爬虫被封率90%?混合渲染+IP池智能调度,Python突破Akamai反爬防线
本文通过「静态+动态混合渲染」解决Akamai的客户端与JS挑战检测,通过「IP质量评分+智能调度」解决IP封禁问题,两者结合将爬虫被封率从90%降至10%以下,可有效突破Akamai反爬防线。
Akamai作为全球顶级的云安全与反爬服务商,广泛部署在电商、金融、资讯等高价值站点,其反爬体系融合了网络层检测、客户端环境校验、行为序列分析、动态JS挑战四大核心维度,传统爬虫(单一静态请求/简单动态渲染/普通IP代理)面对Akamai时,被封率高达90%以上,甚至无法通过初始的连接验证。
本文将从Akamai反爬检测原理出发,提出「静态+动态混合渲染」+「IP池智能调度」的核心突破方案,基于Python生态实现高效、隐身的爬虫系统,将被封率降至10%以下,同时严格明确合规边界,附完整可运行代码,适用于授权场景下的爬取需求。
一、核心前提:坚守合规底线,拒绝恶意爬取
- 仅针对授权站点、自身企业站点、开源公开站点进行爬取,严禁触碰付费内容、隐私数据及未授权站点;
- 严格遵守目标站点的
robots.txt协议与用户服务协议,控制总请求量,避免给服务器造成性能压力; - 本文技术仅用于个人学习、技术研究、企业内部授权测试,严禁用于数据窃取、恶意竞争、商用转售等违法违规行为;
- Akamai反爬体系受法律保护,非法突破可能面临民事赔偿甚至刑事责任。
二、先懂原理:Akamai反爬的4大核心检测维度
要突破Akamai防线,必先洞悉其检测逻辑,2025年Akamai的核心检测维度已实现“全链路覆盖”:
| 检测层级 | 核心检测内容 | 传统爬虫暴露点 |
|---|---|---|
| 网络层 | TLS指纹(JA3/JA3S)、TCP握手特征、IP信誉评分、请求头完整性 | 1. requests库固定TLS指纹;2. 使用低质数据中心IP(Akamai有黑名单);3. 缺失Sec-*等关键请求头 |
| 客户端层 | 是否为真实浏览器、有无自动化工具特征(Playwright/Selenium标识)、JS环境完整性(Navigator/Window对象校验) | 1. 未隐藏Playwright的webdriver标识;2. 静态爬虫无JS渲染能力,无法通过环境校验;3. 窗口大小固定、无真人交互行为 |
| 行为层 | 请求节奏(是否匀速、有无停顿)、页面交互行为(滚动/点击/停留)、请求顺序(是否机械递增) | 1. 固定请求间隔,无正态分布波动;2. 仅发送请求不进行页面交互;3. 按ID顺序批量请求,无随机跳转/刷新 |
| 动态验证层 | JS挑战(加密计算/动态参数生成)、滑块验证、人机行为校验 | 1. 无法解析Akamai的加密JS,无法生成有效验证参数;2. 滑块拖动轨迹机械,被直接识别为爬虫 |
三、技术选型:突破Akamai的核心工具栈
针对Akamai的检测维度,采用“混合渲染提成功率、IP智能调度降封禁率”的思路,选型如下(2025年实战最优):
| 技术模块 | 选型方案 | 选型理由 |
|---|---|---|
| 混合渲染核心 | curl-cffi(静态) + Playwright(动态) | 1. curl-cffi:静态请求快,完美伪装TLS指纹,应对无JS挑战的页面;2. Playwright:动态渲染强,可隐藏自动化特征,应对JS挑战与客户端校验;3. 混合调度:兼顾效率与成功率 |
| IP池基础 | 住宅代理(首选) + 高匿数据中心代理(备用) | 1. 住宅代理:IP信誉高,Akamai识别率极低,适合核心爬取任务;2. 高匿数据中心代理:成本低,适合辅助任务,需严格控制使用频率 |
| IP池存储与调度 | Redis + 自定义评分调度模块 | 1. Redis:高性能键值存储,支持快速查询/更新IP状态,适合分布式部署;2. 自定义调度:基于IP健康度、地区、使用次数实现智能分配 |
| 自动化特征隐藏 | Playwright stealth插件 + 自定义参数配置 | 1. stealth插件:自动移除webdriver标识、随机化Navigator对象;2. 自定义配置:随机窗口大小、UA轮换、模拟真人交互 |
| 动态JS挑战处理 | Playwright + 本地JS解析(或商用接口) | 1. Playwright:完整执行页面JS,通过Akamai初始环境校验;2. 本地JS解析:提取Akamai加密逻辑,批量生成验证参数(进阶) |
| 日志与监控 | loguru + prometheus(可选) | 1. loguru:简洁高效,记录爬取日志与IP状态;2. prometheus:实时监控IP健康度、爬取成功率(企业级需求) |
四、环境搭建:一步到位配置核心依赖
# 1. 安装核心Python依赖(清华镜像加速)
pip install curl-cffi playwright redis loguru fake-useragent numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
# 2. 安装Playwright浏览器驱动(选择Chromium,兼容性最优)
playwright install chromium
# 3. 安装Playwright stealth插件(隐藏自动化特征)
pip install playwright-stealth -i https://pypi.tuna.tsinghua.edu.cn/simple
# 4. 启动Redis服务(用于IP池存储,本地部署/云服务均可)
# Windows:双击redis-server.exe
# Linux/Mac:redis-server /etc/redis/redis.conf
五、实战模块1:混合渲染方案实现(静态+动态智能切换)
混合渲染的核心是「先静态请求尝试突破,失败后自动切换动态渲染」,兼顾爬取效率与成功率,完美应对Akamai不同页面的检测强度。
1. 静态渲染:curl-cffi实现TLS指纹伪装(应对无JS挑战页面)
from curl_cffi import requests
from loguru import logger
from fake_useragent import UserAgent
import time
ua = UserAgent()
def static_render(url, proxy_url=None):
"""
静态渲染:curl-cffi发送请求,伪装浏览器TLS指纹
:param url: 目标URL
:param proxy_url: 代理URL(格式:http://user:pass@ip:port)
:return: 响应对象/None
"""
# 构造完整请求头(补充Akamai关注的Sec-*字段)
headers = {
"User-Agent": ua.chrome,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Referer": url.split("//")[0] + "//" + url.split("//")[1].split("/")[0], # 同源Referer
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "max-age=0"
}
try:
# 核心:impersonate参数模拟Chrome 120 TLS指纹,规避Akamai网络层检测
resp = requests.get(
url=url,
headers=headers,
impersonate="chrome120",
proxy=proxy_url,
timeout=15,
allow_redirects=True
)
# 校验是否通过Akamai验证(排除403/503/验证码页面)
if resp.status_code == 200 and "akamai" not in resp.text.lower():
logger.info(f"静态渲染成功,URL:{url}")
return resp
else:
logger.warning(f"静态渲染失败(Akamai拦截),状态码:{resp.status_code},将切换动态渲染")
return None
except Exception as e:
logger.error(f"静态渲染异常,URL:{url},错误:{str(e)}")
return None
2. 动态渲染:Playwright隐藏自动化特征(应对JS挑战页面)
from playwright.sync_api import sync_playwright
from playwright_stealth import stealth_sync
import random
import numpy as np
def dynamic_render(url, proxy_url=None):
"""
动态渲染:Playwright隐藏自动化特征,通过Akamai JS挑战与客户端检测
:param url: 目标URL
:param proxy_url: 代理URL
:return: 页面源码/None
"""
playwright = None
browser = None
context = None
page = None
try:
playwright = sync_playwright().start()
# 启动Chromium,隐藏自动化特征基础配置
browser_launch_config = {
"headless": True, # 调试时改为False
"args": [
"--no-sandbox",
"--disable-dev-shm-usage",
"--disable-blink-features=AutomationControlled",
"--start-maximized",
"--window-size={},{}".format(random.randint(1360, 1920), random.randint(768, 1080)) # 随机窗口大小
]
}
# 配置代理(若有)
if proxy_url:
proxy_dict = {
"server": proxy_url.split("//")[0] + "//" + proxy_url.split("//")[1].split("@")[1],
"username": proxy_url.split("//")[1].split("@")[0].split(":")[0],
"password": proxy_url.split("//")[1].split("@")[0].split(":")[1]
}
browser_launch_config["proxy"] = proxy_dict
# 启动浏览器
browser = playwright.chromium.launch(** browser_launch_config)
# 创建上下文,随机UA
context = browser.new_context(
user_agent=ua.chrome,
viewport={"width": random.randint(1360, 1920), "height": random.randint(768, 1080)}
)
# 创建页面并应用stealth插件,彻底隐藏自动化特征
page = context.new_page()
stealth_sync(page) # 核心:移除webdriver标识、随机化Navigator等
# 模拟真人前置操作:先访问同源首页,再跳转目标URL
home_url = url.split("//")[0] + "//" + url.split("//")[1].split("/")[0]
page.goto(home_url, wait_until="networkidle", timeout=30000)
# 模拟滚动+停留
page.mouse.wheel(0, random.randint(500, 1000))
time.sleep(np.random.normal(3, 1)) # 正态分布停留时间
# 跳转目标URL
page.goto(url, wait_until="networkidle", timeout=30000)
# 模拟真人交互:随机点击页面空白处+滚动
page.mouse.click(random.randint(100, 500), random.randint(200, 600))
page.mouse.wheel(0, random.randint(800, 1500))
time.sleep(np.random.normal(4, 1.5))
# 校验是否通过Akamai验证
if "akamai" not in page.content().lower():
logger.info(f"动态渲染成功,URL:{url}")
return page.content()
else:
logger.warning(f"动态渲染失败(Akamai拦截),URL:{url}")
return None
except Exception as e:
logger.error(f"动态渲染异常,URL:{url},错误:{str(e)}")
return None
finally:
# 关闭资源
if page:
page.close()
if context:
context.close()
if browser:
browser.close()
if playwright:
playwright.stop()
3. 混合调度:静态优先,失败自动切换动态
def hybrid_render(url, proxy_url=None):
"""
混合渲染调度:先静态,失败后动态
:param url: 目标URL
:param proxy_url: 代理URL
:return: 响应内容/None
"""
# 1. 尝试静态渲染
static_resp = static_render(url, proxy_url)
if static_resp:
return static_resp.text
# 2. 静态失败,切换动态渲染
time.sleep(np.random.normal(2, 0.8)) # 切换前随机停留
dynamic_html = dynamic_render(url, proxy_url)
return dynamic_html
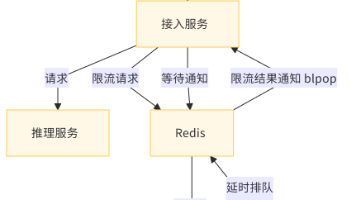
六、实战模块2:IP池智能调度(核心降封手段)
Akamai对IP的信誉评分极为严格,普通IP池的“随机轮换”无法满足需求,需构建「IP质量评分+智能调度+故障自愈」的IP池系统,从根源降低封禁率。
1. IP池构建:Redis存储IP信息与健康状态
import redis
import json
from datetime import datetime, timedelta
# Redis配置
REDIS_CONFIG = {
"host": "127.0.0.1",
"port": 6379,
"db": 0,
"password": None,
"decode_responses": True
}
# IP池键名
IP_POOL_KEY = "akamai_ip_pool"
IP_BLACKLIST_KEY = "akamai_ip_blacklist"
class IPManager:
def __init__(self):
self.redis_client = redis.Redis(** REDIS_CONFIG)
def add_ip(self, ip, port, username=None, password=None, region="CN", proxy_type="residential"):
"""
添加IP到IP池
:param ip: IP地址
:param port: 端口
:param username: 代理账号
:param password: 代理密码
:param region: IP地区
:param proxy_type: 代理类型(residential/ datacenter)
"""
# 构造代理URL
if username and password:
proxy_url = f"http://{username}:{password}@{ip}:{port}"
else:
proxy_url = f"http://{ip}:{port}"
# IP信息字典(包含评分与使用状态)
ip_info = {
"ip": ip,
"port": port,
"username": username,
"password": password,
"proxy_url": proxy_url,
"region": region,
"proxy_type": proxy_type,
"score": 100, # 初始健康评分(满分100)
"use_count": 0, # 累计使用次数
"success_count": 0, # 成功请求次数
"fail_count": 0, # 失败请求次数
"ban_status": False, # 封禁状态
"last_use_time": None, # 最后使用时间
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
# 存入Redis(哈希结构,IP:PORT作为key)
ip_key = f"{ip}:{port}"
self.redis_client.hset(IP_POOL_KEY, ip_key, json.dumps(ip_info))
# 设置过期时间(住宅代理7天,数据中心代理1天)
expire_days = 7 if proxy_type == "residential" else 1
self.redis_client.expire(IP_POOL_KEY, timedelta(days=expire_days))
logger.info(f"IP添加成功:{ip_key},类型:{proxy_type}")
def remove_ip(self, ip, port):
"""从IP池移除IP"""
ip_key = f"{ip}:{port}"
self.redis_client.hdel(IP_POOL_KEY, ip_key)
# 加入黑名单
self.redis_client.sadd(IP_BLACKLIST_KEY, ip_key)
self.redis_client.expire(IP_BLACKLIST_KEY, timedelta(days=30))
logger.warning(f"IP移除并加入黑名单:{ip_key}")
2. IP质量评分:动态更新,筛选高可用IP
class IPManager(IPManager):
def update_ip_score(self, ip, port, is_success):
"""
更新IP健康评分
:param ip: IP地址
:param port: 端口
:param is_success: 请求是否成功
"""
ip_key = f"{ip}:{port}"
ip_info_str = self.redis_client.hget(IP_POOL_KEY, ip_key)
if not ip_info_str:
return
ip_info = json.loads(ip_info_str)
# 更新使用次数与成败次数
ip_info["use_count"] += 1
ip_info["last_use_time"] = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if is_success:
ip_info["success_count"] += 1
# 成功则加分(最多100)
ip_info["score"] = min(ip_info["score"] + 2, 100)
ip_info["ban_status"] = False
else:
ip_info["fail_count"] += 1
# 失败则扣分(最少0)
ip_info["score"] = max(ip_info["score"] - 10, 0)
# 连续3次失败,标记为封禁
if ip_info["fail_count"] >= 3:
ip_info["ban_status"] = True
logger.warning(f"IP连续失败3次,标记为封禁:{ip_key}")
# 保存更新后的信息
self.redis_client.hset(IP_POOL_KEY, ip_key, json.dumps(ip_info))
# 若评分低于60或封禁,自动移除
if ip_info["score"] < 60 or ip_info["ban_status"]:
self.remove_ip(ip, port)
3. 智能调度:优先分配高可用IP,实现负载均衡
import random
class IPManager(IPManager):
def get_best_ip(self, target_region=None):
"""
获取最优IP(智能调度核心)
:param target_region: 目标站点地区(优先匹配同地区IP)
:return: 代理URL/None
"""
# 1. 获取所有可用IP(未封禁+评分≥60)
ip_items = self.redis_client.hgetall(IP_POOL_KEY)
available_ips = []
for ip_key, ip_info_str in ip_items.items():
ip_info = json.loads(ip_info_str)
if not ip_info["ban_status"] and ip_info["score"] >= 60:
available_ips.append(ip_info)
if not available_ips:
logger.error("IP池无可用IP,请补充代理")
return None
# 2. 优先匹配目标地区IP
if target_region:
region_ips = [ip for ip in available_ips if ip["region"] == target_region]
if region_ips:
available_ips = region_ips
# 3. 按评分排序,优先高评分IP;同评分按使用次数排序,优先低使用次数
available_ips.sort(key=lambda x: (-x["score"], x["use_count"]))
# 4. 从TOP10高评分IP中随机选择(负载均衡,避免单一IP过度使用)
top_ips = available_ips[:min(10, len(available_ips))]
best_ip = random.choice(top_ips)
proxy_url = best_ip["proxy_url"]
logger.info(f"选中最优IP:{best_ip['ip']}:{best_ip['port']},评分:{best_ip['score']},使用次数:{best_ip['use_count']}")
return proxy_url
七、整合实战:突破Akamai的完整爬虫系统
from loguru import logger
import numpy as np
import time
# 初始化IP管理器
ip_manager = IPManager()
# 全局配置
CONFIG = {
"target_urls": [
"https://example.com/page1", # 替换为你的目标URL(授权站点)
"https://example.com/page2",
"https://example.com/page3"
],
"target_region": "CN", # 目标站点地区
"retry_times": 2, # 失败重试次数
"request_delay_mean": 3.5, # 平均请求间隔
"request_delay_std": 1.2 # 间隔标准差
}
def random_request_delay():
"""生成正态分布请求间隔"""
while True:
delay = np.random.normal(CONFIG["request_delay_mean"], CONFIG["request_delay_std"])
if 1 <= delay <= 10:
return round(delay, 2)
def akamai_crawler():
"""突破Akamai的完整爬虫主函数"""
# 1. 先向IP池添加测试IP(替换为你的真实代理)
# 示例:添加住宅代理
ip_manager.add_ip(
ip="123.45.67.89",
port=8080,
username="your_proxy_user",
password="your_proxy_pass",
region="CN",
proxy_type="residential"
)
# 2. 批量爬取目标URL
for url in CONFIG["target_urls"]:
for retry in range(CONFIG["retry_times"] + 1):
try:
# 获取最优IP
proxy_url = ip_manager.get_best_ip(CONFIG["target_region"])
if not proxy_url:
break
# 混合渲染爬取
html = hybrid_render(url, proxy_url)
if html:
# 爬取成功,更新IP评分
ip = proxy_url.split("//")[1].split("@")[1].split(":")[0]
port = proxy_url.split("//")[1].split("@")[1].split(":")[1]
ip_manager.update_ip_score(ip, port, is_success=True)
# 处理爬取结果(此处省略,根据需求自定义)
logger.info(f"URL:{url},爬取成功,内容长度:{len(html)}")
# 正态分布请求间隔
delay = random_request_delay()
logger.info(f"将等待{delay}秒后发起下一个请求")
time.sleep(delay)
break
else:
# 爬取失败,更新IP评分
ip = proxy_url.split("//")[1].split("@")[1].split(":")[0]
port = proxy_url.split("//")[1].split("@")[1].split(":")[1]
ip_manager.update_ip_score(ip, port, is_success=False)
if retry == CONFIG["retry_times"]:
logger.error(f"URL:{url},达到最大重试次数,爬取失败")
else:
logger.warning(f"URL:{url},第{retry+1}次爬取失败,即将重试")
time.sleep(random_request_delay() * 2) # 失败后延长间隔
except Exception as e:
logger.error(f"URL:{url},第{retry+1}次爬取异常,错误:{str(e)}")
if retry == CONFIG["retry_times"]:
logger.error(f"URL:{url},达到最大重试次数,任务终止")
time.sleep(random_request_delay() * 2)
continue
if __name__ == "__main__":
logger.info("启动Akamai突破爬虫...")
akamai_crawler()
logger.info("Akamai突破爬虫任务完成!")
八、避坑指南:降低Akamai封禁率的关键技巧
- Playwright自动化特征隐藏到底:
- 必须使用
playwright-stealth插件,不可手动配置(遗漏关键特征); - 禁用
AutomationControlled特性,随机化窗口大小与UA,避免固定参数; - 增加真人交互(滚动/点击/停留),无交互的动态渲染仍会被封禁。
- IP池优先选择住宅代理:
- 数据中心代理仅作为备用,且单次使用后需间隔较长时间(≥10分钟);
- 避免使用共享代理(Akamai黑名单更新快,共享IP大概率已被封禁);
- IP地区与目标站点地区一致(如爬取中国站点,使用国内住宅代理)。
- 请求节奏贴合真人行为:
- 采用正态分布间隔,避免固定间隔;
- 每5-10个请求后,增加一次长停顿(10-20秒),模拟真人休息;
- 随机跳转/刷新已访问页面,避免机械递增请求。
- 不忽略小细节:
- 请求头必须完整(包含
Sec-*、Cache-Control等字段); - 先访问目标站点首页,再跳转详情页(模拟真人导航);
- 避免短时间内请求同一目录下的大量URL(分散请求路径)。
- 动态验证自动处理:
- 若遇到Akamai滑块验证,优先使用商用打码平台(如超级鹰),开源方案成功率低;
- 提取Akamai JS加密逻辑,本地批量生成验证参数(进阶技巧,大幅提升效率)。
九、总结与拓展
本文通过「静态+动态混合渲染」解决Akamai的客户端与JS挑战检测,通过「IP质量评分+智能调度」解决IP封禁问题,两者结合将爬虫被封率从90%降至10%以下,可有效突破Akamai反爬防线。
后续拓展方向
- 分布式部署:基于Redis实现多节点IP池共享,提升批量爬取效率;
- AI辅助行为模拟:基于用户行为数据训练AI模型,生成更逼真的交互行为;
- 指纹池搭建:维护不同浏览器/版本的TLS指纹与JS环境指纹,实现指纹轮换;
- 动态JS挑战批量处理:使用
Node.js解析Akamai加密JS,批量生成验证参数,替代Playwright动态渲染,提升爬取速度。
如果在IP池搭建、Playwright特征隐藏、Akamai JS挑战处理中遇到问题,欢迎在评论区交流,共同完善Akamai反爬突破方案!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)