踩很多坑。
于是,FedAdamW 这篇工作就是在回答一个核心问题:
“如何把 AdamW 真正改造成一个适配联邦学习、通信高效、收敛有保证的大模型优化器?”
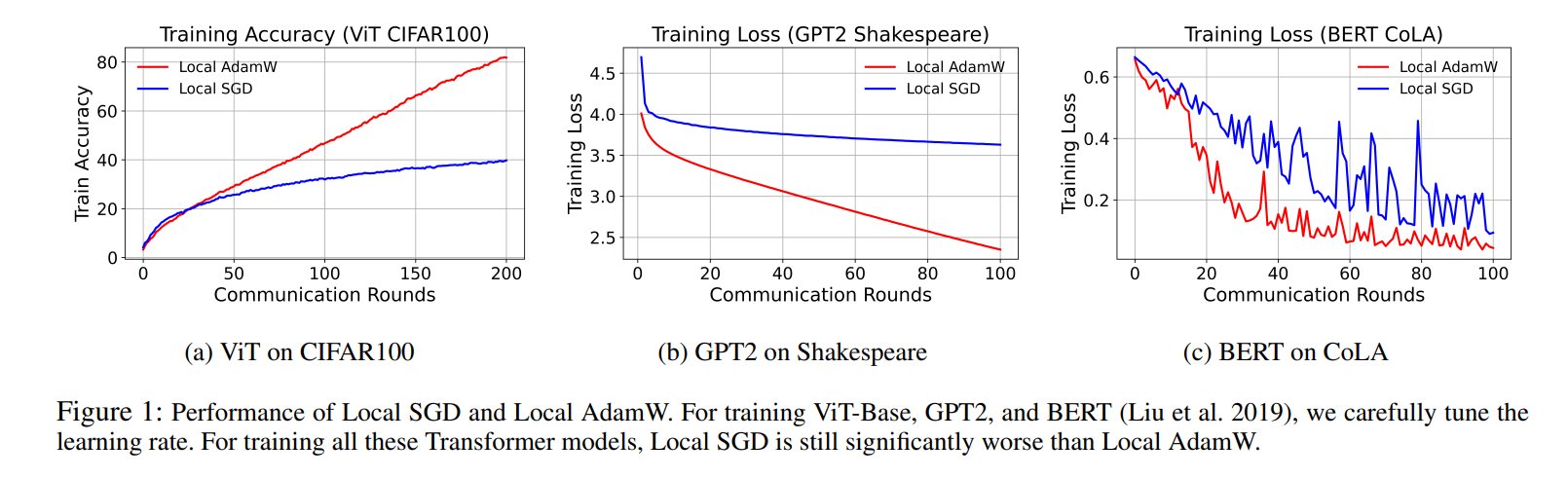
二、问题出在哪:AdamW 在联邦学习中的三大痛点
1. 二阶动量方差巨大:各个客户端各念各的经
AdamW 里有个关键变量:二阶动量估计 v
在单机场景,它可以平滑梯度、做自适应学习率;
但在联邦学习里,每个客户端都有自己的数据分布:
- 梯度分布差异大
- 于是 g⊙g 的波动非常剧烈
- 导致各客户端的 v 差异巨大,聚合起来经常不稳定
论文通过可视化对比展示:在非 i.i.d. 的 CIFAR-100 上,Local AdamW 的 v 在客户端之间方差非常大,这会让优化过程“抖得厉害”。
2. 本地过拟合与 Client Drift
AdamW 的特点:收敛快、更新大、适应性强。
在单机上是优点,在联邦环境下却放大了一个老问题:
每个客户端都更“执着”地朝自己的本地最优走,导致与全局最优方向偏离越来越大,这就是典型的 client drift。
表现为:
- 本地模型效果看起来不错
- 全局模型聚合后,效果反而很差
- 各客户端模型的参数差异越来越大
3. 每轮都把动量清零:收敛被迫“失忆”
很多联邦算法实现 Adam/AdamW 时会在每个通信轮:
m ← 0, v ← 0
也就是说:
- 每一轮从头学自适应统计量
- 完全抹掉历史信息
- 对于深层大模型,这相当于每轮都让优化器“失忆”,收敛速度受到明显影响

三、FedAdamW 核心思路:三板斧
FedAdamW 并不是简单“在服务器端再套一层 AdamW”,
而是围绕以上三大痛点做了三个关键设计:
1. Block-wise 二阶动量聚合:只传“均值”,省流量
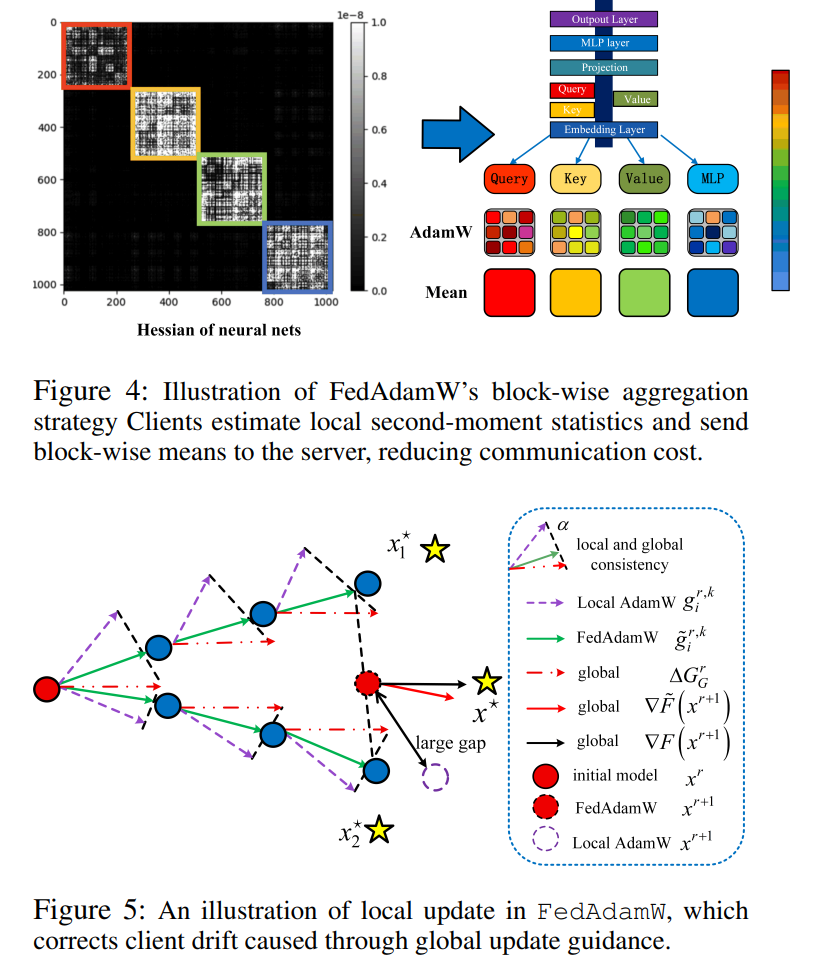
灵感来自一个重要现象:
Transformer 等深度网络的 Hessian 通常呈 近似块对角结构,同一 block 内曲率相似。
于是作者做了两件事:
-
按语义/结构对参数进行分块(block)
-
比如 ViT 中:
- Class 1:Query / Key,每个注意力头一个 block
- Class 2:Attention 输出和 MLP,各自按输出维度分 block
- Class 3:Value 层(曲率更大)
- Class 4:Embedding & 输出层
-
-
对每个 block 的二阶动量 v 只传“均值”:
-
客户端本地正常更新 v
-
发送到服务器时,不上传完整向量,而是:
v̄_b = mean(v_b), b = 1,...,B -
即每个 block 只上传一个标量均值
-
好处:
- 通信量:从“传整向量”变成 传 B 个标量
- 仍然保留每个 block 的曲率信息(自适应学习率)
- 聚合后再广播给各客户端作为二阶动量初始化
这就是论文中所谓的 Agg-mean-v 策略:在实验中兼顾了精度和通信效率,是几个聚合策略里综合表现最好的。
2. 全局更新对齐:给本地优化加一个“方向盘”
为缓解 client drift,FedAdamW 在本地更新中显式加入 全局更新方向:
记
- Δᵍʳ = 服务器估计得到的 全局梯度方向(或者说全局更新步长)
FedAdamW 本地更新为(直观形式):
x_{i}^{k+1} = x_{i}^k - η ( AdamW_梯度项 + α · Δᵍʳ )
其中 α 是一个控制强度的超参数。
理解方式:
- 本地优化仍然可以根据自己的数据走自适应的 AdamW 步
- 但每一步都会被 全局方向拉一把,避免各客户端“跑飞”
论文中实验发现:
-
α = 0:退化为普通 Local AdamW(client drift 严重)
-
适中 α(例如 0.5)时:
- 收敛更快
- 测试精度更高
- 本地与全局方向更加一致
3. 二阶动量复用:只重置一阶、保留二阶记忆
对于“每轮都清零动量”的问题,FedAdamW 的做法是:
-
一阶动量 m:每轮重置为 0
- 理由:m 反应的是最近的梯度方向,本身适应很快
-
二阶动量 v:从服务器聚合得到的 v̄ 进行初始化,不再清零
好处:
- 充分利用跨轮次累积到的曲率信息
- 加速大模型训练收敛
- 减少每轮“从零开始估计二阶动量”的浪费
四、理论保证:收敛率 & 泛化界的大白话解释
论文不仅做了大量实验,还给出了 非凸场景下的收敛率 和 PAC-Bayes 泛化界。
1. 收敛分析(非凸)
在一些标准假设下(L-Lipschitz、梯度有界、方差有界等),FedAdamW 的结果是:
-
在 R 轮通信后,平均梯度范数满足大致形如:
[
\mathbb{E}|\nabla f(x)|^2
\lesssim O\left(\sqrt{\frac{LΔσ_l2}{SKRϵ2}} + \frac{LΔ}{R}\right)
] -
其中:
- S:每轮参与的客户端数
- K:本地迭代步数
- R:总通信轮数
- σ_l:本地梯度噪声水平
可以理解为:
客户端越多(S 大)、本地训练越充分(K 大)、通信轮越多(R 大),FedAdamW 越快接近“平坦点”(小梯度)。并且它能做到线性加速。
更重要的是:
- 论文与一类已有的联邦 Adam 系算法对比后指出:
FedAdamW 不再需要额外的梯度异质性假设,理论条件更自然。
2. 泛化分析(PAC-Bayes)
论文用 PAC-Bayesian 框架分析了 FedAdamW 的泛化误差,并引入了 权重衰减 λ 对界的影响。结论大致是:
-
泛化误差随样本数 n 呈 O(1/√n) 收敛,这是正常现象
-
λ 越大:
- 一方面增强正则化,抑制过拟合
- 另一方面过大 λ 会损伤模型表达能力
-
这提供了一个 理论视角 解释:
- 为什么合理的 decoupled weight decay 能让 FedAdamW 在非 i.i.d. 联邦场景下泛化更好,
- 也解释了实验中 λ=0.01 一类设置表现最优的现象。
五、实验结果速览:CNN + Transformer + LLM 全面占优
论文在视觉和 NLP 两大方向做了充分实验,包括:
- CIFAR-100 / Tiny-ImageNet(图像分类)
- GLUE 上的多个任务(SST-2、QQP、RTE、MNLI 等)
- 模型:ResNet-18、ViT-Tiny、Swin Transformer、RoBERTa-Base + LoRA
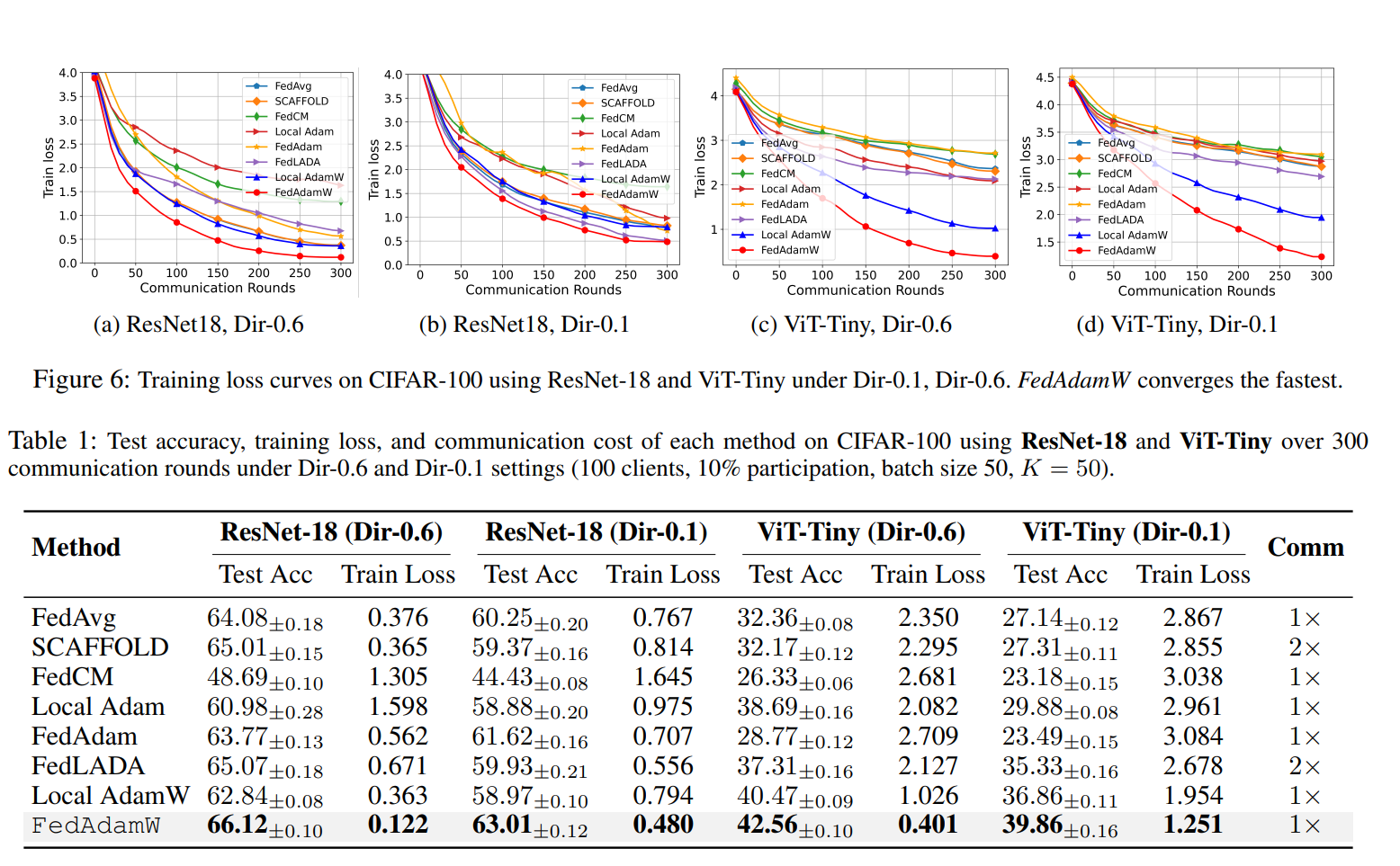
1. ResNet-18:传统 CNN 场景也赢
在 CIFAR-100 上(非 i.i.d. 设置),FedAdamW 相比:
- FedAvg / SCAFFOLD / FedAdam / FedLADA / Local Adam / Local AdamW
- 取得了 更高的测试精度和更低的训练损失,且通信成本保持同一量级
这说明:
即便是在传统 CNN 上,FedAdamW 也能在稳定性和收敛速度上优于主流算法,而不是“只对大模型有效”的偏科选手。
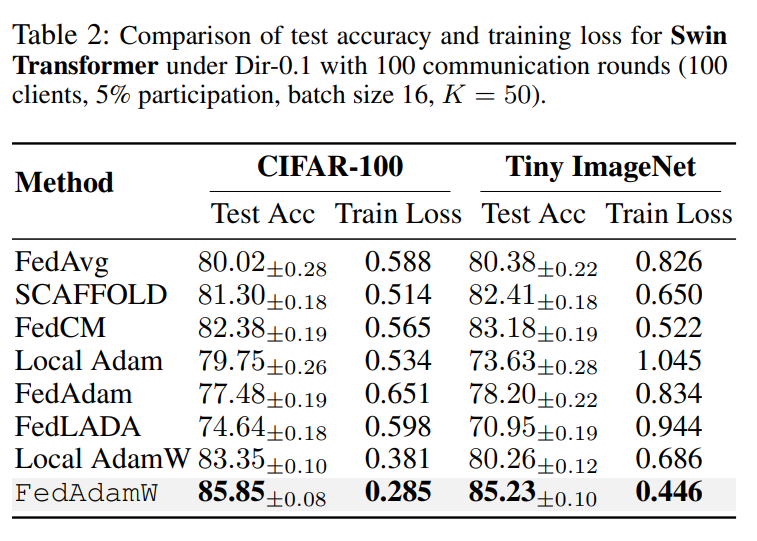
2. ViT & Swin Transformer:专治难训练的大模型
对于 ViT-Tiny、Swin Transformer 这种对优化器非常敏感的模型,FedAdamW 的优势更明显:
-
在 CIFAR-100 和 Tiny-ImageNet 上:
- 几乎在所有数据异质性设置下都拿到 最高测试精度
- 训练 loss 收敛速度和最终值也都最优
-
其他方法(尤其是基于 Adam 的联邦变体)在高异质性(Dir-0.1)下明显吃力
整体来看,这侧面验证了 FedAdamW 针对:
- 二阶动量方差
- client drift
- 动量重置
这三类问题的设计确实是 对症下药。
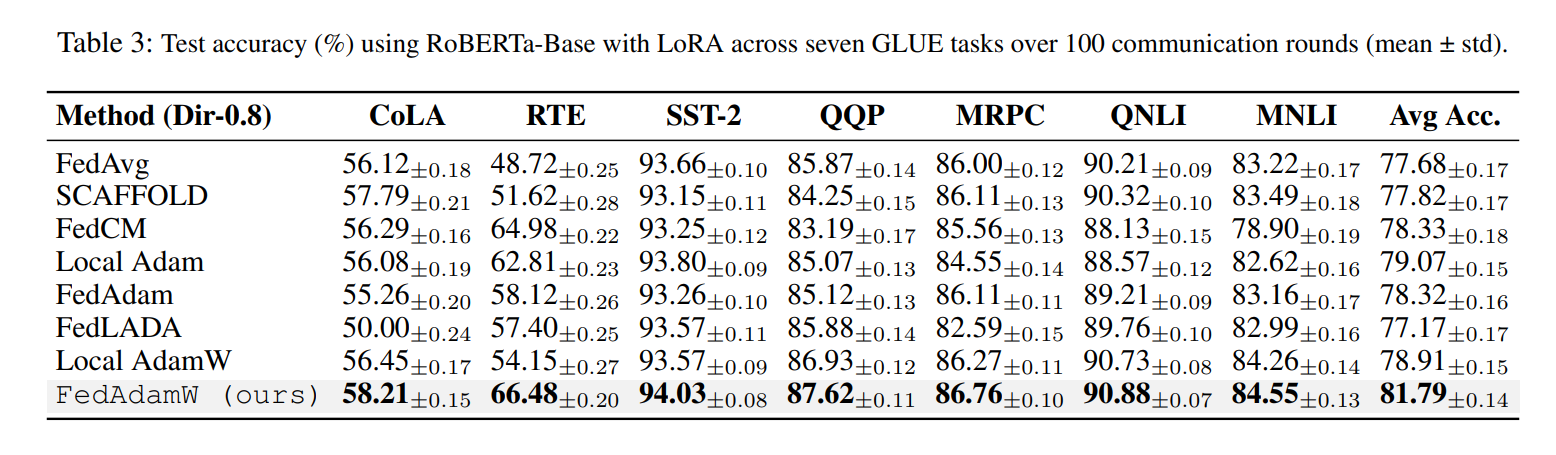
3. RoBERTa-Base(GLUE):联邦微调大语言模型
在 RoBERTa-Base + LoRA 的联邦微调实验中(多 GLUE 任务):
-
FedAdamW 的 平均精度 明显高于:
- FedAvg
- FedAdam
- FedLADA
- Local Adam / Local AdamW 等
-
在像 RTE、QQP 这种比较难的任务上,FedAdamW 提升尤为明显
结论非常清晰:
FedAdamW 不只是一个“玩具级”的优化器,而是能真正落地到联邦大模型微调场景的实用方法。
六、如何上手 FedAdamW(结合 GitHub 仓库)
由于这里无法直接浏览仓库细节,我们给出一个通用但实用的“上手路线图”,你可以对照仓库 README 和示例脚本来操作。
1. 环境准备(示意)
通常你会需要:
- Python 3.x
- PyTorch / 深度学习框架
- 常见联邦实验依赖(如 numpy、torchvision、transformers 等)
建议步骤:
git clone https://github.com/junkangLiu0/FedAdamW.git
cd FedAdamW
# 创建并激活你的虚拟环境,然后根据 README 安装依赖
pip install -r requirements.txt # 如果仓库中有该文件
2. 理解 FedAdamW 的接口思路
结合论文的 Algorithm 2,大致会有如下组件(名称以实际代码为准):
-
FedAdamW 优化器类
-
输入:学习率、β1、β2、权重衰减 λ、α(全局对齐系数)等
-
功能:
- 本地:实现 AdamW 更新 + 全局更新对齐项
- 服务器端:维护并广播全局模型与 block-wise v̄
-
在你自己的联邦框架中,可以按如下逻辑替换优化器:
-
保持原有 客户端划分、采样、数据加载逻辑不变
-
把本地训练阶段的优化器,从:
SGD/Adam/AdamW
换成:FedAdamW或 类似包装的 local-AdamW-with-global-align
-
在每轮聚合时:
- 除了聚合模型参数
- 还要聚合客户端上传的 block-wise 二阶动量均值,更新服务器端 v̄ 并广播给下一轮客户端初始化使用
3. 在自己数据集和模型上使用的建议
如果你想在自己的任务上试试 FedAdamW,可以参考论文设置:
- 学习率:对于 AdamW 类优化器,通常从
1e-4 ~ 1e-3区间网格搜索 - 权重衰减 λ:论文中在 ViT 上表现较好的值大约是
0.01量级 - α(全局对齐强度):可以从
0.25 / 0.5 / 0.75中挑,经验上 0.5 是一个不错的默认值 - 本地步数 K:取决于通信频率需求和数据量,可以在
10~100之间尝试
调参顺序建议:
- 固定 α 和 λ,先调学习率
- 在较优学习率附近,调 λ 控制正则程度
- 最后微调 α,看是否可以进一步提高稳定性和收敛速度
七、总结与展望:从 FedAdamW 到更多联邦优化新方向
FedAdamW 做成的一件事,可以总结成一句话:
把 AdamW 真正改造成了一个“联邦友好型”的大模型优化器:既通信高效,又有收敛和泛化保证。
它的设计思路有几个非常值得借鉴的点:
- 利用 Hessian 的块结构 做通信降维(block-wise v 聚合)
- 用 全局更新对齐 缓解 client drift,而不是一味加约束项
- 对动量进行 精细化管理:仅复用二阶、重置一阶,兼顾记忆与灵活性
- 既有 非凸收敛理论,又有 PAC-Bayes 泛化分析,跟实验结果形成闭环
未来可以继续探索的方向包括:
-
把 FedAdamW 的设计思想迁移到:
- LAMB、Lion 等新型优化器
- 更多参数高维、结构复杂的 LLM / ViT 变体
-
在隐私约束更强(如 DP-FL)或异构设备场景中,进一步优化通信与算力平衡

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)