三篇大模型代码生成优化:探索REx - 反思Reflexion - 调试LDB
大语言模型(LLM)在代码生成领域展现出显著潜力,但单次生成难以满足复杂任务的测试用例覆盖要求,且传统优化策略常陷入局部最优或资源浪费困境。本文将系统解析这三类代表性工作的核心机制:从 REx 引入多臂老虎机的 “探索 - 利用” 权衡机制优化迭代方向,到 Reflexion 以 “语言记忆” 构建反思式强化学习范式实现经验复用,再到 LDB 借鉴人类调试逻辑,通过跟踪运行时中间状态定位代码缺陷。
大语言模型(LLM)在代码生成领域展现出显著潜力,
但单次生成难以满足复杂任务的测试用例覆盖要求,且传统优化策略常陷入局部最优或资源浪费困境。
本文将系统解析这三类代表性工作的核心机制:
从 REx 引入多臂老虎机的 “探索 - 利用” 权衡机制优化迭代方向,
到 Reflexion 以 “语言记忆” 构建反思式强化学习范式实现经验复用,
再到 LDB 借鉴人类调试逻辑,通过跟踪运行时中间状态定位代码缺陷。
目录
1. REx Repair-Exploration-Exploitation -- 多臂老虎机
2. Reflexion: Language Agents with Verbal RL
1. REx Repair-Exploration-Exploitation -- 多臂老虎机
程序难以通过单次生成完成。给定测试用例集和候选程序,LLM 通过失败测试用例的提示来迭代改进程序,
调用过程生成一棵 "可能程序树",问题能否解决取决于如何扩展这棵树。
下一步从哪个程序(节点)调用进行进一步优化,存在 "探索 - 利用" 权衡问题。
("利用接近正确的程序(通过更多测试用例)" 与 "探索优化次数较少的程序")
传统策略的局限 —— 贪心策略只 "利用" 当前最优程序(通过测试最多),可能陷入局部最优;
BFS 策略盲目探索,浪费 LLM 调用资源。
将优化哪一个程序建模为 "多臂老虎机问题",汤普森采样的方式。
使用后验分布 Beta (α,β) 刻画每个臂,初始化为 Beta (1,1)。循环下两个步骤:
- 采样决策:对每个臂,从其 Beta (α,β) 分布中随机采样一个奖励概率估计值,选择采样值最大的臂拉动。
- 参数更新:根据拉动臂后的奖励结果更新参数。若获得奖励(r=1),则该臂的 α 参数加 1;若未获得奖励(r=0),则 β 参数加 1。
动作 a 对应优化不同程序,奖励 r -> 新生成程序的质量,
最大化折扣未来奖励 U -> 最少的 LLM 调用解决编程问题。
规范 Φ=ϕ1∧ϕ2∧⋯∧ϕK;目标程序满足规范 ρ⊢Φ。
启发式函数(Heuristic):h(ρ)∈[0,1],用于评估程序 ρ 的“进展程度”
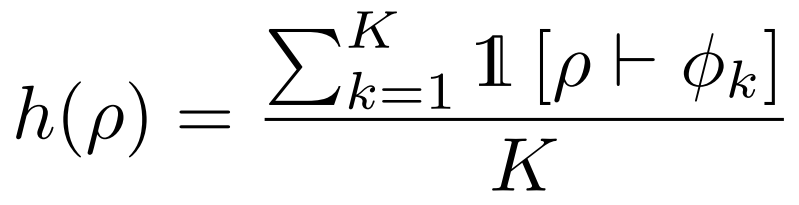 这里用,通过测试样例的比例。
这里用,通过测试样例的比例。
超参数 C,α越大期望越高,β越大期望越低,每错一次 β+1 惩罚。
![]()
![]()

2. Reflexion: Language Agents with Verbal RL
Reflexion —— 一种用 “语言记忆” 代替“参数调优”的强化学习新范式
不修改模型的内部参数,而是让智能体通过“语言反馈”“口头反思”从错误中学习。
智能体把任务反馈(比如“对/错”)转成一段文字总结,存到它的“记忆库”里。
下次再做类似任务时,它先看看以前犯的错和总结的经验,就能做得更好。
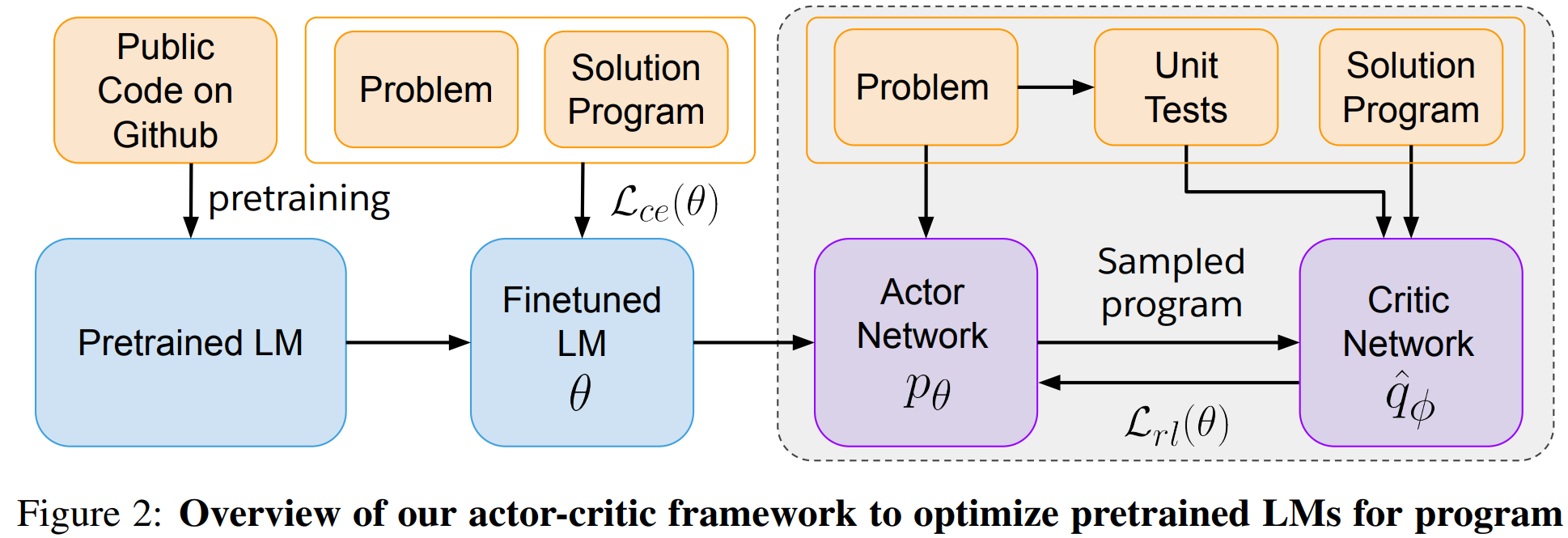
总体步骤:行动 a 得到一段轨迹 -> 打分 r -> 反思得到文本总结 srt -> 存入经验库 mem 帮助之后的行动。
1. Actor
核心身份:执行者
-
根据当前观察和记忆,直接生成行动或文本,类似于强化学习中的“策略网络”(πθ)
-
像智能体一样与环境交互,尝试完成任务(CoT 或 ReAct 等技巧)
2. Evaluator
核心身份:裁判
-
接收 Actor 生成的一整条行动轨迹,给出分数(多手段打分)
-
精确匹配:对于有标准答案的推理任务(如数学题),检查输出是否与答案完全一致。
-
启发式函数:对于决策类任务(如游戏),使用预定义的规则(如“是否拿到了钥匙?”、“还剩多少生命值?”)来计算分数。
-
LLM作为裁判:直接使用另一个LLM来审阅轨迹,并输出一个分数或评价。这尤其适用于编程或开放性任务,因为LLM可以理解代码逻辑或语义的合理性。
3. Self-Reflection Model
核心身份:反思教练
-
核心创新点:根据轨迹和分数,生成一段文本形式的反思总结 srt
-
信息丰富:与一个冰冷的“-10分”相比,这段文本明确指出了哪里错了以及应该怎么做。
-
如在 s 状态下,执行动作 a 导致了后面错误的 a1,a2;所以在 s 状态应该执行 a'。
-
经验固化:这段反思文本
srt会被存入 长期记忆(mem) 中,成为未来决策的“前车之鉴”。
4. Memory
核心身份:经验库 两种记忆
-
短期记忆:即当前这次尝试的完整轨迹历史 。提供了具体、细致的上下文,帮助Actor理解“我刚才做了什么”。
-
长期记忆:一个专门存储反思总结
srt的队列mem。存放从多次失败或成功中提炼出来的核心教训和策略。
3. LDB 大型语言模型调试器
现有方法将程序视为不可分割的整体,依赖执行后的反馈进行调试(比如只告诉你“这个测试没过”)。
而人类程序员遇到一个有缺陷的程序时,他们做的不仅仅是收集程序的输出。
他们会深入运行时执行,观察执行轨迹,通过设置断点来检查中间变量的值。
当中间执行状态偏离了他们的预期时,开发者就能准确定位bug并进行修正。
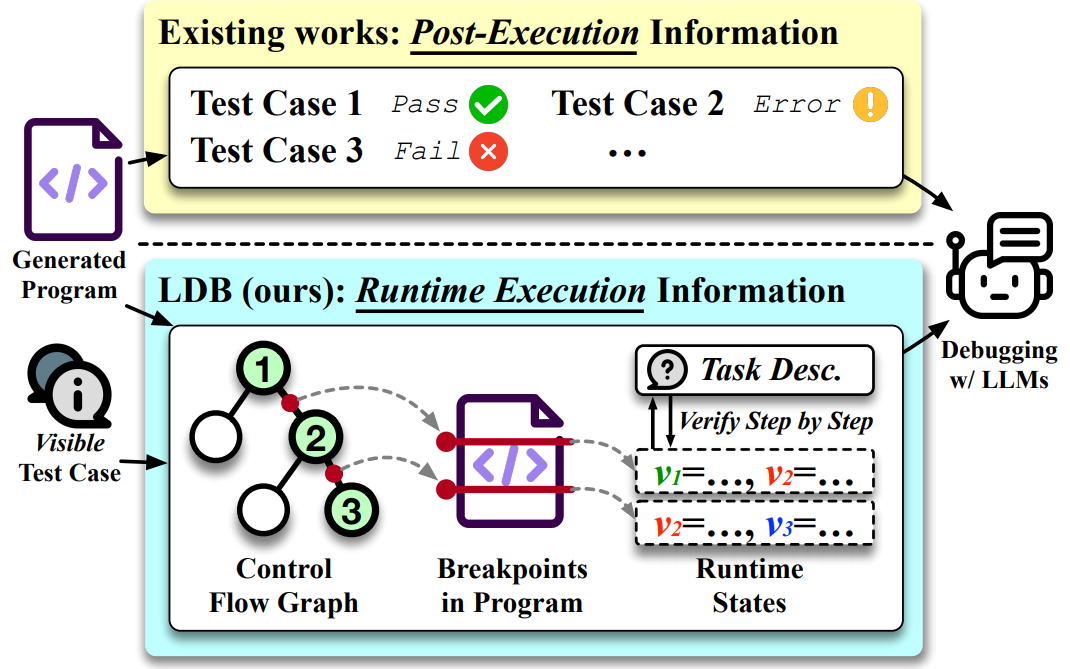
1. LDB会根据程序的控制流图,将执行轨迹分割成基本块。
2. 跟踪记录每个基本块执行结束后的中间变量值,类似于开发者设置的断点。
3. 收集到运行时执行信息后,LDB会向LLM提问,要求它对每个代码块的正确性做出判断,并解释执行流程与编码任务的关系。
代码生成任务:任务描述 Q,可见测试用例 Tv(代码生成或调试阶段用);
隐藏测试用例Th(衡量最终代码答案的好坏)
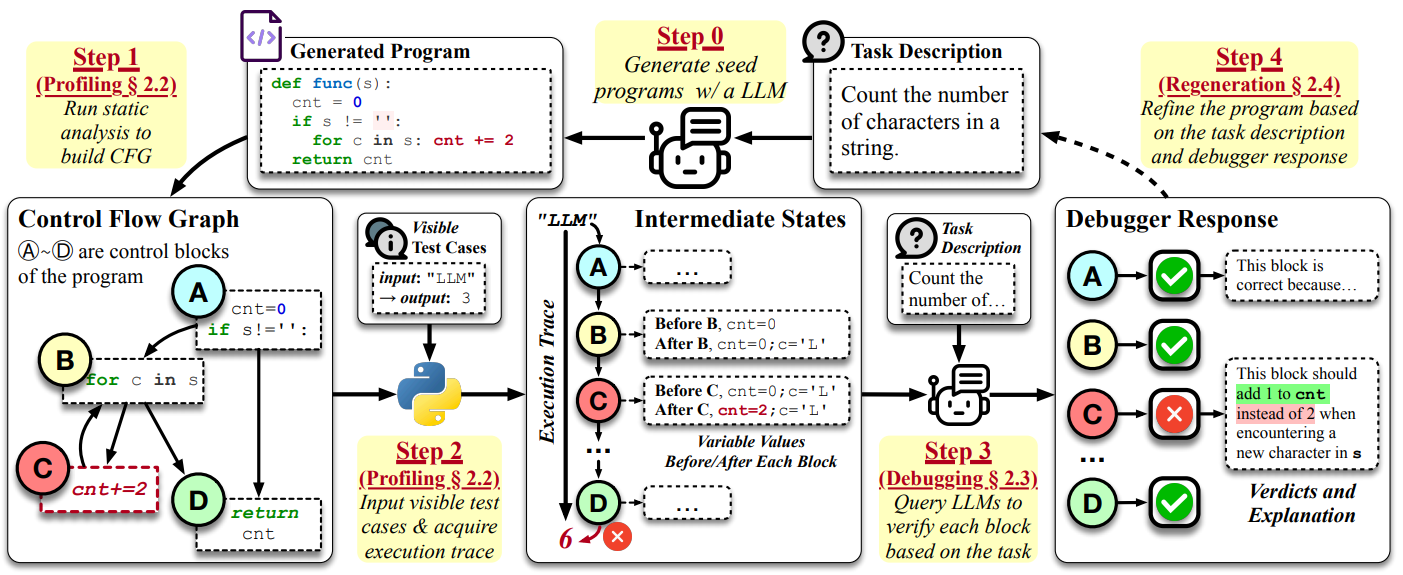
1. 运行时信息收集(Profiling)
LDB基于静态分析将程序转换为控制流图。每个基本块 B 以及输入输出构成三元组 (Vi-1, Bi, Vi)。
2. Debugging
(1) Debugging Verdicts:LDB 构建提示,LLM 回答是否符合预期。
“给定任务描述 Q、执行前的状态 Vi-1 以及执行的代码块 Bi,实际得到的输出状态 Vi”
输出是一个判断 Di(True 或 False),以及一个解释 Ei,说明为什么认为这一步正确或错误。
(2)Selective Debugging
不会分析所有基本块,而是从长轨迹中采样 Nb 个关键块进行分析。
(3)Batch Debugging 一系列 (V,B) 打包成 Batch -> (D,E)
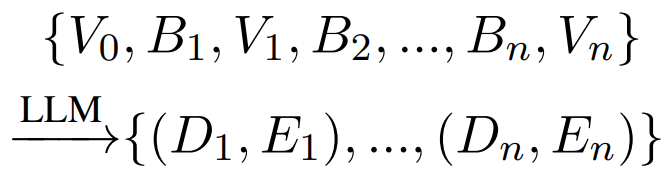
3. Regeneration
将 D 为 False 的基本块,以及解释 E,连同原任务描述 Q,让 LLM 重新生成 修复这些问题的程序。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)