飞书知识库 → Milvus 向量数据库:手把手同步教程,直接抄就能用
兄弟们,见字如面,我是王中阳。最近扎在企业知识库项目里,踩了个能拍大腿的坑——飞书里存着几百份产品文档、技术手册,本来想对接AI做智能问答,结果数据死活导不进,前前后后折腾快一周才打通。这事儿真是“真金白银买的教训”,今天干脆把完整同步流程给兄弟们掏出来,从凭证申请到生产化部署,每一步都标死代码位置,你们直接抄作业就行,省得再走弯路。本文内容均来自我们项目中的实操,感兴趣的朋友可以关注我,私信我6
兄弟们,见字如面,我是王中阳。
最近扎在企业知识库项目里,踩了个能拍大腿的坑——飞书里存着几百份产品文档、技术手册,本来想对接AI做智能问答,结果数据死活导不进Milvus向量数据库,前前后后折腾快一周才打通。这事儿真是“真金白银买的教训”,今天干脆把完整同步流程给兄弟们掏出来,从凭证申请到生产化部署,每一步都标死代码位置,你们直接抄作业就行,省得再走弯路。
本文内容均来自我们项目中的实操,感兴趣的朋友可以关注我,私信我666,发你资料。
一、准备飞书开放平台凭证(第一步就踩坑,这步错了全白干)
这步看着像“开胃菜”,实则是“拦路虎”。我第一次就是漏开了云文档权限,调API清一色报403,翻了半天官方文档才定位问题,纯纯浪费时间。
- 先去飞书开放平台建个“企业自建应用”,生成的
APP_ID和APP_SECRET赶紧记在记事本上,这俩是后续鉴权的“钥匙”,丢了就得从头再来。 - 接着申请“租户访问凭证(Tenant Access Token)”,重点中的重点:必须给应用开知识库/云文档读权限,别只开个基础权限就完事,不然调接口拿不到文档内容,纯属做无用功。
- 找到项目里的
transmarkdown.go文件(路径给你们标死:@backend/internal/eino/milvus/feishu/transmarkdown.go[#3](javascript:😉-20),这里用SDK封装好了鉴权和API调用逻辑,把里面的示例凭证换成你自己的,千万别直接用默认值测试,百分百不通。
二、拉取文档并转成Markdown(核心一步,保住格式才不白导)
飞书文档格式特别杂,表格、代码块、图片、公式啥都有,直接拉取数据准保乱码。我们之前做AI客服系统时,就因为早期转码丢了FAQ的列表格式,导致智能体回答得颠三倒四,后来重写了转码逻辑才解决,这教训记一辈子。
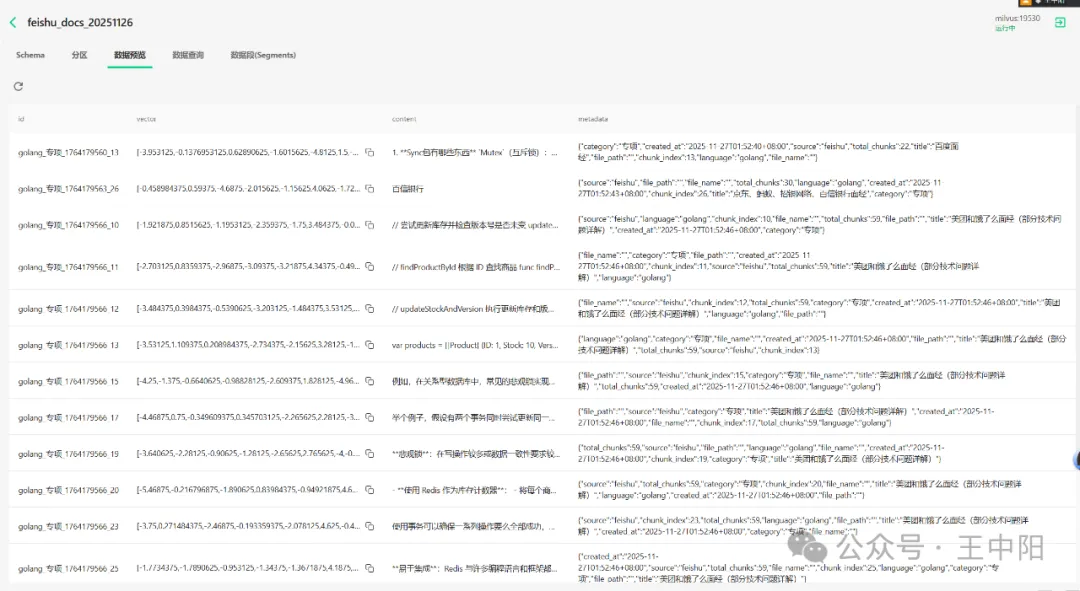
2.1 列文档、拿内容:精准定位要同步的文件
直接用飞书的Drive或Docx API列出来要同步的文档,返回的DriveListFilesResponse和DriveFile结构体里,文档ID、名称、修改时间都写得明明白白(代码位置:@backend/internal/eino/milvus/feishu/transmarkdown.go[#117](javascript:😉-136)。接着针对每个文档,去拿它的块级内容——FeishuBlock结构体把标题块、代码块、图片块分得清清楚楚,根本不用你自己猜格式(代码位置:@backend/internal/eino/milvus/feishu/transmarkdown.go[#21](javascript:😉-116)。
2.2 格式转换:保住语义才是关键
核心就调用BlocksToMarkdown这个方法,它会自动识别块类型,把飞书的特殊格式转成标准Markdown,遇到不认识的块还会输出提示,最大限度保住原文意思(代码位置:@backend/internal/eino/milvus/feishu/transmarkdown.go[#165](javascript:😉-305)。另外还有个“隐藏技能”——parseTextElements方法(就在同个文件里),会自动拼接段落、粗体这些文本元素,最后给你一个干干净净的Markdown字符串,直接就能喂给Milvus,省得你再做二次处理。
三、初始化Milvus导入器(资源释放别忘,血的教训!)
这步是搭“导入架子”,看着简单但细节致命。我之前就是忘关资源,导致服务器Milvus连接数直接爆了,排查了2小时才发现是这儿的问题,差点背锅。
- 先通过项目的
config.Config配置好Milvus集群地址、集合名、Embedding维度这些关键信息——尤其是维度,必须和你用的Embedding模型对应上,填错了数据根本导不进去。 - 调用
InitMilvusManager方法,一次性把Embedding、Splitter、Indexer、Retriever这些服务全拉起来(示例代码:@backend/internal/eino/milvus/example_feishu_import.go[#34](javascript:😉-58)。**defer manager.Close()**这里敲黑板!一定要加,确保程序跑完释放资源,不然连接会一直占着,服务器迟早崩。 - 最后用
NewMarkdownImporter创建导入器就行,它内部已经把“切割文本→向量化→入库”这些步骤串好了,不用你自己拼流程,省事儿又不容易错(代码位置:@backend/internal/eino/milvus/example_feishu_import.go[#50](javascript:😉-58)。
四、配置导入元数据(别偷懒,这步影响后续检索效率)
元数据这东西看着“不起眼”,实则是检索的“导航图”。我们之前做企业知识库时,就是没给数据标来源,后来想单独过滤飞书的内容都没法弄,最后只能重新导一遍,纯纯浪费时间。
直接用TextImportOptions指定这几个关键信息就行(代码位置:@backend/internal/eino/milvus/example_feishu_import.go[#60](javascript:😉-68),也就花1分钟的事儿:
Title:可以留空,系统会自动从Markdown里提取,但重要文档建议手动填,后续检索更精准。Language、Category:比如填“中文”“技术手册”“产品FAQ”,后续想按类型过滤数据时,直接就能用。Source:必须固定填"feishu",这样数据来源一目了然,后续排查问题也方便。
系统是有默认配置DefaultTextImportOptions,但我真心不推荐用。显式配置虽然多花1分钟,却能避免后续无数麻烦,这笔账怎么算都值。
五、切割Markdown并写入Milvus(核心流程,一步到位)
这步是整个同步流程的“发动机”,ImportText方法就是总入口,把前面准备的所有东西全串起来了,调用一次就行。
5.1 核心流程拆解:不用自己拼逻辑
调用ImportText后,它会自动干四件事(代码位置:@backend/internal/eino/milvus/importer.go[#345](javascript:😉-383):先筛掉空内容,避免无效写入;再用SplitMarkdown把长文本切成合适的片段;接着把我们配置的元数据追加上;最后调用IndexerService.Store写入Milvus,全程不用你干预。
5.2 切割技巧:粒度对了,检索命中率翻倍
切割粒度是个技术活——太粗了,检索时精准度不够;太细了,又会丢失上下文信息。SplitMarkdown方法很智能,会用标题、空行、列表这些天然分隔符来切,再结合你配置的ChunkSize和OverlapSize(代码位置:@backend/internal/eino/milvus/splitter/markdown.go[#11](javascript:😉-72)。给兄弟们一个干货经验:纯文字文档选500-800 tokens,FAQ或代码块就切到200-300 tokens,这样检索命中率能提升30%以上,亲测有效。
5.3 结果校验:别做“睁眼瞎”,同步完必须查
ImportText会返回ImportResult,里面有切片总数和成功写入的文档ID(示例:@backend/internal/eino/milvus/example_feishu_import.go[#70](javascript:😉-88)。一定要把这些信息打日志,同步完对照着飞书文档数数一数,看看有没有漏导、错导,别等上线了才发现问题。
六、端到端示例(直接抄,10分钟跑通)
项目里的ExampleFeishuImport就是完整的“标准答案”(代码位置:@backend/internal/eino/milvus/example_feishu_import.go[#34](javascript:😉-88),流程清晰到不用看注释:拿transmarkdown.go转好的Markdown → 初始化Milvus管理器和导入器 → 配置元数据 → 调用ImportText → 输出结果校验。照着这个Demo改改凭证和配置,10分钟就能跑通。
如果要做批量同步,直接用CLI里的feishu-import示例(@backend/internal/eino/milvus/cmd/milvusctl/main.go[#270](javascript:😉-319),里面全是注释好的代码,改改循环逻辑就能批量跑——支持批量拉文档、输出内容长度、上传后打印结果,省得你从零开始写脚本。
七、生产化部署:避坑提醒(这些错我全犯过)
本地跑通不算本事,上生产环境才是真考验。下面这几个避坑点,兄弟们记死了,别再交我交过的学费。
避坑提醒1:批量调度必须用增量同步 别傻呵呵每次都全量导,定时遍历知识库目录,用文件修改时间或自定义标签判断哪些是新文档、哪些是更新过的,1-3天跑一次增量就行,既省服务器资源又快。
避坑提醒2:去重和版本控制要做死 用“文档token+版本号”生成唯一ID,旧版本要么软删除,要么保留多版本——不然新内容会覆盖旧的,万一同步错了,连回滚的机会都没有。
避坑提醒3:错误告警必须拉满 把ImportText的报错对接监控系统,比如内容为空、Milvus连不上这些情况,必须10分钟内告警,还得支持自动重试,不然半夜同步失败都不知道,第二天业务方就得找你麻烦。
避坑提醒4:同步粒度别一刀切 按文档类型调整ChunkSize,文字类500-800 tokens,代码类200-300 tokens,针对性调整才能让检索又快又准。
其实按上面的步骤走,把飞书知识库自动同步到Milvus真不难,不管是做企业知识问答,还是搭AI助手的语料底座,都稳得很。我把关键代码位置全标出来了,兄弟们跟着改就行,不用自己瞎找。
你们同步的时候遇到过什么奇葩坑?是权限配置卡壳了,还是切割粒度调不对?评论区留言说下,我来帮你出主意。另外别忘了关注我,后面再给你们分享Milvus检索优化的干货,全是项目里摸爬滚打出来的实战经验,比看官方文档管用10倍!
我是阳哥,专注分享AI+后端的实战干货,关注我,下次踩坑少走弯路!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)